Pertinence dans la recherche par mot clé (scoring BM25)
Cet article explique les algorithmes de scoring de pertinence BM25 utilisés pour calculer les scores de recherche pour la recherche en texte intégral. La pertinence BM25 est exclusive à la recherche en texte intégral. Les requêtes de filtre, l’autocomplétion et les requêtes suggérées, la recherche par caractères génériques et les requêtes de recherche partielles ne sont pas évaluées ou classées selon leur pertinence.
Algorithmes de scoring utilisés dans la recherche en texte intégral
Recherche Azure AI fournit les algorithmes de scoring suivants pour la recherche en texte intégral :
| Algorithme | Utilisation | Plage |
|---|---|---|
BM25Similarity |
Algorithme fixe sur tous les services de recherche créés après juillet 2020. Vous pouvez configurer cet algorithme, mais vous ne pouvez pas basculer vers un autre (classique). | Sans limite. |
ClassicSimilarity |
Valeur par défaut sur les services de recherche plus anciens qui datent de juillet 2020. Sur les services plus anciens, vous pouvez activer BM25 et choisir un algorithme BM25 par index. | 0 < 1.00 |
Les pondérations BM25 et classique sont des fonctions de récupération semblables à TF-IDF qui utilisent la fréquence du terme (TF) et la fréquence de document inverse (IDF) comme variables pour calculer des scores de pertinence pour chaque paire document-requête, qui sont ensuite utilisés pour les résultats du classement. Bien que conceptuellement similaire à la pondération classique, la pondération BM25 est enracinée dans la récupération d’informations probabilistes, qui produit des correspondances plus intuitives, mesurées par les recherches des utilisateurs.
BM25 propose des options de personnalisation avancées, comme permettre à l’utilisateur de décider comment la note de pertinence est mise à l’échelle avec la fréquence des termes correspondants.
Fonctionnement du classement BM25
Le scoring de pertinence fait référence au calcul d’un score de recherche (@search.score) qui sert d’indicateur de la pertinence d’un élément dans le contexte de la requête actuelle. La plage n’est pas délimitée. Cependant, plus le score est élevé, plus l’élément est pertinent.
Le score de recherche est calculé sur la base de propriétés statistiques de l’entrée de chaîne et de la requête elle-même. Recherche Azure AI trouve les documents qui contiennent des correspondances de recherche (en totalité ou en partie, selon searchMode), en favorisant les documents qui contiennent de nombreuses occurrences du terme recherché. Le score de recherche augmente davantage si le terme est rare dans l’index de données, mais courant au sein du document. La base de cette approche de la pertinence du calcul est appelée TF-IDF ou Term Frequency-Inverse Document Frequency (fréquence de terme-fréquence inverse de document).
Des scores de recherche peuvent être répétés dans un jeu de résultats. Quand plusieurs correspondances ont le même score de recherche, le classement des éléments ayant le même score n’est ni défini ni stable. Réexécutez la requête, et vous constaterez peut-être que des éléments changent de position, en particulier si vous utilisez le service gratuit ou un service facturable avec plusieurs réplicas. Si deux éléments ont un score identique, il est impossible de prédire celui qui apparait en première position.
Pour départager des scores identiques, vous pouvez ajouter une clause $orderby afin de trier d’abord par score, puis par un autre champ pouvant être trié (par exemple $orderby=search.score() desc,Rating desc).
Seuls les champs marqués comme searchable dans l’index ou searchFields dans la requête sont utilisés pour le scoring. Seuls les champs marqués comme retrievable, ou les champs spécifiés dans select dans la requête, sont retournés dans les résultats de recherche, ainsi que leur score de recherche.
Remarque
Un @search.score = 1 indique un jeu de résultats sans score ou non classé. Le score est uniforme parmi tous les résultats. Des résultats sans score se produisent quand le formulaire de requête est une recherche approximative, de caractères génériques ou d’expression régulière, ou une recherche vide (search=*, parfois assortie de filtres, où le filtre est le principal moyen de retourner une correspondance).
