Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les notebooks Jupyter fournissent un environnement interactif pour l’exploration, l’analyse et la visualisation des données dans le lac de données Microsoft Sentinel et les tables fédérées. Les notebooks vous permettent d’écrire et d’exécuter du code, de documenter votre flux de travail et d’afficher les résultats au même endroit. Cela facilite l’exploration des données, la création de solutions analytiques avancées et le partage d’informations avec d’autres personnes. En tirant parti de Python et Apache Spark dans Visual Studio Code, les notebooks vous aident à transformer des données de sécurité brutes en informations exploitables.
Cet article explique comment explorer et interagir avec des données de lac de données à l’aide de notebooks Jupyter dans Visual Studio Code.
Configuration requise
Intégrer au lac de données Microsoft Sentinel
Pour utiliser des notebooks dans le lac de données Microsoft Sentinel, vous devez d’abord intégrer le lac de données. Si vous n’avez pas intégré au lac de données Sentinel, consultez Intégration à Microsoft Sentinel lac de données. Si vous avez récemment intégré le lac de données, l’ingestion d’un volume suffisant de données peut prendre un certain temps avant que vous puissiez créer des analyses significatives à l’aide de notebooks.
Autorisations
Microsoft Entra ID rôles fournissent un accès étendu à tous les espaces de travail du lac de données. Vous pouvez également accorder l’accès à des espaces de travail individuels à l’aide de Azure rôles RBAC. Les utilisateurs disposant d’autorisations RBAC Azure pour Microsoft Sentinel espaces de travail peuvent exécuter des notebooks sur ces espaces de travail dans le niveau data lake. Pour plus d’informations, consultez Rôles et autorisations dans Microsoft Sentinel.
Si vous le souhaitez, Microsoft Sentinel RBAC d’étendue ou au niveau des lignes peut être configuré pour restreindre davantage l’accès aux données au sein d’un espace de travail. Lorsqu’elle est activée, l’étendue au niveau des lignes limite les données retournées par les requêtes en fonction de l’étendue attribuée à l’utilisateur. Si l’étendue au niveau des lignes n’est pas configurée, le modèle d’autorisation existant au niveau de l’espace de travail s’applique sans modification. Pour plus d’informations, consultez Configurer Microsoft Sentinel étendue (RBAC au niveau des lignes) (préversion) .
Pour créer des tables personnalisées dans le niveau analytique, l’identité managée data lake doit se voir attribuer le rôle Contributeur Log Analytics dans l’espace de travail Log Analytics.
Pour attribuer le rôle, suivez les étapes ci-dessous :
- Dans le Portail Azure, accédez à l’espace de travail Log Analytics auquel vous souhaitez attribuer le rôle.
- Sélectionnez Contrôle d’accès (IAM) dans le volet de navigation gauche.
- Sélectionnez Ajouter une attribution de rôle.
- Dans la table Rôle , sélectionnez Contributeur Log Analytics, puis Suivant
- Sélectionnez Identité managée, puis sélectionnez Sélectionner des membres.
- Votre identité managée data lake est une identité managée affectée par le système nommée
msg-resources-<guid>. Sélectionnez l’identité managée, puis sélectionnez Sélectionner. - Sélectionnez Vérifier et attribuer.
Pour plus d’informations sur l’attribution de rôles à des identités managées, consultez Attribuer des rôles Azure à l’aide de la Portail Azure.
Installer Visual Studio Code et l’extension Microsoft Sentinel
Si vous n’avez pas encore Visual Studio Code, téléchargez et installez Visual Studio Code pour Mac, Linux ou Windows.
L’extension Microsoft Sentinel pour Visual Studio Code (VS Code) est installée à partir de la Place de marché des extensions. Pour installer l’extension, procédez comme suit :
- Sélectionnez la Place de marché extensions dans la barre d’outils de gauche.
- Recherchez Sentinel.
- Sélectionnez l’extension Microsoft Sentinel, puis sélectionnez Installer.
- Une fois l’extension installée, l’icône Microsoft Sentinel
 s’affiche dans la barre d’outils de gauche.
s’affiche dans la barre d’outils de gauche.

Installez l’extension GitHub Copilot pour Visual Studio Code afin d’activer la saisie semi-automatique du code et les suggestions dans les notebooks.
