Augmenter la rapidité des points de contrôle et réduire les coûts avec Nebula
Découvrez comment augmenter la vitesse des points de contrôle et réduire le coût des points de contrôle pour les modèles d’entraînement Azure Machine Learning volumineux au moyen de Nebula.
Vue d’ensemble
Nebula est un outil de point de contrôle rapide, simple, sans disque et prenant en charge les modèles, qui fait partie d’Azure Container pour PyTorch (ACPT). Nebula offre une solution simple de points de contrôle à grande vitesse pour les travaux d’entraînement distribué de modèles à grande échelle avec PyTorch. En utilisant les dernières technologies d’informatique distribuée, Nebula peut réduire le temps des points de contrôle de quelques heures à quelques secondes, ce qui permet d’économiser de 95 % à 99,9 % de temps. Les travaux d’entraînement à grande échelle peuvent grandement tirer parti des performances de Nebula.
Pour rendre Nebula disponible pour vos travaux d’entraînement, importez le package Python nebulaml dans votre script. Nebula est entièrement compatible avec différentes stratégies d’entraînement PyTorch distribué, notamment PyTorch Lightning, DeepSpeed, etc. L’API Nebula offre un moyen simple de surveiller et de consulter les cycles de vie des points de contrôle. Les API prennent en charge différents types de modèles et garantissent la cohérence et la fiabilité des points de contrôle.
Important
Le package nebulaml n’est pas disponible dans l’index des packages Python PyPI public. Il n’est disponible que dans l’environnement organisé par Azure Container pour PyTorch (ACPT) sur Azure Machine Learning. Pour éviter les problèmes, n’essayez pas d’installer nebulaml à partir de PyPI ou à l’aide de la commande pip.
Dans ce document, vous allez apprendre à utiliser Nebula avec ACPT sur Azure Machine Learning pour vérifier rapidement vos travaux d’entraînement de modèles à l’aide de points de contrôle. En outre, vous allez apprendre à afficher et à gérer les données des points de contrôle Nebula. Vous découvrirez également comment reprendre les travaux d’entraînement de modèles à partir du dernier point de contrôle disponible en cas d’interruption, de défaillance ou d’arrêt d’Azure Machine Learning.
Pourquoi l’optimisation des points de contrôle pour l’entraînement de modèles volumineux est-elle importante ?
À mesure que les volumes de données augmentent et que les formats de données deviennent plus complexes, les modèles Machine Learning sont également devenus plus sophistiqués. L’entraînement de ces modèles complexes peut devenir difficile à cause des limites de capacité de mémoire GPU et des temps d’entraînement longs. Par conséquent, l’entraînement distribué est souvent utilisé lors de l’utilisation de jeux de données volumineux et de modèles complexes. Toutefois, les architectures distribuées peuvent rencontrer des erreurs inattendues et des défaillances de nœuds, ce qui peut devenir de plus en plus problématique à mesure que le nombre de nœuds dans un modèle Machine Learning augmente.
Les points de contrôle peuvent aider à atténuer ces problèmes en enregistrant régulièrement un instantané de l’état complet du modèle à un moment donné. En cas de défaillance, cet instantané peut être utilisé pour reconstruire le modèle à son état au moment de l’instantané pour que l’entraînement puisse reprendre à partir de ce point.
Lorsque les opérations d’entraînement de modèles volumineux subissent des échecs ou des arrêts, les chercheurs et scientifiques des données peuvent restaurer le processus d’entraînement à partir d’un point de contrôle précédemment enregistré. Toutefois, toute progression entre le point de contrôle et l’arrêt est perdue, car les calculs doivent être réexécutés pour récupérer des résultats intermédiaires non enregistrés. Des intervalles de point de contrôle plus courts peuvent aider à réduire cette perte. Le diagramme illustre le temps perdu entre le processus d’entraînement à partir des points de contrôle et l’arrêt :

Toutefois, le processus d’enregistrement des points de contrôle lui-même peut générer une surcharge importante. L’enregistrement d’un point de contrôle de l’ordre du téraoctet peut souvent devenir un goulot d’étranglement dans le processus d’entraînement, le processus de point de contrôle synchronisé bloquant l’entraînement pendant des heures. En moyenne, les surcharges liées aux points de contrôle peuvent compter pour 12 % du temps total d’entraînement et atteindre jusqu’à 43 % (Maeng et al., 2021).
