Présentation des Acteurs fiables Service Fabric
Reliable Actors est une infrastructure d’application Service Fabric reposant sur le modèle Virtual Actor. L’API Reliable Actors fournit un modèle de programmation monothread qui tire parti des garanties de fiabilité et d’évolutivité fournies par Service Fabric.
Qu’est-ce qu’un « acteur » ?
Un acteur est une unité de calcul et d’état indépendante et isolée, associée à une exécution monothread. Le modèle d’acteur est un modèle de calcul utilisé pour les systèmes simultanés ou distribués dans lesquels un grand nombre de ces acteurs peut s’exécuter simultanément et indépendamment les uns des autres. Les acteurs peuvent communiquer entre eux et créer d’autres acteurs.
Quand utiliser Reliable Actors
Service Fabric Reliable Actors est une implémentation du modèle de conception d’acteurs. Comme pour n’importe quel modèle de conception de logiciels, le choix de l’utilisation d’un modèle spécifique dépend de son degré d’adéquation avec le problème de conception du logiciel.
Bien que le modèle de conception d’acteurs puisse être adapté à divers problèmes et scénarios de systèmes distribués, il est important de bien tenir compte des contraintes du modèle et du cadre servant à sa mise en œuvre. En règle générale, vous pouvez envisager d’utiliser le modèle d’acteur pour modéliser votre problème ou votre scénario si :
- Votre espace de problème implique un nombre élevé (plusieurs milliers) de petites unités d’état et de logique indépendantes et isolées.
- Vous souhaitez travailler avec des objets monothread ne nécessitant aucune interaction significative avec des composants externes, par exemple l’interrogation de l’état sur un ensemble d’acteurs.
- Vos instances d’acteurs ne bloquent pas les appelants avec des retards inattendus en exécutant des opérations d’E/S.
Le rôle des acteurs dans Service Fabric
Dans Service Fabric, les acteurs sont implémentés dans le framework Reliable Actors : un framework d’application s’appuyant sur le modèle d’acteur et Service Fabric Reliable Services. Chaque service Reliable Actor que vous écrivez correspond en fait à une instance Reliable Service partitionnée avec état.
Chaque acteur se définit comme une instance d’un type d’acteur, de la même façon qu’un objet .NET est une instance d’un type .NET. Par exemple, un type d'acteur peut implémenter les fonctionnalités d'une calculatrice, et plusieurs acteurs de ce type peuvent être distribués sur différents nœuds d'un cluster. Chaque acteur de ce type est identifié de façon unique par un ID d'acteur.
Durée de vie de l’acteur
Les acteurs Service Fabric sont virtuels, ce qui signifie que leur durée de vie n'est pas liée à leur représentation en mémoire. En conséquence, ils n’ont pas besoin d’être explicitement créés ou détruits. Le runtime Reliable Actors active automatiquement un acteur la première fois qu’il reçoit une demande pour cet identifiant d’acteur. Si un acteur n’est pas utilisé pendant un certain temps, le runtime Reliable Actors nettoie l’objet en mémoire. Il tient également compte de l’existence de l’acteur si celui-ci doit être réactivé ultérieurement. Pour plus de détails, consultez la page Cycle de vie des acteurs et Garbage Collection.
Cette abstraction de la durée de vie de l’acteur virtuel comporte certains inconvénients liés au modèle d’acteur virtuel ; en réalité, l’implémentation de Reliable Actors diffère parfois de ce modèle.
- Un acteur est automatiquement activé (ce qui entraîne la construction d’un objet d’acteur) la première fois qu’un message est envoyé à son ID d’acteur. Après un certain temps, l’objet d’acteur est nettoyé. Si vous réutilisez ensuite ce même ID d’acteur, un nouvel objet d’acteur sera construit. L’état d’un acteur survit à la durée de vie de l’objet lorsqu’il est stocké dans le gestionnaire d’état.
- Le déclenchement d’une méthode d’acteur pour un ID d’acteur donné aura pour effet d’activer cet acteur. Pour cette raison, le constructeur des types d’acteur est implicitement appelé par le runtime. Par conséquent, le code client ne peut pas transmettre les paramètres au constructeur du type d’acteur, bien que des paramètres puissent être transférés au constructeur de l’acteur par le service lui-même. Le résultat est que les acteurs peuvent être construits à un état partiellement initialisé au moment où d’autres méthodes sont appelées si l’acteur nécessite l’envoi de paramètres d’initialisation par le client. Il n’existe aucun point d’entrée unique pour l’activation d’un acteur à partir du client.