- Recherchez GitHub Copilot dans la Place de marché des extensions et installez-la.
- Après l’installation, connectez-vous à GitHub Copilot à l’aide de votre compte GitHub.
Explorer les tables de niveau de lac de données
Après avoir installé l’extension Microsoft Sentinel, vous pouvez commencer à explorer les tables de niveau lac de données et à créer des notebooks Jupyter pour analyser les données.
Connectez-vous à l’extension Microsoft Sentinel
Sélectionnez le Microsoft Sentinel
dans la barre d’outils de gauche.Une boîte de dialogue s’affiche avec le texte suivant L’extension « Microsoft Sentinel » souhaite se connecter à l’aide de Microsoft. Sélectionnez Autoriser.
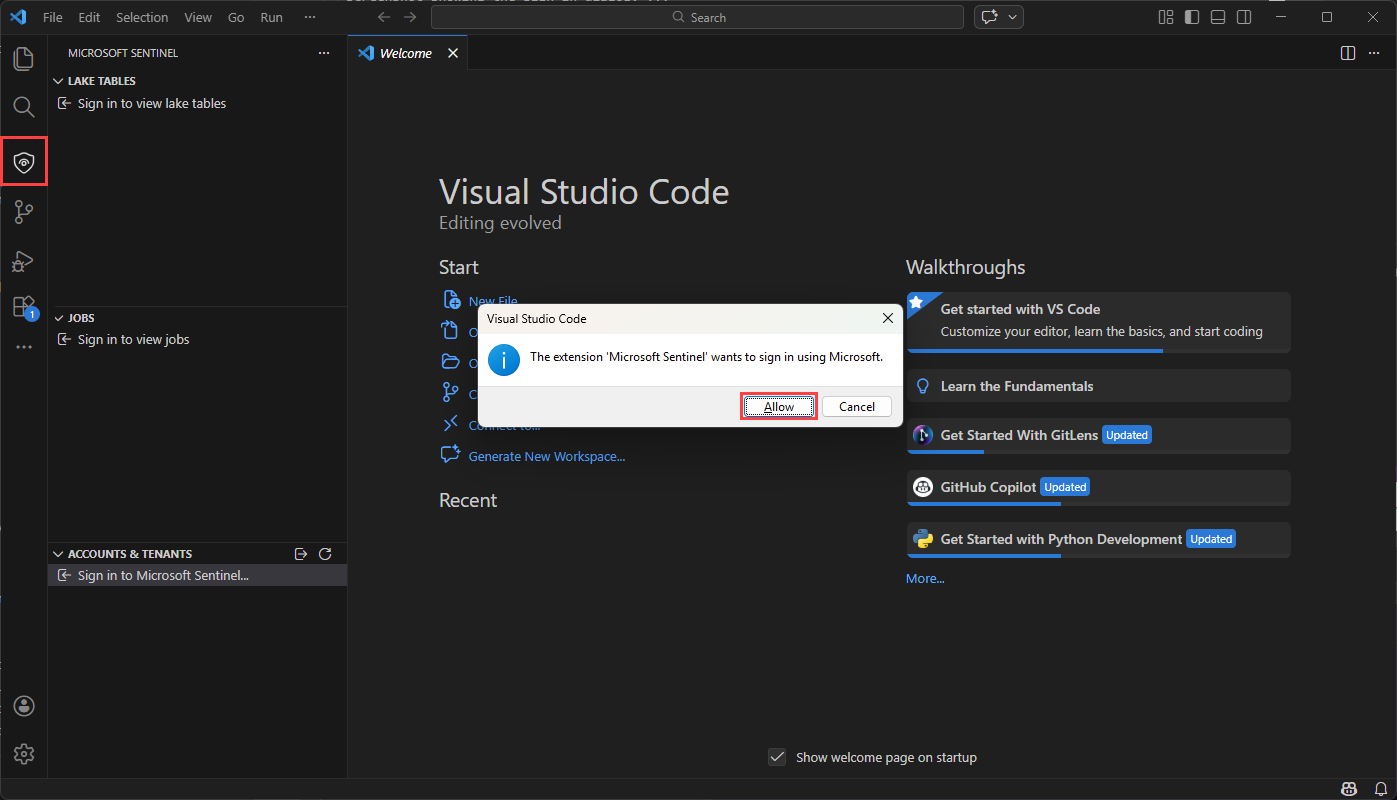
Sélectionnez le nom de votre compte pour terminer la connexion.
