Tutoriel : Effectuer l’apprentissage de votre premier modèle Machine Learning (SDK v1, partie 2 sur 3)
S’APPLIQUE À : SDK Python azureml v1
SDK Python azureml v1
Ce tutoriel vous montre comment former un modèle Machine Learning dans Azure Machine Learning. Ce tutoriel est la deuxième partie d’une série de tutoriels qui en compte trois.
Dans la Partie 1 : Exécuter « Hello World ! » de la série, vous avez appris à utiliser un script de contrôle pour exécuter un tâches dans le cloud.
À présent, vous allez soumettre un script qui forme un modèle Machine Learning. Cet exemple vous permettra de comprendre comment Azure Machine Learning facilite la cohérence entre les procédures de débogage local et d’exécutions distantes.
Dans ce tutoriel, vous allez :
- Créez un script d’entraînement.
- Utiliser Conda pour définir un environnement Azure Machine Learning.
- Créer un script de contrôle.
- Comprendre les classes Azure Machine Learning (
Environment,Run,Metrics). - Soumettre et exécuter votre script de formation.
- Afficher le résultat de votre code dans le cloud.
- Journaliser des métriques dans Azure Machine Learning.
- Afficher vos métriques dans le cloud.
Prérequis
- Avoir suivi la partie 1 de la série.
Créer des scripts de formation
Définissez tout d’abord l’architecture du réseau neuronal dans un fichier model.py. Tout votre code d’entraînement sera placé dans le sous-répertoire src, notamment model.py.
Le code d’entraînement est tiré de cet exemple d’introduction de PyTorch. Notez que les concepts de Azure Machine Learning s’appliquent à tout code Machine Learning, pas seulement à PyTorch.
Créez un fichier model.py dans le sous-dossier src. Copiez ce code dans le fichier :
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xDans la barre d’outils, sélectionnez Enregistrer pour enregistrer le fichier. Fermez l’onglet si vous le souhaitez.
Définissez ensuite le script d’entraînement, également dans le sous-dossier src. Ce script télécharge le jeu de données CIFAR10 en utilisant les API PyTorch
torchvision.dataset. De plus, il configure le réseau défini dans model.py et l’entraîne pour deux périodes à l’aide de la méthode SGD (Stochastic Gradient Descent) et de la méthode de l’entropie croisée standard.Créez un script train.py dans le sous-dossier src :
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Vous disposez à présent de la structure de dossiers suivante :
Tester les topologies localement
Sélectionnez Enregistrer et exécuter le script dans le terminal pour exécuter le script train.py directement sur l’instance de calcul.
Une fois le script exécuté, sélectionnez Actualiser au-dessus des dossiers de fichiers. Vous verrez le nouveau dossier de données appelé get-started/data. Développez ce dossier pour voir les données téléchargées.
Créer un environnement Python
Azure Machine Learning fournit le concept d’environnement pour représenter un environnement Python reproductible et versionné afin d’exécuter des expériences. La création d’un environnement à partir d’un environnement Conda ou PIP local est simple.
Tout d’abord, vous allez créer un fichier avec les dépendances du package.
Créez un fichier dans le dossier get-started appelé
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionDans la barre d’outils, sélectionnez Enregistrer pour enregistrer le fichier. Fermez l’onglet si vous le souhaitez.
Créer le script de contrôle
La différence entre le script de contrôle ci-dessous et celui utilisé pour soumettre « Hello World » consiste en l’ajout de quelques lignes pour définir l’environnement.
Créez un fichier Python dans le dossier get-started appelé run-pytorch.py :
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Conseil
Si vous avez utilisé un autre nom quand vous avez créé le cluster de calcul, veillez à modifier également ce nom dans le code compute_target='cpu-cluster'.
Comprendre les modifications du code
env = ...
Fait référence au fichier de dépendance que vous avez créé ci-dessus.
config.run_config.environment = env
Ajoute l’environnement à ScriptRunConfig.
Soumettre l’exécution à Azure Machine Learning
Sélectionnez Enregistrer et exécuter le script dans le terminal pour exécuter le script run-pytorch.py.
Vous verrez un lien dans la fenêtre du terminal qui s’ouvre. Sélectionnez le lien pour afficher le travail.
Notes
Vous verrez peut-être des avertissements commençant par Échec lors du chargement de azureml_run_type_providers... Vous pouvez les ignorer. Utilisez le lien situé en bas de ces avertissements pour afficher la sortie.
Affichage du résultat
- La page qui s’ouvre affiche l’état du travail. La première fois que vous exécutez ce script, Azure Machine Learning va générer une nouvelle image Docker à partir de votre environnement PyTorch. L’ensemble du travail peut prendre environ 10 minutes. Cette image sera réutilisée dans les prochains travaux, ce qui permettra d’accélérer leur exécution.
