Organiser les données géospatiales avec STAC (SpatioTemporal Asset Catalog)
Cette architecture de référence montre une implémentation de bout en bout de la création d’un catalogue STAC (SpatioTemporal Asset Catalog) pour structurer les données géospatiales. Dans ce document, nous allons utiliser le jeu de données NAIP (National Agriculture Imagery Program) publiquement disponible avec des bibliothèques géospatiales sur Azure. L’architecture peut être adaptée pour accepter des jeux de données provenant d’autres sources telles que des fournisseurs d’images satellites, AOGS (Azure Orbital Ground Station) ou BYOD (Bring Your Own Data).
L’implémentation comprend quatre étapes : acquisition de données, génération des métadonnées, catalogage et découverte de données par le biais de STAC FastAPI. Cet article montre également comment créer un catalogue STAC en fonction d’une nouvelle source de données ou de données apportées par l’utilisateur.
Une implémentation de cette architecture est disponible sur GitHub.
Cet article est destiné aux utilisateurs disposant de compétences intermédiaires en matière d’utilisation des données géospatiales. Reportez-vous au tableau du glossaire pour connaître la définition des termes STAC couramment utilisés. Pour plus d’informations, consultez la page stacspec officielle.
Détails du scénario
La collecte de données spatiales devient de plus en plus courante. Il existe différents fournisseurs de données de ressources spatiotemporelles tels qu’Imagery, SAR (Synthetic Aperture Radar), Point Clouds, etc. Les fournisseurs de données ne disposent pas d’un moyen standard de fournir aux utilisateurs l’accès à leurs données spatiotemporelles. Les utilisateurs de données spatiotemporelles sont souvent contraints de créer des flux de travail uniques pour chaque collection de données différente qu’ils souhaitent consommer. Les développeurs doivent développer de nouveaux outils et bibliothèques pour interagir avec les données spatiotemporelles.
La communauté STAC a défini une spécification pour supprimer ces complexités et encourager le recours à des outils courants. La spécification STAC est un langage courant qui permet de décrire les informations géospatiales afin de faciliter leur utilisation, leur indexation et leur découverte. De nombreux produits déployés sont basés sur STAC, dont Microsoft Planetary Computer, qui fournit un catalogue STAC multi-pétaoctets de données environnementales mondiales pour la recherche sur la durabilité.
Notre exemple de solution utilise des outils open source tels que STAC FastAPI, pystac, les API Microsoft Planetary Computer et des bibliothèques géospatiales standard ouvertes (listées dans la section Composants) pour exécuter la solution sur Azure.
Cas d’usage potentiels
La spécification STAC est devenue une norme du secteur en matière de prise en charge de la structuration et de l’interrogation des données géospatiales. Elle a été utilisée dans de nombreux déploiements de production pour différents cas d’usage.
Voici quelques exemples :
Une société de fournisseurs de données satellites doit faciliter la découverte de leurs données et l’accès à celles-ci. Le fournisseur crée des catalogues STAC pour indexer tous ses jeux de données d’archive historiques ainsi que les données d’actualisation entrantes quotidiennement. Une interface utilisateur cliente web basée sur les API STAC permet aux utilisateurs de parcourir les catalogues et de rechercher les images de leur choix en fonction de la zone d’intérêt, de la plage de dates et de l’intervalle de temps ainsi que d’autres paramètres.
Une société d’analyse des données géospatiales doit créer une base de données de données spatiales, notamment des images, un modèle d’élévation numérique (DEM) et des types 3D qu’elle a acquises à partir de différentes sources de données. La base de données alimente sa solution d’analyse du système d’information géographique (GIS) afin d’agréger différents jeux de données pour l’analyse de détection d’objets basée sur le modèle Machine Learning. Pour prendre en charge une couche d’accès aux données standard, la société décide d’implémenter une interface d’API STAC compatible open source pour la solution d’analyse GIS afin d’interagir avec la base de données de manière scalable et performante.
