Exemples de jeux de données et de pipelines pour le concepteur Azure Machine Learning
Utilisez les exemples intégrés du concepteur Azure Machine Learning pour commencer rapidement à créer vos propres pipelines Machine Learning. Le dépôt GitHub du concepteur Azure Machine Learning contient une documentation détaillée pour mieux comprendre certains scénarios de machine learning courants.
Prérequis
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit
- Espace de travail Azure Machine Learning
Important
Si vous ne voyez pas les éléments graphiques mentionnés dans ce document, tels que les boutons dans Studio ou le concepteur, vous ne disposez peut-être pas du niveau d’autorisations approprié pour l’espace de travail. Contactez votre administrateur d’abonnement Azure pour vérifier que le niveau d’accès est correct. Pour plus d’informations, consultez Gérer les utilisateurs et les rôles.
Utiliser les exemples de pipelines
Le concepteur enregistre une copie des exemples de pipelines dans votre espace de travail Studio. Vous pouvez modifier un pipeline pour l’adapter à vos besoins et l’enregistrer afin de vous l’approprier. Utilisez-les comme point de départ pour démarrer vos projets.
Voici comment utiliser un exemple de concepteur :
Connectez-vous à ml.azure.com, puis sélectionnez l’espace de travail à utiliser.
Sélectionnez Concepteur.
Sélectionnez un exemple de pipeline dans la section Nouveau pipeline.
Sélectionnez Afficher plus d’échantillons pour obtenir la liste complète des exemples.
Pour exécuter un pipeline, vous devez d’abord définir la cible de calcul par défaut sur laquelle exécuter le pipeline.
Dans le volet Paramètres à droite du canevas, sélectionnez Sélectionner une cible de calcul.
Dans la boîte de dialogue qui s’affiche, sélectionnez une cible de calcul existante ou créez-en une. Sélectionnez Enregistrer.
Sélectionnez Envoyer en haut du canevas pour envoyer un travail de pipeline.
Selon l’exemple de pipeline et les paramètres de calcul, les travaux peuvent prendre du temps. Les paramètres de calcul par défaut ont une taille de nœud minimale de 0, ce qui signifie que le concepteur doit allouer des ressources après une période d’inactivité. Les travaux de pipeline répétés prennent moins de temps dans la mesure où les ressources de calcul sont déjà allouées. Par ailleurs, le concepteur utilise les résultats mis en cache pour chaque composant afin d’améliorer l’efficacité.
Une fois l’exécution du pipeline terminée, vous pouvez passer en revue le pipeline et examiner la sortie de chaque composant pour en savoir plus. Utilisez les étapes suivantes pour consulter les sorties des composants :
- Cliquez avec le bouton droit sur le composant dans le canevas dont vous souhaitez afficher la sortie.
- Sélectionnez Visualiser.
Utilisez les exemples comme points de départ pour quelques-uns des scénarios de Machine Learning les plus courants.
régression ;
Explorez ces exemples de régression intégrés.
| Exemple de titre | Description |
|---|---|
| Régression – Prédiction du prix des véhicules automobiles (simple) | Prédit le prix des véhicules à l’aide d’une régression linéaire. |
| Régression – Prédiction du prix des véhicules automobiles (avancé) | Prédit le prix des véhicules à l’aide des régresseurs de la forêt de décision et de l’arbre de décision optimisé. Compare les modèles pour trouver le meilleur algorithme. |
classification ;
Explorez ces exemples de classification intégrés. Vous pouvez en apprendre davantage sur ces exemples en les ouvrant et en consultant les commentaires des composants dans le concepteur.
| Exemple de titre | Description |
|---|---|
| Classification binaire avec sélection des caractéristiques – Prédiction des revenus | Prédit des revenus comme étant élevés ou faibles à l’aide d’un arbre de décision optimisé à deux classes. Utilisez la corrélation de Pearson pour sélectionner les caractéristiques. |
| Classification binaire avec un script Python personnalisé – Prédiction du risque de crédit | Classe les demandes de crédit comme présentant un risque élevé ou faible. Utilisez le composant Exécuter un script Python pour pondérer vos données. |
| Classification binaire – Prédiction de la relation client | Prédit l’attrition clients à l’aide d’arbres de décision optimisés à deux classes. Utilisez SMOTE pour échantillonner des données biaisées. |
| Classification de texte – Jeu de données Wikipédia SP 500 | Classifie des types de sociétés à partir d’articles Wikipédia avec la régression logistique multiclasse. |
| Classification multiclasse - Reconnaissance des lettres | Crée un ensemble de classifieurs binaires pour classifier les lettres écrites. |
Vision par ordinateur
Explorez ces exemples de vision par ordinateur intégrée. Vous pouvez en apprendre davantage sur ces exemples en les ouvrant et en consultant les commentaires des composants dans le concepteur.
