Réplicas et instances
Cet article donne une vue d’ensemble du cycle de vie des réplicas de services avec état et des instances de services sans état.
Instances de services sans état
Une instance d’un service sans état est une copie de la logique de service qui s’exécute sur l’un des nœuds du cluster. Une instance au sein d’une partition n’est identifiable que par le biais de son ID d’instance. Le cycle de vie d’une instance est représenté dans le diagramme suivant :
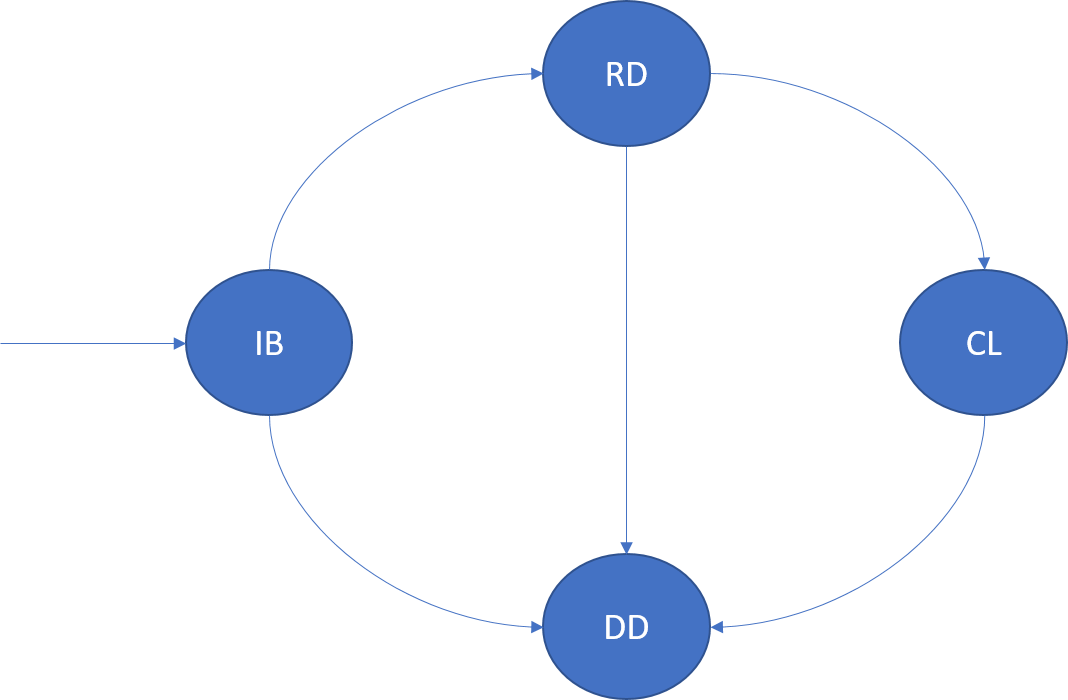
InBuild (IB)
Une fois que Cluster Resource Manager a déterminé le placement d’une instance, celle-ci entre dans cette phase du cycle de vie. L’instance est démarrée sur le nœud. L’hôte de l’application est démarré, l’instance est créée, puis ouverte. À l’issue du démarrage, l’état de l’instance passe à prêt.
Si le nœud ou l’hôte d’application de cette instance tombe en panne, son état passe à abandonné.
Ready (RD)
Dans l’état prêt, l’instance est opérationnelle sur le nœud. Si cette instance est un service fiable, RunAsync a été appelée.
Si le nœud ou l’hôte d’application de cette instance tombe en panne, son état passe à abandonné.
Closing (CL)
Dans l’état de fermeture, Azure Service Fabric procède à l’arrêt de l’instance sur ce nœud. La cause de cet arrêt peut être multiple, par exemple une mise à niveau d’application, un équilibrage de charge ou la suppression du service. Au terme de l’arrêt, son état passe à abandonné.
Dropped (DD)
Dans l’état abandonné, l’instance n’est plus exécutée sur le nœud. À ce stade, Service Fabric conserve les métadonnées relatives à cette instance, qui sont au final également supprimées.
Notes
Il est possible de passer de n’importe quel état à l’état abandonné par l’intermédiaire de l’option ForceRemove sur Remove-ServiceFabricReplica.
Réplicas de services avec état
Un réplica d’un service avec état est une copie de la logique de service en cours d’exécution sur l’un des nœuds du cluster. De plus, le réplica conserve une copie de l’état de ce service. Deux concepts connexes décrivent le cycle de vie et le comportement des réplicas avec état :
- Cycle de vie du réplica
- Rôle du réplica
Les paragraphes suivants décrivent les services avec état persistant. Pour les services avec état volatile (ou en mémoire), les états hors service et abandonné sont équivalents.