Le segment vidéo suivant permet d’accéder rapidement à une explication sur les algorithmes de classement en disponibilité générale, utilisés dans la Recherche Azure AI. Vous pouvez regarder la vidéo complète pour plus d’informations.
Scores dans les résultats d’un texte
Chaque fois que les résultats sont classés, la propriété @search.score contient la valeur utilisée pour classer les résultats.
Le tableau suivant identifie la propriété de scoring, l’algorithme et la plage.
| Méthode de recherche | Paramètre | Algorithme de scoring | Plage |
|---|---|---|---|
| recherche en texte intégral | @search.score |
Algorithme BM25, à l’aide des paramètres spécifiés dans l’index. | Sans limite. |
Variation de score
Les scores de recherche donnent une impression générale de pertinence, reflétant la force de la correspondance par rapport à d’autres documents du même jeu de résultats. Toutefois, les scores ne sont pas toujours cohérents d’une requête à l’autre. Par conséquent, vous pouvez remarquer de légères différences dans l’ordre des documents recherchés quand vous utilisez des requêtes. Il existe plusieurs explications à cette situation.
| Cause | Description |
|---|---|
| Scores identiques | Si plusieurs documents ont le même score, chacun d’entre eux peut apparaître en premier. |
| Volatilité des données | Le contenu de l’index varie au fur et à mesure que vous ajoutez, modifiez ou supprimez des documents. La fréquence des termes changera à mesure que les mises à jour de l’index seront traitées, ce qui aura un impact sur les scores de recherche des documents correspondants. |
| Réplicas multiples | Pour les services qui utilisent plusieurs réplicas, les requêtes sont émises en parallèle pour chaque réplicas. Les statistiques d’index utilisées pour calculer un score de recherche sont calculées par réplica, les résultats étant fusionnés et classés dans la réponse de la requête. Les réplicas sont principalement des miroirs les uns des autres, mais les statistiques peuvent varier en raison de petites différences d’état. Par exemple, un réplica peut avoir supprimé des documents contribuant à leurs statistiques, qui ont été fusionnées à partir d’autres réplicas. En règle générale, les différences dans les statistiques par réplica sont plus perceptibles dans les index plus petits. La section suivante fournit plus d’informations sur cette condition. |
Effets de partitionnement sur les résultats des requêtes
Une partition est un bloc d’un index. Recherche Azure AI divise chaque index en partitions pour accélérer le processus d’ajout de partitions (en déplaçant les partitions vers de nouvelles unités de recherche). Dans un service de recherche, la gestion de partitions est un détail d’implémentation et ne peut pas être configurée, mais le fait de savoir qu’un index fait l’objet d’un partitionnement aide à comprendre les anomalies occasionnelles dans les comportements de classement et d’autocomplétion :
Anomalies de classement : les scores de recherche sont d’abord calculés au niveau des shards avant d’être agrégés dans un même jeu de résultats. Selon les caractéristiques du contenu des shards, les correspondances d’un shard peuvent être mieux classées que les correspondances d’un autre shard. Si vous remarquez des classements contre-intuitifs dans les résultats de recherche, cela est probablement dû aux effets du partitionnement, tout particulièrement si les index sont de petite taille. Vous pouvez éviter ces anomalies de classement en choisissant de calculer les scores globalement dans l’index tout entier, mais cela nuira aux performances.
Anomalies d’autocomplétion : les requêtes autocomplétées, où les correspondances portent sur les premiers caractères d’un terme partiellement entré, acceptent un paramètre approximatif qui pardonne les petits écarts orthographiques. Pour l’autocomplétion, la correspondance approximative est limitée aux termes contenus dans le shard actif. Par exemple, si une partition contient « Microsoft » et que le terme partiel « micro » est entré, le moteur de recherche établit une correspondance avec « Microsoft » dans cette partition, mais pas dans ceux qui contiennent les autres parties de l’index.