- Bien que Reliable Actors crée implicitement des objets d’acteur, vous avez la possibilité de supprimer explicitement un acteur et son état.
Distribution et basculement
Dans un souci de fiabilité et d’évolutivité, Service Fabric distribue les acteurs dans l’ensemble du cluster et les migre automatiquement à partir des nœuds ayant échoué vers des nœuds sains selon les besoins. Il s’agit ici d’une abstraction sur une instance Reliable Service partitionnée avec état. L’exécution des acteurs dans une instance Reliable Service avec état appelée Actor Servicegarantit la distribution, l’évolutivité, la fiabilité et le basculement automatique du service.
Les acteurs sont distribués sur les partitions d’Actor Service, et ces partitions sont réparties entre les nœuds d’un cluster Service Fabric. Chaque partition de service contient un ensemble d’acteurs. Service Fabric gère la distribution et le basculement des partitions du service.
Par exemple, un service d’acteur avec neuf partitions déployées sur trois nœuds à l’aide de l’emplacement de partition d’acteurs par défaut serait distribué comme suit :
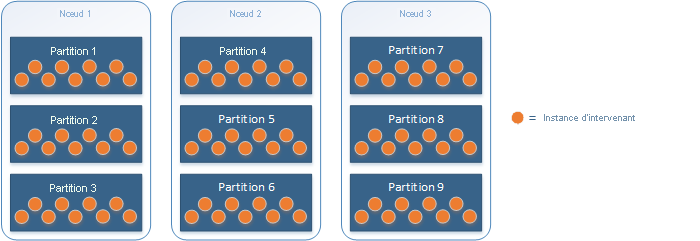
L’infrastructure Actor gère automatiquement les paramètres du schéma de partitions et de la plage de clés. Bien que cela simplifie certains choix, certains aspects méritent d’être pris en compte :
- Reliable Services vous permet de choisir un schéma de partitionnement, une plage de clés (lorsque vous utilisez un schéma de partitionnement par plage) et un nombre de partitions. Reliable Actors est limité au schéma de partitionnement par plage (schéma uniforme Int64) et vous oblige à utiliser la plage de clés Int64 complète.
- Par défaut, les acteurs sont placés aléatoirement dans les partitions, ce qui entraîne une distribution uniforme.
- Du fait de ce placement aléatoire, il faudra vraisemblablement s’attendre à ce que les opérations d’acteur requièrent systématiquement une communication réseau, y compris la sérialisation et la désérialisation des données d’appel de méthode, ce qui implique un effet de latence et une surcharge.
- Dans les scénarios avancés, il est possible de contrôler le placement des partitions en utilisant des ID d’acteur Int64 ID qui correspondent à des partitions spécifiques. Toutefois, cette opération peut entraîner une répartition déséquilibrée des acteurs sur les différentes partitions.
Pour plus d’informations sur le mode de partitionnement des services d’acteur, reportez-vous à la rubrique relative aux concepts de partitionnement pour les acteurs.
Communication d’acteur
Les interactions d’acteur sont définies dans une interface partagée entre l’acteur qui implémente l’interface et le client qui obtient un proxy vers un acteur via la même interface. Étant donné que cette interface est utilisée pour appeler des méthodes d’acteur de façon asynchrone, toutes les méthodes sur l’interface doivent retourner des tâches.
Comme les appels de méthode et leurs réponses aboutissent à des demandes réseau sur le cluster, les arguments et les types de résultat des tâches renvoyées doivent être sérialisables par la plateforme. En particulier, ils doivent être sérialisables en contrat de données.
Le proxy d’acteur
L’API du client Reliable Actors assure la communication entre une instance d’acteur et un client d’acteur. Pour communiquer avec un acteur, un client crée un objet proxy d'acteur qui implémente l'interface d'acteur. Le client interagit avec l'acteur en appelant des méthodes sur l'objet proxy. Le proxy d’acteur peut être utilisé pour les communications client-acteur et acteur-acteur.