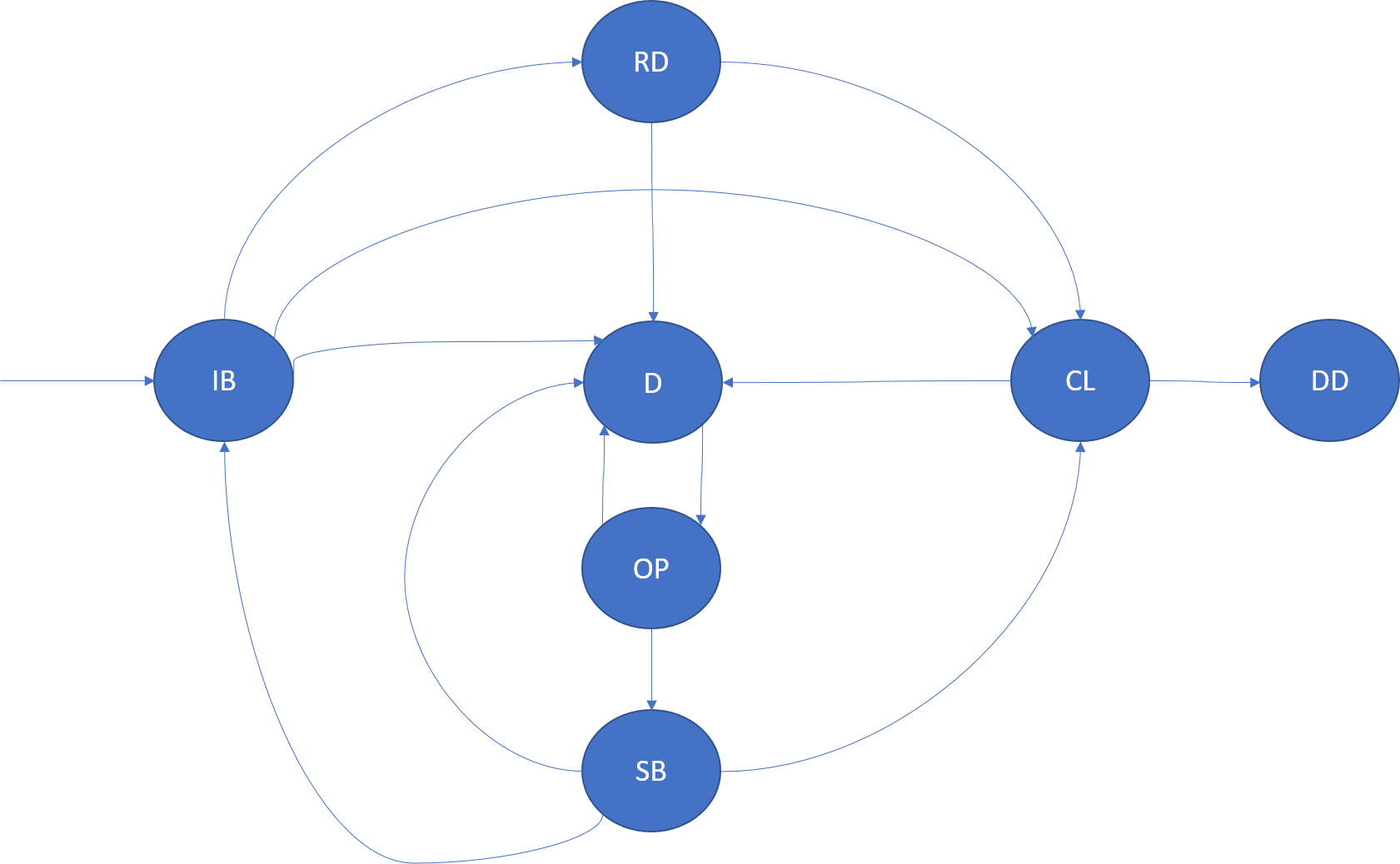
InBuild (IB)
Un réplica InBuild est un réplica qui est créé ou préparé en vue de rejoindre le jeu de réplicas. Selon le rôle du réplica, la phase InBuild adopte une sémantique différente.
Si le nœud ou l’hôte d’application d’un réplica InBuild tombe en panne, son état passe à hors service.
Réplicas Primary InBuild : les réplicas Primary InBuild sont les premiers réplicas d’une partition. Ce réplica se produit généralement à la création de la partition. Les réplicas Principal InBuild apparaissent également lorsque tous les réplicas d’une partition redémarrent ou sont abandonnés.
