Le TDSP est une méthodologie agile et itérative de science des données que vous pouvez utiliser pour fournir des solutions d'analyse prédictive et des applications d'IA de manière efficace. Le TDSP améliore la collaboration et l'apprentissage au sein de l'équipe en recommandant des moyens optimaux pour que les rôles de l'équipe travaillent ensemble. Le TDSP intègre les meilleures pratiques et les cadres de Microsoft et d'autres leaders du secteur pour aider votre équipe à mettre en œuvre efficacement des initiatives de science des données. Le TDSP vous permet de tirer pleinement parti de votre programme d'analyse.
Cet article présente une vue d'ensemble de la TDSP et de ses principaux composants. Il présente des conseils sur la façon d’implémenter le TDSP à l’aide des outils et de l’infrastructure Microsoft. Vous trouverez des ressources plus détaillées dans l’article.
Composants clés du processus TDSP
Le TDSP présente les composants clés suivants :
- Définition du cycle de vie de la science des données
- Structure de projet normalisée
- Infrastructure et des ressources idéales pour les projets de science des données.
- IA responsable : et un engagement en faveur de l'avancement de l'IA, motivé par des principes éthiques.
Cycle de vie de la science des données
Le TDSP propose un cycle de vie que vous pouvez utiliser pour structurer le développement de vos projets de science des données. Le cycle de vie décrit l’ensemble des étapes que suivent les projets réussis.
Vous pouvez combiner le processus TDSP basé sur des tâches avec d'autres cycles de vie des sciences des données, tels que le processus CRISP-DM (Cross Industry Standard Process for Data Mining), la découverte KDD (Knowledge Discovery in Databases) ou un autre processus personnalisé. À haut niveau, ces méthodologies ont beaucoup en commun.
Utilisez ce cycle de vie si votre projet de science des données fait partie d'une application intelligente. Les applications intelligentes déploient des modèles de Machine Learning ou d’intelligence artificielle pour l’analytique prédictive. Vous pouvez également utiliser ce processus pour les projets de science des données exploratoires et les projets d’analytique improvisée.
Le cycle de vie de la TDSP se compose de cinq étapes principales que votre équipe exécute de manière itérative. Ces étapes sont les suivantes :
- Présentation de l’entreprise
- Acquisition et compréhension des données
- Modélisation
- Déploiement