| Exemple de titre | Description |
|---|---|
| Classification d’images à l’aide de DenseNet | Utilisez les composants Vision par ordinateur pour créer un modèle de classification d’images basé sur PyTorch DenseNet. |
Générateur de recommandations
Explorez ces exemples de générateur de recommandations intégrés. Vous pouvez en apprendre davantage sur ces exemples en les ouvrant et en consultant les commentaires des composants dans le concepteur.
| Exemple de titre | Description |
|---|---|
| Recommandation basée sur Wide & Deep – Prédiction d’évaluation de restaurant | Créez un moteur de recommandation de restaurant à partir des fonctionnalités et évaluations d’un restaurant/utilisateur. |
| Recommandation - Tweets d’évaluation des films | Créez un moteur de recommandations de films à partir des fonctionnalités et évaluations d’un film/utilisateur. |
Utilitaire
Découvrez les exemples qui montrent les utilitaires et les caractéristiques de Machine Learning. Vous pouvez en apprendre davantage sur ces exemples en les ouvrant et en consultant les commentaires des composants dans le concepteur.
| Exemple de titre | Description |
|---|---|
| Classification binaire à l’aide du modèle Vowpal Wabbit – Prédiction Adult Income | Vowpal Wabbit est un système de Machine Learning qui repousse les limites de l’apprentissage automatique grâce à des techniques telles que l’apprentissage en ligne, par hachage, par allreduce, par réductions, par learning2search, mais aussi l’apprentissage actif et interactif. Cet exemple montre comment utiliser le modèle Vowpal Wabbit pour générer un modèle de classification binaire. |
| Utiliser un script R personnalisé – Prédiction de retard des vols | Utilisez un script R personnalisé pour prédire si un vol de passagers planifié est retardé de plus de 15 minutes. |
| Validation croisée pour la classification binaire - Prédiction des revenus des adultes | Utilise la validation croisée afin de créer un classifieur binaire pour les revenus des adultes. |
| Importance de la fonctionnalité de permutation | Utilise l’importance d’une caractéristique de permutation pour calculer les scores d’importance du jeu de données de test. |
| Réglage des paramètres pour la classification binaire - Prédiction des revenus des adultes | Utilise Optimiser les hyperparamètres du modèle afin de trouver des hyperparamètres optimaux pour la création d’un classifieur binaire. |
Groupes de données
Quand vous créez un pipeline dans le concepteur Azure Machine Learning, vous disposez par défaut d’un certain nombre d’exemples de jeux de données. Ces exemples de jeux de données sont utilisés par les exemples de pipelines dans la page d’accueil du concepteur.
Les exemples de jeux de données sont disponibles dans la catégorie Jeux de données-Exemples. Vous les trouverez dans la palette de composants à gauche du canevas du concepteur. Vous pouvez utiliser l’un de ces jeux de données dans votre propre pipeline en le faisant glisser sur le canevas.
