Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Dans ce tutoriel, vous allez :
- Charger vos données sur un stockage en ligne
- Créer une ressource de données Azure Machine Learning
- Accéder à vos données dans un notebook pour le développement interactif
- Créer de nouvelles versions de ressources de données
Un projet d’apprentissage automatique débute le plus souvent par une analyse exploratoire des données (EDA), suivie d’un prétraitement des données (nettoyage, ingénierie des fonctionnalités) et de la conception de prototypes de modèles d’apprentissage automatique afin de valider les hypothèses. Cette phase de prototypage est fortement interactive et se prête particulièrement au développement dans un IDE ou dans un notebook Jupyter disposant d’une console Python interactive. Ce tutoriel présente ces différents concepts.
Prérequis
-
Pour utiliser Azure Machine Learning, vous avez besoin d’un espace de travail. Si vous n’en avez pas, suivez la procédure Créer les ressources nécessaires pour commencer pour créer un espace de travail et en savoir plus sur son utilisation.
Important
Si votre espace de travail Azure Machine Learning est configuré avec un réseau virtuel managé, vous devrez peut-être ajouter des règles de trafic sortant pour autoriser l’accès aux dépôts publics de packages Python. Pour plus d’informations, voir Scénario : Accéder aux packages d’apprentissage automatique publics.
-
Connectez-vous au studio et sélectionnez votre espace de travail s’il n’est pas encore ouvert.
-
Ouvrez ou créez un notebook dans votre espace de travail :
- Si vous souhaitez copier et coller du code dans les cellules, créez un notebook.
- Vous pouvez également ouvrir tutorials/get-started-notebooks/explore-data.ipynb dans la section Échantillons de Studio. Sélectionnez ensuite Cloner pour ajouter le notebook à vos fichiers. Pour trouver des exemples de notebooks, consultez Apprendre à partir d’exemples de notebooks.
Définir votre noyau et ouvrir dans Visual Studio Code (VS Code)
Dans la barre supérieure au-dessus de votre notebook ouvert, créez une instance de calcul si vous n’en avez pas déjà une.

Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.

Attendez que l’instance de calcul soit en cours d’exécution. Ensuite, assurez-vous que le noyau, situé en haut à droite, est
Python 3.10 - SDK v2. Si ce n’est pas le cas, sélectionnez ce noyau à l’aide de la liste déroulante.
Si vous ne voyez pas ce noyau, vérifiez que votre instance de calcul est en cours d’exécution. Si tel est le cas, cliquez sur le bouton Actualiser en haut du notebook à droite.
Si une bannière vous indique que vous devez être authentifié, sélectionnez Authentifier.
Vous pouvez exécuter le notebook ici ou l’ouvrir dans VS Code pour un environnement de développement intégré (IDE) complet avec la puissance des ressources Azure Machine Learning. Cliquez sur Ouvrir dans VS Code, puis sélectionnez l’option Web ou Bureau. Lors d’un tel lancement, VS Code est attaché à votre instance de calcul, au noyau et au système de fichiers de l’espace de travail.
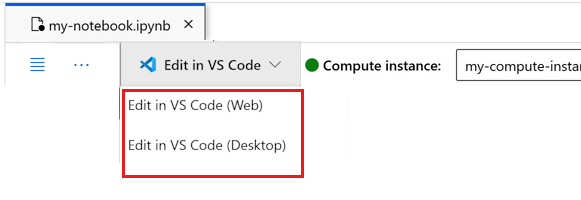




Important
Le reste de ce tutoriel contient des cellules du notebook du tutoriel. Copiez-le, et collez-le dans votre nouveau notebook, ou accédez maintenant au notebook si vous l’avez cloné.
Télécharger les données utilisées dans ce tutoriel
Pour l’ingestion des données, Azure Data Explorer prend en charge le traitement de données brutes dans ces formats. Ce tutoriel s’appuie sur un jeu de données d’exemple concernant des clients de cartes de crédit, au format CSV. Les différentes étapes sont réalisées au sein d’une ressource Azure Machine Learning. Dans cette ressource, vous créez un dossier local nommé « data », directement sous le dossier contenant ce notebook.
Remarque
Ce tutoriel dépend des données placées dans un emplacement de dossier de ressources Azure Machine Learning. Pour ce tutoriel, « local » désigne un emplacement de dossier dans cette ressource Azure Machine Learning.