- Acceptation du client
Voici une représentation visuelle du cycle de vie TDSP :
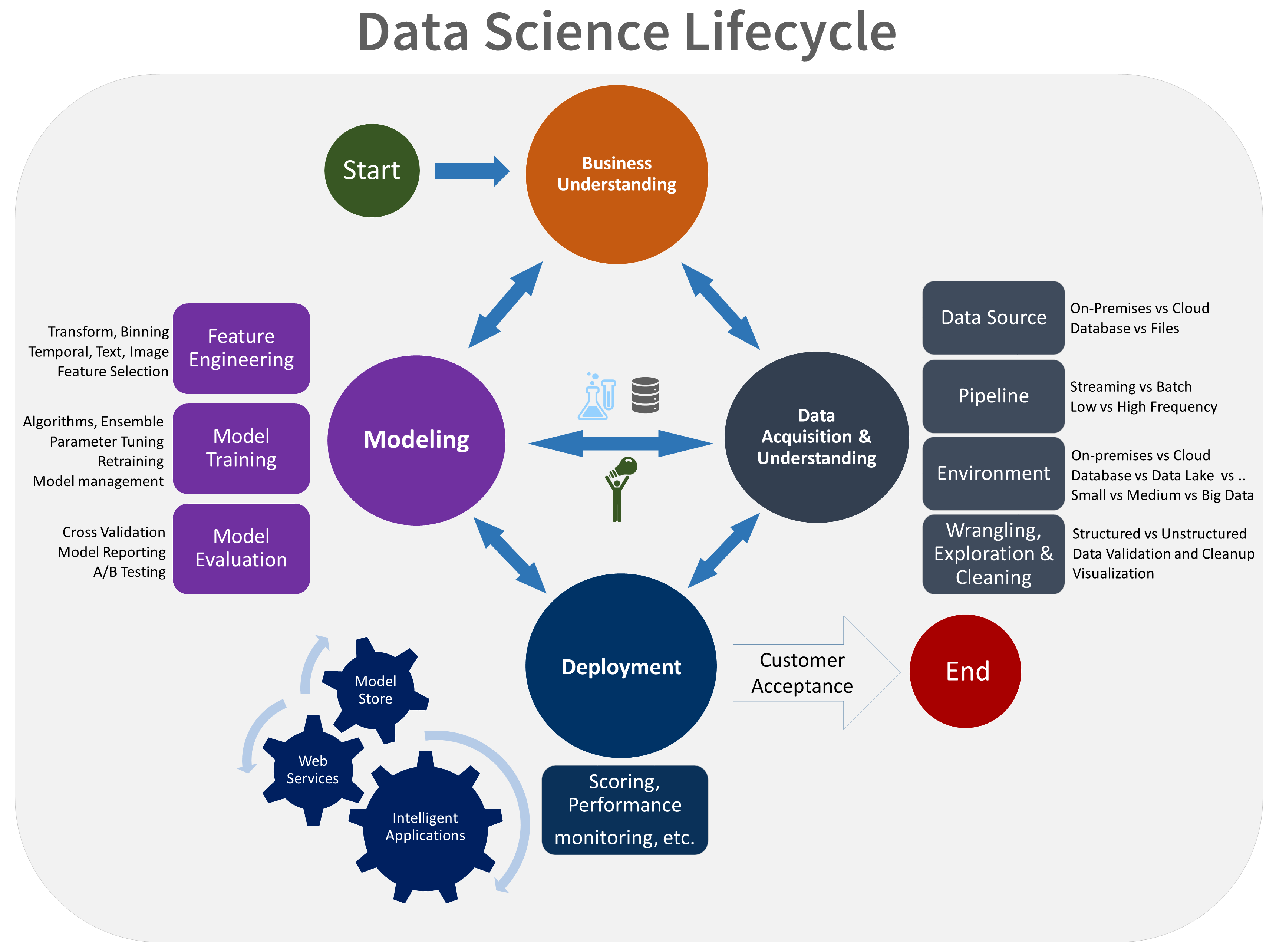
Pour plus d'informations sur les objectifs, les tâches et les artefacts de documentation de chaque étape, voir Le cycle de vie de la TDSP.
Ces tâches et artefacts s'alignent sur les rôles du projet, tels que le rôle de l'équipe de projet :
- Architecte de solution
- Chef de projet
- Ingénierie de données
- Scientifique des données
- Développeur d’applications
- Coordinateur de projet
Le diagramme suivant montre les tâches (en bleu) et les artefacts (en vert) qui correspondent à chaque étape du cycle de vie représenté sur l'axe horizontal et pour les rôles représentés sur l'axe vertical.

Structure de projet normalisée
Votre équipe peut utiliser l’infrastructure Azure pour organiser vos ressources de science des données.
Azure Machine Learning prend en charge la plateforme open source MLflow. Nous vous recommandons d'utiliser MLflow pour la gestion des projets de science des données et d'IA. MLflow est conçu pour gérer le cycle de vie complet du Machine Learning. Il entraîne et sert des modèles sur différentes plateformes, ce qui vous permet d'utiliser un ensemble cohérent d'outils, quel que soit l'endroit où se déroulent vos expériences. Vous pouvez utiliser MLflow localement sur votre ordinateur, sur une cible de calcul distante, sur une machine virtuelle ou sur une instance de calcul de machine learning.
MLflow se compose de plusieurs fonctionnalités clés :
Suivi des expériences : Vous pouvez utiliser MLflow pour garder une trace des expériences, y compris les paramètres, les versions de code, les mesures et les fichiers de sortie. Cette fonctionnalité vous aide à comparer différentes exécutions et à gérer efficacement le processus d'expérimentation.
Package code : Il fournit un format standardisé pour le package du code de machine learning, qui inclut les dépendances et les configurations. Cet empaquetage facilite la reproduction des séries et le partage de code avec d’autres utilisateurs.
Gérer les modèles : MLflow fournit des fonctionnalités pour gérer et versionner les modèles. Il prend en charge divers frameworks de machine learning afin que vous puissiez stocker, versionner et servir les modèles.
Servir et déployer des modèles : MLflow intègre des fonctionnalités de service et de déploiement de modèles afin que vous puissiez facilement déployer des modèles dans divers environnements.