// Create a randomly distributed actor ID
ActorId actorId = ActorId.CreateRandom();
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
IMyActor myActor = ActorProxy.Create<IMyActor>(actorId, new Uri("fabric:/MyApp/MyActorService"));
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
await myActor.DoWorkAsync();
// Create actor ID with some name
ActorId actorId = new ActorId("Actor1");
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
MyActor myActor = ActorProxyBase.create(actorId, new URI("fabric:/MyApp/MyActorService"), MyActor.class);
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
myActor.DoWorkAsync().get();
Notez que les deux informations utilisées pour créer l’objet proxy d’acteur sont l’ID d’acteur et le nom d’application. L’ID d’acteur identifie de façon unique l’acteur, tandis que le nom d’application identifie l’ application Service Fabric dans laquelle l’acteur est déployé.
La classe ActorProxy(C#) / ActorProxyBase(Java) côté client effectue la résolution nécessaire pour localiser l’acteur par ID et ouvrir un canal de communication avec lui. Cette classe retente également de localiser l’acteur en cas d’échecs de communication et de basculements. Par conséquent, la remise des messages présente les caractéristiques suivantes :
- La remise de messages est conseillée.
- Les acteurs peuvent recevoir des messages en double provenant du même client.
Accès concurrentiel
Le runtime Reliable Actors fournit un modèle d’accès en alternance simple pour accéder aux méthodes d’acteur. Cela signifie qu’un seul thread peut être actif à tout moment à l’intérieur du code d’un objet d’acteur. L’accès en alternance simplifie considérablement l’exécution de systèmes simultanés dans la mesure où aucun mécanisme de synchronisation n’est nécessaire pour accéder aux données. Cela signifie également que les systèmes doivent être conçus en tenant tout particulièrement compte de la nature de l’accès monothread de chaque instance d’acteur.
- Une instance unique d’acteur ne peut pas traiter plusieurs demandes à la fois. Une instance d’acteur peut provoquer un goulot d’étranglement au niveau du débit si elle est prévue pour gérer des demandes simultanées.
- Les acteurs peuvent se bloquer mutuellement s’il existe une demande circulaire entre deux acteurs alors qu’une demande externe est effectuée simultanément à un des acteurs. Le runtime de l’acteur expirera automatiquement lors des appels de l’acteur et lèvera une exception à l’appelant afin d’interrompre toute situation de blocage potentielle.
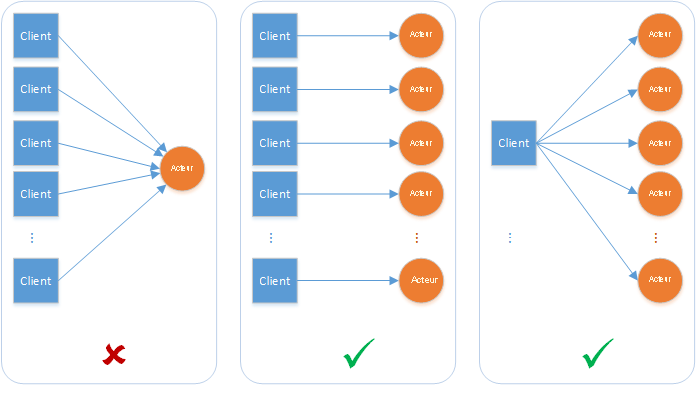
Accès en alternance
Un tour consiste en l’exécution complète d’une méthode d’acteur en réponse à une demande d’autres acteurs ou clients, ou l’exécution complète d’un rappel de minuterie/rappel . Bien que ces méthodes et ces rappels soient asynchrones, le runtime Actors ne les entremêle pas. Un tour doit être totalement terminé avant qu’un nouveau tour soit autorisé. En d’autres termes, une méthode d’acteur ou un rappel de minuterie/rappel en cours d’exécution doit être totalement terminé avant qu’un nouvel appel à une méthode ou qu’un rappel soit autorisé. Une méthode ou un rappel est considéré terminé si l’exécution a été retournée depuis la méthode ou le rappel et que la tâche retournée par la méthode ou le rappel est terminée. Il est important de souligner que cet accès concurrentiel en alternance est respecté même dans les différents rappels, minuteries et méthodes.
Le runtime Actors applique un accès concurrentiel en alternance en acquérant un verrou par acteur au début d'un tour et en le relâchant à la fin du tour. Par conséquent, l'accès concurrentiel en alternance est appliqué sur une base par acteur et non entre acteurs. Les méthodes d'acteur et les rappels de minuterie/rappel peuvent s'exécuter simultanément pour le compte de différents acteurs.
