Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment utiliser des charges de travail GPU NVIDIA avec Azure Red Hat OpenShift (ARO).
Conditions préalables
- OpenShift CLI
- Packages jq, moreutils et gettext
- Azure Red Hat OpenShift 4.10
Si vous avez besoin d’installer un cluster ARO, consultez Tutoriel : Créer un cluster Azure Red Hat OpenShift 4. Les clusters ARO doivent être de version 4.10.x ou ultérieure.
Remarque
À partir d’ARO 4.10, il n’est plus nécessaire de configurer des droits d’utilisation pour utiliser l’opérateur NVIDIA. Cela a considérablement simplifié la configuration du cluster pour les charges de travail GPU.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Demander un quota GPU
Tous les quotas GPU dans Azure sont 0 par défaut. Vous devez vous connecter au portail Azure et demander un quota GPU. En raison de la concurrence pour les rôles de travail GPU, il se peut que vous deviez approvisionner un cluster ARO dans une région où vous pouvez réellement réserver un GPU.
ARO prend en charge les rôles de travail GPU suivants :
- NC4as_T4_v3
- NC6s v3
- NC8as_T4_v3
- NC12s v3
- NC16as_T4_v3
- NC24s v3
- NC24rs v3
- NC64as_T4_v3
Les instances suivantes sont également prises en charge dans d’autres MachineSets :
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Remarque
Lors de la demande de quota, n’oubliez pas qu’Azure est facturé par cœur. Pour demander un seul nœud NC4as T4 v3, vous devez demander un quota de 4. Si vous souhaitez demander un NC16as T4 v3, vous devez demander un quota de 16.
Connectez-vous au portail Azure.
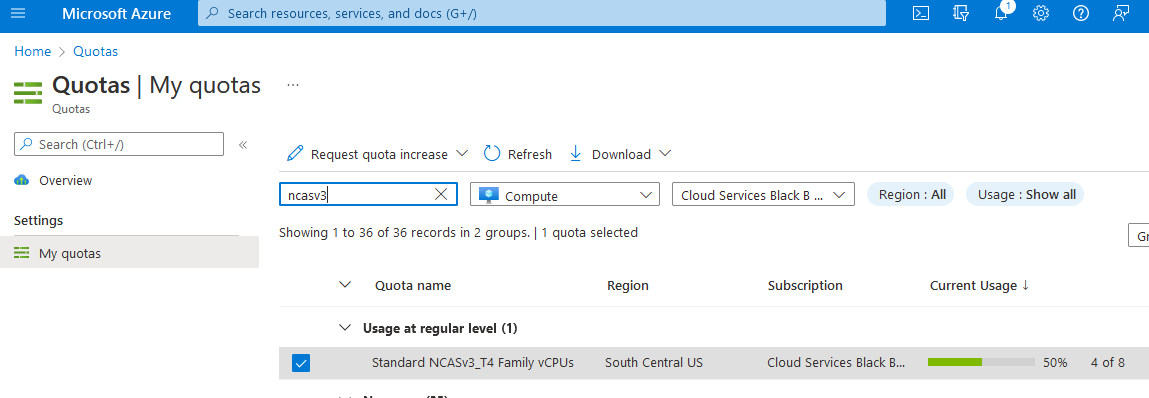
Entrez les quotas dans la zone de recherche, puis sélectionnez Calcul.
Dans la zone de recherche, entrez NCAsv3_T4, cochez la case correspondant à la région dans laquelle se trouve votre cluster, puis sélectionnez Demander une augmentation du quota.
Configurez le quota.
Vous connectez à votre cluster ARO
Connectez-vous à OpenShift avec un compte d’utilisateur disposant de privilèges d’administrateur de cluster. L’exemple ci-dessous utilise un compte nommé kubadmin :
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Secret d’extraction (conditionnel)
Mettez à jour votre secret d’extraction pour vous assurer que vous pouvez installer des opérateurs et vous connecter à cloud.redhat.com.
Remarque
Ignorez cette étape si vous avez déjà recréé un secret d’extraction complet avec cloud.redhat.com activé.
Connectez-vous à cloud.redhat.com.
Accédez à https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Sélectionnez Télécharger le secret d’extraction, puis enregistrez-le secret d’extraction sous
pull-secret.txt.Important
Les étapes restantes de cette section doivent être exécutées dans le même répertoire de travail que
pull-secret.txt.Exportez le secret d’extraction existant.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonFusionnez le secret d’extraction téléchargé avec le secret d’extraction système pour ajouter
cloud.redhat.com.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonChargez le nouveau fichier de secret.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonIl se peut que vous deviez attendre environ 1 heure pour que tout soit synchronisé avec cloud.redhat.com.