Pour résumer, la gestion des points de contrôle de modèles volumineux implique un stockage important et des surcharges de temps de récupération des travaux. Les enregistrements fréquents de points de contrôle, combinés à la reprise des travaux d’entraînement à partir des derniers points de contrôle disponibles, constituent un grand défi.
Nebula à la rescousse
Pour entraîner efficacement des modèles distribués volumineux, il est utile de disposer d’un moyen fiable et efficace pour enregistrer et reprendre la progression de l’entraînement qui permet de réduire les pertes de données et de ressources. Nebula permet de réduire les temps d’enregistrement des points de contrôle et les demandes d’heures GPU pour les travaux d’entraînement Azure Machine Learning de grands modèles en offrant une gestion des points de contrôle plus rapide et plus facile.
Avec Nebula, vous pouvez :
Augmenter jusqu’à 1 000 fois les vitesses des points de contrôle avec une API simple qui fonctionne de manière asynchrone avec votre processus d’entraînement. Nebula peut réduire le temps des points de contrôle à quelques secondes, au lieu d’heures, soit une réduction potentielle de 95 % à 99,9 %.
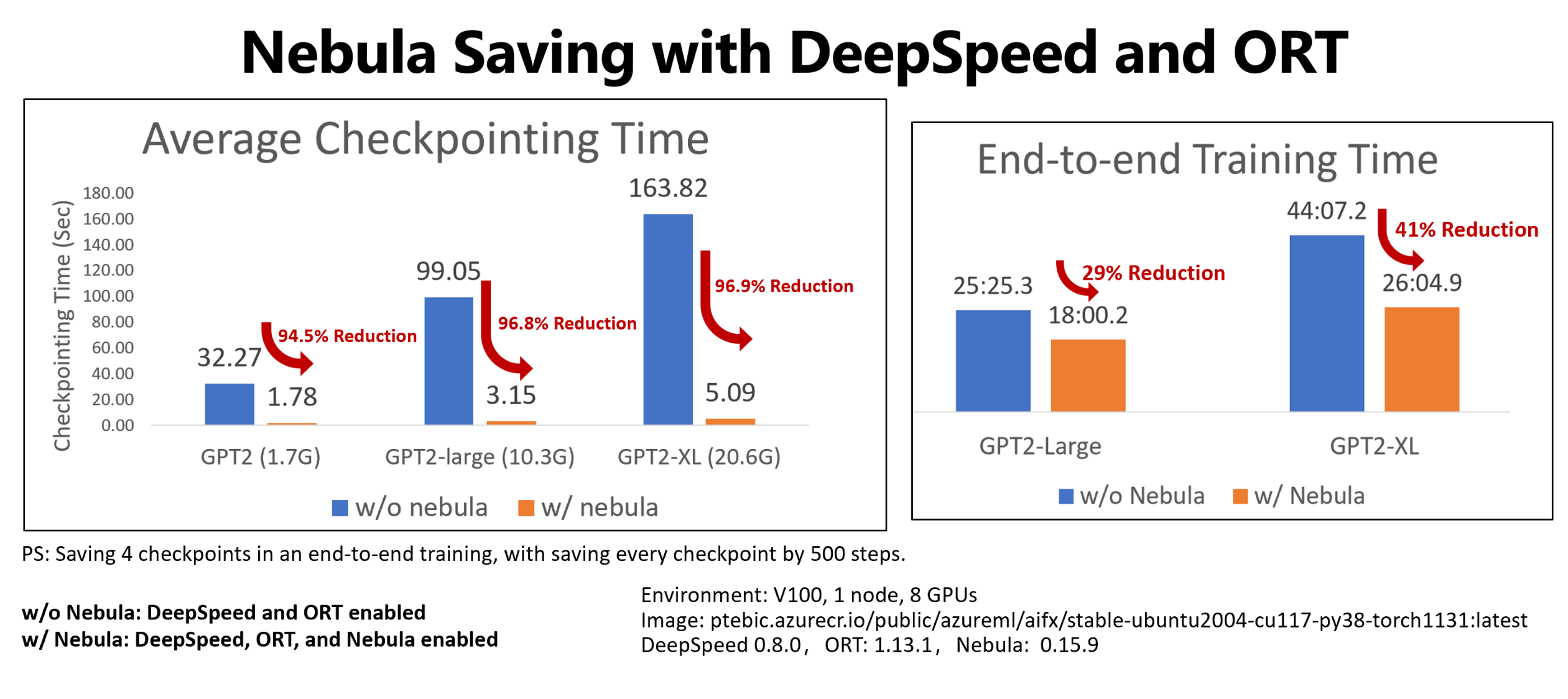
Cet exemple montre la réduction du temps de contrôle et d’entraînement de bout en bout pour quatre enregistrements de points de contrôle des travaux d’entraînement Hugging Face GPT-2, GPT-2 Large et GPT-2 XL. Pour l’enregistrement de point de contrôle Hugging Face GPT-2 XL de taille moyenne (20,6 Go), Nebula a obtenu une réduction du temps de 96,9 % pour un point de contrôle.