Le diagramme suivant montre la relation entre réplicas, partitions, shards et unités de recherche. À travers un exemple, il montre comment un même index est réparti entre quatre unités de recherche dans un service constitué de deux réplicas et deux partitions. Chacune des quatre unités de recherche stocke uniquement la moitié des shards de l’index. Les unités de recherche de la colonne de gauche stockent la première moitié des shards, qui comprend la première partition, tandis que celles situées dans la colonne de droite stockent la deuxième moitié des shards, qui comprend la deuxième partition. Compte tenu de la présence de deux réplicas, il existe deux copies de chaque shard d’index. Les unités de recherche de la ligne du haut stockent une copie, comprenant le premier réplica, tandis que celles de la ligne du bas stockent une autre copie, comprenant le deuxième réplica.
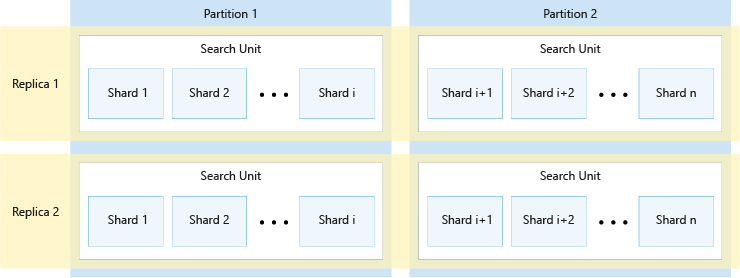
Le diagramme ci-dessus n’est qu’un exemple parmi d’autres. De nombreuses combinaisons de partitions et de réplicas sont possibles, jusqu’à 36 unités de recherche au maximum.
Remarque
Le nombre de réplicas et de partitions est divisible par 12 de manière égale (plus précisément, 1, 2, 3, 4, 6, 12). Le service Recherche Azure AI divise au préalable chaque index en 12 partitions pour que celles-ci puissent être réparties en proportions égales sur plusieurs partitions. Par exemple, si votre service comporte trois partitions et que vous créez un index, chaque partition contiendra quatre partitions de l'index. Le partitionnement d’un index réalisé par la Recherche Azure AI est un détail d'implémentation susceptible d’être modifié dans des futures versions. Le nombre de partitions (12 à l’heure actuelle) peut être, à l’avenir, totalement différent.
Statistiques de scoring et sessions rémanentes
À des fins de scalabilité, Recherche Azure AI distribue chaque index horizontalement par le biais d’un processus de sharding, ce qui signifie que les portions d’un index sont physiquement séparées.
Par défaut, le score d’un document est calculé en fonction de propriétés statistiques des données au sein d’une partition. Cette approche n’est généralement pas un problème pour un corpus important de données, et elle offre de meilleures performances que le calcul du score à partir des informations de l’ensemble des partitions. Cela dit, avec cette optimisation des performances, deux documents très similaires (ou même des documents identiques) risquent de se retrouver avec des scores de pertinence différents s’ils figurent dans des partitions différentes.
Si vous préférez calculer le score à partir des propriétés statistiques sur l’ensemble des partitions, vous pouvez le faire en ajoutant scoringStatistics=global en tant que paramètre de requête (ou en ajoutant "scoringStatistics": "global" en tant que paramètre de corps de la demande de requête).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
L’utilisation de scoringStatistics garantit que toutes les partitions dans le même réplica fournissent les mêmes résultats. Cela dit, plusieurs réplicas peuvent être légèrement différents les uns des autres, car ils sont toujours mis à jour avec les dernières modifications apportées à votre index. Dans certains scénarios, vous souhaiterez peut-être que vos utilisateurs obtiennent des résultats plus cohérents pendant une « session de requête ». Dans de tels scénarios, vous pouvez fournir un sessionId dans le cadre de vos requêtes. Le sessionId est une chaîne unique que vous créez pour faire référence à une session utilisateur unique.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Tant que le même sessionId est utilisé, la méthode de la meilleure tentative possible est utilisée pour cibler le même réplica, ce qui améliore la cohérence des résultats présentés à vos utilisateurs.
