Tutoriel : utiliser le concepteur pour déployer un modèle Machine Learning
Dans la première partie du tutoriel, vous avez entraîné un modèle de régression linéaire qui prédit le prix des voitures. Dans cette deuxième partie, vous utilisez le concepteur Azure Machine Learning pour déployer le modèle afin que d’autres puissent l’utiliser.
Remarque
Le concepteur prend en charge deux types de composants : les composants prédéfinis classiques (v1) et les composants personnalisés (v2). Ces deux types de composants ne sont PAS compatibles.
Les composants prédéfinis classiques fournissent principalement des composants prédéfinis utilisés pour le traitement des données et les tâches de Machine Learning traditionnelles telles que la régression et la classification. Ce type de composant continue d’être pris en charge, mais aucun nouveau composant n’est ajouté.
Les composants personnalisés vous permettent d’encapsuler votre propre code en tant que composant. Ils vous permettent de partager des composants dans des espaces de travail et de créer en toute transparence dans des interfaces Studio Machine Learning, CLI v2 et le Kit de développement logiciel (SDK) v2.
Pour les nouveaux projets, nous vous conseillons d’utiliser des composants personnalisés compatibles avec Azure Machine Learning v2 et de continuer à recevoir les nouvelles mises à jour.
Cet article s’applique aux composants classiques et prédéfinis. Il ne concerne pas l’interface CLI v2 et le Kit de développement logiciel (SDK) v2.
Dans ce tutoriel, vous allez :
- Créez un pipeline d’inférence en temps réel.
- Créez un cluster d’inférence.
- Déployez le point de terminaison en temps réel.
- Testez le point de terminaison en temps réel.
Prérequis
Suivez la première partie du tutoriel pour découvrir comment entraîner et évaluer un modèle Machine Learning dans le concepteur.
Important
Si vous ne voyez pas les éléments graphiques mentionnés dans ce document, tels que les boutons dans Studio ou le concepteur, vous ne disposez peut-être pas du niveau d’autorisations approprié pour l’espace de travail. Contactez votre administrateur d’abonnement Azure pour vérifier que le niveau d’accès est correct. Pour plus d’informations, consultez Gérer les utilisateurs et les rôles.
Créer un pipeline d’inférence en temps réel
Pour déployer votre pipeline, vous devez d’abord convertir le pipeline d’entraînement en pipeline d’inférence en temps réel. Ce processus supprime les composants de formation et ajoute les entrées et sorties de service web pour gérer les demandes.
Remarque
La fonctionnalité Créer un pipeline d’inférence prend en charge les pipelines d’entraînement qui contiennent uniquement les composants intégrés du concepteur et qui ont un composant comme Entraîner le modèle qui génère le modèle entraîné.
Créer un pipeline d’inférence en temps réel
Sélectionnez Pipelines dans le volet de navigation latéral, puis ouvrez le travail de pipeline que vous avez créé. Sur la page de détails, au-dessus du canevas du pipeline, sélectionnez les points de suspension ... puis choisissez Créer un pipeline d’inférence>Pipeline d’inférence en temps réel.
Votre nouveau pipeline ressemble maintenant à ceci :
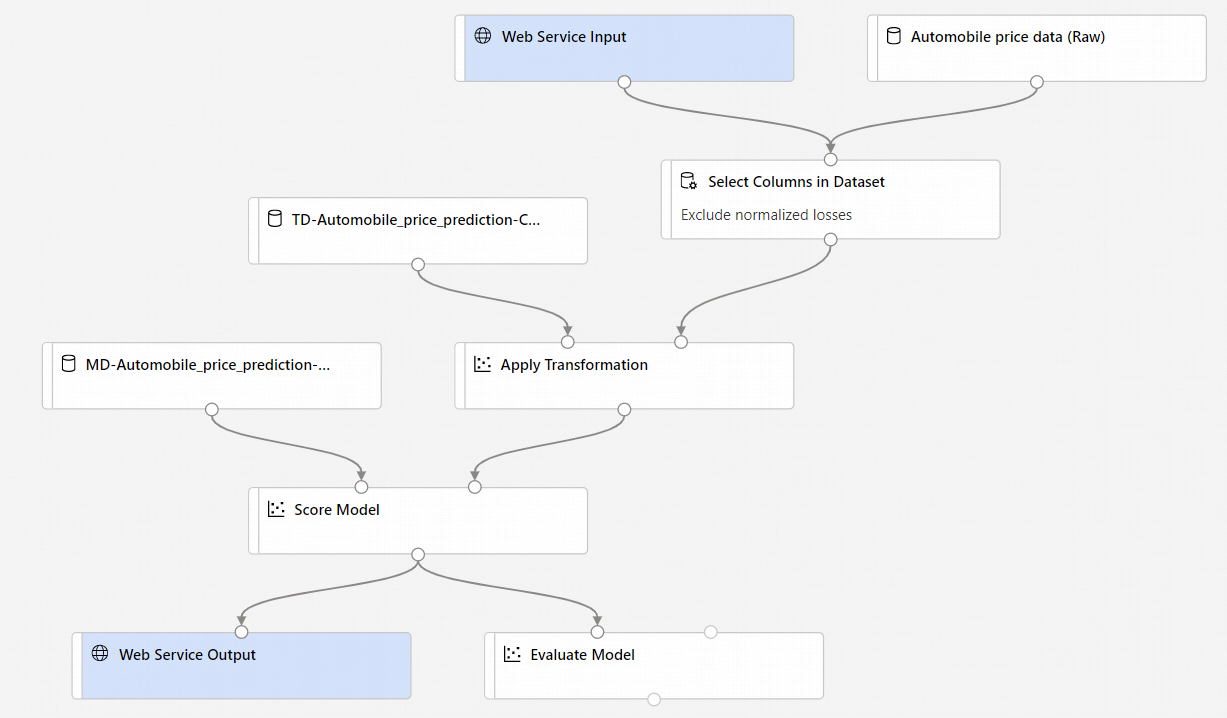
Quand vous sélectionnez Créer un pipeline d’inférence, plusieurs choses se produisent :
- Le modèle formé est stocké sous la forme d’un composant Jeux de données dans la palette de composants. Vous pouvez le trouver sous Mes modèles.
- Des composants de formation, comme Effectuer l’apprentissage du modèle et Fractionner les données sont supprimés.
- Le modèle entraîné enregistré est rajouté au pipeline.