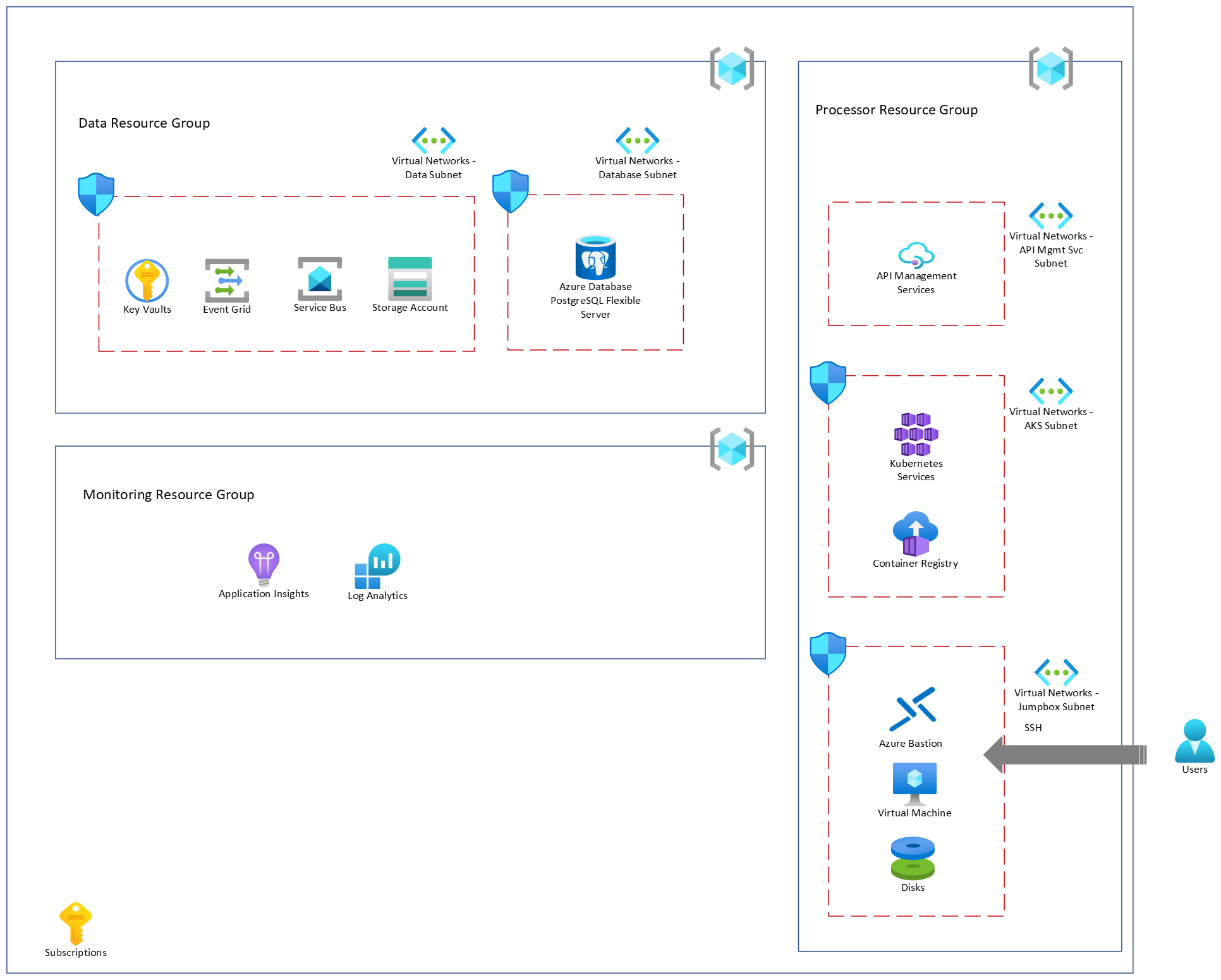
Architecture

Téléchargez un fichier Visio pour cette architecture.
Dataflow

Téléchargez un fichier Visio pour ce flux de données.
Les sections suivantes décrivent les quatre étapes de l’architecture.
Acquisition de données
- Les données spatiales proviennent de différents fournisseurs de données, notamment Airbus, NAIP/USDA (par le biais de l’API Planetary Computer) et Maxar.
- Dans l’exemple de solution, nous utilisons le jeu de données NAIP fourni par Microsoft Planetary Computer.
Génération de métadonnées
- Les fournisseurs de données définissent les métadonnées décrivant le fournisseur, les termes du contrat de licence, les mots clés, etc. Ces métadonnées forment la collection STAC.
- Les fournisseurs de données peuvent fournir des métadonnées décrivant les ressources géospatiales. Dans notre exemple, nous utilisons les métadonnées fournies par NAIP & FGDC. D’autres métadonnées sont extraites des ressources en utilisant des bibliothèques géospatiales standard. Ces métadonnées forment les éléments STAC.