Enregistrer les modèles : Vous pouvez gérer le cycle de vie d'un modèle, ce qui inclut les versions, les transitions d'étape et les annotations. Vous pouvez utiliser MLflow pour maintenir un magasin de modèles centralisé dans un environnement collaboratif.
API et interface utilisateur : dans Azure, MLflow est intégré à la version 2 de l'API Machine Learning, ce qui vous permet d'interagir avec le système de manière programmatique. Vous pouvez utiliser le portail Azure pour interagir avec une interface utilisateur.
MLflow simplifie et standardise le processus de développement de machine learning, de l'expérimentation au déploiement.
Machine Learning s'intègre aux référentiels Git, de sorte que vous pouvez utiliser des services compatibles avec Git, tels que GitHub, GitLab, Bitbucket, Azure DevOps ou un autre service compatible avec Git. En plus des ressources déjà suivies dans Machine Learning, votre équipe peut développer sa propre taxonomie au sein de son service compatible avec Git pour stocker d'autres données de projet, telles que :
- Documentation
- Données du projet : par exemple, le rapport final du projet
- Rapport de données : comme le dictionnaire de données ou les rapports sur la qualité des données.
- Modèle : tels que les rapports de modèle
- Code
- Préparation des données
- Développement d’un modèle
- l'opérationnalisation, qui comprend la sécurité et la conformité.
Infrastructure et ressources
La TDSP fournit des recommandations sur la façon de gérer l'infrastructure partagée d'analyse et de stockage dans les catégories suivantes :
- Systèmes de fichiers cloud pour stocker les ensembles de données
- Bases de données dans le cloud
- Clusters de big data qui utilisent SQL ou Spark
- Services Machine Learning et IA
Systèmes de fichiers cloud pour stocker les ensembles de données.
Les systèmes de fichiers cloud sont cruciaux pour le TDSP pour plusieurs raisons :
Stockage centralisé des données : Les systèmes de fichiers cloud offrent un emplacement centralisé pour stocker les ensembles de données, ce qui est essentiel pour la collaboration entre les membres de l'équipe de science des données. La centralisation garantit que tous les membres de l'équipe peuvent accéder aux données les plus récentes et réduit le risque de travailler avec des ensembles de données obsolètes ou incohérents.
Évolutivité : Les systèmes de fichiers cloud peuvent gérer de gros volumes de données, ce qui est courant dans les projets de science des données. Les systèmes de fichiers fournissent des solutions de stockage évolutives qui s'adaptent aux besoins du projet. Ils permettent aux équipes de stocker et de traiter des ensembles de données volumineux sans se soucier des limites matérielles.
Accessibilité : Avec les systèmes de fichiers cloud, vous pouvez accéder aux données depuis n'importe quel endroit disposant d'une connexion internet. Cet accès est important pour les équipes distribuées ou lorsque les membres de l'équipe doivent travailler à distance. Les systèmes de fichiers cloud facilitent une collaboration transparente et garantissent que les données sont toujours accessibles.
Sécurité et conformité : Les fournisseurs de cloud mettent souvent en œuvre des mesures de sécurité solides, qui comprennent le chiffrement, les contrôles d'accès et la conformité aux normes et réglementations du secteur. Des mesures de sécurité solides peuvent protéger les données sensibles et aider votre équipe à répondre aux exigences légales et réglementaires.
Contrôle des versions : Les systèmes de fichiers cloud comprennent souvent des fonctionnalités de contrôle de version, que les équipes peuvent utiliser pour suivre les modifications apportées aux ensembles de données au fil du temps. Le contrôle des versions est essentiel pour maintenir l'intégrité des données et reproduire les résultats dans les projets de science des données. Il vous aide également à auditer et à résoudre les problèmes qui surviennent.
Intégration avec des outils : Les systèmes de fichiers cloud peuvent s'intégrer de manière transparente à divers outils et plateformes de science des données. L'intégration des outils facilite l'ingestion, le traitement et l'analyse des données. Par exemple, Azure Storage s'intègre bien avec Machine Learning, Azure Databricks et d'autres outils de science des données.
Collaboration et partage : Les systèmes de fichiers cloud facilitent le partage des ensembles de données avec d'autres membres de l'équipe ou parties prenantes. Ces systèmes prennent en charge des fonctionnalités de collaboration telles que les dossiers partagés et la gestion des permissions. Les fonctionnalités de collaboration facilitent le travail en équipe et garantissent que les bonnes personnes ont accès aux données dont elles ont besoin.