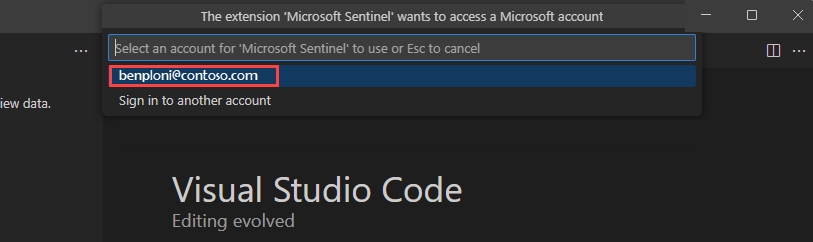
Si vous avez plusieurs comptes invités associés à votre connexion, vous pouvez basculer en toute transparence entre les comptes. Pour basculer entre les comptes, sélectionnez le nom du compte en bas à gauche de la fenêtre Visual Studio Code. Un seul compte peut être sélectionné à la fois.
Importante
Le basculement entre les comptes déconnecte toutes les sessions pyspark actives.



Afficher les tables et les travaux de lac de données
Une fois que vous êtes connecté, l’extension Sentinel affiche une liste de tables lake et de travaux dans le volet gauche. Les tables sont regroupées par base de données et catégorie. Les tables fédérées sont affichées sous la catégorie Tables fédérées sous Tables système. Sélectionnez une table pour afficher les définitions de colonne.
Pour plus d’informations sur les travaux, consultez Travaux et planification. Pour plus d’informations sur les tables fédérées, consultez Utilisation de tables fédérées dans le lac de données Microsoft Sentinel.

Créer un bloc-notes
Pour créer un bloc-notes, utilisez l’une des méthodes suivantes.
Entrez > dans la zone de recherche ou appuyez sur Ctrl+Maj+P, puis entrez Créer un nouveau Jupyter Notebook.

Sélectionnez Fichier > Nouveau fichier, puis sélectionnez Jupyter Notebook dans la liste déroulante.
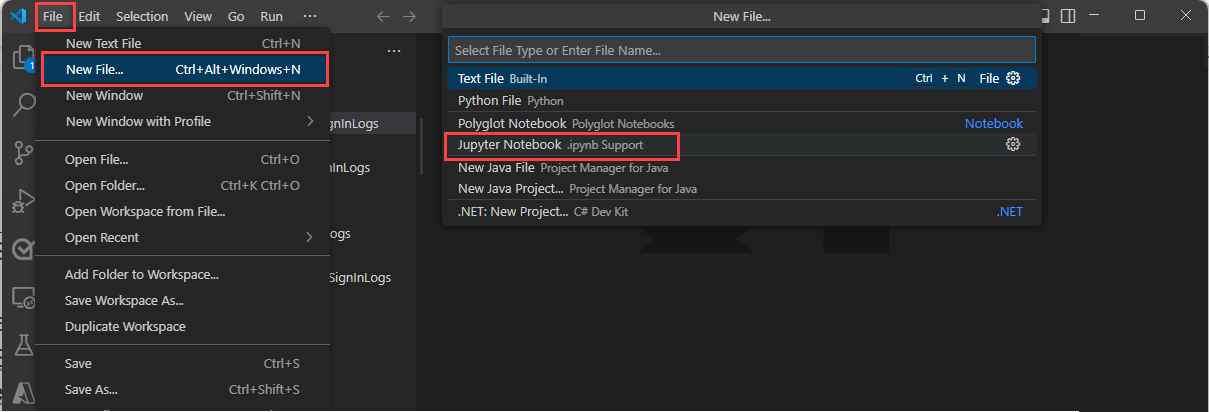
Dans le nouveau notebook, collez le code suivant dans la première cellule.