Supprimer des clés secrètes.
rm pull-secret.txt export-pull.json new-pull-secret.json
Ensemble de machines GPU
ARO utilise Kubernetes MachineSet pour créer des ensembles de machines. La procédure ci-dessous explique comment exporter le premier ensemble de machines dans un cluster et l’utiliser comme modèle pour générer une seule machine GPU.
Affichez les ensembles de machines existants.
Pour faciliter la configuration, cet exemple utilise le premier ensemble de machines à cloner pour créer un ensemble de machines GPU.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Enregistrez une copie de l’exemple d’ensemble de machines.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonModifiez le champ
.metadata.nameen le définissant sur un nouveau nom unique.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonVérifiez que la valeur de
spec.replicascorrespond au nombre de réplicas souhaité pour l’ensemble de machines.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonModifiez le champ
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetpour qu’il corresponde au champ.metadata.name.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonModifiez la valeur de
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetpour qu’elle corresponde au champ.metadata.name.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonModifiez la valeur de
spec.template.spec.providerSpec.value.vmSizepour qu’elle corresponde au type d’instance GPU souhaité d’Azure.La machine utilisée dans cet exemple est Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonModifiez la valeur de
spec.template.spec.providerSpec.value.zonepour qu’elle corresponde à la zone souhaitée d’Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonSupprimez la section
.statusdu fichier yaml.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonVérifiez les autres données dans le fichier yaml.
Vérifier que la référence SKU correcte est définie
Selon l’image utilisée pour l’ensemble de machines, les valeurs de image.sku et de image.version doivent être définies en conséquence. Cela permet de s’assurer qu’une machine virtuelle de génération 1 ou 2 pour Hyper-V sera utilisée. Pour plus d’informations, consultez ici.
Exemple:
Si vous utilisez Standard_NC4as_T4_v3, les deux versions sont prises en charge. Ceci est mentionné dans Prise en charge des fonctionnalités. Dans ce cas, aucune modification n’est nécessaire.
Si vous utilisez Standard_NC24ads_A100_v4, seule la machine virtuelle de génération 2 est prise en charge.
Dans ce cas, la valeur image.sku doit suivre la version v2 équivalente de l’image qui correspond à la valeur image.sku d’origine du cluster. Pour cet exemple, la valeur est v410-v2.
Vous pouvez la trouver à l’aide de la commande suivante :
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Si le cluster a été créé avec l’image de référence SKU de base aro_410 et que la même valeur est conservée dans l’ensemble de machines, il échoue avec l’erreur suivante :
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Créer un ensemble de machines GPU
Suivez les étapes suivantes pour créer la nouvelle machine GPU. L’approvisionnement d’une nouvelle machine GPU peut prendre de 10 à 15 minutes. Si cette étape échoue, connectez-vous au portail Azure et assurez-vous qu’il n’y a pas de problème de disponibilité. Pour ce faire, accédez à Machines Virtuelles, puis recherchez le nom de rôle de travail que vous avez créé précédemment pour voir l’état des machines virtuelles.
Créez un ensemble de machines GPU.
oc create -f gpu_machineset.jsonCette commande prend plusieurs minutes.
Vérifiez l’ensemble de machines GPU.
Les machines devraient être déployées. Vous pouvez afficher l’état de l’ensemble de machines avec les commandes suivantes :
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiUne fois les machines approvisionnées (ce qui pourrait prendre de 5 à 15 minutes), elles s’affichent en tant que nœuds dans la liste de nœuds :
oc get nodesVous devriez voir un nœud portant le nom
nvidia-worker-southcentralus1créé précédemment.
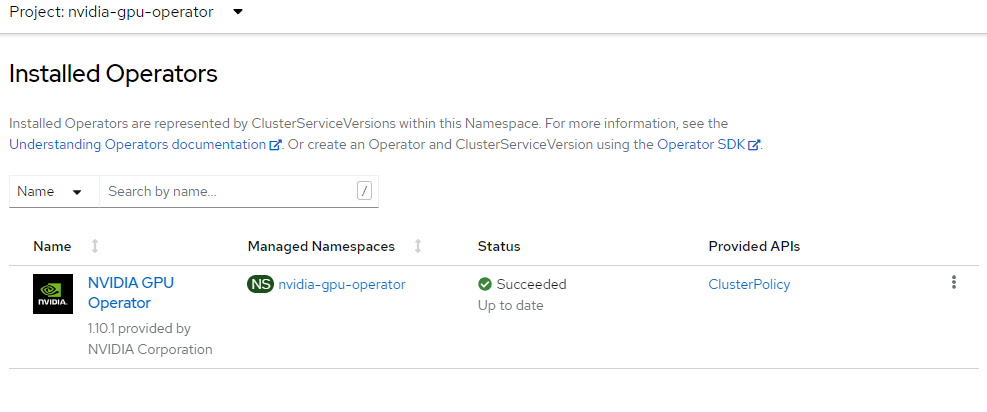
Installer l’opérateur GPU NVIDIA
Cette section explique comment créer l’espace de noms nvidia-gpu-operator, configurer le groupe d’opérateurs et installer l’opérateur GPU NVIDIA.