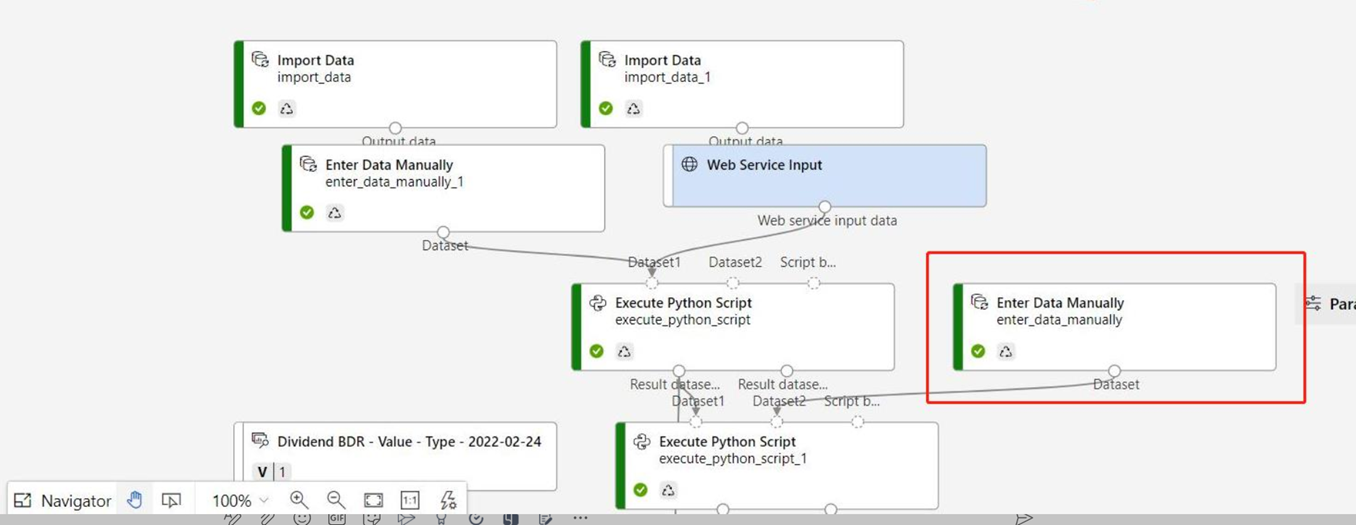
- Les composants Entrée du service web et Sortie du service web sont ajoutés. Ces composants montrent l’emplacement où les données utilisateur entrent dans le pipeline ainsi que l’emplacement où ces données sont renvoyées.
Remarque
Par défaut, le composant Entrée du service web attend le même schéma de données que les données de sortie du composant qui se connectent au même port en aval. Dans cet exemple, le composant Entrée du service web et le jeu de données Données sur le prix des véhicules automobiles (brutes) se connectent au même composant en aval. Par conséquent, le composant Entrée du service web attend le même schéma de données que le jeu de données Données sur le prix des véhicules automobiles (brutes) et la colonne variable cible
priceest incluse dans le schéma. Toutefois, lorsque vous attribuez un score aux données, vous ne connaissez pas les valeurs des variables cibles. Dans ce cas, vous pouvez supprimer la colonne variable cible dans le pipeline d’inférence à l’aide du composant Sélectionner des colonnes dans le jeu de données. Vérifiez que la sortie du composant Sélectionner des colonnes dans le jeu de données supprimant la colonne variable cible est connectée au même port que la sortie du composant Entrée du service web.Sélectionnez Configurer et soumettre, puis utilisez la même cible de calcul et la même expérience que durant la première partie.
S’il s’agit du premier travail, l’exécution de votre pipeline peut prendre 20 minutes. Les paramètres de calcul par défaut ont une taille de nœud minimale de 0, ce qui signifie que le concepteur doit allouer des ressources après une période d’inactivité. Les travaux de pipeline répétés prennent moins de temps dans la mesure où les ressources de calcul sont déjà allouées. Par ailleurs, le concepteur utilise les résultats mis en cache pour chaque composant afin d’améliorer l’efficacité.
Accédez au détail du travail du pipeline d’inférence en temps réel en sélectionnant Détails du travail dans le volet gauche.
Sélectionnez Déployer sur la page des détails du travail.
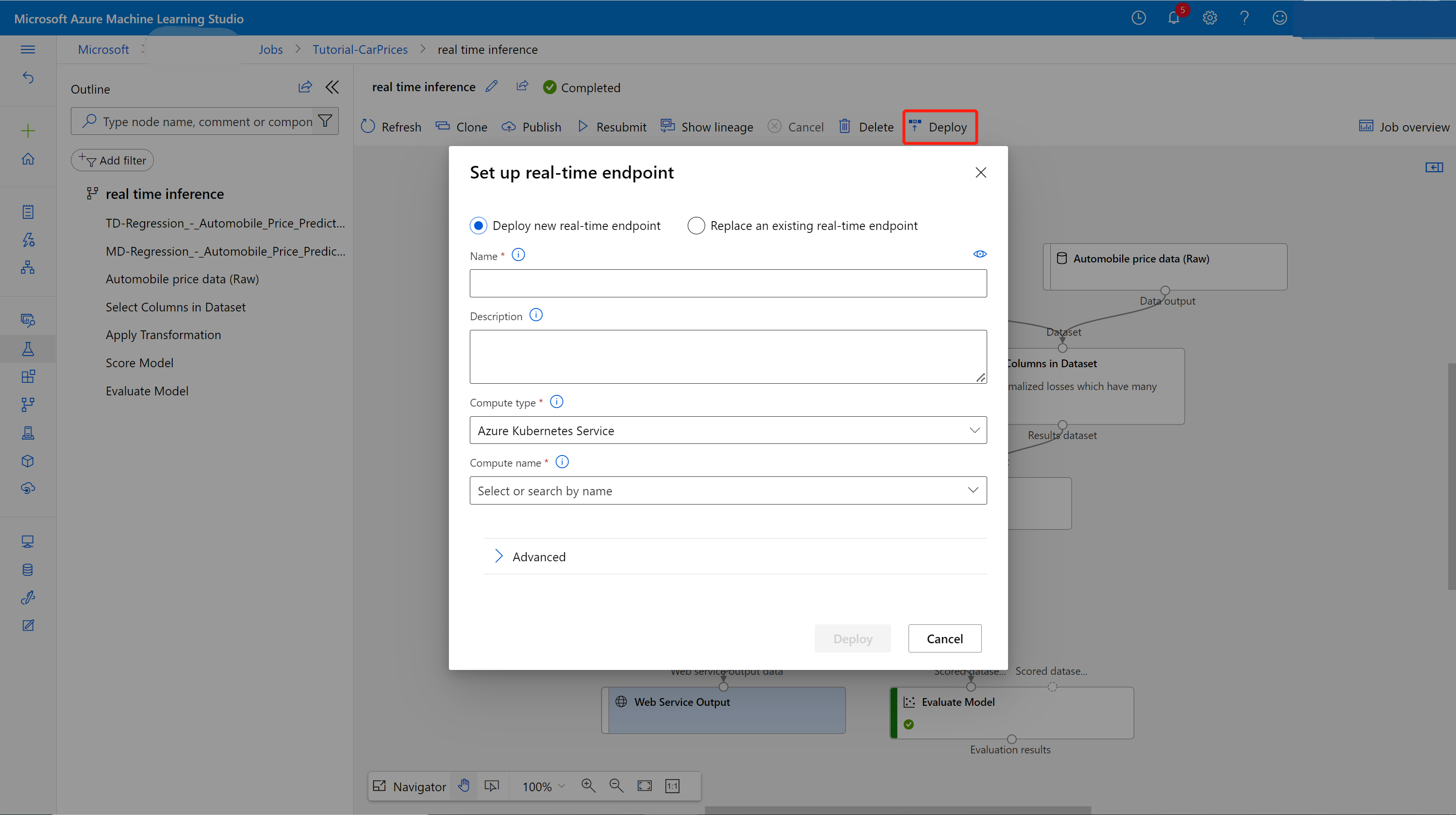


Créer un cluster d’inférence
Dans la boîte de dialogue qui s’affiche, vous pouvez sélectionner n’importe quel cluster AKS (Azure Kubernetes Service) existant sur lequel déployer votre modèle. Si vous n’avez pas de cluster AKS, utilisez les étapes suivantes pour en créer un.
Accédez à la page Calcul en sélectionnant Calcul dans la boîte de dialogue.
Dans le ruban de navigation, sélectionnez Clusters Kubernetes>+ Nouveau.
Dans le volet Cluster d’inférence, configurez un nouveau service Kubernetes.
Entrez aks-compute pour Nom du calcul.
Sélectionnez une région proche disponible pour Région.