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df_filtered = df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False) # Transform the dataframe df_transformed = df.filter(df.mail.isNotNull()).select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId") write_options = { 'mode': 'overwrite' } # Save to a new table data_provider.save_as_table(df_transformed, "EntraGroups_Processed_SPRK", write_options=write_options)


L’éditeur fournit la saisie semi-automatique du code IntelliSense pour la MicrosoftSentinelProvider classe et les noms de table dans le lac de données.
Sélectionnez le triangle Exécuter pour exécuter le code dans le notebook. Les résultats sont affichés dans le volet de sortie sous la cellule de code.
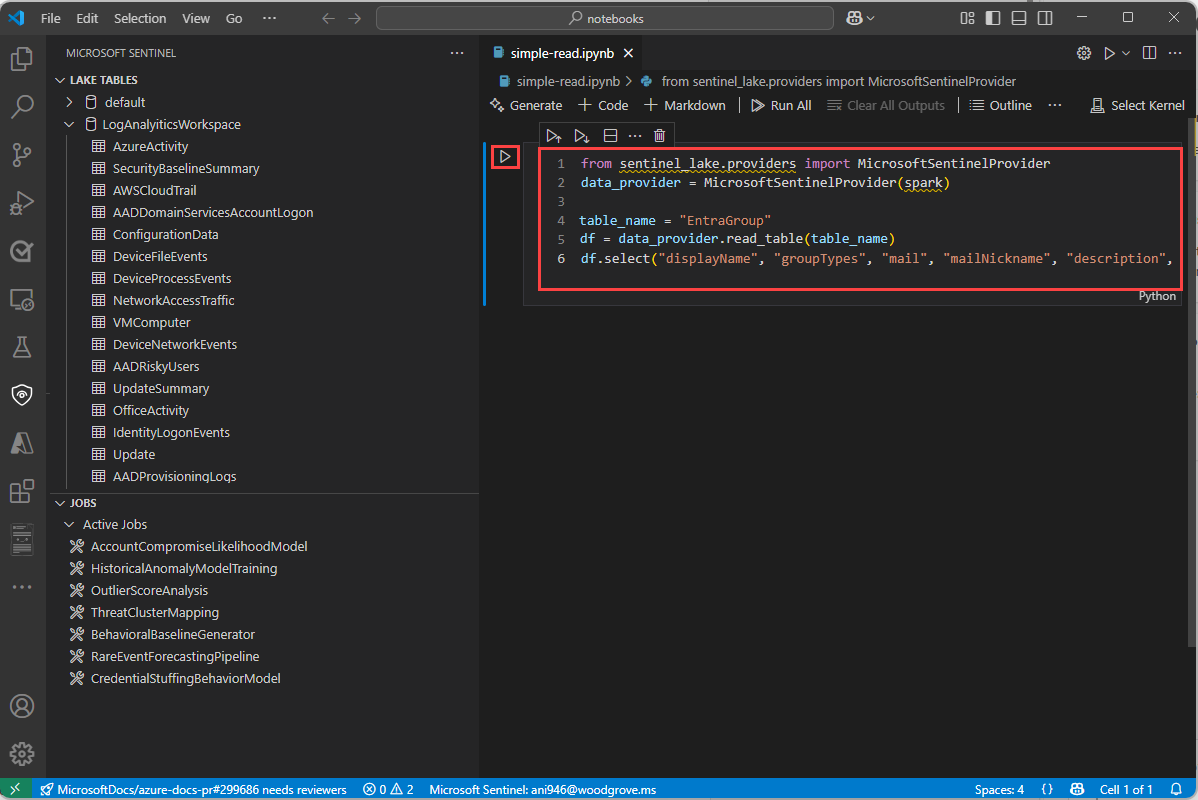
Sélectionnez Microsoft Sentinel dans la liste pour obtenir la liste des pools d’exécution.
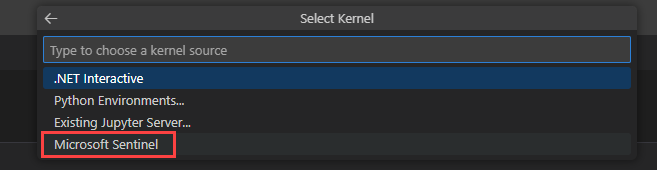
Sélectionnez Moyen pour exécuter le notebook dans le pool d’exécution de taille moyenne. Pour plus d’informations sur les différents runtimes, consultez Sélection du runtime Microsoft Sentinel approprié.