Créez un espace de noms NVIDIA.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFCréer un groupe d’opérateurs.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFObtenez le dernier canal NVIDIA avec la commande suivante :
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Remarque
Si votre cluster a été créé sans fournir le secret d’extraction, le cluster n’inclut pas d’échantillons ou d’opérateurs de Red Hat ou de partenaires certifiés. Il en résulte le message d’erreur suivant :
Erreur du serveur (NotFound) : packagemanifests.packages.operators.coreos.com « gpu-operator-certified » introuvable.
Pour ajouter votre secret d’extraction Red Hat sur un cluster Azure Red Hat OpenShift, suivez ces instructions.
Obtenez le dernier package NVIDIA avec la commande suivante :
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Créez un abonnement.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFAttendez que l’installation de l’opérateur soit terminée.
Ne poursuivez pas tant que vous n’avez pas vérifié que l’installation de l’opérateur est terminée. Vérifiez également que votre rôle de travail GPU est en ligne.
Installer un opérateur de découverte de fonctionnalités de nœud
L’opérateur de découverte de fonctionnalités de nœud découvre le GPU sur vos nœuds et étiquette les nœuds de manière appropriée afin de pouvoir les cibler pour les charges de travail.
Cet exemple installe l’opérateur de découverte de fonctionnalités de nœud dans l’espace de noms openshift-ndf et crée l’« abonnement », qui est la configuration de découverte de fonctionnalités de nœud.
Documentation officielle pour l’installation d’opérateur de découverte de fonctionnalités de nœud.
Configurez
Namespace.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFCréez
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFCréez
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFAttendez que l’installation de l’opérateur de découverte de fonctionnalités de nœud soit terminée.
Vous pouvez vous connecter à votre console OpenShift pour afficher les opérateurs ou simplement attendre quelques minutes. À défaut d’attendre la fin de l’installation de l’opérateur, une erreur se produira à l’étape suivante.
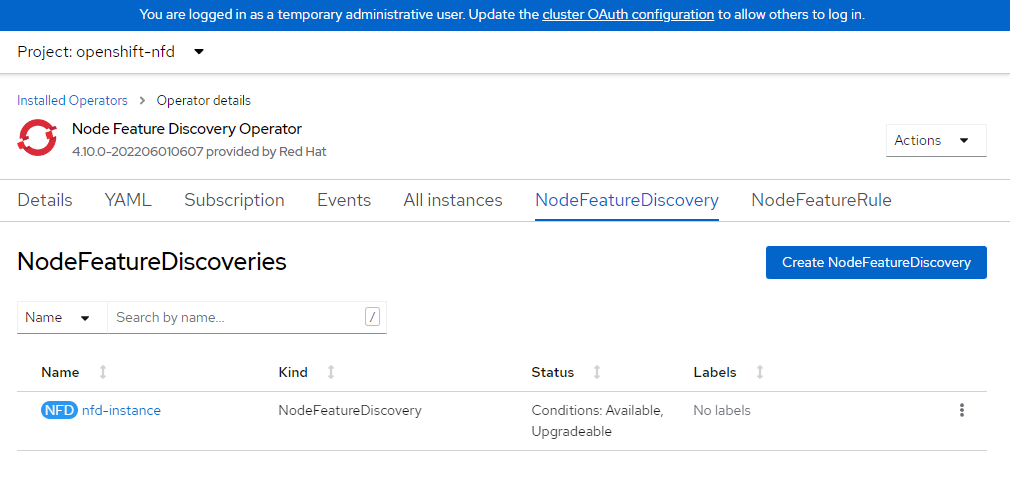
Créez une instance de découverte de fonctionnalités de nœud.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFVérifiez que l’opérateur de découverte de fonctionnalités de nœud est prêt.
L’état de cet opérateur devrait être Disponible.
