Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À :  Azure Database pour PostgreSQL – Serveur flexible
Azure Database pour PostgreSQL – Serveur flexible
Le serveur flexible Azure Database pour PostgreSQL permet d’étendre les fonctionnalités de votre base de données avec des extensions. Les extensions regroupent plusieurs objets SQL associés au sein d’un package qui peut être chargé ou supprimé de votre base de données à l’aide d’une commande. Une fois chargées dans la base de données, les extensions fonctionnent comme des fonctionnalités intégrées.
Guide pratique pour utiliser les extensions PostgreSQL
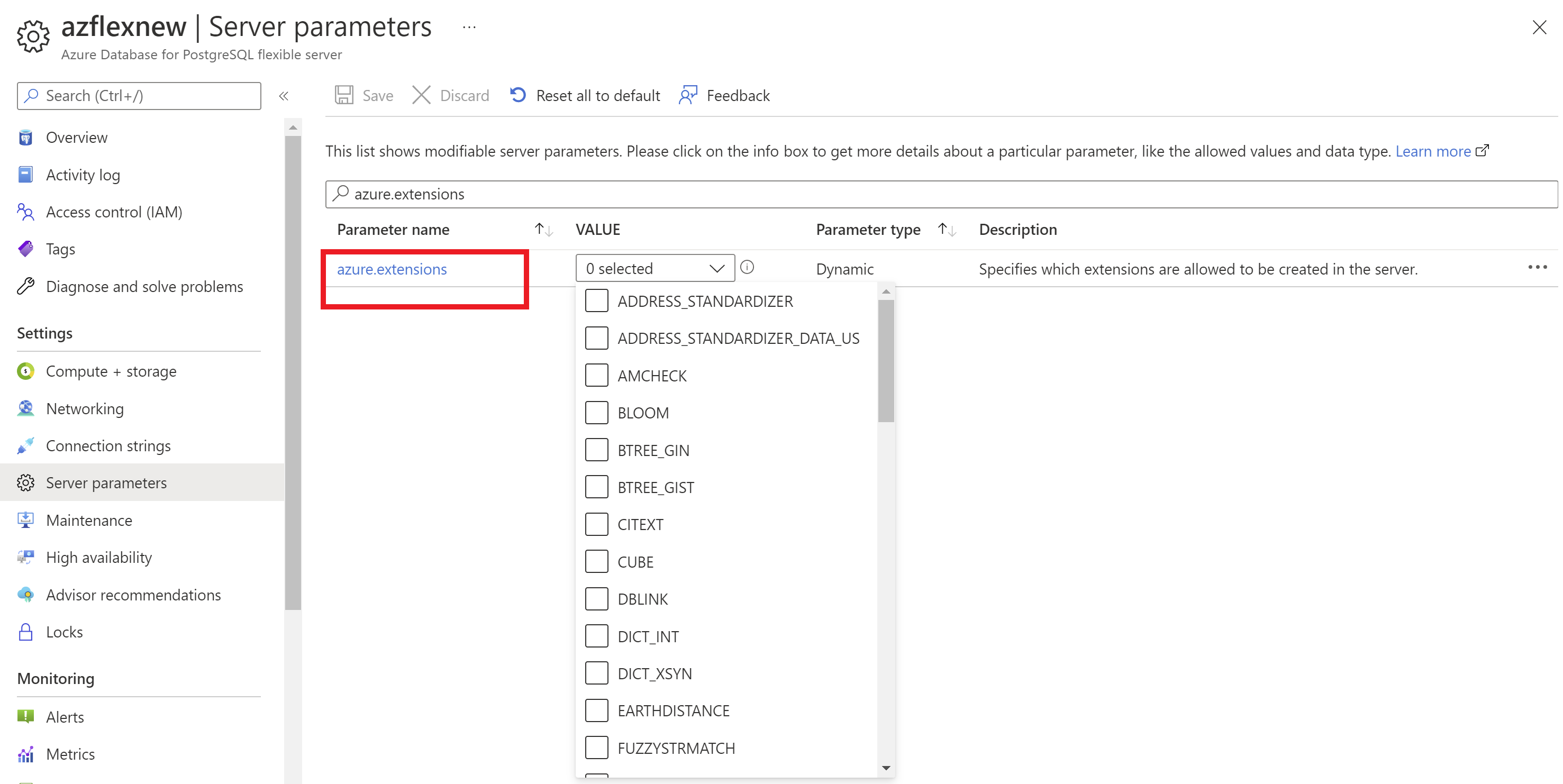
Avant d’installer des extensions dans le serveur flexible Azure Database pour PostgreSQL, vous devez les ajouter à la liste d’autorisation pour les utiliser.