Sélectionnez Ouvrir le terminal sous les trois points, comme illustré dans cette image :
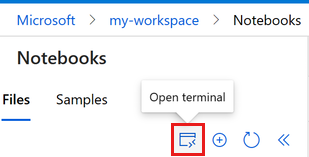
La fenêtre du terminal s’ouvre dans un nouvel onglet.
Veillez à modifier le répertoire (
cd) afin qu’il corresponde à l’emplacement de ce notebook. Par exemple, si le notebook se trouve dans un dossier nommé get-started-notebooks :cd get-started-notebooks # modify this to the path where your notebook is locatedEntrez ces commandes dans la fenêtre de terminal pour copier les données dans votre instance de calcul :
mkdir data cd data # the subfolder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvVous pouvez maintenant fermer la fenêtre du terminal.
Pour obtenir davantage d’informations sur les données issues du référentiel d’apprentissage automatique de l’université de Californie à Irvine, veuillez consulter cette ressource.
Créer un identifiant pour l’espace de travail
Avant d’examiner le code, vous devez disposer d’un moyen permettant de référencer votre espace de travail. Vous définissez ml_client comme identifiant de l’espace de travail. Vous utilisez ensuite ml_client pour administrer les ressources et les tâches.
Dans la cellule suivante, saisissez votre ID d’abonnement, le nom du groupe de ressources ainsi que le nom de l’espace de travail. Pour rechercher ces valeurs :
- Dans la barre d’outils supérieure droite d’Azure Machine Learning Studio, sélectionnez le nom de votre espace de travail.
- Copiez la valeur de l’espace de travail, du groupe de ressources et de l’ID d’abonnement dans le code.
- Chaque valeur doit être copiée séparément, l’une après l’autre. Fermez le champ, collez la valeur, puis passez à la suivante.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Remarque
La création de MLClient n’entraîne pas immédiatement la connexion à l’espace de travail. L’initialisation du client est différée et intervient uniquement lors du premier appel effectif. Cela se produit dans la cellule de code suivante.
Charger des données sur un stockage en ligne
Azure Machine Learning utilise des URI (Uniform Resource Identifier), qui pointent vers des emplacements de stockage dans le cloud. Un URI facilite l’accès aux données dans les notebooks et les tâches. Les formats d’URI de données sont comparables aux URL Web utilisées dans un navigateur pour accéder aux pages Internet. Voici un exemple :
- Accédez aux données à partir d’un serveur https public :
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Accédez aux données à partir d’Azure Data Lake Gen 2 :
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Une ressource de données Azure ML est similaire aux signets de navigateur web (favoris). Au lieu de mémoriser de longs chemins de stockage (URI) qui pointent vers vos données les plus fréquemment utilisées, vous pouvez créer une ressource de données, puis y accéder avec un nom convivial.
En créant une ressource de données, vous créez aussi une référence à l’emplacement de la source de données ainsi qu’une copie de ses métadonnées. Étant donné que les données restent à leur emplacement existant, vous n’exposez aucun coût de stockage supplémentaire et ne risquez pas l’intégrité des sources de données. Vous pouvez créer des ressources de données à partir de magasins de données Azure ML, d’un Stockage Azure, d’URL publiques et de fichiers locaux.
Conseil
Pour des chargements de données de petite taille, la création de ressources de données Azure Machine Learning constitue une solution adaptée pour transférer des données depuis des machines locales vers le stockage cloud. Cette approche permet d’éviter l’utilisation d’outils ou d’utilitaires supplémentaires. Le chargement de volumes de données plus importants peut toutefois nécessiter l’utilisation d’un outil ou d’un utilitaire dédié, tel qu’azcopy. L’outil de ligne de commande azcopy permet de déplacer des données vers et depuis le Stockage Azure. Pour plus d’informations sur azcopy, veuillez consulter la section Démarrer avec AzCopy.
La cellule de notebook suivante crée la ressource de données. L’exemple de code charge le fichier de données brutes dans la ressource de stockage en ligne désignée.
Chaque fois que vous créez une ressource de données, vous avez besoin d’une version unique pour celle-ci. Si la version existe déjà, une erreur est générée. Dans ce code, la valeur « initial » est utilisée pour la première ingestion des données. Si cette version existe déjà, le code ne la recrée pas.
Il est également possible d’omettre le paramètre de version. Dans ce cas, un numéro de version est automatiquement généré, à partir de 1 et incrémenté par la suite.