Appliquer la configuration du cluster NVIDIA
Cette section explique comment appliquer la configuration du cluster NVIDIA. Lisez la documentation NVIDIA sur la personnalisation de cette configuration si vous avez vos propres dépôts privés ou des paramètres spécifiques. Ce processus peut prendre plusieurs minutes.
Appliquez la configuration du cluster.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFVérifiez la stratégie de cluster.
Connectez-vous à la console OpenShift et accédez aux opérateurs. Vérifiez que vous êtes dans l’espace de noms
nvidia-gpu-operator. Cette valeur doit êtreState: Ready once everything is complete.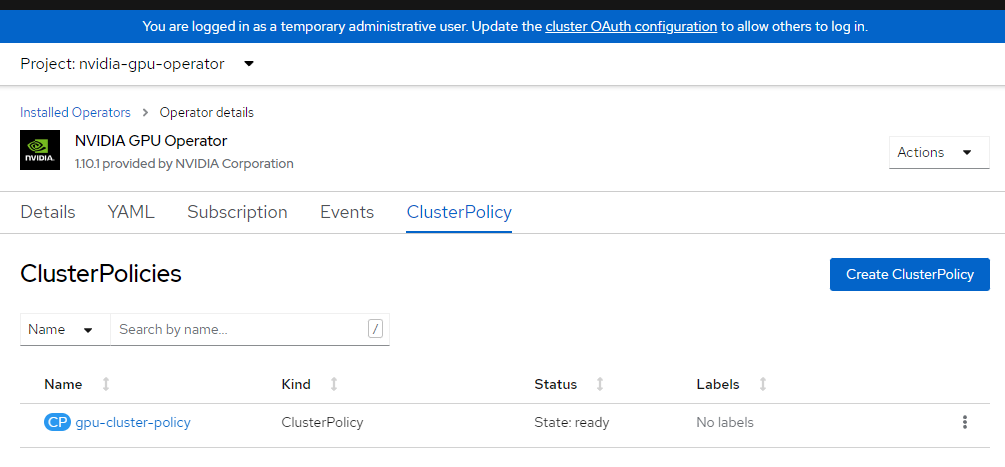
Valider le GPU
L’installation complète de l’opérateur NVIDIA et de NFD ainsi que l’identification automatique des machines peuvent prendre un certain temps. Exécutez les commandes suivantes pour vérifier que tout fonctionne comme prévu :
Vérifiez que l’opérateur de découverte de fonctionnalités de nœud peut voir vos GPU.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterLe résultat doit ressembler à ce qui suit :
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueVérifiez les étiquettes de nœud.