À l’aide du Portail Azure :
- Sélectionnez votre instance de serveur flexible Azure Database pour PostgreSQL.
- Dans le menu des ressources, sous la section Paramètres, sélectionnez Paramètres du serveur.
- Recherchez le paramètre
azure.extensions. - Sélectionnez les extensions à ajouter à la liste d’autorisation.

Avec Azure CLI :
Vous pouvez ajouter des extensions à la liste d’autorisation en utilisant la commande CLI « parameter set ».
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
À l’aide d’un modèle ARM : l’exemple suivant ajoute à la liste d’autorisation les extensions dblink, dict_xsyn et pg_buffercache sur un serveur nommé postgres-test-server :
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries est un paramètre de configuration de serveur qui détermine les bibliothèques à charger lors du démarrage du serveur flexible Azure Database pour PostgreSQL. Toutes les bibliothèques qui utilisent de la mémoire partagée doivent être chargées via ce paramètre. Si votre extension doit être ajoutée aux bibliothèques de préchargement partagées, effectuez ces étapes :
À l’aide du Portail Azure :
- Sélectionnez votre instance de serveur flexible Azure Database pour PostgreSQL.
- Dans le menu des ressources, sous la section Paramètres, sélectionnez Paramètres du serveur.
- Recherchez le paramètre
shared_preload_libraries. - Sélectionnez les bibliothèques à ajouter.
:::image type="content" source="./media/concepts-extensions/shared-libraries.png" alt-text="Screenshot showing Azure Database for PostgreSQL -setting shared preload libraries parameter setting for extensions installation." lightbox="./media/concepts-extensions/shared-libraries.png":::
```Using [Azure CLI](/cli/azure/):
You can set `shared_preload_libraries` via CLI [parameter set](/cli/azure/postgres/flexible-server/parameter?view=azure-cli-latest&preserve-view=true) command.
```azurecli
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
Créer une extension
Une fois les extensions ajoutées à la liste d’autorisation et chargées, vous devez les installer dans les bases de données sur lesquelles vous prévoyez de les utiliser.
- Pour créer une extension, l’utilisateur doit être membre du rôle
azure_pg_admin. Un membre du rôleazure_pg_adminpeut accorder des privilèges de création d’extensions à d’autres utilisateurs. - Pour installer une extension, vous devez exécuter la commande CREATE EXTENSION. Cette commande charge les objets empaquetés dans votre base de données.
Remarque
Les extensions tierces proposées dans le serveur flexible Azure Database pour PostgreSQL disposent d’un code sous licence open source. Nous n’offrons actuellement aucune extension ou aucune version d’extension tierce avec des modèles de licence Premium ou propriétaires.
L’instance de serveur flexible Azure Database pour PostgreSQL prend en charge un sous-ensemble d’extensions PostgreSQL clés qui sont répertoriées dans le tableau suivant. Ces informations sont également disponibles en exécutant SHOW azure.extensions;. Les extensions non listées dans ce document ne sont pas prises en charge sur le serveur flexible Azure Database pour PostgreSQL. Vous ne pouvez ni créer ni charger votre propre extension dans le serveur flexible Azure Database pour PostgreSQL.
Versions d’extension
Les extensions suivantes sont disponibles dans le serveur flexible Azure Database pour PostgreSQL :
Remarque
Les extensions du tableau suivant avec la ✔️ marque nécessitent que leurs bibliothèques correspondantes soient activées dans le paramètre de serveur shared_preload_libraries .