Ce tutoriel utilise le nom « initial » comme première version. Le tutoriel Créer des pipelines d’apprentissage automatique de production réutilise également cette version des données, ce qui permet d’employer une valeur commune entre les deux tutoriels.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# Update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# Set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Pour consulter les données chargées, sélectionnez Données dans la section Ressources du menu de navigation situé à gauche Les données ont été importées et une ressource de données a été créée :
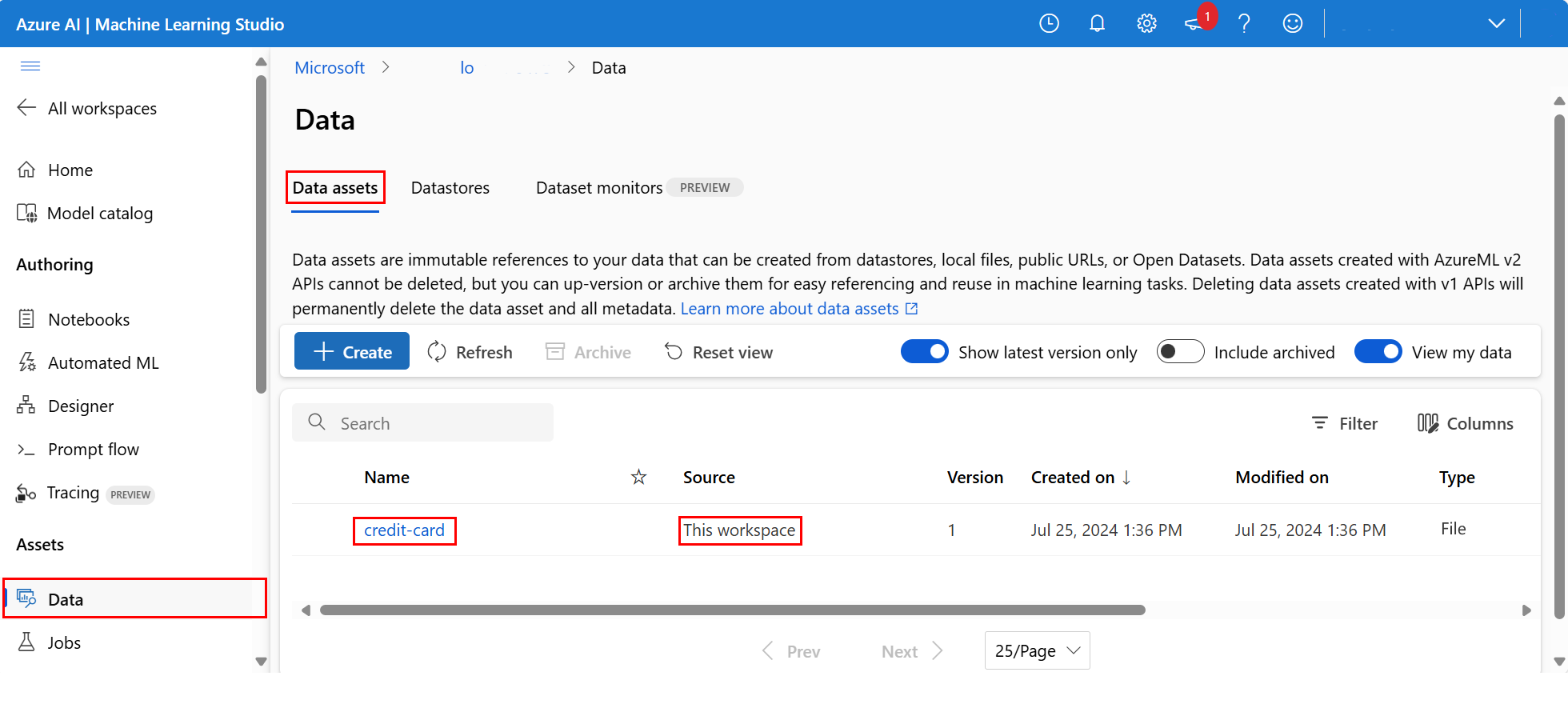
Ces données portent le nom « credit-card ». Dans l’onglet Ressources de données, elles apparaissent dans la colonne Nom.
Un magasin de données Azure Machine Learning est une référence à un compte de stockage existant sur Azure. Un magasin de données offre les avantages suivants :
Une API unifiée et simple d’utilisation permettant d’interagir avec différents types de stockage :
- Azure Data Lake Storage
- Objet blob
- Fichiers
ainsi qu’avec les méthodes d’authentification.