Remarque
La réutilisation des mêmes valeurs sessionId à plusieurs reprises peut interférer avec l’équilibrage de la charge des demandes sur les réplicas et nuire aux performances du service de recherche. La valeur utilisée comme sessionId ne peut pas commencer par un caractère « _ ».
Réglage de la pertinence
Dans la Recherche Azure AI, pour la recherche par mot clé et la partie texte d’une requête hybride, vous pouvez configurer des paramètres d’algorithme BM25, ainsi que régler la pertinence de la recherche et améliorer les scores de recherche via les mécanismes suivants.
| Approche | Implémentation | Description |
|---|---|---|
| Configuration de l’algorithme BM25 | Index de recherche | Configurez la façon dont la longueur du document et la fréquence des termes affectent le score de pertinence. |
| Profils de score | Index de recherche | Fournissez les critères utilisés pour surévaluer le score de recherche d’une correspondance en fonction des caractéristiques du contenu. Par exemple, vous pouvez améliorer les correspondances en fonction de leur potentiel de chiffre d’affaires, promouvoir les nouveaux articles ou booster les articles qui sont en stock depuis trop longtemps. Un profil de score fait partie de la définition d'index, composée de champs, fonctions et paramètres pondérés. Vous pouvez mettre à jour un index existant avec des modifications de profil de score, sans entraîner de reconstruction d’index. |
| Classement sémantique | Demande de requête | Applique la compréhension de lecture automatique aux résultats de la recherche, en favorisant des résultats plus sémantiquement pertinents en haut. |
| Paramètre featuresMode | Demande de requête | Ce paramètre est principalement utilisé pour décompresser un score classé par BM25, mais il peut être utilisé dans le code qui fournit une solution de scoring personnalisée. |
Paramètre featuresMode (préversion)
Les requêtes Search Documents prennent en charge un paramètre featuresMode qui fournit plus de détails sur un score de pertinence BM25 au niveau du champ. Alors que le @searchScore est calculé pour l’ensemble du document (le niveau de pertinence du document dans le contexte de la requête), featuresMode révèle des informations sur les champs individuels, exprimées dans une structure @search.features. La structure contient tous les champs utilisés dans la requête (soit des champs spécifiques par le biais de searchFields dans une requête, soit tous les champs attribués comme interrogeables dans un index).
Pour chaque champ, @search.features vous donne les valeurs suivantes :
- Nombre de jetons uniques trouvés dans le champ
- Score de similarité, ou mesure de la similitude entre le contenu du champ et le terme recherché
- Fréquence du terme, ou nombre de fois où le terme recherché a été trouvé dans le champ
Pour une requête qui cible les champs « Description » et « Titre », une réponse incluant @search.features peut se présenter comme suit :
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Vous pouvez utiliser ces points de données dans des solutions de scoring personnalisées ou utiliser les informations pour déboguer des problèmes de pertinence des recherches.
Le paramètre featuresMode n’est pas documenté dans les API REST, mais vous pouvez l’utiliser dans un appel d’API REST en préversion dans Search Documents pour rechercher du texte (mot clé) classé par BM25.
Nombre de résultats classés dans une réponse de requête en texte intégral
Par défaut, si vous n’utilisez pas la pagination, le moteur de recherche retourne les 50 correspondances de classement les plus élevées pour la recherche en texte intégral. Le paramètre top vous permet de définir le retour d'un nombre supérieur ou inférieur d'éléments (jusqu'à 1 000 par réponse). Vous pouvez utiliser skip et next pour mettre en page les résultats. La pagination détermine le nombre de résultats sur chaque page logique et prend en charge la navigation dans le contenu. Pour plus d’informations, consultez Mettre en forme les résultats de la recherche.
Si votre requête en texte intégral fait partie d’une requête hybride, vous pouvez définir maxTextRecallSize pour augmenter ou diminuer le nombre de résultats du côté texte de la requête.
La recherche en texte intégral est soumise à une limite maximale de 1 000 correspondances (voir limites de réponse de l’API). Une fois que 1 000 correspondances sont trouvées, le moteur de recherche ne recherche plus d’informations.