Remarque
La sélection du noyau démarre la session Spark et exécute le code dans le notebook. Après avoir sélectionné le pool, le démarrage de la session peut prendre 3 à 5 minutes. Les exécutions suivantes sont plus rapides, car la session est déjà active.
Lorsque la session est démarrée, le code du notebook s’exécute et les résultats sont affichés dans le volet de sortie sous la cellule de code, par exemple : 
Pour obtenir des exemples de notebooks qui montrent comment interagir avec le lac de données Microsoft Sentinel, consultez Exemples de notebooks pour Microsoft Sentinel lac de données.
Barre d’état
La barre status en bas du bloc-notes fournit des informations sur l’état actuel du bloc-notes et de la session Spark. La barre status contient les informations suivantes :
Pourcentage d’utilisation des vCores pour le pool Spark sélectionné. Pointez sur le pourcentage pour voir le nombre de vCores utilisés et le nombre total de vCores disponibles dans le pool. Les pourcentages représentent l’utilisation actuelle des charges de travail et interactives pour le compte connecté.
La connexion status de la session Spark, par exemple
Connecting,ConnectedouNot Connected.

Définir les délais d’expiration de session
Vous pouvez définir les avertissements de délai d’expiration et de délai d’expiration de session pour les notebooks interactifs. Ces paramètres sont conservés dans les paramètres d’extension afin d’être conservés entre les sessions.
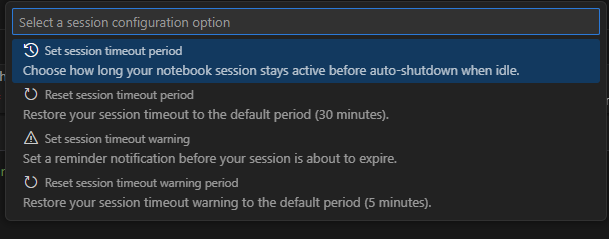
Pour modifier le délai d’expiration, sélectionnez le status de connexion dans la barre de status en bas du bloc-notes. Choisissez l'une des options suivantes :
Définir le délai d’expiration de session : définit la durée en minutes avant l’expiration de la session. La valeur par défaut est 30 minutes.
Réinitialiser le délai d’expiration de session : réinitialise le délai d’expiration de session à la valeur par défaut de 30 minutes.
Définir la période d’avertissement du délai d’expiration de session : définit le délai en minutes avant l’expiration du délai d’affichage d’un avertissement indiquant que la session est sur le point d’expirer. La valeur par défaut est de 5 minutes.
Période d’avertissement de réinitialisation du délai d’expiration de session : rétablit la valeur par défaut de 5 minutes pour l’avertissement de délai d’expiration de session.

Utiliser GitHub Copilot dans les notebooks
Utilisez GitHub Copilot pour vous aider à écrire du code dans des notebooks. GitHub Copilot fournit des suggestions de code et une autocomplétion en fonction du contexte de votre code. Pour utiliser GitHub Copilot, vérifiez que l’extension GitHub Copilot est installée dans Visual Studio Code.
Copiez le code à partir des exemples de notebooks pour Microsoft Sentinel lac de données et enregistrez-le dans votre dossier notebooks pour fournir un contexte pour GitHub Copilot. GitHub Copilot pourrez ensuite suggérer des saisies semi-automatiques de code en fonction du contexte de votre bloc-notes.
L’exemple suivant montre GitHub Copilot générer une révision de code.

Microsoft Sentinel Provider, classe
Pour vous connecter au lac de données Microsoft Sentinel, utilisez la SentinelLakeProvider classe .
Cette classe fait partie du access_module.data_loader module et fournit des méthodes pour interagir avec le lac de données. Pour utiliser cette classe, importez-la et créez un instance de la classe à l’aide d’une spark session.
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
Pour plus d’informations sur les méthodes disponibles, consultez Microsoft Sentinel informations de référence sur la classe Provider.