Réplicas IdleSecondary InBuild : il s’agit de réplicas créés par Cluster Resource Manager ou de réplicas existants qui ont été mis hors service et qui doivent être rajoutés au jeu. Ces réplicas sont amorcés ou générés par le réplica principal avant de pouvoir rejoindre le jeu de réplicas en tant que réplicas ActiveSecondary et ainsi participer à l’accusé de réception quorum d’opérations.
Réplicas ActiveSecondary InBuild : cet état est observé dans certaines requêtes. Il s’agit d’une optimisation où le jeu de réplicas ne change pas, mais où la création d’un réplica est nécessaire. Le réplica lui-même suit les transitions de l’état normal de la machine (comme décrit dans la section sur les rôles du réplica).
Ready (RD)
Un réplica Ready est un réplica qui participe à la réplication et à l’accusé de réception quorum d’opérations. L’état prêt s’applique aux réplicas principaux et secondaires actifs.
Si le nœud ou l’hôte d’application d’un réplica prêt tombe en panne, son état passe à hors service.
Closing (CL)
Un réplica passe à l’état de fermeture dans les scénarios suivants :
Arrêt du code pour le réplica : Service Fabric peut être amené à mettre fin à l’exécution du code pour un réplica. Cet arrêt peut avoir diverses causes. Par exemple, il peut se produire en raison d’une application, structure ou mise à niveau d’infrastructure, ou en raison d’une défaillance signalée par le réplica. Quand la fermeture du réplica est terminée, il passe à l’état hors service. L’état persistant associé à ce réplica stocké sur le disque n’est pas nettoyé.
Suppression du réplica du cluster : Service Fabric peut être amené à supprimer l’état persistant et à arrêter l’exécution du code d’un réplica. La cause de cet arrêt peut être multiple, par exemple, un équilibrage de charge.
Dropped (DD)
Dans l’état abandonné, l’instance n’est plus exécutée sur le nœud. Il n’existe également plus d’état sur le nœud. À ce stade, Service Fabric conserve les métadonnées relatives à cette instance, qui sont au final également supprimées.
Down (D)
Dans l’état hors service, le code du réplica ne s’exécute pas, mais l’état persistant de ce réplica existe sur ce nœud. Un réplica peut être hors service pour de nombreuses raisons, par exemple une panne de nœud, des incidents survenant dans le code du réplica, une mise à niveau d’application ou des défaillances de réplica.
Le cas échéant, un réplica hors service est ouvert par Service Fabric, par exemple quand la mise à niveau est terminée sur le nœud.
Le rôle de réplica ne s’applique pas à l’état hors service.
Opening (OP)
Un réplica hors service passe à l’état d’ouverture quand Service Fabric doit le rendre de nouveau opérationnel. Par exemple, cet état peut exister après une mise à niveau de code, pour que l’application se termine sur un nœud.
Si le nœud ou l’hôte d’application pour un réplica qui s’ouvre se bloque, son état passe à hors service.
Le rôle de réplica ne s’applique pas dans l’état d’ouverture.
StandBy (SB)
Un réplica Standby est un réplica d’un service persistant qui s’est arrêté et a ensuite été ouvert. Ce réplica peut être utile à Service Fabric si l’ajout d’un autre réplica au jeu de réplicas est nécessaire (car le réplica possède déjà une partie de l’état et le processus de génération est plus rapide). Après l’expiration de StandByReplicaKeepDuration, le réplica en attente est ignoré.
Si le nœud ou l’hôte d’application pour un réplica en attente tombe en panne, son état passe à hors service.
Le rôle de réplica ne s’applique pas dans l’état en attente.
Notes
Tout réplica qui n’est pas hors service ou abandonné est considéré opérationnel.
Notes
Il est possible de passer de n’importe quel état à l’état abandonné par l’intermédiaire de l’option ForceRemove sur Remove-ServiceFabricReplica.
Rôle du réplica
Le rôle du réplica détermine sa fonction dans le jeu de réplicas :
- Principal (P) : il existe un principal dans le jeu de réplicas qui est chargé d’effectuer les opérations de lecture et d’écriture.
- ActiveSecondary (S) : ce sont les réplicas qui reçoivent des mises à jour d’état du réplica principal, les appliquent, puis retournent des accusés de réception. Il existe plusieurs réplicas secondaires actifs dans le jeu de réplicas. Leur nombre détermine le nombre de défaillances que le service peut supporter.
- IdleSecondary (I) : ces réplicas sont générés par le réplica principal. Ils reçoivent l’état du réplica principal avant d’être promus vers le rôle de secondaire active.
- None (N) : ces réplicas n’ont pas de responsabilité dans le jeu de réplicas.