| Nom du jeu de données | Description du jeu de données |
|---|---|
| Jeu de données Adult Census Income Binary Classification | Sous-ensemble de la base de données Census de 1994, qui recense les adultes de plus de 16 ans en activité avec un index des revenus ajustés supérieur à 100. Utilisation: classifier des personnes en utilisant des données démographiques pour prédire si une personne gagne plus de 50 000 $ par an. Recherche associée : Kohavi, R., Becker, B., (1996). Dépôt Machine Learning UCI. Irvine, CA: University of California, School of Information and Computer Science |
| Données sur le prix des véhicules automobiles (brutes) | Informations sur les véhicules automobiles par marque et modèle, incluant le prix, des caractéristiques telles que le nombre de cylindres et de litres au 100, et une note de risque d'assurance. La note de risque est initialement associée au prix de l’automobile. Elle est ensuite ajustée en fonction du risque réel selon un processus que les actuaires connaissent sous le nom de symbolisation. La valeur +3 indique que le véhicule est à risque et la valeur -3 qu’il est plutôt sûr. Utilisation: prédire le score de risque en fonction des caractéristiques, en utilisant une classification de régression ou multivariée. Recherche associée : Schlimmer, J.C. (1987). Dépôt Machine Learning UCI. Irvine, CA: University of California, School of Information and Computer Science. |
| Étiquettes de l'appétence CRM partagées | Étiquettes provenant du KDD Cup 2009 Customer Relationship Prediction Challenge (orange_small_train_appetency.labels). |
| Étiquettes de l'attrition CRM partagées | Étiquettes provenant du KDD Cup 2009 Customer Relationship Prediction Challenge (orange_small_train_churn.labels). |
| Jeu de données CRM partagé | Ces données proviennent du KDD Cup 2009 Customer Relationship Prediction Challenge (orange_small_train.data.zip). Le jeu de données contient 50 000 clients de la société de télécoms française Orange. Chaque client possède 230 caractéristiques rendues anonymes, dont 190 sont numériques et 40 sont catégorielles. Elles sont très fragmentées. |
| Étiquettes de vente incitative CRM partagées | Étiquettes provenant du KDD Cup 2009 Customer Relationship Prediction Challenge (orange_large_train_upselling.labels |
| Données relatives aux vols retardés | Données de ponctualité des vols passagers provenant de la collection de données TranStats du ministère Ministère des transports des États-Unis (à l’heure). Le jeu de données couvre la période d’avril à octobre 2013. Avant son chargement dans le concepteur, le jeu de données a été traité comme suit : - Le jeu de données a été filtré afin de prendre uniquement en compte les 70 aéroports les plus fréquentés aux États-Unis - Les vols annulés ont été considérés comme ayant été retardés de plus de 15 minutes - Les vols déviés ont été supprimés - Les colonnes suivantes ont été sélectionnées : Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Jeu de données d'UCI pour une carte de crédit allemande | Jeu de données UCI Statlog (carte de crédit allemande) (Statlog+German+Credit+Data), utilisant le fichier german.data. Le jeu de données classe les gens, décrits par un ensemble d’attributs, par risque de crédit (faible ou élevé). Chaque exemple représente une personne. Il y a 20 caractéristiques, numériques et catégoriques, ainsi qu’une étiquette binaire (la valeur du risque de crédit). Les entrées avec un risque de crédit élevé portent une étiquette = 2, tandis que les entrées avec un risque de crédit faible portent une étiquette = 1. Le coût d’une erreur de classification d’un risque de crédit faible en risque élevé est de 1 tandis qu’il est de 5 dans le cas inverse (classification d’un risque de crédit élevé en risque faible). |
| Titres de films IMDB | Ce jeu de données contient des informations sur les films évalués dans des tweets sur Twitter : ID de film IMDB, titre du film, genre et année de production. Ce jeu de données contient 17 000 films. Le jeu de données provient du document « S. Dooms, T. De Pessemier et L. Martens. MovieTweetings: a Movie Rating Dataset Collected From Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013. » |