| Nom de l’extension | Description | PostgreSQL 17 | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|---|
| address_standardizer | Utilisé pour analyser une adresse et la décomposer en éléments constitutifs, généralement afin de prendre en charge l’étape de normalisation des adresses par géocodage. | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Exemple de jeu de données de normalisation des adresses aux États-Unis | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| âge (préversion) | Fournit des fonctionnalités de base de données de graphe | S/O | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | N/A | N/A |
| amcheck | Fonctions permettant de vérifier l’intégrité de la relation | 1.4 | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1.1 |
| anon (préversion) | Outils d’anonymisation des données | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ |
| azure_ai | Intégration d’Azure AI et de ML Services pour PostgreSQL | S/O | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | S/O |
| azure_storage | Intégration d’Azure pour PostgreSQL | S/O | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | S/O |
| bloom | Méthode d’accès Bloom, index basé sur un fichier de signature | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | Prise en charge de l’indexation des types de données communs dans GIN | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | Prise en charge de l’indexation des types de données communs dans GiST | 1.7 | 1.7 | 1.7 | 1.6 | 1.5 | 1.5 | 1.5 |
| citext | Type de données des chaînes de caractères sans respect de la casse | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| cube | Type de données pour les cubes multidimensionnels | 1.5 | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | Se connecte à d’autres bases de données PostgreSQL à partir d’une base de données | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Modèle de dictionnaire de recherche de texte pour les entiers | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | Modèle de dictionnaire de recherche de texte pour le traitement de synonyme étendu | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | Calcule les distances orthodromiques à la surface de la Terre | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| fuzzystrmatch | Détermine les ressemblances et la distance entre les chaînes | 1,2 | 1.2 | 1.1 | 1.1 | 1.1 | 1.1 | 1,1 |
| hstore | Type de données permettant de stocker des paires clé/valeur | 1.8 | 1.8 | 1.8 | 1.8 | 1.7 | 1.6 | 1.5 |
| hypopg | Index hypothétiques pour PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Agrégateur et énumérateur d’entier (obsolète) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| intarray | Fonctions, opérateurs et prise en charge d’index pour les tableaux d’entiers 1D | 1.5 | 1.5 | 1.5 | 1.5 | 1.3 | 1.2 | 1.2 |
| isn | Types de données pour les standards internationaux de numérotation de produits | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| lo | Maintenance des objets volumineux (Large Object) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1,1 |
| login_hook | Login_hook – hook pour exécuter login_hook.login() au moment de la connexion | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Type de données pour les structures hiérarchiques de type arborescence | 1.3 | 1.2 | 1.2 | 1.2 | 1.2 | 1.1 | 1,1 |
| oracle_fdw | Enveloppe de données étrangères pour les bases de données Oracle | 1,2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | S/O |
| orafce | Fonctions et opérateurs qui émulent un sous-ensemble de fonctions et de packages à partir du système de gestion de base de données relationnelle Oracle | 4,9 | 4.4 | 3.24 | 3,18 | 3,18 | 3,18 | 3.7 |
| pageinspect | Inspectez le contenu de pages de base de données de bas niveau | 1.12 | 1.12 | 1.11 | 1.9 | 1.8 | 1.7 | 1.7 |
| pgaudit | Fournit des fonctionnalités d’audit | 16.0 ✔️ | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4.3 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Examine le cache des tampons partagé | 1.5 | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | Planificateur de travaux pour PostgreSQL | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Fonctions de chiffrement | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_freespacemap | Examinez le mappage d’espace libre (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Permet d’ajuster les plans d’exécution PostgreSQL à l’aide de « conseils » dans les commentaires SQL. | 1.7.0 ✔️ | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | Réplication logique PostgreSQL | 2.4.5 ✔️ | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Extension pour gérer les tables partitionnées par date et heure ou par ID | 5.0.1 ✔️ | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Préchauffe les données de relation | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Réorganiser les tables dans les bases de données PostgreSQL avec des verrous minimaux | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | Extension PgRouting | N/A | N/A | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Affiche les informations de verrouillage au niveau des lignes | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | Outil permettant de supprimer l’espace inutilisé d’une relation. | 1.7 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | Suit les statistiques d’exécution de toutes les instructions SQL exécutées | 1.11 ✔️ | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Affiche les statistiques au niveau du tuple | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | Mesure de la similarité du texte et recherche d’index sur la base de trigrammes | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | Examinez le mappage de visibilité (machine virtuelle) et les informations de visibilité au niveau des pages | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | Langage procédural PL/pgSQL | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | Langage procédural PL/JavaScript (v8) approuvé | 3.1.7 | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | Fonctions et types spatiaux de géométrie et géographie PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | Types et fonctions raster PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | Fonctions SFCGAL PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | PostGIS tiger geocoder et geocoder inverse | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | Types et fonctions spatiaux de topologie PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Wrapper de données externes pour les serveurs PostgreSQL distants | 1.1 | 1.1 | 1.1 | 1,1 | 1.0 | 1.0 | 1.0 |
| postgres_protobuf | Mémoires tampons de protocole pour PostgreSQL | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | 0.2 | S/O |
| semver | Type de données de version sémantique | 0.32.1 | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable – inscription et manipulation des variables de session et des constantes | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Informations sur les certificats SSL | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Fonctions qui manipulent des tables entières, y compris les tables d’analyse croisée | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | Wrapper de données étrangères pour interroger une base de données TDS (Sybase ou Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Permet des insertions scalables et des requêtes complexes pour les données de séries chronologiques | S/O | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | méthode TABLESAMPLE, qui accepte le nombre de lignes en tant que limite | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | méthode TABLESAMPLE, qui accepte le temps en millisecondes en tant que limite | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| unaccent | Dictionnaire de recherche de texte qui supprime les accents | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1,1 |
| uuid-ossp | Génère des identificateurs uniques universels (UUID). | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1,1 |
| vector | Types de données vectorielles et méthodes d’accès ivfflat et hnsw | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Mise à niveau des extensions PostgreSQL
Les mises à niveau sur place des extensions de base de données sont autorisées avec une commande simple. Cette fonctionnalité permet aux clients de mettre automatiquement à jour leurs extensions tierces vers les dernières versions, en maintenant les systèmes à jour et sécurisés sans effort manuel.