Rentabilité : Les systèmes de fichiers dans le cloud peuvent être plus rentables que le maintien de solutions de stockage sur site. Les fournisseurs de cloud ont des modèles de tarification flexibles qui incluent des options de paiement à l'utilisation, ce qui peut aider à gérer les coûts en fonction de l'utilisation réelle et des besoins de stockage de votre projet de science des données.
Reprise après sinistre : Les systèmes de fichiers en nuage comprennent généralement des fonctionnalités de sauvegarde des données et de reprise après sinistre. Ces fonctionnalités permettent de protéger les données contre les défaillances matérielles, les suppressions accidentelles et d'autres catastrophes. Elles assurent la tranquillité d'esprit et la continuité des opérations de science des données.
Automatisation et intégration des workflows : Les systèmes de stockage dans le cloud peuvent s'intégrer dans des workflows automatisés, qui permettent un transfert transparent des données entre les différentes étapes du processus de science des données. L'automatisation peut contribuer à améliorer l'efficacité et à réduire les efforts manuels nécessaires à la gestion des données.
Ressources Azure recommandées pour les systèmes de fichiers dans le cloud
- Azure Blob Storage - Documentation complète sur Azure Blob Storage, un service de stockage d'objets évolutif pour les données non structurées.
- Azure Data Lake Storage - Informations sur Azure Data Lake Storage Gen2, conçu pour l'analyse des big data et prenant en charge des ensembles de données à grande échelle.
- Azure Files - Détails sur Azure Files, qui fournit des partages de fichiers entièrement gérés dans le cloud.
En résumé, les systèmes de fichiers cloud sont cruciaux pour le TDSP car ils fournissent des solutions de stockage évolutives, sécurisées et accessibles qui prennent en charge l'ensemble du cycle de vie des données. Les systèmes de fichiers en nuage permettent une intégration transparente des données provenant de diverses sources, ce qui favorise une acquisition et une compréhension complètes des données. Les scientifiques des données peuvent utiliser les systèmes de fichiers cloud pour stocker, gérer et accéder efficacement à de grands ensembles de données. Cette fonctionnalité est essentielle pour la formation et le déploiement de modèles de machine learning. Ces systèmes améliorent également la collaboration en permettant aux membres de l'équipe de partager et de travailler simultanément sur les données dans un environnement unifié. Les systèmes de fichiers cloud offrent des fonctionnalités de sécurité robustes qui contribuent à protéger les données et à les rendre conformes aux exigences réglementaires, ce qui est essentiel pour maintenir l'intégrité et la confiance dans les données.
Bases de données en nuage
Les bases de données cloud jouent un rôle essentiel dans la TDSP pour plusieurs raisons :
Évolutivité : Les bases de données cloud fournissent des solutions évolutives qui peuvent facilement se développer pour répondre aux besoins croissants en données d'un projet. L'évolutivité est cruciale pour les projets de science des données qui traitent fréquemment des ensembles de données volumineux et complexes. Les bases de données cloud peuvent gérer des charges de travail variables sans nécessiter d'intervention manuelle ou de mise à niveau du matériel.
Optimisation des performances : Les développeurs optimisent les performances des bases de données cloud en utilisant des fonctionnalités telles que l'indexation automatique, l'optimisation des requêtes et l'équilibrage des charges. Ces fonctionnalités permettent de s'assurer que la récupération et le traitement des données sont rapides et efficaces, ce qui est crucial pour les tâches de science des données qui nécessitent un accès aux données en temps réel ou quasi-temps réel.
Accessibilité et collaboration : Les équipes peuvent accéder aux données stockées dans les bases de données cloud depuis n'importe quel endroit. Cette accessibilité favorise la collaboration entre les membres de l'équipe qui peuvent être dispersés géographiquement. L'accessibilité et la collaboration sont importantes pour les équipes distribuées ou les personnes qui travaillent à distance. Les bases de données cloud prennent en charge les environnements multi-utilisateurs qui permettent un accès et une collaboration simultanés.
Intégration avec les outils de science des données : Les bases de données cloud s'intègrent de manière transparente à divers outils et plateformes de science des données. Par exemple, les bases de données cloud Azure s'intègrent bien avec Machine Learning, Power BI et d'autres outils d'analyse de données. Cette intégration rationalise le pipeline de données, de l'ingestion et du stockage à l'analyse et à la visualisation.