Sélectionner le pool d’exécution approprié
Trois pools d’exécution sont disponibles pour exécuter vos notebooks Jupyter dans l’extension Microsoft Sentinel. Chaque pool est conçu pour des charges de travail et des exigences de performances différentes. Le choix du pool d’exécution affecte les performances, le coût et le temps d’exécution de vos travaux Spark.
| Pool d’exécutions | Cas d’usage recommandés | Caractéristiques |
|---|---|---|
| Small | Développement, test et analyse exploratoire légère. Petites charges de travail avec des transformations simples. Rentabilité prioritaire. |
Adapté aux petites charges de travail Transformations simples. Coût inférieur, temps d’exécution plus long. |
| Medium | Travaux ETL avec jointures, agrégations et entraînement de modèle ML. Modérer les charges de travail avec des transformations complexes. |
Amélioration des performances par rapport à Small. Gère le parallélisme et modère les opérations nécessitant beaucoup de mémoire. |
| Large | Charges de travail d’apprentissage profond et de ML. Shuffling de données étendu, jointures volumineuses ou traitement en temps réel. Temps d’exécution critique. |
Mémoire et puissance de calcul élevées. Des délais minimes. Idéal pour les charges de travail volumineuses, complexes ou sensibles au temps. |
Remarque
Lors de la première consultation, le chargement des options de noyau peut prendre environ 30 secondes.
Après avoir sélectionné un pool d’exécution, le démarrage de la session peut prendre 3 à 5 minutes.
Afficher les messages, les journaux et les erreurs
Les journaux des messages et les messages d’erreur sont affichés dans trois zones dans Visual Studio Code.
Volet Sortie .
- Dans le volet Sortie, sélectionnez Microsoft Sentinel dans la liste déroulante.
- Sélectionnez Déboguer pour inclure des entrées de journal détaillées.