Mise à jour des extensions
Pour mettre à jour une extension installée vers la dernière version disponible prise en charge par Azure, utilisez la commande SQL suivante :
ALTER EXTENSION <extension_name> UPDATE;
Cette commande simplifie la gestion des extensions de base de données en permettant aux utilisateurs de passer manuellement à la dernière version approuvée par Azure, ce qui renforce la compatibilité et la sécurité.
Limites
Bien que la mise à jour des extensions soit simple, il existe certaines limitations :
- Sélection d’une version spécifique : la commande ne prend pas en charge la mise à jour vers les versions intermédiaires d’une extension. La mise à jour porte toujours sur la dernière version disponible.
- Rétrogradation : ne prend pas en charge la rétrogradation d’une extension vers une version précédente. Si une rétrogradation est nécessaire, elle peut nécessiter une assistance de support et dépend de la disponibilité de la version précédente.
Extensions installées
Pour lister les extensions actuellement installées sur votre base de données, utilisez la commande SQL suivante :
SELECT * FROM pg_extension;
Extensions disponibles et leurs versions
Pour vérifier les versions disponibles d’une extension pour l’installation actuelle de votre base de données, interrogez la vue du catalogue système pg_available_extensions. Par exemple, pour déterminer la version disponible pour l’extension azure_ai, exécutez :
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
Ces commandes fournissent des insights nécessaires sur les configurations d’extension de votre base de données, ce qui vous permet de gérer vos systèmes efficacement et de manière sécurisée. En activant les mises à jour faciles des dernières versions d’extension, Azure Database pour PostgreSQL continue de prendre en charge la gestion robuste, sécurisée et efficace de vos applications de base de données.
Considérations propres au serveur flexible Azure Database pour PostgreSQL
Voici la liste des extensions prises en charge qui nécessitent des considérations spécifiques en cas d’utilisation dans le service du serveur flexible Azure Database pour PostgreSQL. La liste est triée par ordre alphabétique.
dblink
dblink vous permet de vous connecter d’une instance de serveur flexible Azure Database pour PostgreSQL à une autre, ou à une autre base de données dans le même serveur. Le serveur flexible Azure Database pour PostgreSQL prend en charge les connexions entrantes et sortantes vers n’importe quel serveur PostgreSQL. Le serveur d’envoi doit autoriser les connexions sortantes vers le serveur de réception. De même, le serveur de réception doit autoriser les connexions à partir du serveur d’envoi.
Nous vous recommandons de déployer vos serveurs avec intégration au réseau virtuel si vous envisagez d’utiliser cette extension. Par défaut, l’intégration au réseau virtuel autorise les connexions entre les serveurs du réseau virtuel. Vous pouvez également choisir d’utiliser des groupes de sécurité réseau de réseau virtuel pour personnaliser l’accès.
pg_buffercache
pg_buffercache peut être utilisé pour étudier le contenu de shared_buffers. À l’aide de cette extension vous pouvez savoir si une relation particulière est mise en cache ou non (dans shared_buffers). Cette extension peut vous aider à résoudre les problèmes de performances (mise en cache des problèmes de performances associés).
Cette extension, intégrée à l’installation principale de PostgreSQL, est facile à installer.