Sélectionnez Create (Créer).
Notes
La création d’un service AKS prend environ 15 minutes. Vous pouvez vérifier l’état de provisionnement dans la page Clusters d’inférence.
Déployer le point de terminaison en temps réel
Une fois l’approvisionnement du service AKS terminé, revenez au pipeline d’inférence en temps réel pour terminer le déploiement.
Sélectionnez Déployer au-dessus du canevas.
Sélectionnez Déployer un nouveau point de terminaison en temps réel.
Sélectionnez le cluster AKS que vous avez créé.
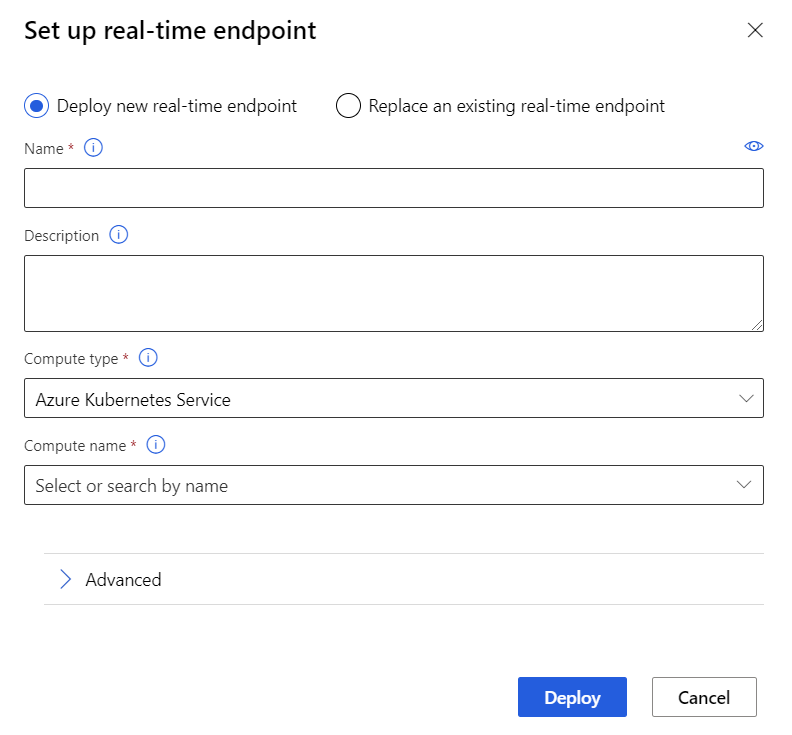
Vous pouvez également changer le paramètre Avancé pour votre point de terminaison en temps réel.
Paramètre avancé Description Activer les diagnostics et la collecte de données Application Insights Permet à Azure Application Insights de collecter des données à partir des points de terminaison déployés.
Par défaut : false.Délai d’expiration du scoring Délai d’expiration en millisecondes à appliquer pour les appels de scoring au service web.
Par défaut : 60000.Mise à l’échelle automatique activée Autorise la mise à l’échelle automatique du service web.
Par défaut : true.Nb min. de réplicas Nombre minimal de conteneurs à utiliser lors de la mise à l’échelle automatique de ce service web.
Par défaut : 1.Nb max. de réplicas Nombre maximal de conteneurs à utiliser lors de la mise à l’échelle automatique de ce service web.
Par défaut : 10.Utilisation cible Utilisation cible (en pourcentage) que la mise à l’échelle automatique doit tenter de gérer pour ce service web.
Par défaut : 70.Période d’actualisation Fréquence (en secondes) à laquelle la mise à l’échelle automatique tente de mettre à l’échelle ce service web.
Par défaut : 1.Capacité de réserve de processeur Nombre de cœurs de processeur à allouer pour ce service web.
Par défaut : 0,1.Capacité de réserve de mémoire Quantité de mémoire (en Go) à allouer à ce service web.
Par défaut : 0,5.Sélectionnez Déployer.
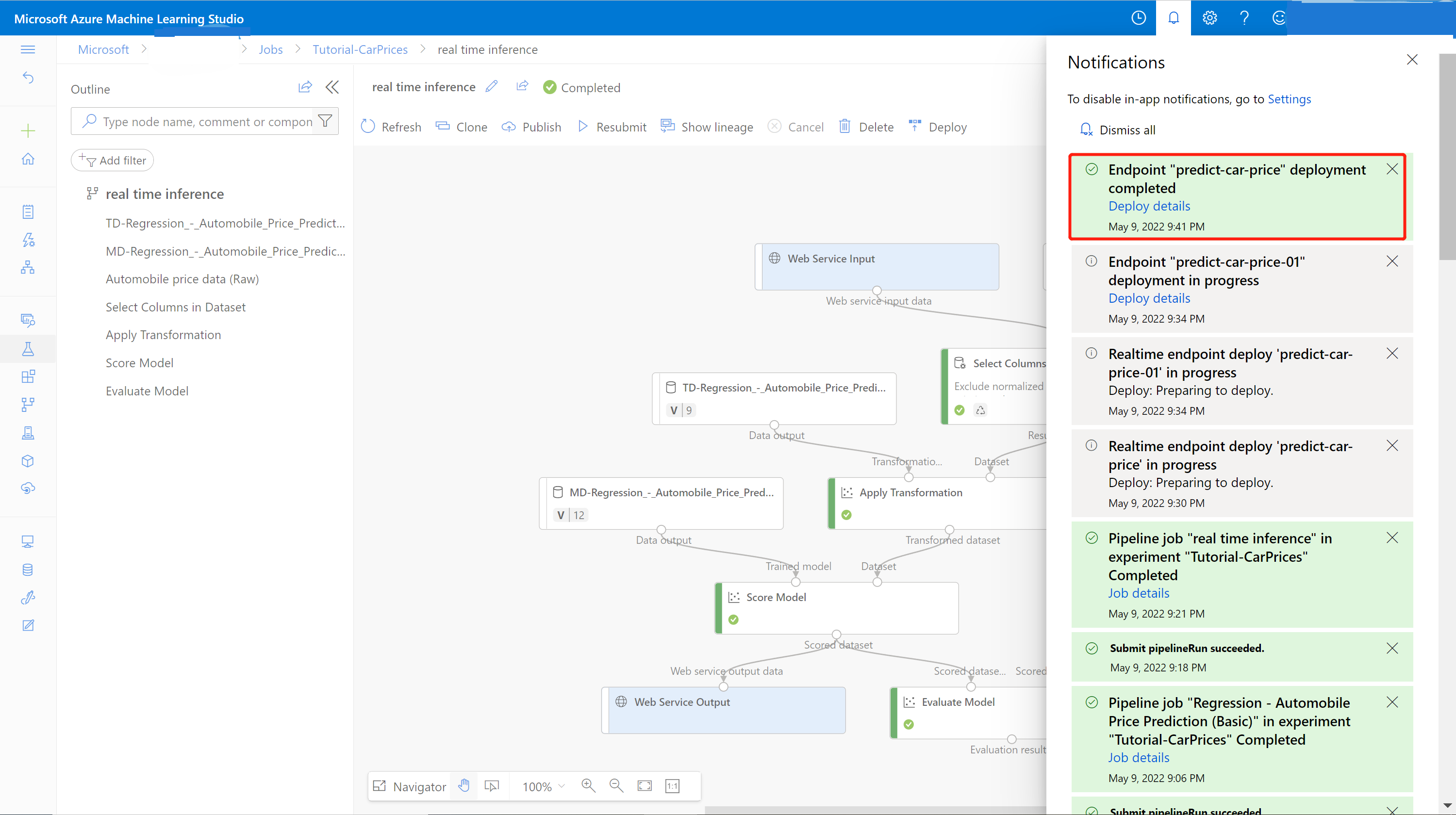
Une notification de réussite provenant du cente de notification s’affiche une fois le déploiement effectué. Cela peut prendre quelques minutes.

