Versionner et suivre des jeux de données Azure Machine Learning
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Dans cet article, vous apprendrez à gérer les versions et à suivre les jeux de données Azure Machine Learning pour la reproductibilité. Le contrôle de version d’un jeu de données met en signet des états spécifiques de vos données afin de pouvoir appliquer une version spécifique du jeu de données pour de futures expériences.
Vous pouvez vouloir contrôler la version de vos ressources Azure Machine Learning dans les scénarios classiques suivants :
- Quand de nouvelles données deviennent disponibles pour une nouvelle formation
- Quand vous appliquez différentes approches de préparation des données ou d’ingénierie des caractéristiques
Prérequis
Le kit de développement logiciel (SDK) Azure Machine Learning pour Python. Ce kit de développement logiciel (SDK) comprend le package azureml-datasets
Un espace de travail Azure Machine Learning. Créez un espace de travail ou récupérez un espace de travail existant avec cet exemple de code :
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Inscrire et récupérer des versions de jeux de données
Vous pouvez contrôler la version d’un jeu de données inscrit, le réutiliser et le partager entre des expériences et avec des collègues. Vous pouvez inscrire plusieurs jeux de données sous le même nom et récupérer une version spécifique à partir de son nom et de son numéro de version.
Inscrire une version de jeu de données
Cet exemple de code définit le paramètre create_new_version du jeu de données titanic_ds sur True pour inscrire une nouvelle version de ce jeu de données. Si aucun jeu de données titanic_ds existant n’est inscrit auprès de l’espace de travail, le code crée un nouveau jeu de données portant le nom titanic_ds et définit sa version sur 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Récupérer un jeu de données par nom
Par défaut, la méthode get_by_name() de la classe Dataset retourne la dernière version du jeu de données inscrit auprès de l’espace de travail.
Ce code retourne la version 1 du jeu de données titanic_ds.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Meilleures pratiques relatives au contrôle de version
Lorsque vous créez une version d’un jeu de données, vous ne créez pas une copie supplémentaire des données avec l’espace de travail. Dans la mesure où les jeux de données sont des références aux données de votre service de stockage, vous disposez d’une seule source de vérité, gérée par votre service de stockage.
Important
Si les données référencées par votre jeu de données sont remplacées ou supprimées, un appel d’une version spécifique du jeu de données ne permet pas d’annuler la modification.
Lorsque vous chargez des données à partir d’un jeu données, le contenu des données actuelles référencées par le jeu de données est toujours chargé. Si vous souhaitez vous assurer que chaque version du jeu de données est reproductible, nous vous recommandons d’éviter de modifier le contenu des données référencées par la version du jeu de données. Lorsque de nouvelles données arrivent, enregistrez les nouveaux fichiers de données dans un dossier de données distinct, puis créez une nouvelle version du jeu de données pour inclure les données de ce nouveau dossier.
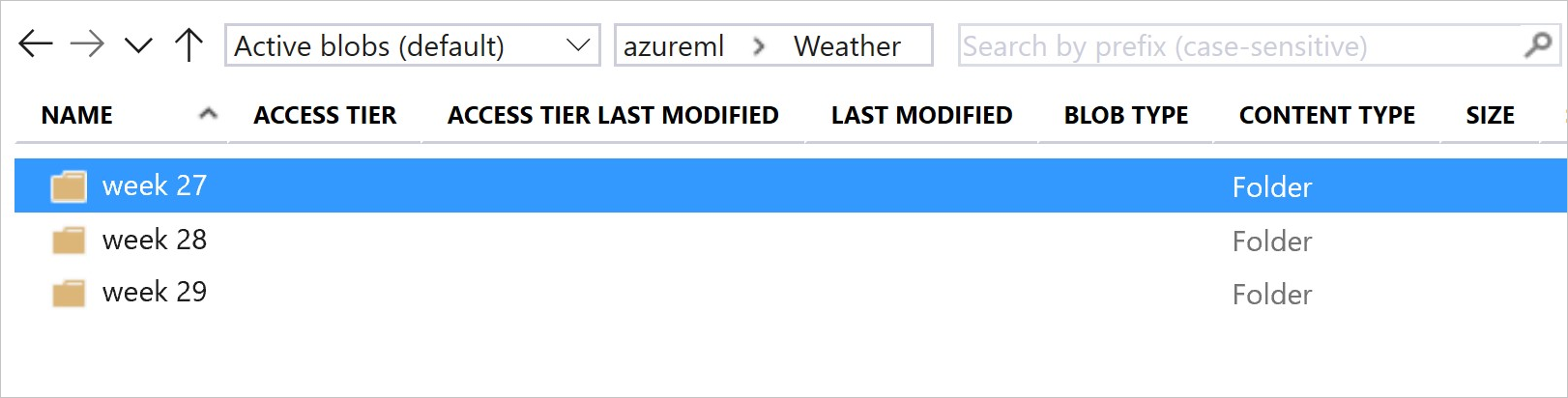
Cette image et cet exemple de code montrent la méthode recommandée pour à la fois structurer vos dossiers de données et créer des versions de jeu de données faisant référence à ces dossiers :
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Gérer la version d’un jeu de données de sortie de pipeline ML
Vous pouvez utiliser un jeu de données comme entrée et sortie de chaque étape de pipeline ML. Lorsque vous réexécutez des pipelines, la sortie de chaque étape de pipeline est inscrite en tant que nouvelle version du jeu de données.