Une approche plus intuitive pour identifier des magasins de données pertinents lors d’un travail collaboratif.
Dans vos scripts, un moyen de masquer les informations de connexion pour l’accès aux données basées sur les informations d’identification (principal de service/SAS/clé).
Accéder à vos données dans un notebook
Il est recommandé de créer des ressources de données pour les ensembles de données consultés fréquemment. Vous pouvez accéder aux données à l’aide de l’URI, comme décrit dans Access data datastore URI comme vous le feriez à partir d’un système de fichiers. Toutefois, comme indiqué précédemment, la mémorisation de ces URI peut s’avérer complexe.
Une autre option consiste à utiliser la bibliothèque azureml-fsspec, qui propose une interface de type système de fichiers pour les magasins de données Azure Machine Learning. Cette solution facilite l’accès au fichier CSV depuis Pandas :
Important
Dans une cellule de notebook, exécutez ce code pour installer la bibliothèque Python azureml-fsspec dans votre noyau Jupyter :
%pip install -U azureml-fsspec
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# Read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Pour plus de détails sur l’accès aux données dans un bloc-notes, consultez Accéder aux données à partir du stockage cloud Azure pendant le développement interactif.
Créer une nouvelle version de la ressource de données
Les données nécessitent un léger nettoyage avant de pouvoir être utilisées pour l’entraînement d’un modèle d’apprentissage automatique. Il comprend :
- Deux lignes d’en-tête
- Une colonne d’identifiant client qui ne sera pas exploitée comme caractéristique en apprentissage automatique
- Des espaces présents dans le nom de la variable cible
Par ailleurs, comparé au format CSV, le format de fichier Parquet constitue une solution plus adaptée pour stocker ces données. Parquet permet la compression et préserve le schéma des données. Pour nettoyer les données et les enregistrer au format Parquet :
# Read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# Rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# Remove ID column
df.drop("ID", axis=1, inplace=True)
# Write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Ce tableau décrit la structure des données issues du fichier default_of_credit_card_clients.csv original téléchargé lors d’une étape antérieure. Les données chargées contiennent 23 variables explicatives et 1 variable de réponse, comme illustré ici :
| Nom(s) de colonne | Type de variable | Descriptif |
|---|---|---|
| X1 | Explications | Montant du crédit accordé (dollar NT) : il comprend à la fois le crédit à la consommation individuel et le crédit familial (supplémentaire). |
| X2 | Explications | Sexe (1 = homme ; 2 = femme). |
| X3 | Explications | Éducation (1 = études supérieures ; 2 = université ; 3 = lycée ; 4 = autres). |
| X4 | Explications | État civil (1 = marié ; 2 = célibataire ; 3 = autres). |
| X5 | Explications | Âge (années). |
| X6-X11 | Explications | Historique des paiements antérieurs. Historique des paiements mensuels enregistrés d’avril à septembre 2005. -1 = paiement intégral ; 1 = retard de paiement d’un mois ; 2 = retard de paiement de deux mois ; . . 8 = retard de paiement de huit mois ; 9 = retard de paiement de neuf mois et plus. |
| X12-17 | Explications | Montant des relevés de factures (en dollars NT) d’avril à septembre 2005. |
| X18-23 | Explications | Montant du paiement précédent (dollar NT) d’avril à septembre 2005. |
| O | response | Défaut de paiement (Oui = 1, Non = 0) |
Créez ensuite une nouvelle version de la ressource de données. Les données sont automatiquement transférées vers le stockage cloud. Pour cette version, ajoutez une valeur temporelle afin de générer un numéro de version distinct à chaque exécution du code.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new version of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Le fichier Parquet nettoyé correspond à la version la plus récente de la source de données. Ce code affiche d’abord le jeu de résultats de version CSV, puis la version Parquet :
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# Print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# Print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Nettoyer les ressources
Si vous comptez suivre d’autres tutoriels, passez aux Étapes suivantes.
Arrêter l’instance de calcul
Si aucune utilisation immédiate n’est prévue, arrêtez la capacité de calcul :
- Dans le studio, dans le volet gauche, sélectionnez Calcul.
- Dans les onglets supérieurs, sélectionnez Instances de calcul.
- Sélectionnez l’instance de calcul dans la liste.
- Dans la barre d’outils supérieure, sélectionnez Arrêter.
Supprimer toutes les ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans la zone de recherche du portail Azure, saisissez Groupes de ressources et sélectionnez cette option dans les résultats.