Sécurité et conformité : Les fournisseurs de cloud mettent en œuvre des mesures de sécurité robustes qui incluent le chiffrement des données, les contrôles d'accès et la conformité aux normes et réglementations du secteur. Les mesures de sécurité protègent les données sensibles et aident votre équipe à répondre aux exigences légales et réglementaires. Les fonctionnalités de sécurité sont essentielles pour maintenir l'intégrité et la confidentialité des données.
Rentabilité : Les bases de données cloud fonctionnent souvent selon un modèle de paiement à l'utilisation, ce qui peut être plus rentable que de maintenir des systèmes de base de données sur site. Cette souplesse de tarification permet aux organisations de gérer efficacement leur budget et de ne payer que pour les ressources de stockage et de calcul qu'elles utilisent.
Sauvegardes automatiques et reprise après sinistre : Les bases de données cloud offrent des solutions de sauvegarde automatique et de reprise après sinistre. Ces solutions permettent d'éviter la perte de données en cas de défaillance matérielle, de suppression accidentelle ou d'autres catastrophes. La fiabilité est essentielle pour maintenir la continuité et l'intégrité des données dans les projets de science des données.
Traitement des données en temps réel : De nombreuses bases de données cloud prennent en charge le traitement et l'analyse des données en temps réel, ce qui est essentiel pour les tâches de science des données qui nécessitent les informations les plus récentes. Cette capacité aide les scientifiques des données à prendre des décisions opportunes sur la base des données disponibles les plus récentes.
Intégration des données : Les bases de données cloud peuvent facilement s'intégrer à d'autres sources de données, bases de données, lacs de données et flux de données externes. L'intégration aide les data scientists à combiner des données provenant de sources multiples et permet d'obtenir une vue d'ensemble et une analyse plus sophistiquée.
Flexibilité et variété : Les bases de données cloud se présentent sous différentes formes, telles que les bases de données relationnelles, les bases de données NoSQL et les entrepôts de données. Cette variété permet aux équipes de science des données de choisir le type de base de données le mieux adapté à leurs besoins spécifiques, qu'il s'agisse de stockage de données structurées, de traitement de données non structurées ou d'analyse de données à grande échelle.
Prise en charge des analyses avancées : Les bases de données cloud sont souvent accompagnées d'une prise en charge intégrée de l'analytique avancée et du machine learning. Par exemple, Azure SQL Database propose des services intégrés de machine learning. Ces services aident les scientifiques à effectuer des analyses avancées directement dans l'environnement de la base de données.
Ressources Azure recommandées pour les bases de données cloud.
- Azure SQL Database - Documentation sur Azure SQL Database, un service de base de données relationnelle entièrement géré.
- Azure Cosmos DB - Informations sur Azure Cosmos DB, un service de base de données multi-modèle distribué à l'échelle mondiale.
- Azure Database for PostgreSQL - Guide sur Azure Database for PostgreSQL, un service de base de données géré pour le développement et le déploiement d'applications.
- Azure Database for MySQL - Détails sur Azure Database for MySQL, un service géré pour les bases de données MySQL.
En résumé, les bases de données cloud sont cruciales pour TDSP car elles fournissent des solutions de stockage et de gestion des données évolutives, fiables et efficaces qui soutiennent les projets axés sur les données. Elles facilitent l'intégration transparente des données, ce qui permet aux scientifiques d'ingérer, de prétraiter et d'analyser de vastes ensembles de données provenant de diverses sources. Les bases de données cloud permettent d'effectuer des requêtes et des traitements de données rapides, ce qui est essentiel pour développer, tester et déployer des modèles de machine learning. De plus, les bases de données cloud améliorent la collaboration en fournissant une plateforme centralisée permettant aux membres de l'équipe d'accéder aux données et d'y travailler simultanément. Enfin, les bases de données cloud offrent des fonctionnalités de sécurité avancées et une prise en charge de la conformité pour que les données restent protégées et conformes aux normes réglementaires, ce qui est essentiel pour maintenir l'intégrité et la confiance dans les données.