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron est un planificateur de travaux simple basé sur cron pour PostgreSQL qui s’exécute dans la base de données en tant qu’extension. L’extension pg_cron peut être utilisée pour exécuter des tâches de maintenance planifiées dans une base de données PostgreSQL. Par exemple, vous pouvez exécuter le vide périodique d’une table ou supprimer d’anciens travaux de données.
pg_cron peut exécuter plusieurs travaux en parallèle, mais il exécute au plus une instance d’un travail à la fois. Si une deuxième exécution est censée démarrer avant la fin de la première, la deuxième exécution est mise en file d’attente et démarrée dès que la première exécution est terminée. De cette façon, les travaux s’exécutent exactement autant de fois que prévu et ne s’exécutent pas simultanément avec eux-mêmes.
Exemples :
Pour supprimer les anciennes données le samedi à 3h30 (GMT)
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Pour exécuter le vide tous les jours à 10h00 (GMT) dans la base de données par défaut postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Pour annuler la planification de toutes les tâches de pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
Pour afficher tous les travaux actuellement planifiés avec pg_cron.
SELECT * FROM cron.job;
Pour exécuter le vide tous les jours à 10 h (GMT) dans la base de données « testcron » sous azure_pg_admin compte de rôle.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Remarque
pg_cron extension est préchargée dans shared_preload_libraries pour chaque instance de serveur flexible Azure Database pour PostgreSQL à l’intérieur de la base de données postgres pour vous permettre de planifier des travaux à exécuter dans d’autres bases de données au sein de votre instance de base de données flexible Azure Database pour PostgreSQL sans compromettre la sécurité. Toutefois, pour des raisons de sécurité, vous devez toujours ajouter à une liste d’autorisation l’extension pg_cron et l’installer avec la commande CREATE EXTENSION.
À partir de pg_cron version 1.4, vous pouvez utiliser les fonctions cron.schedule_in_database et cron.alter_job pour planifier votre travail dans une base de données spécifique et mettre à jour une planification existante respectivement.
Exemples :
Pour supprimer les anciennes données le samedi à 3h30 (GMT) sur la base de données DBName
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Remarque
cron_schedule_in_database fonction autorise le nom d’utilisateur comme paramètre facultatif. La définition du nom d’utilisateur sur une valeur non null nécessite le privilège de superutilisateur PostgreSQL et n’est pas prise en charge dans le serveur flexible Azure Database pour PostgreSQL. Les exemples précédents montrent l’exécution de cette fonction avec un paramètre de nom d’utilisateur facultatif omis ou défini sur null, qui exécute le travail dans le contexte de la planification du travail par l’utilisateur, lequel doit avoir les privilèges du rôle azure_pg_admin.
Pour mettre à jour ou modifier le nom de la base de données pour la planification existante
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots
L’extension PG Failover Slots améliore le serveur flexible Azure Database pour PostgreSQL quand il fonctionne à la fois avec une réplication logique et des serveurs à haute disponibilité. Elle résout efficacement le défi au sein du moteur PostgreSQL standard qui ne conserve pas les emplacements de réplication logique après un basculement. La maintenance de ces emplacements est essentielle pour empêcher les interruptions de réplication ou les incompatibilités de données pendant les modifications de rôle serveur principal, ce qui garantit la continuité opérationnelle et l’intégrité des données.
L’extension simplifie le processus de basculement en gérant le transfert, le nettoyage et la synchronisation nécessaires des emplacements de réplication, ce qui offre une transition transparente pendant les modifications de rôle serveur. L’extension est prise en charge pour PostgreSQL versions 11 à 16.
Vous trouverez plus d’informations et comment utiliser l’extension PG Failover Slots sur sa page GitHub.
Activer pg_failover_slots
Pour activer l’extension PG Failover Slots pour votre instance de serveur flexible Azure Database pour PostgreSQL, vous devez modifier la configuration du serveur en incluant l’extension dans les bibliothèques de préchargement partagées du serveur et en ajustant un paramètre de serveur spécifique. Le processus est le suivant :
- Ajoutez
pg_failover_slotsaux bibliothèques de préchargement partagées du serveur en mettant à jour le paramètreshared_preload_libraries. - Remplacez le paramètre
hot_standby_feedbackdu serveur paron.
Toutes les modifications apportées au paramètre shared_preload_libraries nécessitent un redémarrage du serveur.
À l’aide du Portail Azure :
- Sélectionnez votre instance de serveur flexible Azure Database pour PostgreSQL.
- Dans le menu des ressources, sous la section Paramètres, sélectionnez Paramètres du serveur.