Conseil
Vous pouvez également effectuer le déploiement sur Azure Container Instance si vous sélectionnez Azure Container Instances comme Type de calcul dans la zone des paramètres de point de terminaison en temps réel. Le paramètre Azure Container Instances est utilisé à des fins de test ou de développement. Utilisez Azure Container Instance pour les charges de travail à faible échelle basées sur le processeur qui nécessitent moins de 48 Go de RAM.
Tester le point de terminaison en temps réel
Une fois le déploiement effectué, vous pouvez afficher votre point de terminaison en temps réel en accédant à la page Points de terminaison.
Dans la page Points de terminaison, sélectionnez le point de terminaison que vous avez déployé.
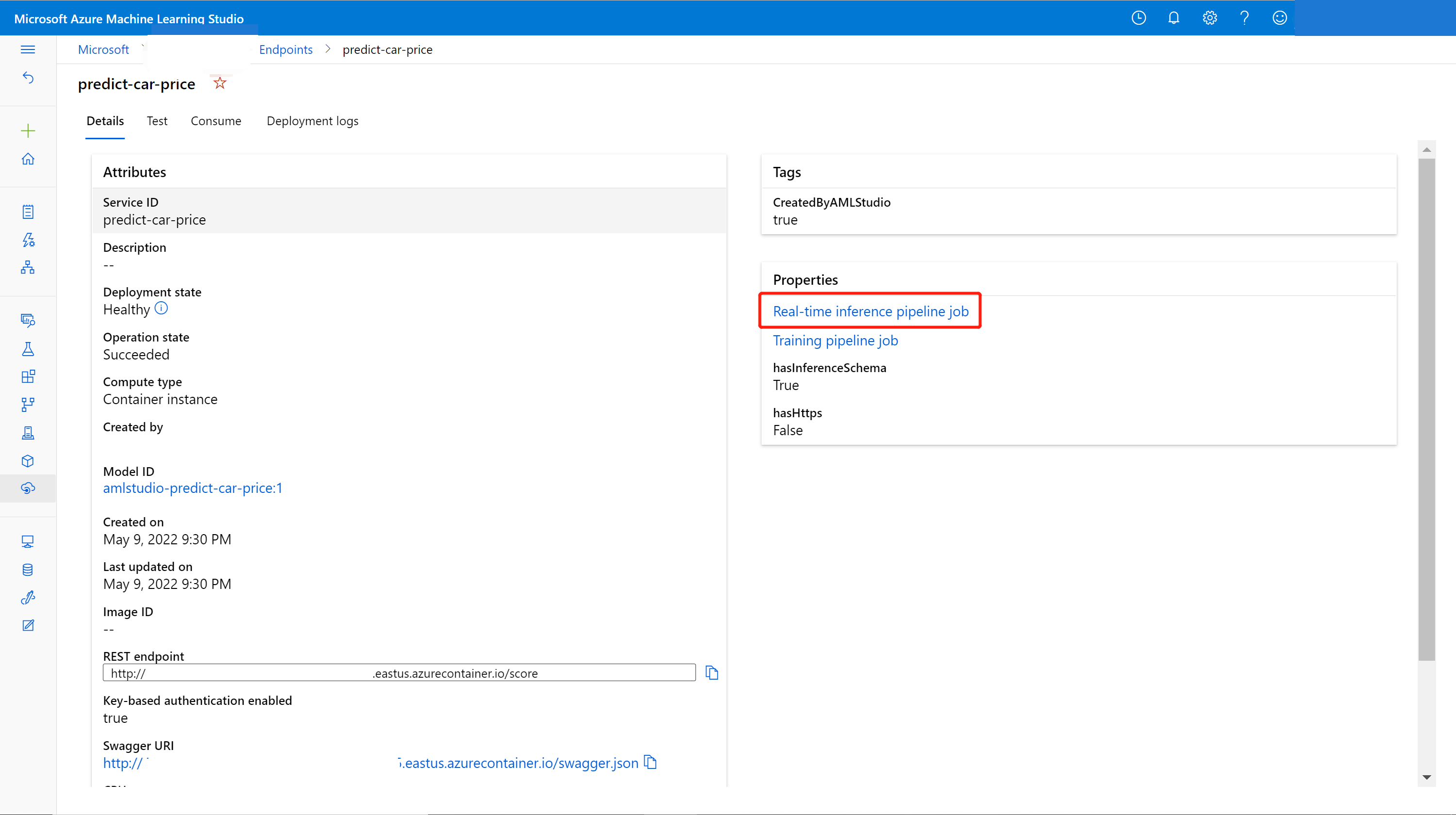
Sous l’onglet Détails, vous pouvez obtenir plus d’informations, telles que l’URI REST, la définition Swagger, l’état et les étiquettes.
Sous l’onglet Consommer, vous trouverez un exemple de code de consommation et des clés de sécurité, et pouvez définir des méthodes d’authentification.
Sous l’onglet Journaux de déploiement, vous trouverez les journaux de déploiement détaillés de votre point de terminaison en temps réel.
Pour tester votre point de terminaison, accédez à l’onglet Tester. À partir de là, vous pouvez entrer des données de test et sélectionner Tester afin de vérifier la sortie de votre point de terminaison.
Mettre à jour le point de terminaison en temps réel
Vous pouvez mettre à jour le point de terminaison en ligne avec le nouveau modèle entraîné dans le concepteur. Sur la page des détails du point de terminaison en ligne, recherchez votre travail de pipeline d’apprentissage précédent et votre travail de pipeline d’inférence.
Vous pouvez rechercher et modifier votre brouillon de pipeline d’entraînement sur la page d’accueil du concepteur.
Vous pouvez également ouvrir le lien de travail du pipeline d’apprentissage, puis le cloner dans un nouveau brouillon de pipeline pour poursuivre les modifications.
Après avoir envoyé le pipeline d’apprentissage modifié, accédez à la page des détails du travail.
Une fois le travail terminé, cliquez avec le bouton droit sur Entraîner le modèle et sélectionnez Inscrire les données.