Clusters de big data qui utilisent SQL ou Spark
Les clusters de big data, tels que ceux qui utilisent SQL ou Spark, sont fondamentaux pour le TDSP pour plusieurs raisons :
Traitement de grands volumes de données : Les clusters de big data sont conçus pour traiter efficacement de grands volumes de données. Les projets de science des données impliquent souvent des ensembles de données massifs qui dépassent la capacité des bases de données traditionnelles. Les clusters de big data basés sur SQL et Spark peuvent gérer et traiter ces données à l'échelle.
Calcul distribué : Les clusters big data utilisent l'informatique distribuée pour répartir les données et les tâches de calcul sur plusieurs nœuds. La capacité de traitement parallèle accélère considérablement le traitement des données et les tâches d'analyse, ce qui est essentiel pour obtenir des aperçus opportuns dans les projets de science des données.
Évolutivité : Les clusters de big data offrent une grande évolutivité, à la fois horizontalement par l'ajout de nœuds et verticalement par l'augmentation de la puissance des nœuds existants. L'évolutivité permet de s'assurer que l'infrastructure de données évolue avec les besoins du projet en gérant des données de plus en plus volumineuses et complexes.
Intégration avec des outils de science des données : Les clusters de big data s'intègrent bien à divers outils et plateformes de science des données. Par exemple, Spark s'intègre parfaitement à Hadoop, et les clusters SQL fonctionnent avec divers outils d'analyse de données. L'intégration facilite un workflow fluide, de l'ingestion des données à l'analyse et à la visualisation.
Analyse avancée : Les clusters de big data prennent en charge l'analytique avancée et le machine learning. Par exemple, Spark fournit les bibliothèques intégrées suivantes :
- Machine learning, MLlib.
- Traitement des graphes, GraphX
- Traitement des flux, Spark Streaming
Ces capacités aident les data scientists à effectuer des analyses complexes directement au sein du cluster.
Traitement des données en temps réel : Les clusters de big data, en particulier ceux qui utilisent Spark, prennent en charge le traitement des données en temps réel. Cette capacité est cruciale pour les projets qui nécessitent une analyse des données et une prise de décision à la minute près. Le traitement en temps réel est utile dans des scénarios tels que la détection des fraudes, les recommandations en temps réel et la tarification dynamique.
Transformation des données et extraction, transformation, chargement (ETL) : les clusters big data sont idéaux pour les processus de transformation des données et d'ETL. Ils peuvent gérer efficacement des tâches complexes de transformation, de nettoyage et d'agrégation des données, qui sont souvent nécessaires avant que les données puissent être analysées.
Rentabilité : Les clusters de big data peuvent être rentables, en particulier lorsque vous utilisez des solutions basées sur le cloud comme Azure Databricks et d'autres services cloud. Ces services proposent des modèles de tarification flexibles qui incluent le paiement à l'utilisation, ce qui peut s'avérer plus économique que de maintenir une infrastructure big data locale.
Tolérance aux pannes : Les clusters de big data sont conçus en tenant compte de la tolérance aux pannes. Ils répliquent les données entre les nœuds afin de garantir que le système reste opérationnel même si certains nœuds tombent en panne. Cette fiabilité est essentielle pour maintenir l'intégrité et la disponibilité des données dans les projets de science des données.
Intégration des lacs de données : Les clusters de big data s'intègrent souvent de manière transparente aux lacs de données, qui permettent aux data scientists d'accéder à diverses sources de données et de les analyser de manière unifiée. L'intégration favorise des analyses plus complètes en prenant en charge une combinaison de données structurées et non structurées.
Traitement basé sur SQL : Pour les data scientists qui sont familiers avec SQL, les clusters big data qui fonctionnent avec des requêtes SQL, comme Spark SQL ou SQL on Hadoop, offrent une interface familière pour interroger et analyser les big data. Cette facilité d'utilisation peut accélérer le processus d'analyse et le rendre plus accessible à un plus grand nombre d'utilisateurs.
Collaboration et partage : Les clusters de big data prennent en charge les environnements collaboratifs dans lesquels plusieurs data scientists et analystes peuvent travailler ensemble sur les mêmes ensembles de données. Ils offrent des fonctionnalités de partage de code, de carnets de notes et de résultats qui favorisent le travail d'équipe et le partage des connaissances.
Sécurité et conformité : Les clusters de big data offrent de solides fonctionnalités de sécurité, telles que le chiffrement des données, les contrôles d'accès et la conformité aux normes du secteur. Les fonctionnalités de sécurité protègent les données sensibles et aident votre équipe à respecter les exigences réglementaires.