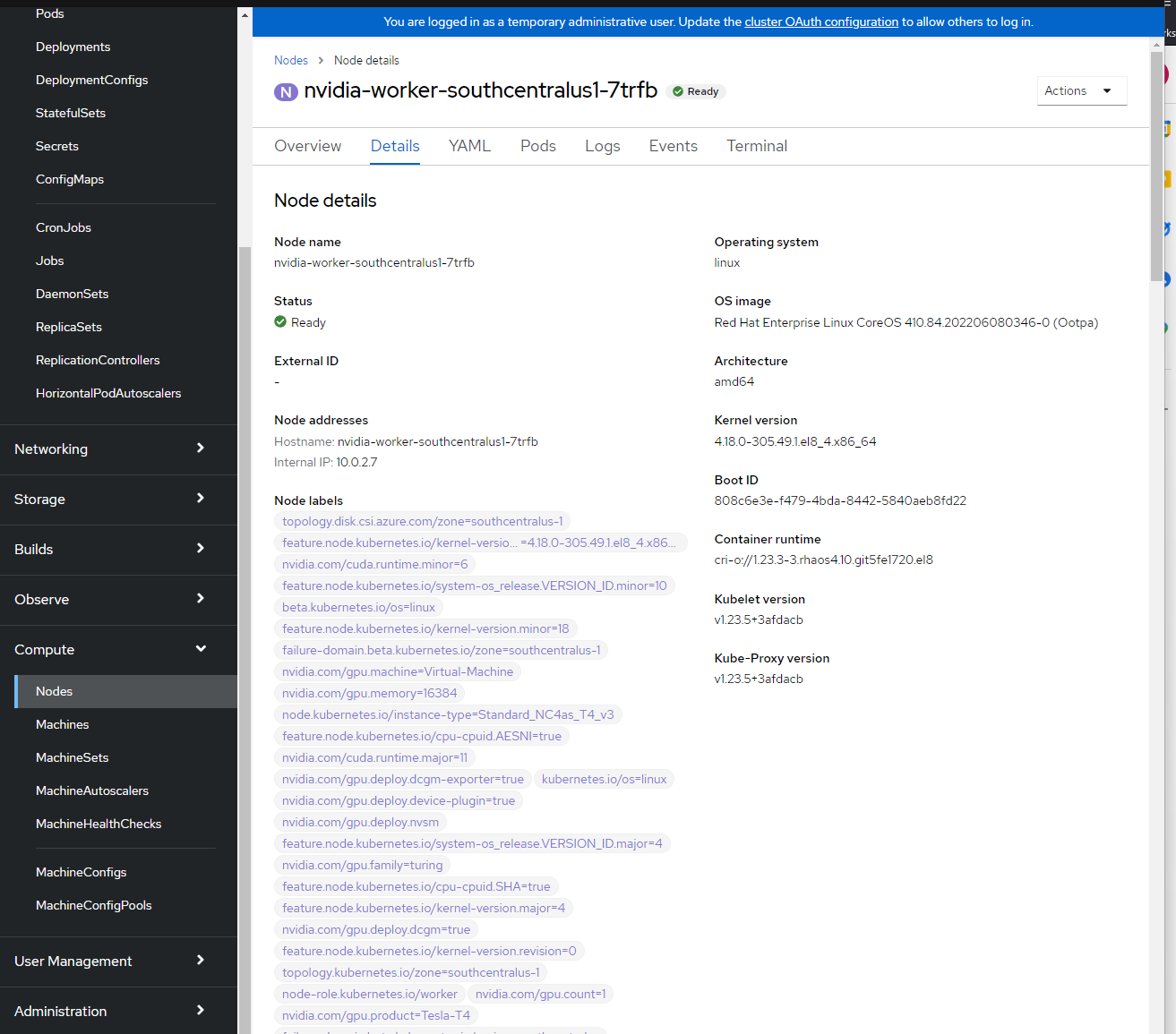
Vous pouvez voir les étiquettes de nœud en vous connectant à la console OpenShift -> Compute -> Nodes -> nvidia-worker-southcentralus1-. Vous devez voir plusieurs étiquettes de GPU NVIDIA et l’appareil pci-10de ci-dessus.
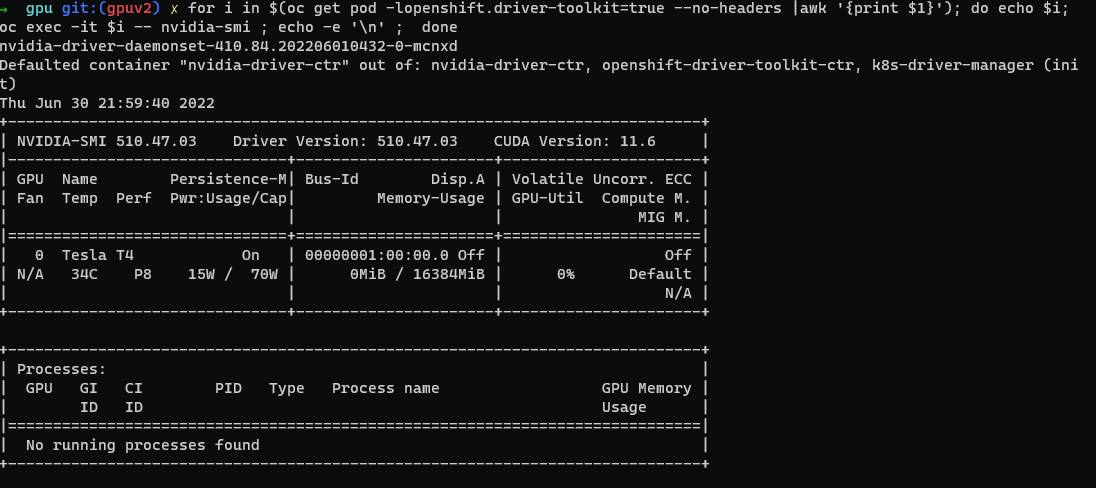
Vérification de l’outil d’interface SMI NVIDIA.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneVous devriez voir la sortie montrant les GPU disponibles sur l’hôte, comme dans cet exemple de capture d’écran. (Varie en fonction du type de rôle de travail GPU)
Créer un pod pour exécuter une charge de travail GPU
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFAffichez les journaux.
oc logs cuda-vector-add --tail=-1
Remarque
Si vous obtenez une erreur Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating, essayez d’exécuter oc delete pod cuda-vector-add, puis réexécutez l’instruction create ci-dessus.
La sortie devrait ressembler à ceci (en fonction du GPU) :
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
En cas de succès, le pod peut être supprimé :
oc delete pod cuda-vector-add