- Recherchez le paramètre
shared_preload_librarieset modifiez sa valeur pour inclurepg_failover_slots. - Recherchez le paramètre
hot_standby_feedbacket définissez sa valeur suron. - Sélectionnez Enregistrer pour conserver vos modifications. Vous pouvez à présent Enregistrer et redémarrer. Choisissez cette option pour vérifier que les modifications prennent effet, car la modification de
shared_preload_librariesnécessite un redémarrage du serveur.
En sélectionnant Enregistrer et redémarrer, votre serveur redémarre automatiquement et applique les modifications que vous venez d’apporter. Une fois que le serveur est de retour en ligne, l’extension PG Failover Slots est activée et opérationnelle sur votre instance de serveur flexible Azure Database pour PostgreSQL principale, prête à gérer les emplacements de réplication logique pendant les basculements.
pg_hint_plan
pg_hint_plan permet d’ajuster les plans d’exécution PostgreSQL à l’aide de ce que l’on appelle des « indicateurs » dans les commentaires SQL, comme
/*+ SeqScan(a) */
pg_hint_plan lit les expressions d’indication dans un commentaire de forme spéciale donnée avec l’instruction SQL cible. La forme spéciale commence par la séquence de caractères « /*+ » et se termine par « */ ». Les phrases indicatives se composent du nom de l’indicateur et des paramètres suivants entre parenthèses et délimités par des espaces. De nouvelles lignes peuvent délimiter chaque expression d’indicateur, pour plus de lisibilité.
Exemple :
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
L’exemple précédent oblige le planificateur à utiliser les résultats d’un seq scan sur la table a à combiner avec la table b en tant que hash join.
Pour installer pg_hint_plan, en plus de l’ajouter à la liste d’autorisation comme indiqué dans le guide pratique pour utiliser les extensions PostgreSQL, vous devez l’inclure dans les bibliothèques de préchargement partagées du serveur. Une modification apportée au paramètre shared_preload_libraries de Postgres nécessite un shared_preload_libraries pour prendre effet. Vous pouvez modifier les paramètres à l’aide du portail Azure ou d’Azure CLI.
À l’aide du Portail Azure :
- Sélectionnez votre instance de serveur flexible Azure Database pour PostgreSQL.
- Dans le menu des ressources, sous la section Paramètres, sélectionnez Paramètres du serveur.
- Recherchez le paramètre
shared_preload_librarieset modifiez sa valeur pour inclurepg_hint_plan. - Sélectionnez Enregistrer pour conserver vos modifications. Vous pouvez à présent Enregistrer et redémarrer. Choisissez cette option pour vérifier que les modifications prennent effet, car la modification de
shared_preload_librariesnécessite un redémarrage du serveur. Vous pouvez maintenant activer pg_hint_plan dans votre base de données de serveur flexible Azure Database pour PostgreSQL. Connectez-vous à la base de données et exécutez la commande suivante :
CREATE EXTENSION pg_hint_plan;
pg_prewarm
L’extension pg_prewarm charge les données relationnelles dans le cache. Le préchauffage de vos caches signifie que vos requêtes ont de meilleurs temps de réponse lors de leur première exécution après un redémarrage. La fonctionnalité de préchauffage automatique n’est actuellement pas disponible dans le serveur flexible Azure Database pour PostgreSQL.
pg_repack
Une question qui revient fréquemment lors de la première utilisation de cette extension est la suivante : est-ce que pg_repack est une extension ou un exécutable côté client comme psql ou pg_dump ?
Il s’agit en fait des deux. pg_repack/lib contient le code de l’extension, y compris le schéma et les artefacts SQL qu’il crée, et la bibliothèque C implémentant le code de plusieurs de ces fonctions. D’un autre côté, pg_repack/bin conserve le code de l’application cliente, qui sait comment interagir avec les artefacts de programmabilité créés par l’extension. Cette application cliente vise à simplifier l’interaction avec les différentes interfaces exposées par l’extension côté serveur, en offrant à l’utilisateur des options de ligne de commande plus faciles à comprendre. L’application cliente sans l’extension créée sur la base de données vers laquelle elle pointe est inutilisable. L’extension côté serveur serait en soi entièrement fonctionnelle, mais elle exigerait que l’utilisateur comprenne un modèle d’interaction complexe consistant à exécuter des requêtes pour récupérer des données utilisées en entrée dans des fonctions implémentées par l’extension.