Ressources Azure recommandées pour les clusters de big data
- Apache Spark dans l'apprentissage machine : L'intégration de Machine Learning avec Azure Synapse Analytics permet d'accéder facilement aux ressources de calcul distribuées grâce au framework Apache Spark.
- Synapse Analytics : Documentation complète sur Synapse Analytics, qui intègre le big data et l'entreposage de données.
En résumé, les clusters de big data, qu'ils soient SQL ou Spark, sont cruciaux pour le TDSP, car ils fournissent la puissance de calcul et l'évolutivité nécessaires pour traiter efficacement de grandes quantités de données. Les clusters de big data permettent aux data scientists d'effectuer des requêtes complexes et des analyses avancées sur de grands ensembles de données qui facilitent les aperçus profonds, et le développement de modèles précis. Lorsque vous utilisez l'informatique distribuée, ces clusters permettent un traitement et une analyse rapides des données, ce qui accélère le workflow global de la science des données. Les clusters de big data prennent également en charge l'intégration transparente avec diverses sources de données et divers outils, ce qui améliore la capacité d'ingérer, de traiter et d'analyser des données provenant de plusieurs environnements. Les clusters de big data favorisent également la collaboration et la reproductibilité en fournissant une plateforme unifiée où les équipes peuvent partager efficacement les ressources, les workflows et les résultats.
Services Machine Learning et IA
Les services d'IA et de machine learning (ML) font partie intégrante du TDSP pour plusieurs raisons :
Analyse avancée : Les services d'IA et d'apprentissage automatique permettent des analyses avancées. Les scientifiques des données peuvent utiliser l'analyse avancée pour découvrir des modèles complexes, faire des prédictions et générer des aperçus qui ne sont pas possibles avec les méthodes d'analyse traditionnelles. Ces capacités avancées sont essentielles pour créer des solutions de science des données à fort impact.
Automatisation des tâches répétitives : Les services d'IA et de ML peuvent automatiser les tâches répétitives, telles que le nettoyage des données, l'ingénierie des fonctionnalités et l'entraînement des modèles. L'automatisation permet de gagner du temps et aide les data scientists à se concentrer sur des aspects plus stratégiques du projet, ce qui améliore la productivité globale.
Amélioration de la précision et des performances : Les modèles de ML peuvent améliorer la précision et la performance des prédictions et des analyses en apprenant à partir des données. Ces modèles peuvent s'améliorer continuellement au fur et à mesure qu'ils sont exposés à davantage de données, ce qui permet de prendre de meilleures décisions et d'obtenir des résultats plus fiables.
Évolutivité : Les services d'IA et de ML fournis par les plateformes cloud, tels que le Machine Learning, sont hautement évolutifs. Ils peuvent gérer de gros volumes de données et des calculs complexes, ce qui aide les équipes de science des données à faire évoluer leurs solutions pour répondre à des demandes croissantes sans se soucier des limites de l'infrastructure sous-jacente.
Intégration avec d'autres outils : Les services d'IA et de ML s'intègrent de manière transparente à d'autres outils et services de l'écosystème Microsoft, tels qu'Azure Data Lake, Azure Databricks et Power BI. L'intégration prend en charge un workflow rationalisé depuis l'ingestion et le traitement des données jusqu'au déploiement et à la visualisation des modèles.
Déploiement et gestion des modèles : Les services AI et ML fournissent des outils robustes pour déployer et gérer les modèles de machine learning en production. Des fonctionnalités telles que le contrôle des versions, la surveillance et le recyclage automatisé permettent de s'assurer que les modèles restent précis et efficaces au fil du temps. Cette approche simplifie la maintenance des solutions de ML.
Traitement en temps réel : Les services d'IA et de ML prennent en charge le traitement des données et la prise de décision en temps réel. Le traitement en temps réel est essentiel pour les applications qui nécessitent des aperçus et des actions immédiats, comme la détection des fraudes, la tarification dynamique et les systèmes de recommandation.
Personnalisation et flexibilité : Les services d'IA et de ML offrent une gamme d'options personnalisables, allant de modèles et d'API préconstruits à des cadres permettant de construire des modèles personnalisés à partir de zéro. Cette flexibilité aide les équipes de science des données à adapter les solutions aux besoins spécifiques de l'entreprise et aux cas d'utilisation.