- Unknown (U) : c’est le rôle initial d’un réplica, avant de recevoir un appel de l’API ChangeRole depuis Service Fabric.
Le diagramme suivant illustre les transitions du rôle de réplica et donne quelques exemples de scénarios dans lesquels celles-ci peuvent se produire :
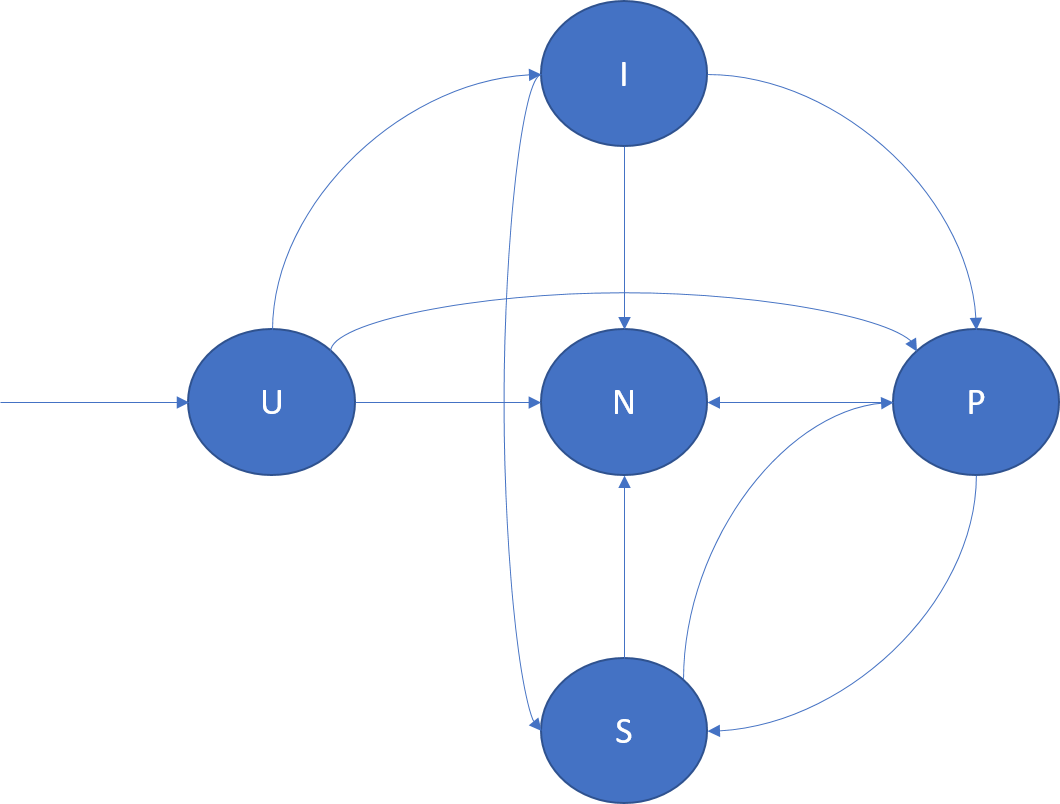
- U -> P :Création d’un réplica principal.
- U -> I : Création d’un réplica inactif.
- U -> N : Suppression d’un réplica en attente.
- I -> S : Promotion du réplica secondaire inactif au rôle de secondaire actif, afin que ses accusés de réception contribuent au quorum.
- I -> P : Promotion du rôle d’inactif secondaire à celui de principal. Ce cas de figure peut se produire sous certaines reconfigurations spéciales, lorsque le réplica secondaire inactif est le candidat approprié pour devenir réplica principal.
- I -> N : Suppression du réplica secondaire inactif.
- S -> P : Promotion du réplica secondaire actif au rôle de réplica principal. Le basculement du principal peut en être la cause, ou un déplacement du principal initié par Cluster Resource Manager. Par exemple, une mise à niveau d’application ou un équilibrage de charge peut en être la cause.
- S -> N : Suppression du réplica secondaire actif.
- P -> S : Rétrogradation du réplica principal. Un déplacement du principal initié par Cluster Resource Manager peut en être à l’origine. Par exemple, une mise à niveau d’application ou un équilibrage de charge peut en être la cause.
- P -> N : Suppression du réplica principal.
Notes
Les modèles de programmation de niveau supérieur, tels que Reliable Actors et Reliable Services, empêchent le développeur de voir le concept de rôle de réplica. Dans Actors, la notion de rôle est superflue. Dans Services, elle est en grande partie simplifiée pour la plupart des scénarios.
Étapes suivantes
Pour plus d’informations sur les concepts propres à Service Fabric, consultez l’article suivant :