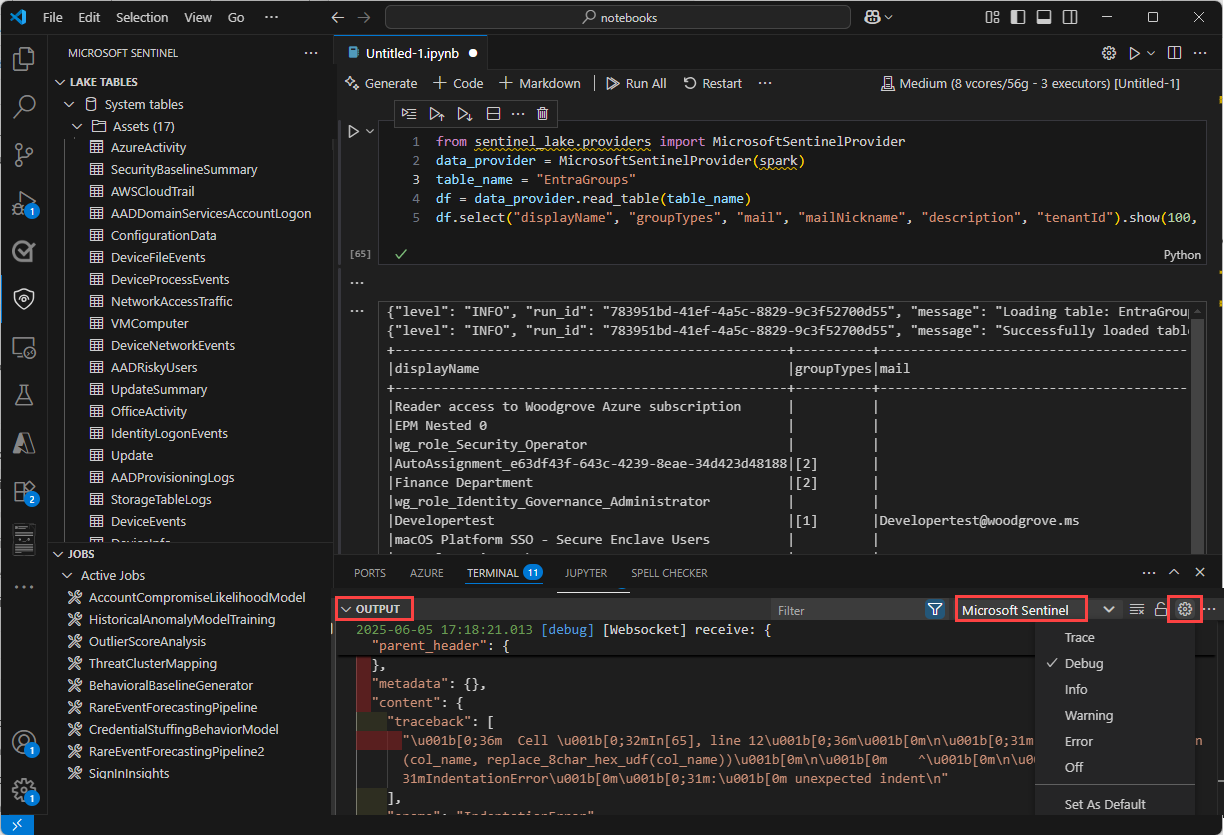
Les messages en ligne dans le notebook fournissent des commentaires et des informations sur l’exécution des cellules de code. Ces messages incluent l’exécution status mises à jour, les indicateurs de progression et les notifications d’erreur liées au code dans la cellule précédente
Une fenêtre contextuelle de notification dans le coin inférieur droit de Visual Studio Code, également connu sous le nom de message toast, fournit des alertes en temps réel et des mises à jour sur la status des opérations dans le notebook et la session Spark. Ces notifications incluent des messages, des avertissements et des alertes d’erreur, comme une connexion réussie à une session Spark et des avertissements de délai d’expiration.
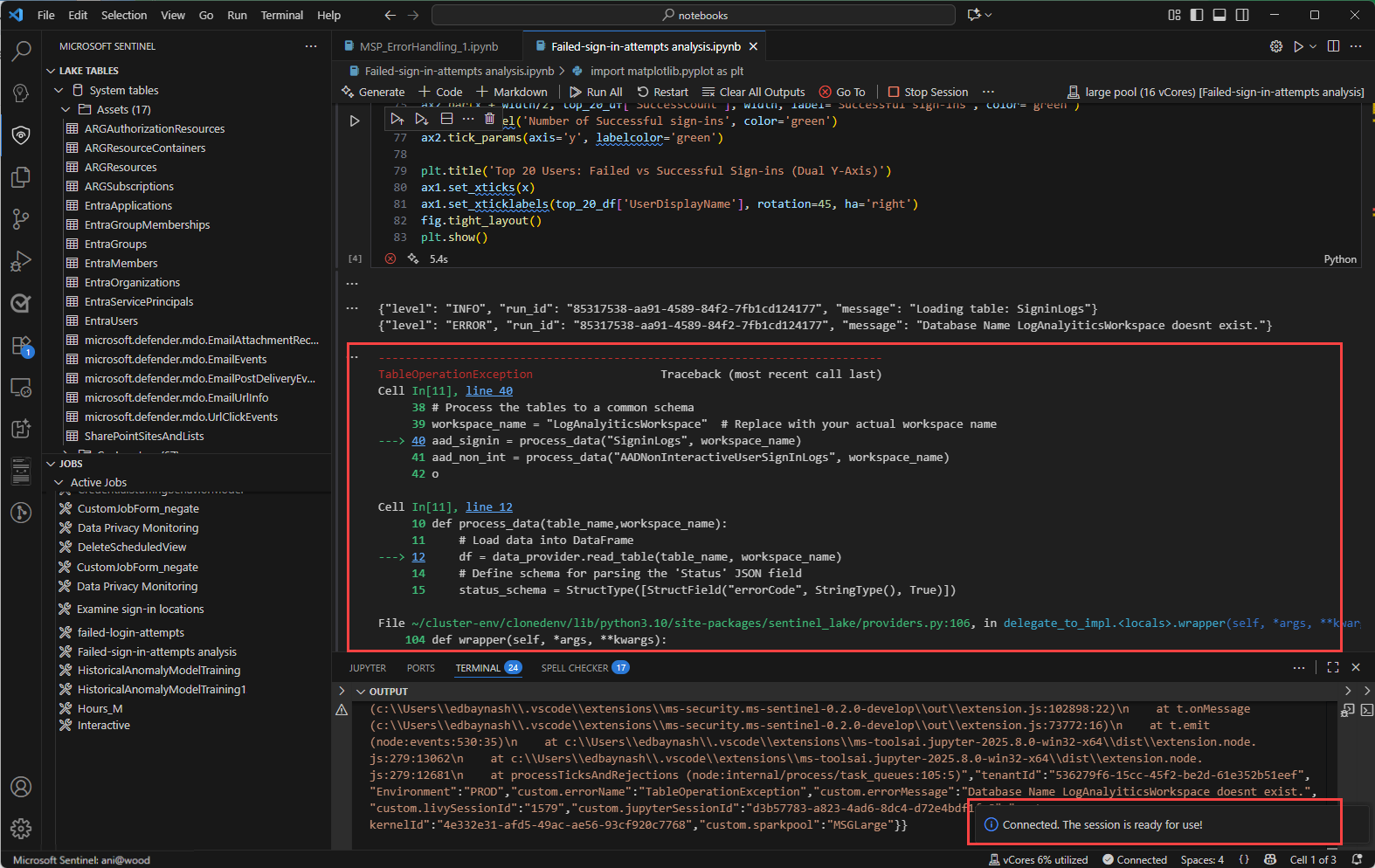


Travaux et planification
Vous pouvez planifier l’exécution des travaux à des heures ou des intervalles spécifiques à l’aide de l’extension Microsoft Sentinel pour Visual Studio Code. Les travaux vous permettent d’automatiser les tâches de traitement des données pour synthétiser, transformer ou analyser des données dans le lac de données Microsoft Sentinel. Les travaux sont également utilisés pour traiter des données et écrire des résultats dans des tables personnalisées dans le niveau data lake ou le niveau analytique. Pour plus d’informations sur la création et la gestion des travaux, consultez Créer et gérer des travaux de notebook Jupyter.
Paramètres et limites de service pour les notebooks VS Code
La section suivante répertorie les paramètres de service et les limites pour Microsoft Sentinel lac de données lors de l’utilisation de notebooks VS Code.
| Catégorie | Paramètre/limite |
|---|---|
| Table personnalisée dans le niveau Analytique | Les tables personnalisées du niveau Analytique ne peuvent pas être supprimées d’un notebook ; Utilisez Log Analytics pour supprimer ces tables. Pour plus d’informations, consultez Ajouter ou supprimer des tables et des colonnes dans les journaux Azure Monitor |