| Classifications des films | Ce jeu de données est une version étendue du jeu de données Movie Tweetings. Il contient 170 000 évaluations de film, tirées de tweets structurés publiés sur Twitter. Chaque instance correspond à un tweet et constitue un tuple : ID utilisateur, ID IMDB, évaluation, horodatage, nombre de favoris pour ce tweet et nombre de retweets pour ce tweet. Ce jeu de données a été fourni par A. Said, S. Dooms, B. Loni et D. Tikk dans le cadre du Recommender Systems Challenge 2014. |
| Jeu de données météorologiques | Observations météorologiques terrestres effectuées toutes les heures par la NOAA (données fusionnées, de 201304 à 201310). Les données météorologiques couvrent les observations effectuées depuis les stations météo des aéroports, entre les mois d’avril et octobre 2013. Avant son chargement dans le concepteur, le jeu de données a été traité comme suit : - Les identifiants des stations météo ont été alignés sur les identifiants des aéroports correspondants - Les stations météo non associées à l’un des 70 aéroports les plus fréquentés ont été supprimées - La colonne Date a été divisée en plusieurs colonnes distinctes indiquant l’année, le mois et le jour - Les colonnes suivantes ont été sélectionnées : AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Jeu de données Wikipedia concernant le SP 500 | Les données sont extraites de Wikipédia (https://www.wikipedia.org/), notamment d’articles sur chaque société S&P 500 et sont stockées sous forme de données XML. Avant son chargement dans le concepteur, le jeu de données a été traité comme suit : - Extraction du contenu textuel de chaque société particulière - Suppression de la mise en forme wiki - Suppression des caractères non alphanumériques - Conversion de tout le texte en minuscules - Ajout d’autres catégories de sociétés connues Notez que pour certaines sociétés, aucun article n’a pu être trouvé, donc le nombre d’enregistrements est inférieur à 500. |
| Données des caractéristiques des restaurants | Jeu de métadonnées sur des restaurants et leurs caractéristiques, comme le type de gastronomie, le style de lieu et l'emplacement. Utilisation: utiliser ce jeu de données avec les deux autres jeux de données sur les restaurants, pour former et tester un système de recommandation. Recherche associée : Bache, K. and Lichman, M. (2013). Dépôt Machine Learning UCI. Irvine, CA: University of California, School of Information and Computer Science. |
| Evaluations des restaurants | Contient les notes attribuées par les consommateurs à des restaurants sur une échelle de 0 à 2. Utilisation: utiliser ce jeu de données avec les deux autres jeux de données sur les restaurants, pour former et tester un système de recommandation. Recherche associée : Bache, K. and Lichman, M. (2013). Dépôt Machine Learning UCI. Irvine, CA: University of California, School of Information and Computer Science. |
| Données des clients des restaurants | Jeu de données sur les clients, comprenant des données démographiques et des préférences. Utilisation: utiliser ce jeu de données avec les deux autres jeux de données sur les restaurants, pour former et tester un système de recommandation. Recherche associée : Bache, K. and Lichman, M. (2013). Dépôt Machine Learning UCI Irvine, Californie : University of California, School of Information and Computer Science. |
Nettoyer les ressources
Important
Vous pouvez utiliser les ressources que vous avez créées comme prérequis pour d’autres didacticiels et articles de guides pratiques Azure Machine Learning.
Tout supprimer
Si vous n’avez pas l’intention d’utiliser les éléments que vous avez créés, supprimez l’intégralité du groupe de ressources pour éviter des frais.
Dans le portail Azure, sélectionnez Groupes de ressources sur le côté gauche de la fenêtre.
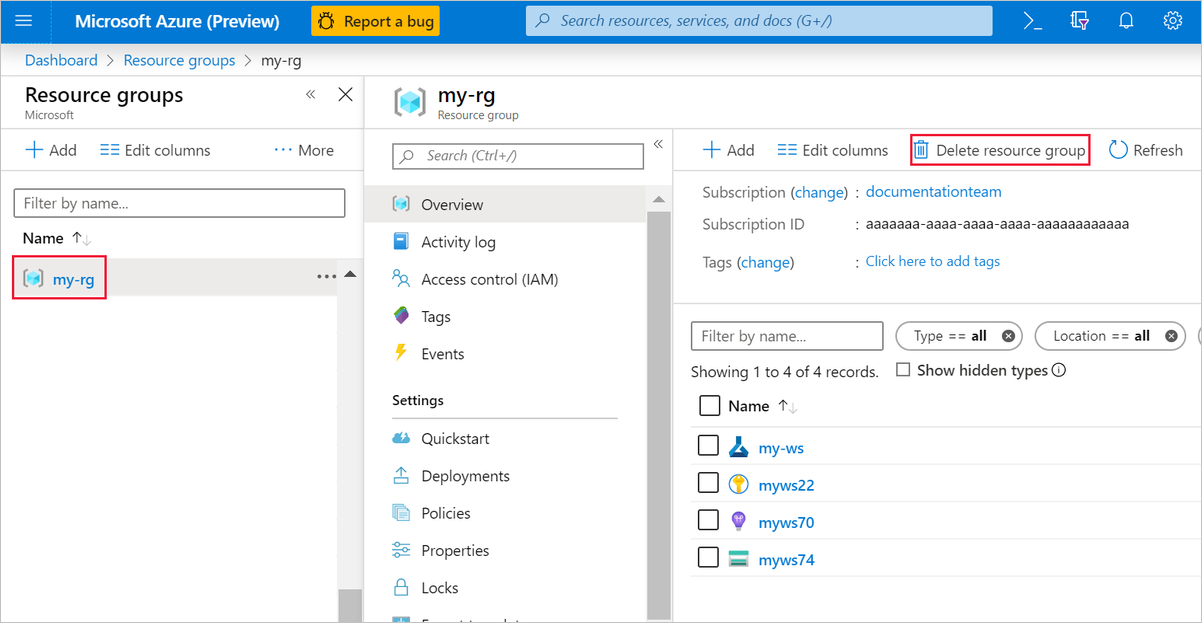
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
La suppression du groupe de ressources supprime également toutes les ressources créées dans le concepteur.