Les pipelines Machine Learning renseignent la sortie de chaque étape dans un nouveau dossier chaque fois que le pipeline est réexécuté. Les jeux de données de sortie faisant l’objet d’un contrôle de version deviennent alors reproductibles. Pour plus d’informations, consultez jeux de données dans les pipelines.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Suivre les données dans vos expériences
Azure Machine Learning effectue le suivi de vos données dans votre expérience en tant que jeux de données d’entrée et de sortie. Dans ces scénarios, vos données sont suivies en tant que jeu de données d’entrée :
En tant qu’objet
DatasetConsumptionConfig, par le biais du paramètreinputsouargumentsde votre objetScriptRunConfiglors de l’envoi d’un travail d’expérimentationLorsque votre script appelle certaines méthodes,
get_by_name()ouget_by_id(), par exemple. Le nom attribué au jeu de données au moment où vous l’avez inscrit auprès de l’espace de travail est le nom affiché
Dans ces scénarios, vos données sont suivies en tant que jeu de données de sortie :
Passez un objet
OutputFileDatasetConfigpar le biais du paramètreoutputsouargumentslorsque vous envoyez un travail d’expérimentation. Les objetsOutputFileDatasetConfigpeuvent également rendre les données persistantes entre les étapes du pipeline. Pour plus d’informations, consultez Déplacer des données entre des étapes du pipeline MLInscrivez un jeu de données dans votre script. Le nom attribué au jeu de données lorsque vous l’avez inscrit auprès de l’espace de travail est le nom affiché. Dans cet exemple de code,
training_dsest le nom affiché :training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )La soumission d’un travail enfant, avec un jeu de données non inscrit, dans le script. Cette soumission aboutit à un jeu de données anonyme enregistré
Suivre des jeux de données dans les travaux d’expérimentation
Pour chaque expérience Machine Learning, vous pouvez suivre les jeux de données d’entrée pour l’objet Job de l’expérience. Cet exemple de code utilise la méthode get_details() pour suivre les jeux de données d’entrée utilisés lors de l’exécution de l’expérience :
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
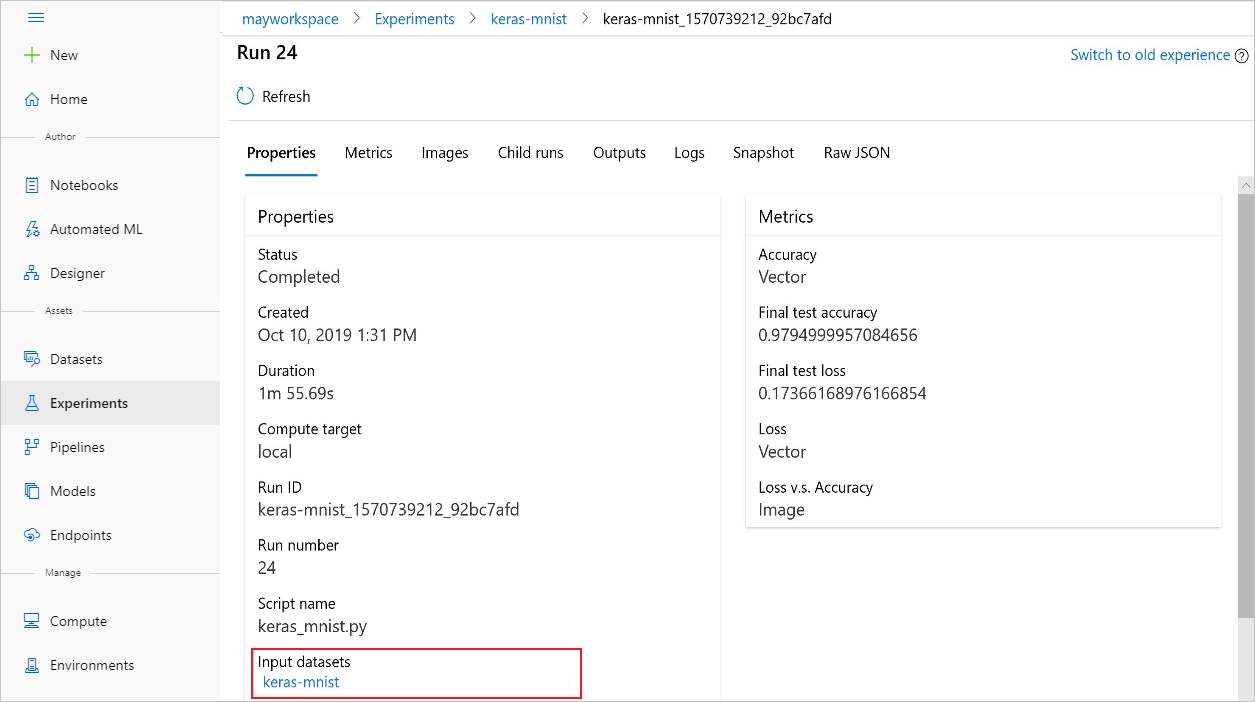
Vous pouvez également trouver les input_datasets à partir d’expériences avec Azure Machine Learning studio.