- Cette collection et ces éléments STAC sont utilisés pour créer le catalogue STAC qui aide les utilisateurs à découvrir les ressources spatiotemporelles avec les API STAC.
Catalogage
Catalogue STAC
- Le catalogue STAC est un objet de niveau supérieur qui regroupe logiquement d’autres objets de catalogue, de collection et d’élément. Dans le cadre du déploiement de cette solution, nous créons un catalogue STAC sous lequel est organisée la totalité des collections et des éléments.
Collection STAC
- Il s’agit d’un groupe associé d’éléments STAC mis à disposition par un fournisseur de données.
- Les requêtes de recherche pour découvrir les ressources ont pour portée la collection STAC.
- Elle est générée pour un fournisseur de données, en l’occurrence NAIP, et ces métadonnées JSON sont chargées sur un conteneur Stockage Azure.
- Le chargement d’un fichier de métadonnées de collection STAC déclenche un message pour Azure Service Bus.
- Le processeur traite ces métadonnées sur le cluster Azure Kubernetes et les ingère dans la base de données du catalogue STAC (base de données PostgreSQL). Il existe différents processeurs pour différents fournisseurs de données et chaque processeur s’abonne à la rubrique Service Bus respective.
Élément et ressource STAC
- Ressource qui doit être cataloguée (données raster au format GeoTiff, Cloud Optimized GeoTiff et ainsi de suite). Les métadonnées décrivant la ressource et les métadonnées extraites de celle-ci sont chargées sur le compte de stockage sous le conteneur de stockage approprié.
- Les ressources (GeoTiff) sont chargées sur le compte de stockage sous le conteneur de stockage approprié, une fois les métadonnées correspondantes correctement chargées.
- Chaque ressource et ses métadonnées associées chargées sur le compte de stockage déclenchent un message pour Service Bus. Ces métadonnées forment l’élément STAC dans la base de données du catalogue.
- Le processeur traite ces métadonnées sur le cluster Azure Kubernetes et les ingère dans la base de données du catalogue STAC (base de données PostgreSQL).
Découverte de données
- L’API STAC est basée sur STAC FastAPI open source.
- La couche de l’API STAC est implémentée sur Azure Kubernetes Service et les API sont exposées à l’aide du service Gestion des API.
- Les API STAC sont utilisées pour découvrir les données géospatiales dans votre catalogue. Ces API sont basées sur des spécifications STAC et comprennent les métadonnées STAC définies et indexées dans la base de données du catalogue STAC (serveur PostgreSQL).
- En fonction des critères de recherche, vous pouvez rapidement localiser vos données dans un jeu de données volumineux.
- Interrogation de la collection STAC, des éléments et des ressources :
- Une requête est envoyée par un utilisateur pour rechercher une ou plusieurs collections STAC, Items &Assets via STAC FastAPI.
- STAC FastAPI interroge les données de la base de données PostgreSQL pour récupérer la collection STAC, les éléments et les références aux ressources.
- Le résultat est retourné à l’utilisateur par STAC FastAPI.
- Interrogation de la collection STAC, des éléments et des ressources :
Composants
Les services Azure suivants sont utilisés dans cette architecture.
- Key Vault stocke et contrôle l’accès aux secrets tels que les jetons, mots de passe et clés API. Key Vault crée et contrôle également des clés de chiffrement et gère les certificats de sécurité.
- Service Bus fait partie d’une infrastructure de messagerie Azure plus large qui prend en charge la mise en file d’attente, la publication/l’abonnement et des modèles d’intégration plus avancés.
- Azure Data Lake Storage est un ensemble de fonctionnalités dédiées à l’analytique du Big Data et basées sur le Stockage Blob Azure.
- Le réseau virtuel Azure permet aux ressources Azure de communiquer en toute sécurité entre elles, avec Internet et avec des réseaux locaux.
- Azure Database pour PostgreSQL – Serveur flexible est un service de base de données complètement managé conçu pour offrir un contrôle et une flexibilité plus granulaires des fonctions de gestion de base de données et des paramètres de configuration. Il intègre des fonctionnalités plus riches, par exemple une haute disponibilité (HA) résiliente aux zones, des performances prédictibles, un contrôle maximal, une fenêtre de maintenance personnalisée, des contrôles d’optimisation des coûts ainsi qu’une expérience de développement simplifiée pour vos charges de travail d’entreprise.
- Le service Gestion des API offre une plateforme de gestion des API multicloud scalable pour la sécurisation, la publication et l’analyse des API.