Supprimer des ressources individuelles
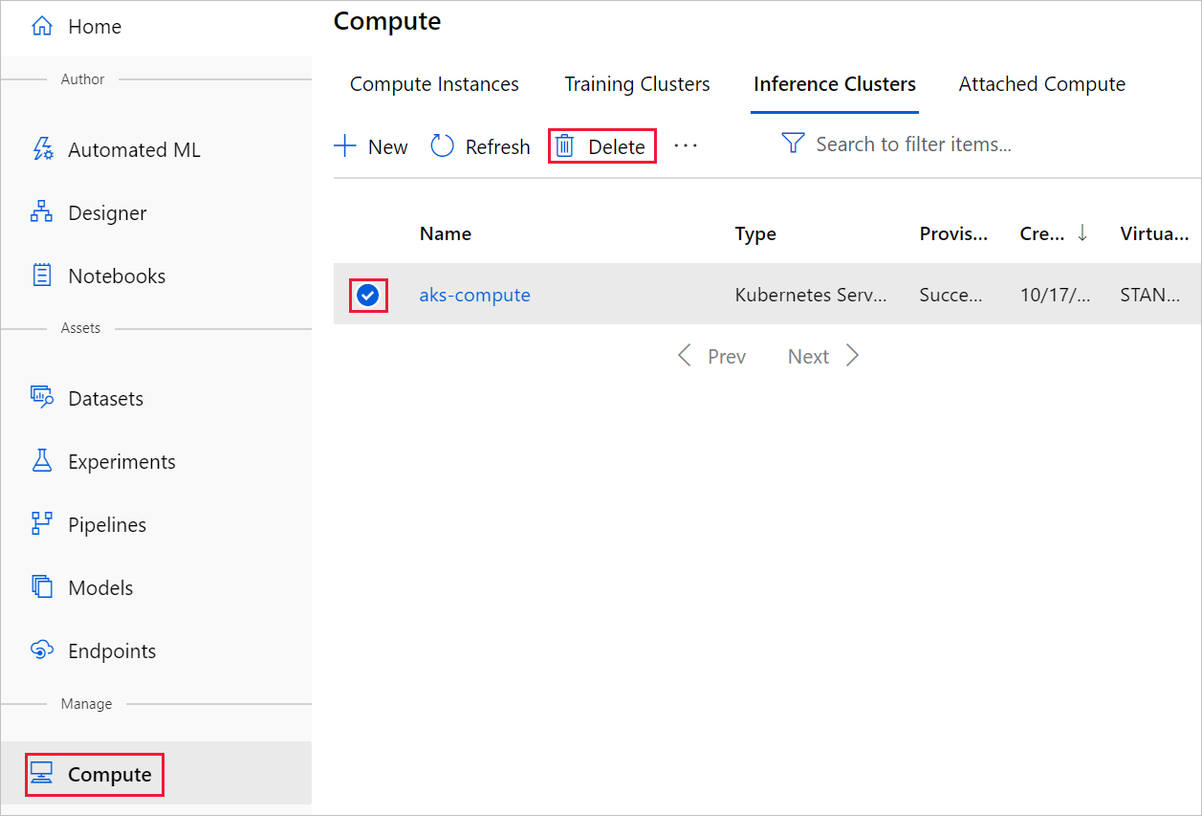
Dans le concepteur où vous avez créé votre expérience, supprimez des ressources individuelles en les sélectionnant, puis en sélectionnant le bouton Supprimer.