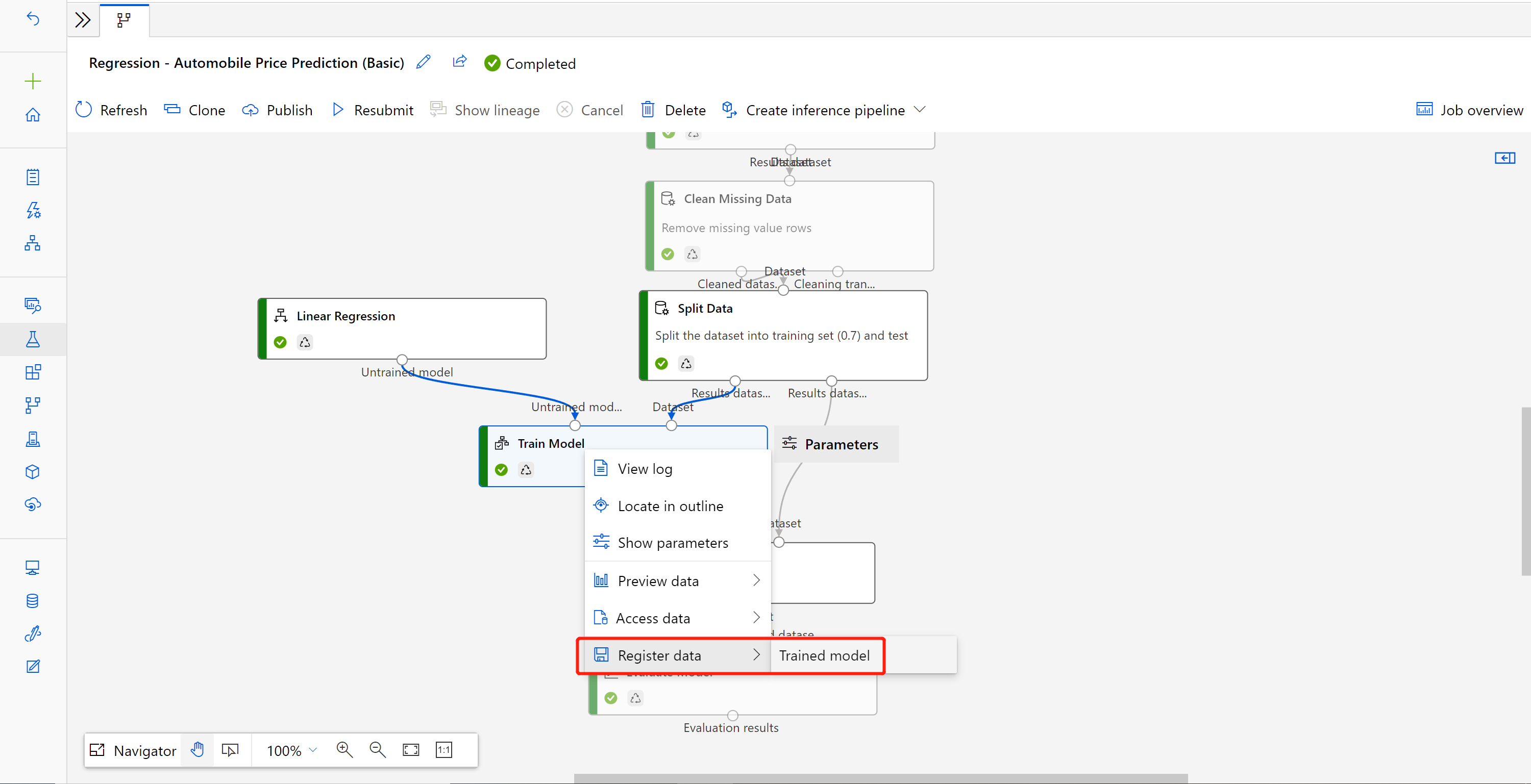
Entrez un nom et sélectionnez le type Fichier.
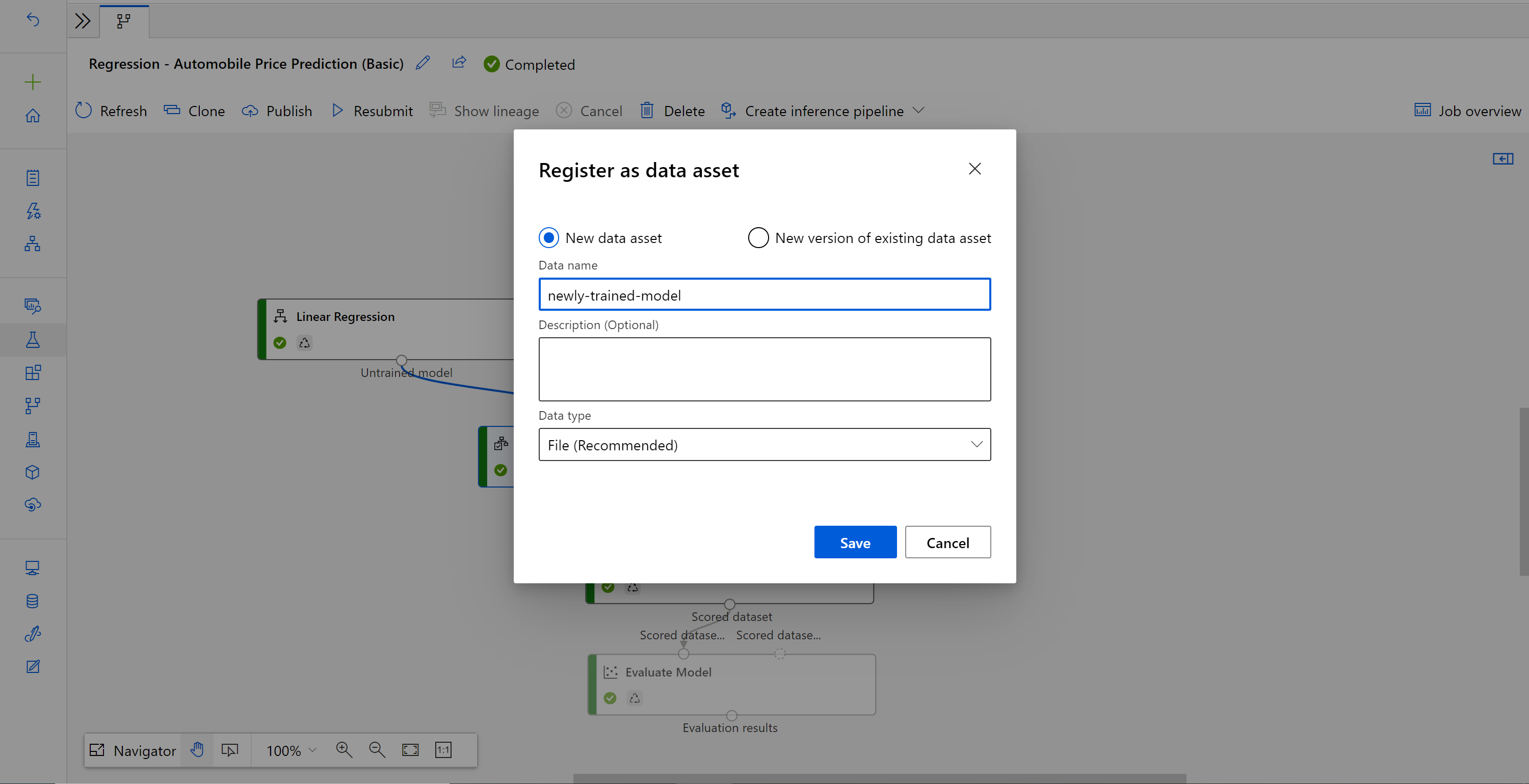
Une fois le jeu de données inscrit, ouvrez votre brouillon de pipeline d’inférence ou clonez le travail de pipeline d’inférence précédent dans un nouveau brouillon. Dans le brouillon du pipeline d’inférence, remplacez le modèle entraîné précédent affiché en tant que nœud MD-XXXX connecté au composant Modèle de score par le jeu de données qui vient d’être inscrit.