- Azure Kubernetes Service offre le moyen le plus rapide de commencer à développer et à déployer des applications natives cloud, avec des garde-fous et des pipelines « du code au cloud » intégrés.
- Container Registry pour stocker et gérer vos images conteneur et les artefacts associés.
- Une machine virtuelle vous offre la flexibilité de la virtualisation pour un large éventail de solutions de calcul. Dans un déploiement entièrement sécurisé, un utilisateur se connecte à une machine virtuelle via Azure Bastion (décrit ci-après) pour effectuer une gamme d’opérations telles que la copie de fichiers dans des comptes de stockage, l’exécution de commandes Azure CLI et l’interaction avec d’autres services.
- Azure Bastion vous permet de connecter en toute sécurité et en toute transparence RDP et SSH à vos machines virtuelles dans un réseau virtuel Azure, sans avoir besoin d’adresse IP publique sur la machine virtuelle, directement à partir de l’Portail Azure et sans avoir besoin d’un autre client/agent ou d’un logiciel quelconque.
- Application Insights fournit des fonctionnalités extensibles de monitoring et de gestion des performances des applications pour les applications web en production.
- Log Analytics est un outil permettant de modifier et d’exécuter des requêtes de journal à partir de données collectées par les journaux Azure Monitor et d’analyser les résultats de manière interactive.
Les bibliothèques géospatiales suivantes sont également utilisées :
- GDAL est une bibliothèque d’outils permettant de manipuler des données spatiales. La bibliothèque GDAL fonctionne sur les types de données raster et vectorielles. Il s’agit d’un bon outil pour savoir si vous travaillez avec des données spatiales.
- Rasterio est un module pour le traitement des données raster. Vous pouvez l’utiliser pour lire et écrire plusieurs formats raster différents dans Python. Rasterio est basé sur GDAL. Lorsque le module est importé, Python inscrit automatiquement tous les pilotes GDAL connus pour la lecture des formats pris en charge.
- Shapely est un package Python pour l’analyse théorétique et la manipulation des caractéristiques planaires. Il utilise (via le module ctypes de Python) des fonctions de la bibliothèque GEOS largement déployée.
- pyproj effectue des transformations cartographiques. Il effectue des conversions de longitude et latitude en coordonnées x, y de projection de carte native, et vice versa, à l’aide de PROJ.
À propos de l’installation
L’exemple de solution illustre la prise en charge JSON principale de STAC qui est nécessaire pour interagir avec n’importe quelle collection de données géospatiales. Même si STAC normalise les champs de métadonnées, les conventions de nommage, le langage de requête et la structure de catalogue, les utilisateurs doivent également envisager les extensions STAC pour prendre en charge les champs de métadonnées spécifiques à leurs ressources.
Dans l’exemple d’implémentation, les composants qui traitent la ressource pour extraire les métadonnées ont un nombre défini de réplicas. La mise à l’échelle de ce composant vous permet de traiter vos ressources plus rapidement. Toutefois, la mise à l’échelle n’est pas dynamique. S’il est nécessaire de cataloguer un grand nombre de ressources, envisagez de mettre à l’échelle ces réplicas.
Ajout d’une nouvelle source de données
Pour cataloguer plus de sources de données ou cataloguer votre propre source de données, envisagez les options suivantes.
- Définissez la collection STAC pour votre source de données. Les requêtes de recherche ont pour portée la collection STAC. Réfléchissez à la façon dont l’utilisateur recherche les éléments et les ressources STAC dans votre collection.
- Générez les métadonnées des éléments STAC. D’autres métadonnées peuvent être dérivées de ressources géospatiales avec des outils et des bibliothèques standard. Définissez et implémentez le processus de capture de métadonnées supplémentaires pour les ressources qui aident à enrichir les éléments STAC et, par voie de conséquence, facilitent la découverte de données avec des API.
- Une fois ces métadonnées (sous forme de collection STAC et d’éléments STAC) disponibles pour une source de données, cet exemple de solution peut être utilisé pour générer votre catalogue STAC au moyen du même flux. Une fois cataloguées, les données sont interrogeables avec les API STAC standard.
- Il est possible d’étendre le composant processeur de cette architecture pour y inclure du code personnalisé qui peut être développé et exécuté en tant que conteneurs dans le cluster Azure Kubernetes. Ce composant est destiné à fournir une représentation différente des données géospatiales à cataloguer en tant que ressources.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
- L’implémentation de la sécurité des conteneurs d’Azure Kubernetes Service garantit que les processeurs sont générés et exécutés en tant que conteneurs sécurisés.