- Vous pouvez voir les journaux de la génération Docker dans Azure Machine Learning Studio. Sélectionnez l’onglet Sorties + journaux, puis 20_image_build_log.txt.
- Lorsque l’état du travail est Terminé, sélectionnez Sortie + journaux.
- Sélectionnez std_log.txt pour afficher le résultat de votre travail.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Si vous voyez une erreur Your total snapshot size exceeds the limit, cela signifie que le dossier data se trouve dans la valeur source_directory utilisée dans ScriptRunConfig.
Sélectionnez ... à la fin du dossier, puis sélectionnez Déplacer pour déplacer data vers le dossier get-started.
Journaliser les métriques de formation
Maintenant que vous avez un modèle de formation dans Azure Machine Learning, commencez le suivi de certaines mesures de performances.
Le script de formation en cours imprime les métriques sur le terminal. Azure Machine Learning fournit un mécanisme de journalisation des métriques avec davantage de fonctionnalités. En ajoutant quelques lignes de code, vous avez la possibilité de visualiser les métriques dans le studio et de comparer celles de plusieurs travaux.
Modifier train.py pour inclure la journalisation
Modifiez le script train.py pour inclure deux lignes de code supplémentaires :
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Enregistrez ce fichier, puis fermez l’onglet si vous le souhaitez.
Comprendre les deux lignes de code supplémentaires
Dans train.py, vous accédez à l’objet d’exécution depuis le script d’entraînement lui-même à l’aide de la méthode Run.get_context(), et vous l’utilisez pour journaliser des métriques :
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Les métriques de Azure Machine Learning sont :
- Organisées par expérience et par exécution ; il est donc facile de suivre et de comparer des métriques.
- Équipées d’une interface utilisateur qui vous permet de visualiser les performances de formation dans Studio.
- Conçues pour être mises à l’échelle, vous conservez ces avantages même lorsque vous exécutez des centaines d’expériences.
Mettre à jour le fichier d’environnement Conda
Le script train.py prenait uniquement une nouvelle dépendance sur azureml.core. Mettre à jour pytorch-env.yml pour refléter cette modification :
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Veillez à enregistrer ce fichier avant d’envoyer l’exécution.
Soumettre l’exécution à Azure Machine Learning
Sélectionnez l’onglet du script run-pytorch.py, puis sélectionnez Enregistrer et exécuter le script dans le terminal pour réexécuter le script run-pytorch.py. Assurez-vous d’avoir enregistré vos modifications dans le pytorch-env.yml en premier.
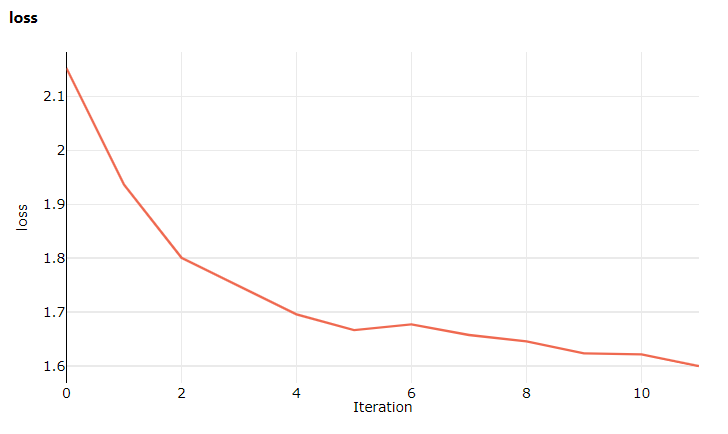
Cette fois, quand vous accédez au studio, accédez à l’onglet Métriques, où vous pouvez maintenant voir les mises à jour en direct sur la perte du modèle d’entraînement ! 1 à 2 minutes peuvent s’écouler avant que l’entraînement commence.
Étapes suivantes
Dans cette session, vous avez mis à niveau un script « Hello World ! » de base vers un script d’apprentissage plus réaliste nécessitant l’exécution d’un environnement Python spécifique. Vous avez vu comment utiliser des environnements Azure Machine Learning organisés. Enfin, vous avez vu comment l’ajout de quelques lignes de code vous permet de journaliser des métriques dans Azure Machine Learning.
Il existe d’autres façons de créer des environnements Azure Machine Learning, y compris à partir d’un fichier pip requirements.txt ou à partir d’un environnement Conda existant.
Dans la prochaine session, vous verrez comment utiliser des données dans Azure Machine Learning en chargeant le jeu de données CIFAR10 sur Azure.
Notes
Si vous voulez arrêter la série de tutoriels ici sans passer à l’étape suivante, n’oubliez pas de nettoyer vos ressources.