| Délai d’expiration du socket web de la passerelle | 2 heures |
| Délai d’expiration des requêtes interactives | 2 heures |
| Délai d’inactivité de session interactive | 20 minutes |
| Langue | Python |
| Délai d’expiration de requête de graphe | 7.5 minutes |
| Délai d’expiration du travail de notebook | 8 heures |
| Nombre maximal de travaux de notebook simultanés | 3, les travaux suivants sont mis en file d’attente |
| Nombre maximal d’utilisateurs simultanés sur l’interrogation interactive | 8-10 sur grande piscine |
| Heure de démarrage de la session | Le démarrage de la session de calcul Spark prend environ 5 à 6 minutes. Vous pouvez afficher les status de la session en bas de votre bloc-notes VS Code. |
| Bibliothèques prises en charge | Seules les bibliothèques Azure Synapse 3.4 et la bibliothèque Microsoft Sentinel Provider pour les fonctions abstraites sont prises en charge pour l’interrogation du lac de données. Les installations Pip ou les bibliothèques personnalisées ne sont pas prises en charge. |
| Limite de l’expérience utilisateur VS Code pour afficher les enregistrements | 100 000 lignes |
Résolution des problèmes
Pour connaître les erreurs et les solutions courantes lors de l’utilisation de notebooks, consultez Résoudre les problèmes liés aux notebooks sur le lac de données Microsoft Sentinel.
Contenu connexe
- Résoudre les problèmes de notebooks sur le lac de données Microsoft Sentinel
- Créer et gérer des travaux de notebook
- Exemples de notebooks pour Microsoft Sentinel data lake
- Informations de référence sur la classe Microsoft Sentinel Provider
- vue d’ensemble du lac de données Microsoft Sentinel
- Microsoft Sentinel rôles et autorisations de lac de données.