La cible de calcul que vous avez créée ici est automatiquement mise à l’échelle sur zéro nœud quand elle n’est pas utilisée. Cette action est effectuée pour réduire les frais. Si vous souhaitez supprimer la cible de calcul, procédez comme suit :
Vous pouvez désinscrire des jeux de données de votre espace de travail en sélectionnant chaque jeu de données, puis Annuler l’enregistrement.
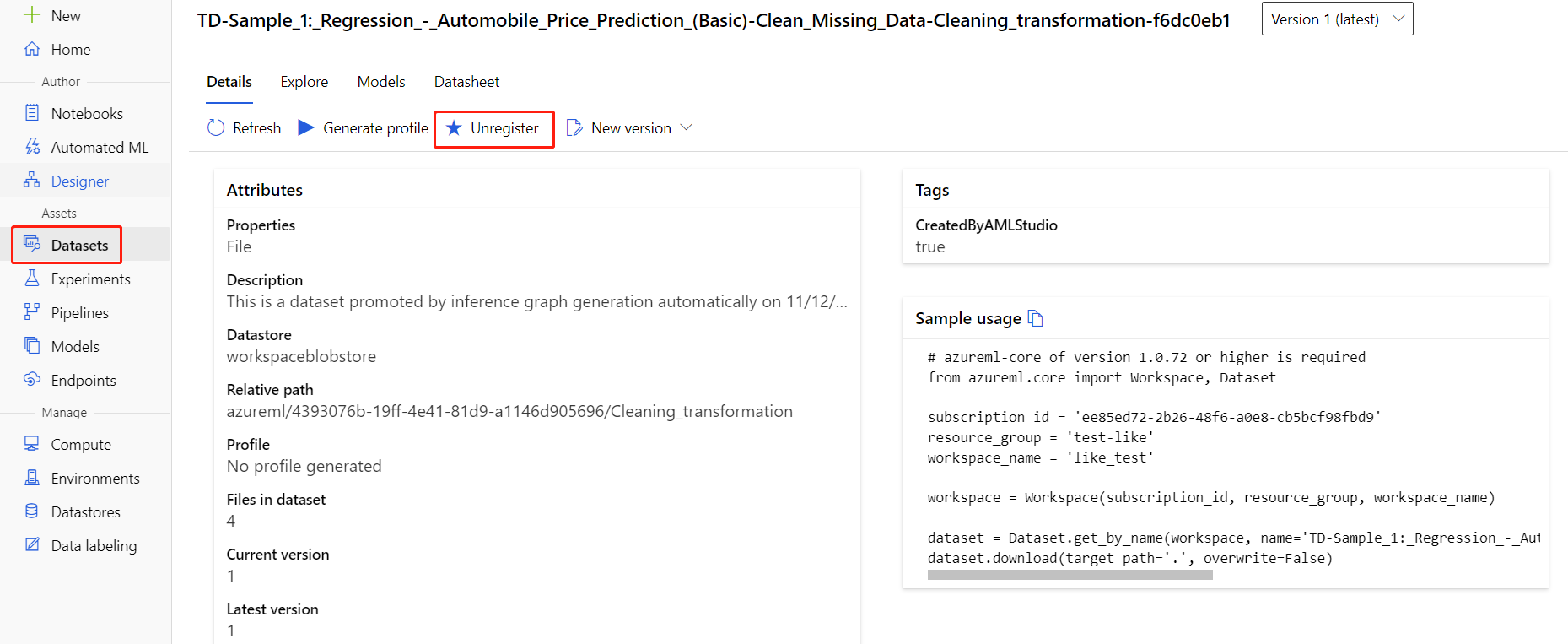
Pour supprimer un jeu de données, accédez au compte de stockage à l’aide du portail Azure ou de l’Explorateur Stockage Azure et supprimez manuellement ces ressources.
Étapes suivantes
Découvrez les principes fondamentaux de l’analytique prédictive et du Machine Learning à l’aide du Tutoriel : Prédire le prix de voitures avec le concepteur