- La base de référence de sécurité du service Gestion des API fournit des recommandations sur la façon de sécuriser vos solutions cloud sur Azure.
- La sécurité dans Azure Database pour PostgreSQL couvre en profondeur la sécurité au niveau de plusieurs couches quand des données sont stockées sur un serveur flexible PostgreSQL, notamment dans le cadre de scénarios de données au repos et de données en transit.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Comme cette solution est destinée à l’apprentissage et au développement, nous avons utilisé une configuration minimale pour les ressources Azure. Cette configuration minimale exécute un exemple de solution sur un exemple de jeu de données.
Pour être performants, les utilisateurs peuvent également ajuster les configurations en fonction de leurs besoins en matière de charge de travail et de mise à l’échelle. Par exemple, vous pouvez remplacer des disques durs HDD Standard par des disques SSD Premium dans votre cluster AKS ou mettre à l’échelle le service Gestion des API vers des références SKU Premium.
Efficacité des performances
L’efficacité des performances est la capacité de votre charge de travail à s’adapter à la demande des utilisateurs de façon efficace. Pour plus d’informations, consultez Vue d’ensemble du pilier d’efficacité des performances. En outre, les conseils suivants peuvent être utiles pour optimiser l’efficacité des performances :
- Les fonctionnalités de supervision et d’optimisation offrent un moyen de superviser vos données et de régler votre base de données afin d’améliorer les performances.
- La page Optimisation des performances d’une application distribuée vous guide dans quelques scénarios différents, et vous montre comment identifier les métriques clés et améliorer les performances.
- La page Architecture de référence pour un cluster Azure Kubernetes Service (AKS) recommande une architecture d’infrastructure de référence pour déployer un cluster Azure Kubernetes Service (AKS) sur Azure.
- La page Améliorer les performances d’une API en ajoutant une stratégie de mise en cache dans Gestion des API Azure est un module de formation sur l’amélioration des performances par le biais de la stratégie de mise en cache.
Déployer ce scénario
Nous avons créé un exemple de solution qui peut être déployé dans votre abonnement. Cette solution permet aux utilisateurs de valider le flux de données global avec les API STAC standard, des métadonnées STAC à la découverte des ressources en passant par l’ingestion. Les instructions de déploiement et les étapes de validation sont documentées dans le fichier README.
Globalement, ce déploiement effectue les opérations suivantes :
Déploie différents composants d’infrastructure tels qu’Azure Kubernetes Services, un serveur Azure PostgreSQL, Azure Key Vault, un compte Stockage Azure, Azure Service Bus, etc. dans le réseau privé.
Déploie le service Azure Gestion des API et publie le point de terminaison pour STAC FastAPI.
Empaquette le code et ses dépendances, génère les images conteneur Docker et les pousse (push) vers Azure Container Registry.

Téléchargez un fichier Visio pour cette implémentation.
Étapes suivantes
Si vous souhaitez vous lancer, nous mettons à votre disposition un exemple de solution abordé brièvement ci-dessus. Vous trouverez ci-dessous quelques liens utiles pour commencer à implémenter STAC &model.
Ressources associées
- Microsoft Planetary Computer permet aux utilisateurs de tirer parti de la puissance du cloud pour accélérer la durabilité environnementale et faire progresser la science de la Terre. La plupart des composants de Planetary Computer sont également open source.
- Spécification STAC
- STAC FastAPI
- PySTAC
- PgSTAC
- pyPgSTAC
- NAIP
- FGDC
Glossaire
| Terme STAC | Définition |
|---|---|
| Actif | Tout fichier qui représente des données spatiales capturées dans un espace et à un moment donnés. |
| Spécification STAC | Vous permet de décrire les données géospatiales afin qu’elles puissent être facilement indexées et découvertes. |
| Élément STAC | Unité atomique principale, représentant une ressource spatiotemporelle unique en tant que fonctionnalité GeoJSON ainsi que des métadonnées telles que les données de date et d’heure et des liens de référence. |
| Catalogue STAC | JSON simple et flexible qui fournit une structure et organise les métadonnées telles que les éléments STAC, les collections et d’autres catalogues. |
| Collection STAC | Fournit des informations supplémentaires telles que les étendues, la licence, les mots clés, les fournisseurs, etc., qui décrivent les éléments STAC de la collection. |
| API STAC | Fournit un point de terminaison RESTful qui permet la recherche d’éléments STAC, spécifié dans OpenAPI. |