Le gain de vitesse des points de contrôle peut toujours augmenter avec la taille du modèle et le nombre de GPU. Par exemple, le test d’enregistrement de point de contrôle d’entraînement de 97 Go sur 128 GPU Nvidia A100 peut passer de 20 minutes à 1 seconde.
Réduisez le temps d’entraînement de bout en bout et les coûts de calcul pour les grands modèles en réduisant la surcharge des points de contrôle et le nombre d’heures de GPU perdues lors de la récupération des travaux. Nebula enregistre les points de contrôle de manière asynchrone et débloque le processus d’entraînement pour réduire le temps d’entraînement de bout en bout. Il permet également d’effectuer des enregistrements de points de contrôle plus fréquents. Vous pouvez dès lors reprendre l’entraînement à partir du dernier point de contrôle après une interruption, gagner du temps et économiser de l’argent dans le cadre de la récupération de travaux et de l’entraînement GPU.
Assurer une compatibilité complète dans PyTorch. Nebula assure une compatibilité complète avec PyTorch et propose une intégration complète avec des infrastructures d’entraînement distribué, notamment DeepSpeed (>=0.7.3) et PyTorch Lightning (>=1.5.0). Vous pouvez également l’utiliser avec différentes cibles de calcul Azure Machine Learning, telles que la capacité de calcul Azure Machine Learning ou AKS.
Gérer facilement vos points de contrôle avec un package Python qui permet de répertorier, d’obtenir, d’enregistrer et de charger vos points de contrôle. Pour afficher le cycle de vie des points de contrôle, Nebula fournit également des journaux complets sur Azure Machine Learning studio. Vous pouvez choisir d’enregistrer vos points de contrôle à un emplacement de stockage local ou distant
- Stockage Blob Azure
- Azure Data Lake Storage
- NFS
et y accéder à tout moment à l’aide de quelques lignes de code.

Prérequis
- Un abonnement Azure et un espace de travail Azure Machine Learning. Pour plus d’informations sur la création de ressources d’espace de travail, consultez l’article Créer des ressources d’espace de travail
- Une cible de calcul Azure Machine Learning. Consultez Gérer la formation et déployer des calculs pour en savoir plus sur la création de cibles de calcul
- Un script d’entraînement qui utilise PyTorch.
- Environnement organisé par ACPT (Azure Container pour PyTorch). Pour obtenir l’image ACPT, consultez la section Environnements organisés. Découvrez comment utiliser l’environnement organisé
Comment utiliser Nebula
Nebula offre une expérience de point de contrôle rapide et facile, intégrée à votre script d’entraînement existant. Les étapes de démarrage rapide de Nebula sont les suivantes :
- Utilisation de l’environnement ACPT
- Initialisation de Nebula
- Appels d’API pour enregistrer et charger des points de contrôle
Utilisation de l’environnement ACPT
Azure Container pour PyTorch (ACPT), un environnement organisé pour l’entraînement de modèles PyTorch, inclut Nebula en tant que package Python dépendant préinstallé. Consultez la section Azure Container pour PyTorch (ACPT) pour afficher l’environnement organisé et l’article Enabling Deep Learning with Azure Container for PyTorch in Azure Machine Learning (en anglais uniquement) pour en savoir plus sur l’image ACPT.
Initialisation de Nebula
Pour activer Nebula avec l’environnement ACPT, il vous suffit de modifier votre script d’entraînement pour importer le package nebulaml, puis d’appeler les API Nebula aux emplacements appropriés. Vous pouvez éviter la modification du SDK ou de l’interface CLI Azure Machine Learning. Vous pouvez également éviter la modification d’autres étapes pour entraîner votre modèle volumineux sur la plateforme Azure Machine Learning.