Autorisation refusée pour le schéma repack
Pour l’instant, compte tenu de la façon dont nous accordons les autorisations au schéma repack créé par cette extension, l’exécution de la fonctionnalité pg_repack n’est prise en charge qu’à partir du contexte de azure_pg_admin.
Vous remarquerez peut-être que si le propriétaire d’une table, qui n’est pas azure_pg_admin, tente d’exécuter pg_repack, il finit par recevoir une erreur semblable à la suivante :
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
Pour éviter cette erreur, veillez à exécuter pg_repack à partir du contexte de azure_pg_admin.
pg_stat_statements
L’extension pg_stat_statements vous donne une vue de toutes les requêtes qui ont été exécutées sur votre base de données. C’est très utile pour se faire une idée du niveau de performance de votre charge de travail de requêtes sur un système de production.
L’extension pg_stat_statements est préchargée dans shared_preload_libraries sur chaque instance de serveur flexible Azure Database pour PostgreSQL pour vous fournir un moyen de suivre les statistiques d’exécution des instructions SQL.
Toutefois, pour des raisons de sécurité, vous devez toujours établir une liste d’autorisation avec l’extension pg_stat_statements et installer celle-ci avec la commande CREATE EXTENSION.
Le paramètre pg_stat_statements.track, qui contrôle quelles instructions sont comptées par l’extension, a la valeur par défaut top, ce qui signifie que toutes les instructions exécutées directement par les clients sont suivies. Les deux autres niveaux de suivi sont none et all. Ce paramètre peut être configuré en tant que paramètre de serveur.
Il y a un compromis entre les informations d’exécution des requêtes fournies par pg_stat_statements et l’impact sur les performances du serveur en raison de la journalisation de chaque instruction SQL. Si vous n’utilisez pas activement l’extension pg_stat_statements, nous vous recommandons de définir pg_stat_statements.track sur none. Certains services de supervision tiers peuvent s’appuyer sur pg_stat_statements pour fournir des insights sur les performances des requêtes. Vérifiez donc si c’est le cas pour vous ou non.
postgres_fdw
postgres_fdw vous permet de vous connecter d’une instance de serveur flexible Azure Database pour PostgreSQL à une autre, ou à une autre base de données dans le même serveur. Le serveur flexible Azure Database pour PostgreSQL prend en charge les connexions entrantes et sortantes vers n’importe quel serveur PostgreSQL. Le serveur d’envoi doit autoriser les connexions sortantes vers le serveur de réception. De même, le serveur de réception doit autoriser les connexions à partir du serveur d’envoi.
Nous vous recommandons de déployer vos serveurs avec intégration au réseau virtuel si vous envisagez d’utiliser cette extension. Par défaut, l’intégration au réseau virtuel autorise les connexions entre les serveurs du réseau virtuel. Vous pouvez également choisir d’utiliser des groupes de sécurité réseau de réseau virtuel pour personnaliser l’accès.
pgstattuple
Lorsque vous utilisez l’extension « pgstattuple » pour essayer d’obtenir des statistiques tuple à partir d’objets conservés dans le schéma pg_toast dans les versions de Postgres 11 à 13, vous recevrez une erreur « permission denied for schema pg_toast » (autorisation refusée pour le schéma pg_toast).
Autorisation refusée pour le schéma pg_toast
Les clients utilisant PostgreSQL versions 11 à 13 sur Azure Database pour serveur flexible ne peuvent pas utiliser l’extension pgstattuple sur les objets dans le schéma pg_toast.
Dans PostgreSQL 16 et 17, le rôle pg_read_all_data est automatiquement accordé à azure_pg_admin, ce qui permet à pgstattuple de fonctionner correctement. Dans PostgreSQL 14 et 15, les clients peuvent accorder manuellement le rôle pg_read_all_data à azure_pg_admin pour obtenir le même résultat. Toutefois, dans PostgreSQL 11 à 13, le rôle pg_read_all_data n’existe pas.
Les clients ne peuvent pas accorder directement les autorisations nécessaires. Si vous devez être en mesure d’exécuter pgstattuple pour accéder aux objets sous le schéma pg_toast, procédez à la création d’une demande de support Azure.
TimescaleDB
TimescaleDB est une base de données de séries chronologiques empaquetée en tant qu’extension pour PostgreSQL. TimescaleDB fournit des fonctions analytiques axées sur le temps et des optimisations et met à l’échelle PostgreSQL pour les charges de travail de série chronologique. En savoir plus sur TimescaleDB, marque déposée de Timescale, Inc. Le serveur flexible Azure Database pour PostgreSQL fournit l’édition Apache-2 de TimescaleDB.