Accès à des algorithmes de pointe : Les services d'IA et de ML permettent aux scientifiques des données d'accéder à des algorithmes et des technologies de pointe développés par des chercheurs de premier plan. Cet accès garantit que l'équipe peut utiliser les dernières avancées en matière d'IA et de ML pour ses projets.
Collaboration et partage : Les plateformes d'IA et de ML prennent en charge les environnements de développement collaboratif, où plusieurs membres de l'équipe peuvent travailler ensemble sur le même projet, partager le code et reproduire des expériences. La collaboration améliore le travail d'équipe et contribue à garantir la cohérence du développement des modèles.
Rentabilité : Les services d'IA et de ML sur le cloud peuvent être plus rentables que la construction et la maintenance de solutions sur site. Les fournisseurs de cloud ont des modèles de tarification flexibles qui incluent des options de paiement à l'utilisation, ce qui peut réduire les coûts et optimiser l'utilisation des ressources.
Sécurité et conformité renforcées : Les services d'IA et de ML s'accompagnent de fonctionnalités de sécurité robustes, qui incluent le chiffrement des données, des contrôles d'accès sécurisés et la conformité aux normes et réglementations du secteur. Ces fonctionnalités permettent de protéger vos données et vos modèles et de répondre aux exigences légales et réglementaires.
Modèles et API préconstruits : De nombreux services d'IA et de ML fournissent des modèles et des API préconstruits pour des tâches courantes telles que le traitement du langage naturel, la reconnaissance d'images et la détection d'anomalies. Ces solutions préconstruites peuvent accélérer le développement et le déploiement et aider les équipes à intégrer rapidement des capacités d'IA dans leurs applications.
Expérimentation et prototypage : Les plateformes d'IA et de ML fournissent des environnements d'expérimentation et de prototypage rapides. Les scientifiques des données peuvent rapidement tester différents algorithmes, paramètres et ensembles de données pour trouver la meilleure solution. L'expérimentation et le prototypage favorisent une approche itérative du développement de modèles.
Ressources Azure recommandées pour les services d'intelligence artificielle et de ML.
L'apprentissage automatique est la principale ressource que nous recommandons pour l'application de la science des données et le TDSP. Azure fournit également des services d'IA qui proposent des modèles d'IA prêts à l'emploi pour des applications spécifiques.
- Machine Learning : La page de documentation principale pour Machine Learning qui couvre la configuration, l'entraînement des modèles, le déploiement, etc.
- Services Azure AI : Informations sur les services d'IA qui fournissent des modèles d'IA préconstruits pour la vision, la parole, le langage et les tâches de prise de décision.
En résumé, les services d'IA et de ML sont cruciaux pour le TDSP, car ils fournissent des outils et des cadres puissants qui rationalisent le développement, la formation et le déploiement de modèles d'apprentissage automatique. Ces services automatisent des tâches complexes telles que la sélection des algorithmes et le réglage des hyperparamètres, ce qui accélère considérablement le processus de développement des modèles. Ces services fournissent également une infrastructure évolutive qui aide les scientifiques des données à traiter efficacement les grands ensembles de données et les tâches à forte intensité de calcul. Les outils d'IA et de ML s'intègrent de manière transparente aux autres services Azure et améliorent l'ingestion des données, le prétraitement et le déploiement des modèles. L'intégration permet d'assurer un workflow fluide de bout en bout. Ces services favorisent également la collaboration et la reproductibilité. Les équipes peuvent partager des aperçus et expérimenter efficacement les résultats et les modèles tout en maintenant des normes élevées de sécurité et de conformité.
IA responsable
Avec les solutions d'IA ou de ML, Microsoft promeut des outils d'IA responsable au sein de ses solutions d'IA et de ML. Ces outils prennent en charge la norme Microsoft Responsible AI Standard. Votre charge de travail doit tout de même traiter individuellement les préjudices liés à l'IA.
Citations examinées par les pairs
La TDSP est une méthodologie bien établie que les équipes utilisent dans le cadre des engagements de Microsoft. La TDSP est documentée et étudiée dans la littérature évaluée par les pairs. Les citations permettent d'étudier les fonctionnalités et les applications de la TDSP. Pour plus d'informations et une liste de citations, voir Le cycle de vie de la TDSP.