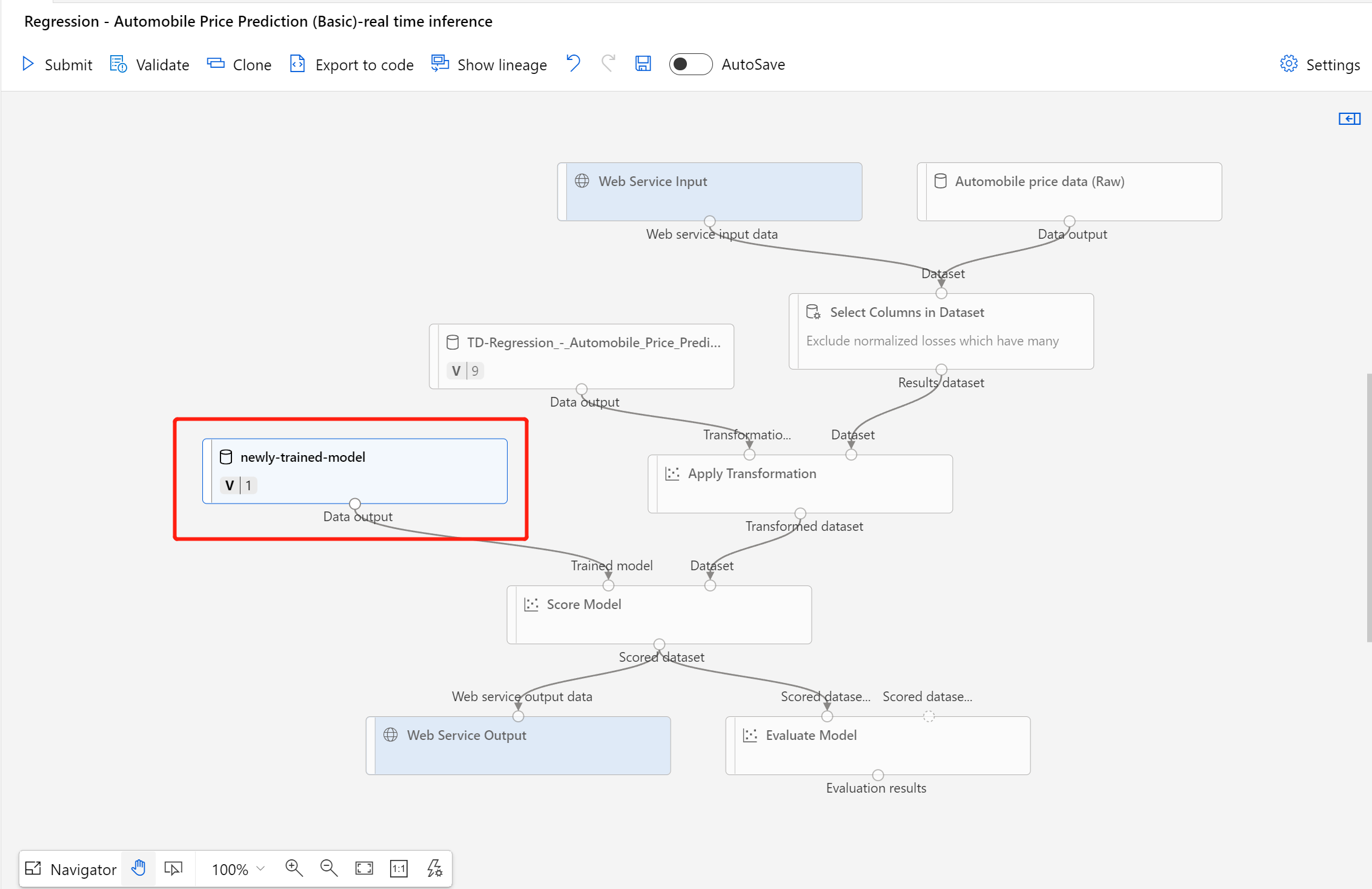
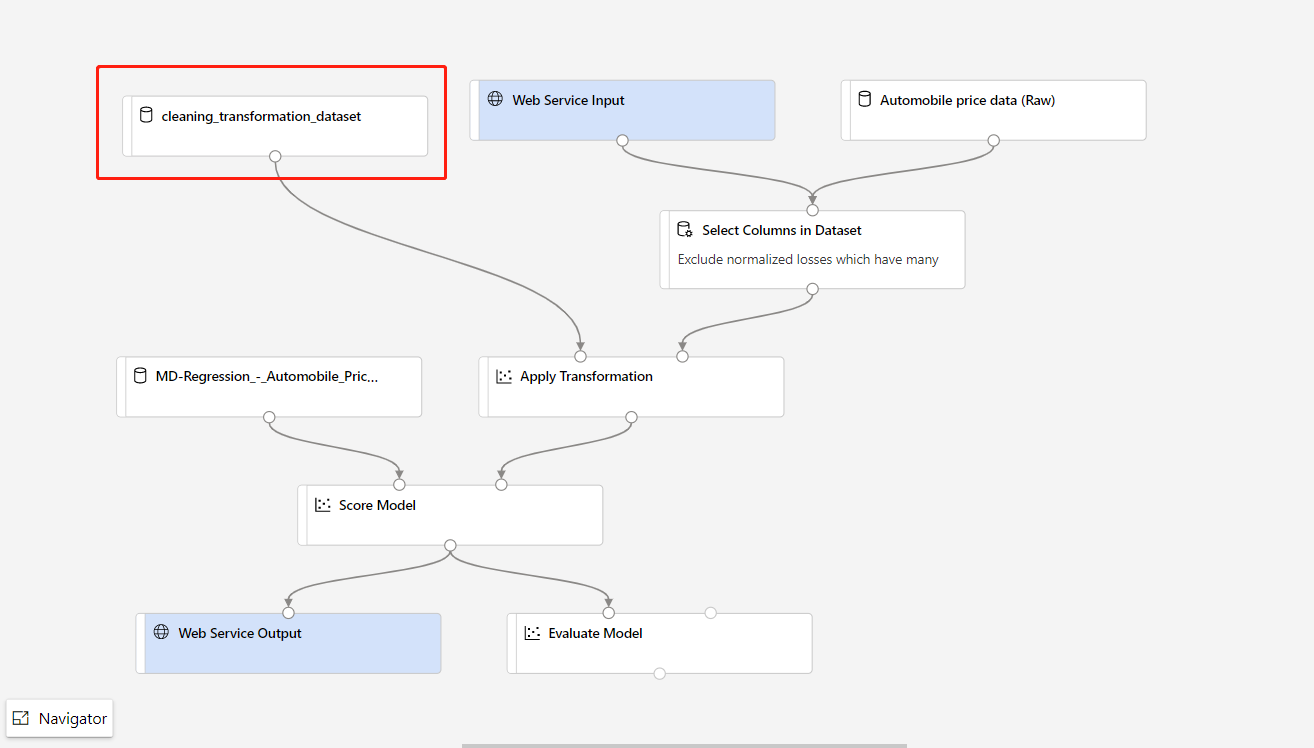
Si vous devez mettre à jour la partie de prétraitement des données dans votre pipeline d’apprentissage et que vous souhaitez mettre à jour cette partie dans le pipeline d’inférence, le traitement est similaire aux étapes ci-dessus.
Vous devez simplement inscrire le résultat de la transformation du composant de transformation comme jeu de données.
Ensuite, remplacez manuellement le composant TD- dans le pipeline d’inférence par le jeu de données inscrit.