Cette capture d’écran montre où trouver le jeu de données d’entrée d’une expérience sur Azure Machine Learning studio. Pour cet exemple, démarrez depuis votre volet Expériences et ouvrez l’onglet Propriétés pour une exécution spécifique de votre expérience, keras-mnist.
Ce code inscrit des modèles avec des jeux de données :
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
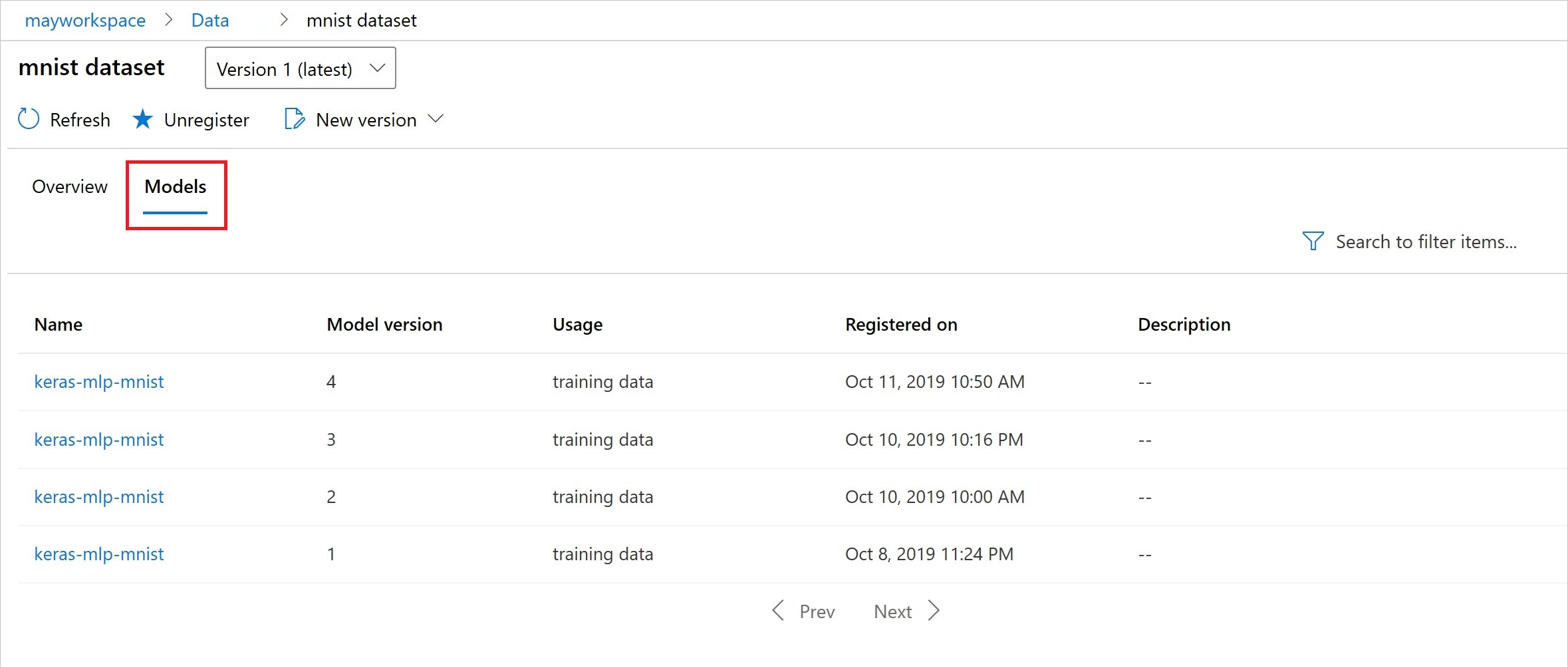
Après l’inscription, vous pouvez voir la liste des modèles inscrits auprès du jeu de données à l’aide de Python ou du studio.
Cette capture d’écran est issue du volet Jeux de données sous Ressources. Sélectionnez le jeu de données, puis sélectionnez l’onglet Modèles pour obtenir la liste des modèles qui sont inscrits avec le jeu de données.