Nebula doit être initialisé pour s’exécuter dans votre script d’entraînement. Lors de la phase d’initialisation, spécifiez les variables qui déterminent l’emplacement et la fréquence d’enregistrement des points de contrôle, comme indiqué dans cet extrait de code :
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
Nebula a été intégré à DeepSpeed et PyTorch Lightning. Par conséquent, l’initialisation est un processus simple et rapide. Ces exemples montrent comment intégrer Nebula à vos scripts d’entraînement.
Important
L’enregistrement des points de contrôle avec Nebula nécessite de la mémoire pour leur stockage. Veuillez vous assurer que votre mémoire est supérieure à au moins trois copies des points de contrôle.
Si la mémoire n’est pas suffisante pour contenir des points de contrôle, il est recommandé de configurer une variable d’environnement NEBULA_MEMORY_BUFFER_SIZE dans la commande afin de limiter l’utilisation de la mémoire pour chaque nœud lors de l’enregistrement des points de contrôle. Lors de la définition de cette variable, Nebula utilise cette mémoire comme mémoire tampon pour enregistrer les points de contrôle. Si l’utilisation de la mémoire n’est pas limitée, Nebula utilise la mémoire autant que possible pour stocker les points de contrôle.
Si plusieurs processus s’exécutent sur le même nœud, la mémoire maximale pour l’enregistrement des points de contrôle sera la moitié de la limite divisée par le nombre de processus. Nebula utilise l’autre moitié pour la coordination multiprocesseur. Par exemple, si vous souhaitez limiter l’utilisation de la mémoire par nœud à 200 Mo, vous pouvez définir la variable d’environnement sur export NEBULA_MEMORY_BUFFER_SIZE=200000000 (en octets, environ 200 Mo) dans la commande. Dans ce cas, Nebula utilise uniquement 200 Mo de mémoire pour stocker les points de contrôle dans chaque nœud. Si 4 processus s’exécutent sur le même nœud, Nebula utilise 25 Mo de mémoire par processus pour stocker les points de contrôle.
Appels d’API pour enregistrer et charger des points de contrôle
Nebula fournit des API pour gérer les enregistrements des points de contrôle. Vous pouvez utiliser ces API dans vos scripts d’entraînement, comme l’API PyTorch torch.save(). Ces exemples montrent comment utiliser Nebula dans vos scripts d’entraînement.
Afficher l’historique des points de contrôle
Une fois votre travail d’entraînement terminé, accédez au volet Travail Name> Outputs + logs. Dans le volet gauche, développez le dossier Nebula, puis sélectionnez checkpointHistories.csv pour afficher des informations détaillées sur les enregistrements de points de contrôle Nebula (durée, débit et taille du point de contrôle).

Exemples
Ces exemples montrent comment utiliser Nebula avec différents types d’infrastructure. Vous pouvez choisir l’exemple qui correspond le mieux à votre script d’entraînement.
Pour activer la compatibilité complète de Nebula avec les scripts d’entraînement PyTorch, modifiez votre script d’entraînement en fonction des besoins.
Commencez par importer le package
nebulamlrequis :# Import the Nebula package for fast-checkpointing import nebulaml as nmPour initialiser Nebula, appelez la fonction
nm.init()dansmain(), comme illustré ici :# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)Pour enregistrer case activée points, remplacez l’instruction d’origine
torch.save()pour enregistrer votre case activée point par Nébula. Vérifiez que votre instance case activée point commence par « global_step », par exemple « global_step500 » ou « global_step1000 » :checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)Remarque
<'CKPT_TAG_NAME'>correspond à l’ID unique du point de contrôle. Une balise indique généralement le nombre d’étapes, le numéro d’époque ou un nom défini par l’utilisateur. Le paramètre facultatif<'NUM_OF_FILES'>détermine le numéro d’état à enregistrer pour cette balise.Chargez le dernier point de contrôle valide, comme illustré ici :
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)Étant donné qu’un point de contrôle ou qu’un instantané peut contenir de nombreux fichiers, vous pouvez en charger un ou plusieurs par nom. Il est possible de restaurer l’état d’entraînement à l’état enregistré par le dernier point de contrôle.
D’autres API peuvent se charger de la gestion des points de contrôle
- répertorier tous les points de contrôle
- obtenir les derniers points de contrôle
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)