Installer TimescaleDB
Pour installer TimescaleDB, en plus d’autoriser son référencement, comme indiqué ci-dessus, vous devez l’inclure dans les bibliothèques de préchargement partagées du serveur. Une modification apportée au paramètre shared_preload_libraries de Postgres nécessite un shared_preload_libraries pour prendre effet. Vous pouvez modifier les paramètres à l’aide du portail Azure ou d’Azure CLI.
À l’aide du Portail Azure :
- Sélectionnez votre instance de serveur flexible Azure Database pour PostgreSQL.
- Dans le menu des ressources, sous la section Paramètres, sélectionnez Paramètres du serveur.
- Recherchez le paramètre
shared_preload_librarieset modifiez sa valeur pour inclureTimescaleDB. - Sélectionnez Enregistrer pour conserver vos modifications. Vous pouvez à présent Enregistrer et redémarrer. Choisissez cette option pour vérifier que les modifications prennent effet, car la modification de
shared_preload_librariesnécessite un redémarrage du serveur. Vous pouvez maintenant activer TimescaleDB dans votre base de données de serveur flexible Azure Database pour PostgreSQL. Connectez-vous à la base de données et exécutez la commande suivante :
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Conseil
Si vous voyez une erreur, vérifiez que vous avez redémarré le serveur après l’enregistrement de shared_preload_libraries.
Vous pouvez maintenant créer une hypertable TimescaleDB à partir de zéro ou migrer des données de série chronologiques existantes dans PostgreSQL.
Restaurer une base de données d’échelle de temps à l’aide de pg_dump et pg_restore
Pour restaurer une base de données d’échelle de temps à l’aide de pg_dump et pg_restore, vous devez exécuter deux procédures d’assistance dans la base de données de destination : timescaledb_pre_restore() et timescaledb_post restore().
Préparez d’abord la base de données de destination :
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
Vous pouvez maintenant exécuter pg_dump sur la base de données d’origine, puis effectuer pg_restore. Après la restauration, veillez à exécuter la commande suivante dans la base de données restaurée :
SELECT timescaledb_post_restore();
Pour plus d’informations sur la méthode de restauration avec une base de données avec une échelle de temps, consultez la documentation relative à l’échelle de temps
Restaurer une base de données d’échelle de données à l’aide de timescaledb-backup
Lors de l’exécution de la procédure SELECT timescaledb_post_restore() indiquée ci-dessus, vous pourriez recevoir des erreurs d’autorisation refusée lors de la mise à jour de l’indicateur timescaledb.restoring. Cela est dû à l’autorisation ALTER DATABASE limitée dans les services de base de données cloud PaaS. Dans ce cas, vous pouvez utiliser une autre méthode à l’aide de l’outil timescaledb-backup pour sauvegarder et restaurer une base de données d’échelle de temps. Timescaledb-backup est un programme qui simplifie le vidage et la restauration d’une base de données TimescaleDB, moins susceptible d’engendrer des erreurs et plus performant.
Pour ce faire, vous devez procéder comme suit
- Installer les outils comme détaillé ici
- Créer une instance de serveur flexible Azure Database pour PostgreSQL cible et une base de données
- Activer l’extension d’échelle de temps comme indiqué ci-dessus
- Accorder le rôle
azure_pg_adminà l’utilisateur qui sera utilisé par ts-restore - Exécuter ts-restore pour restaurer la base de données
Des informations supplémentaires sur ces utilitaires sont disponibles ici.
Extensions et mise à niveau de version principale
Le serveur flexible Azure Database pour PostgreSQL a introduit une fonctionnalité de mise à niveau de version principale sur place qui effectue une mise à niveau sur place de l’instance de serveur flexible Azure Database pour PostgreSQL en un seul clic. La mise à niveau de version principale sur place simplifie le processus de mise à niveau de serveur flexible Azure Database pour PostgreSQL, ce qui réduit les interruptions pour les utilisateurs et les applications accédant au serveur. La mise à niveau de la version principale sur place ne prend pas en charge des extensions spécifiques et il existe certaines limitations à la mise à niveau de certaines extensions. Les extensions anon, Apache AGE, dblink, orafce, pgaudit, postgres_fdw et Timescaledb ne sont pas prises en charge pour toutes les versions d’Azure Database pour PostgreSQL – Serveur flexible lors de l’utilisation de la fonctionnalité de mise à jour d’une version majeure sur place.