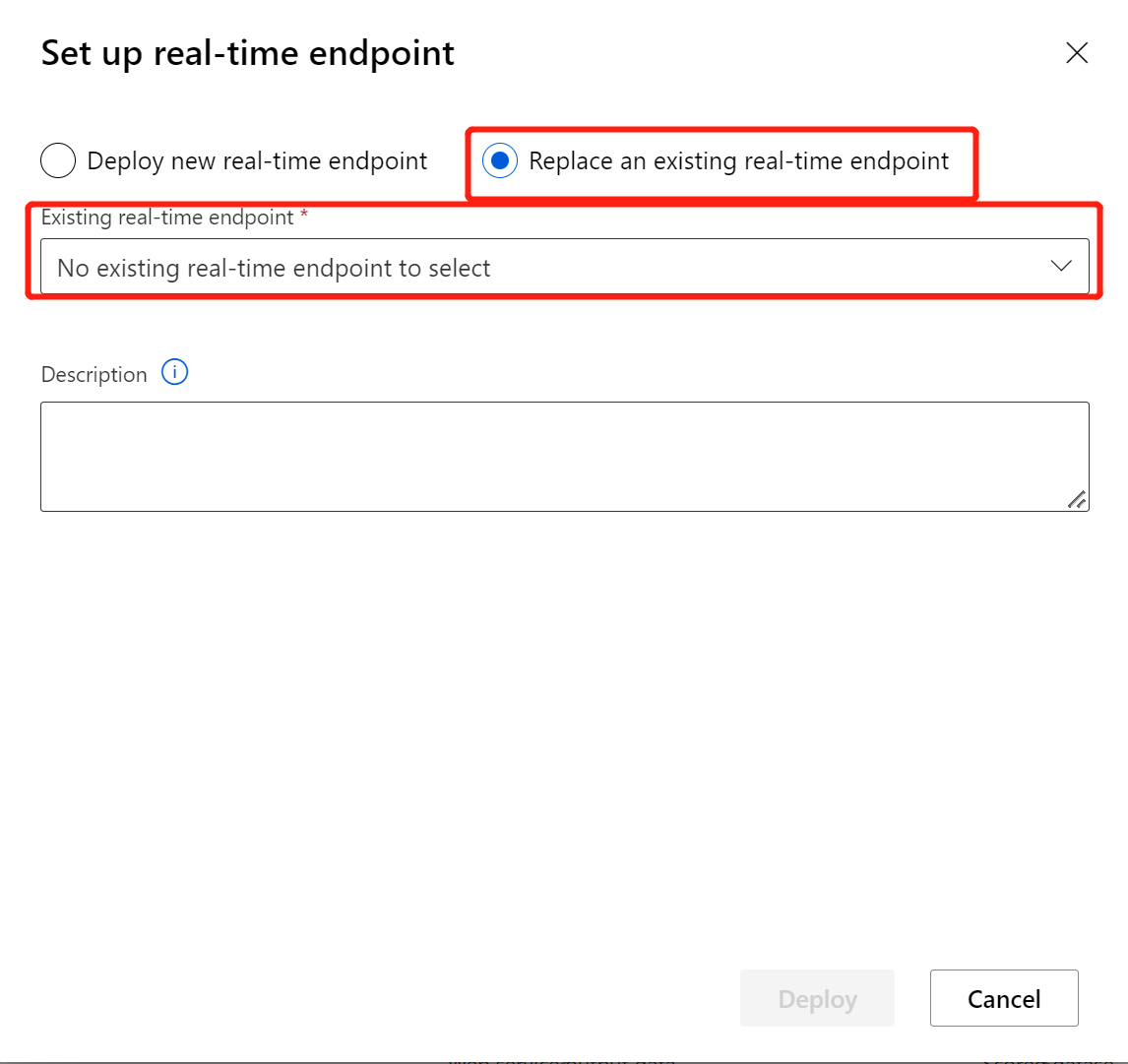
Après avoir modifié votre pipeline d’inférence avec le modèle ou la transformation nouvellement entraînée, envoyez-le. Une fois le travail terminé, déployez-le sur le point de terminaison en ligne existant déployé précédemment.




Limites
En raison de la limitation de l’accès au magasin de données, si votre pipeline d’inférence contient un composant Importer des données ou Exporter des données, ils sont automatiquement supprimés lors du déploiement sur le point de terminaison en temps réel.
Si vous avez des jeux de données dans le pipeline d’inférence en temps réel et que vous souhaitez le déployer sur un point de terminaison en temps réel, ce flux prend uniquement en charge les jeux de données inscrits à partir du magasin de données Blob. Si vous souhaitez utiliser des jeux de données d’autres types de magasins de données, vous pouvez utiliser Sélectionner une colonne pour vous connecter à votre jeu de données initial avec les paramètres de sélection de toutes les colonnes, inscrire les sorties de Sélectionner une colonne en tant que jeu de données de fichier, puis remplacer le jeu de données initial dans le pipeline d’inférence en temps réel par ce jeu de données nouvellement inscrit.
Si votre graphique d’inférence contient le composant Entrer des données manuellement qui n’est pas connecté au même port que le composant Entrée du service web, le composant Entrer des données manuellement n’est pas exécuté pendant le traitement des appels HTTP. Une solution de contournement consiste à inscrire les sorties de ce composant Entrer des données manuellement en tant que jeu de données, puis dans le brouillon du pipeline d’inférence, remplacez le composant Entrer des données manuellement par le jeu de données inscrit.

Nettoyer les ressources
Important
Vous pouvez utiliser les ressources que vous avez créées comme prérequis pour d’autres didacticiels et articles de guides pratiques Azure Machine Learning.
Tout supprimer
Si vous n’avez pas l’intention d’utiliser les éléments que vous avez créés, supprimez l’intégralité du groupe de ressources pour éviter des frais.
Dans le portail Azure, sélectionnez Groupes de ressources sur le côté gauche de la fenêtre.
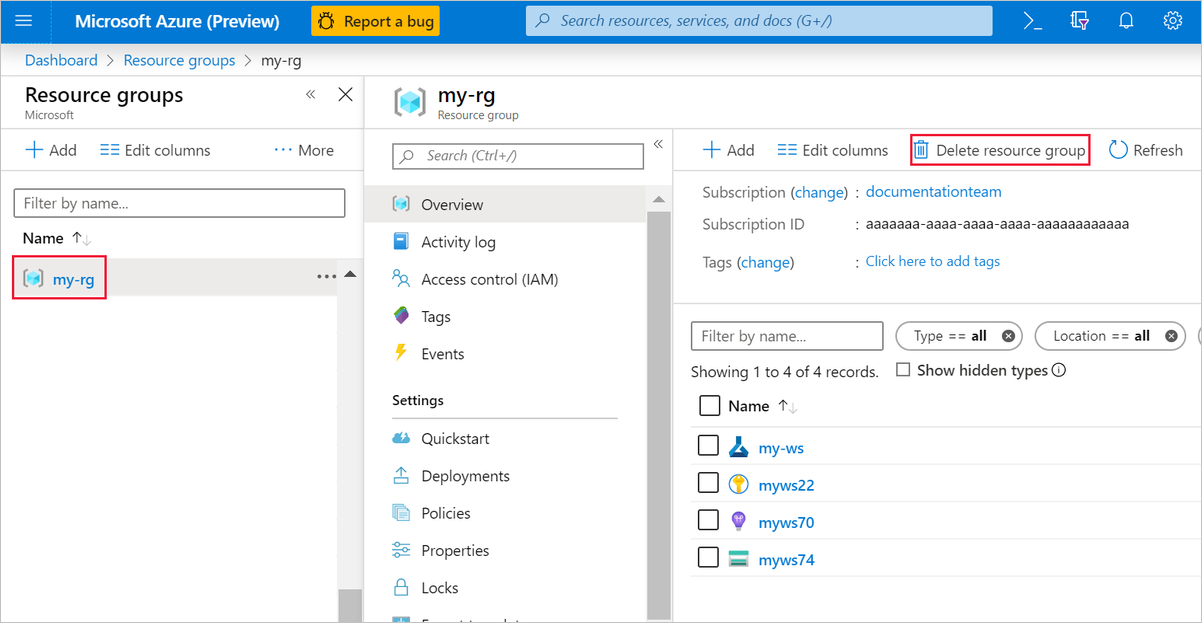
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
La suppression du groupe de ressources supprime également toutes les ressources créées dans le concepteur.