Dans la liste, sélectionnez le groupe de ressources créé.
Sur la page Vue d’ensemble, cliquez sur Supprimer le groupe de ressources.
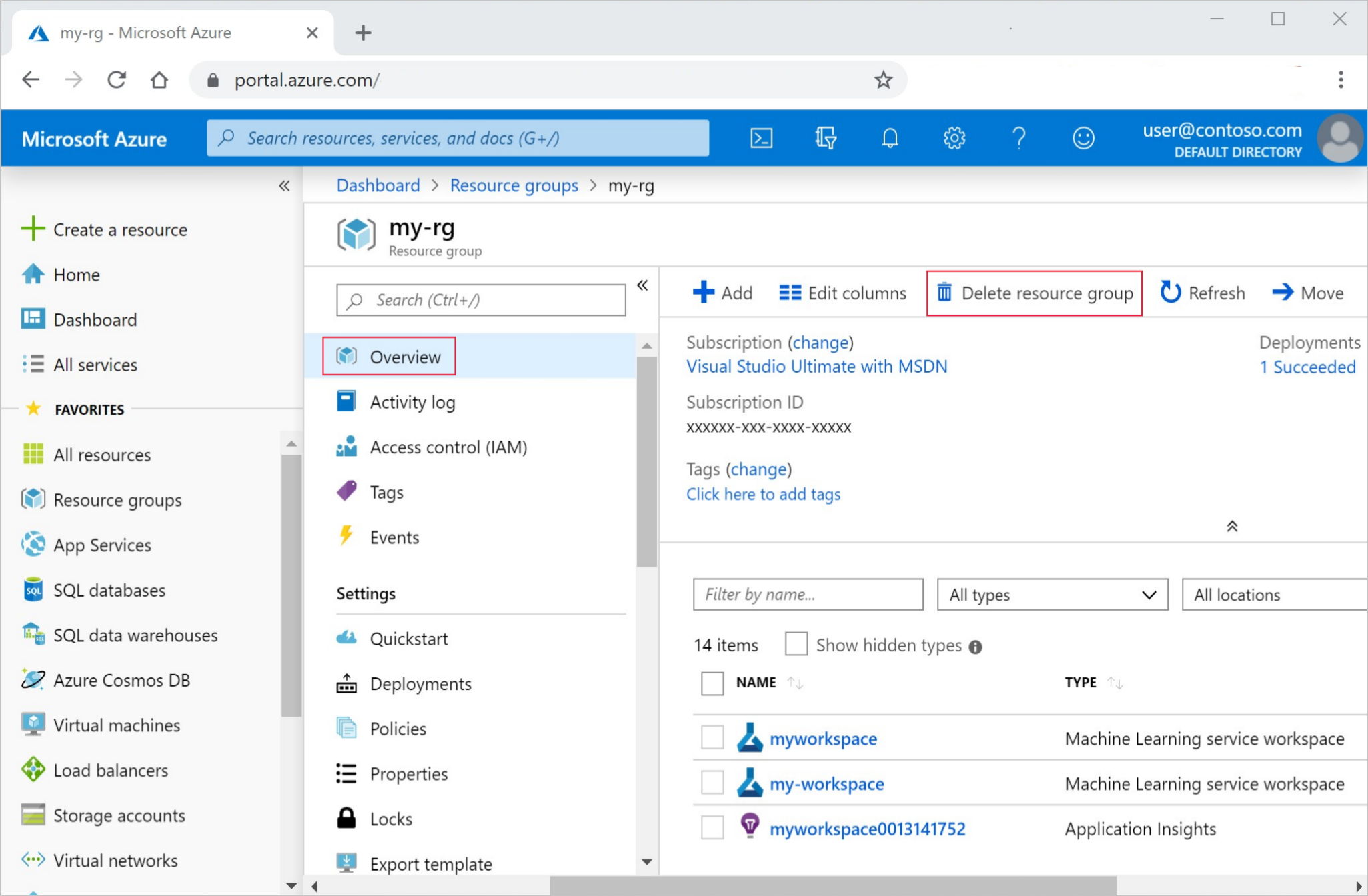
Entrez le nom du groupe de ressources. Ensuite, sélectionnez Supprimer.
Étapes suivantes
Pour plus d’informations sur les ressources de données, consultez Créer des ressources de données.
Pour plus d’informations sur les magasins de données, consultez Créer des magasins de données.
Poursuivez avec le tutoriel suivant afin d’apprendre à développer un script d’entraînement :