Supprimer des ressources individuelles
Dans le concepteur où vous avez créé votre expérience, supprimez des ressources individuelles en les sélectionnant, puis en sélectionnant le bouton Supprimer.
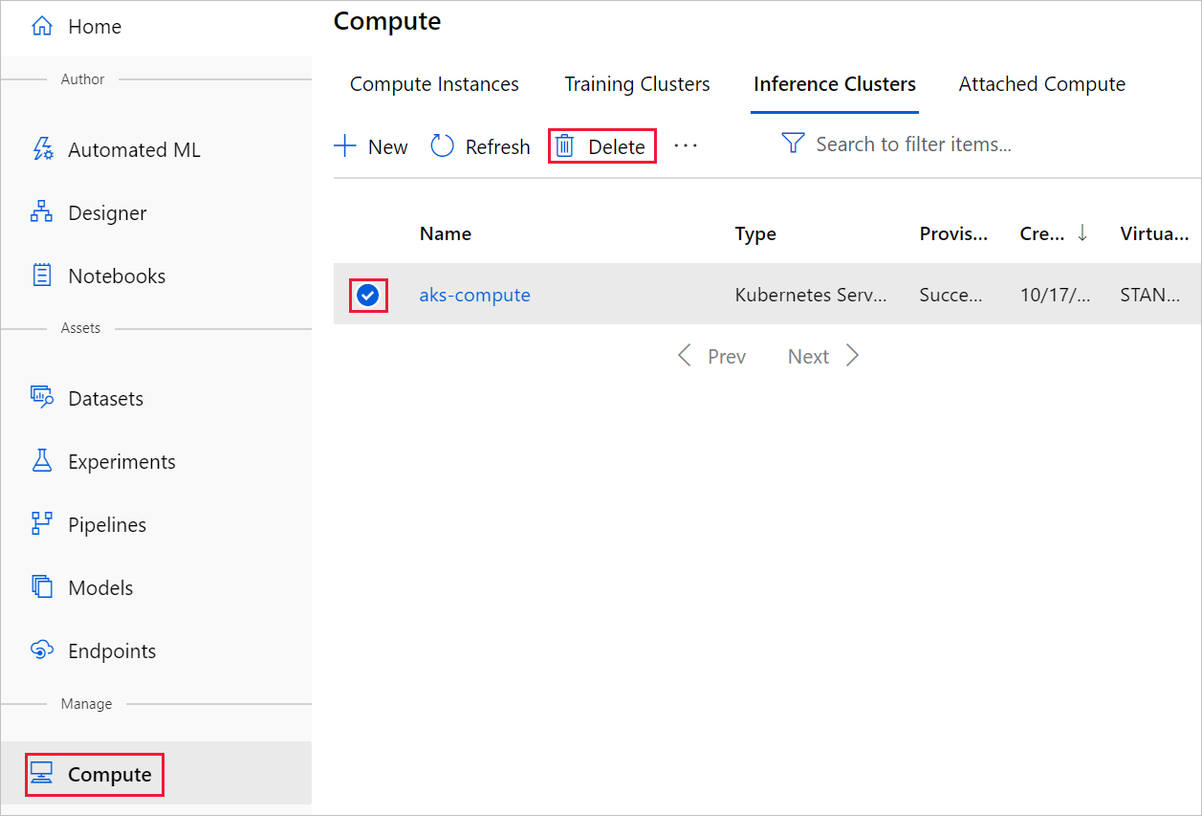
La cible de calcul que vous avez créée ici est automatiquement mise à l’échelle sur zéro nœud quand elle n’est pas utilisée. Cette action est effectuée pour réduire les frais. Si vous souhaitez supprimer la cible de calcul, procédez comme suit :
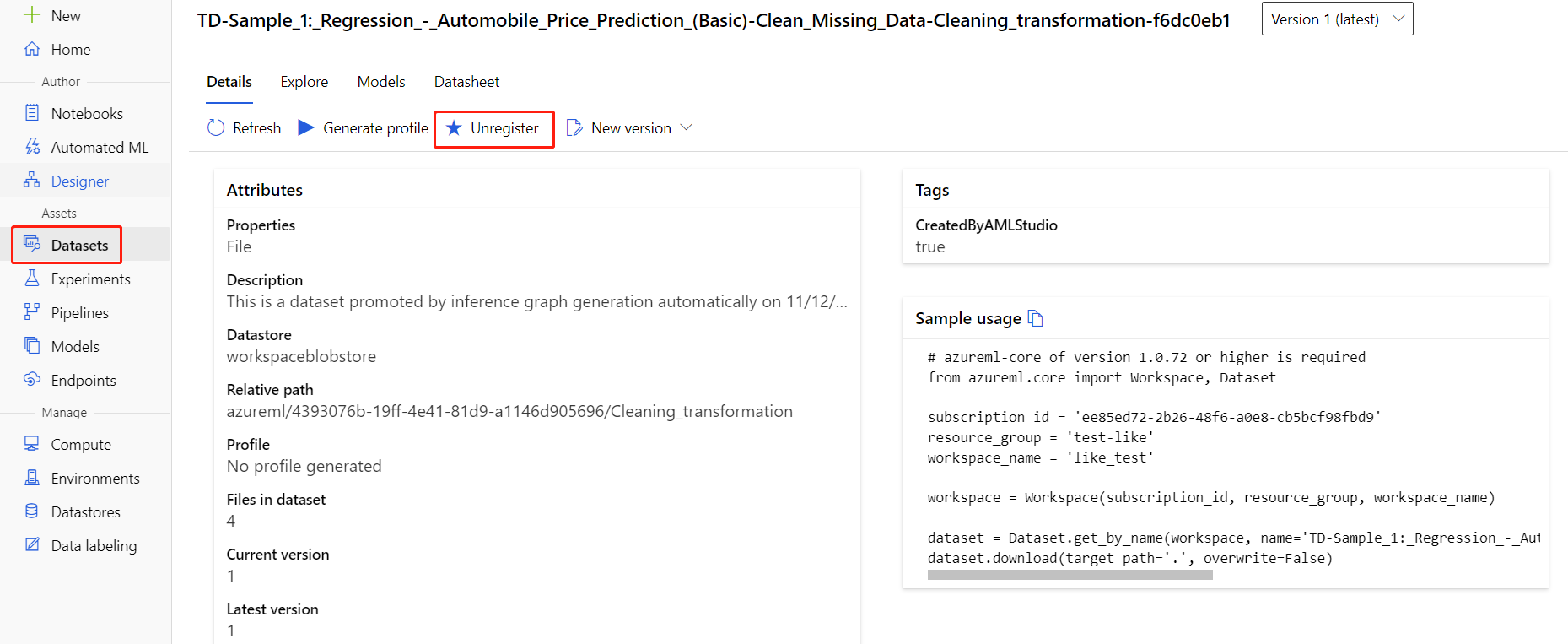
Vous pouvez désinscrire des jeux de données de votre espace de travail en sélectionnant chaque jeu de données, puis Annuler l’enregistrement.
Pour supprimer un jeu de données, accédez au compte de stockage à l’aide du portail Azure ou de l’Explorateur Stockage Azure et supprimez manuellement ces ressources.
Contenu connexe
Dans ce tutoriel, vous avez découvert comment créer, déployer et consommer un modèle Machine Learning dans le concepteur. Pour en savoir plus sur l’utilisation du concepteur, consultez les articles suivants :