L'exemple suivant illustre les concepts ci-dessus : Prenons l’exemple d’un type d’acteur qui implémente deux méthodes asynchrones (par exemple, Method1 et Method2), une minuterie et un rappel. Le diagramme suivant montre un exemple de chronologie de l’exécution de ces méthodes et rappels pour le compte de deux acteurs (ActorId1 et ActorId2) qui appartiennent à ce type d’acteur.
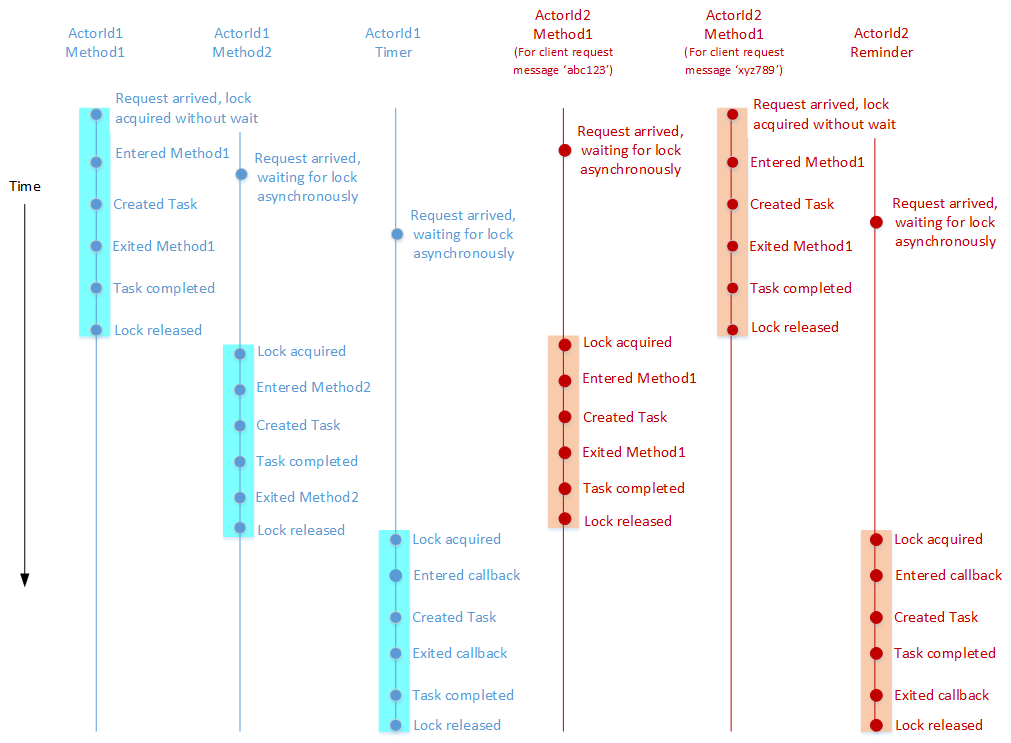
Ce diagramme suit les conventions suivantes :
- Chaque ligne verticale indique le flux logique d'exécution d'une méthode ou d'un rappel pour le compte d'un acteur spécifique.
- Les événements marqués sur chaque ligne verticale se produisent dans l’ordre chronologique, les nouveaux événements se trouvant en dessous des plus anciens.
- Différentes couleurs sont utilisées pour les chronologies des différents acteurs.
- La mise en surbrillance est utilisée pour indiquer la durée pendant laquelle le verrou par acteur est maintenu pour le compte d'une méthode ou d'un rappel.
Quelques points importants à prendre en compte :
- Pendant que Method1 s’exécute pour le compte d’ActorId2 en réponse à la demande du client xyz789, une autre demande du client (abc123) arrive et nécessite également que Method1 soit exécutée par ActorId2. Toutefois, la seconde exécution de Method1 ne commence pas tant que l’exécution précédente n’est pas terminée. De même, un rappel enregistré par ActorId2 se déclenche lors de l'exécution de Method1 en réponse à la demande du client xyz789. Le rappel de rappel est exécuté uniquement une fois que les deux exécutions de Method1 sont terminées. Cela s'explique par l'application de l'accès concurrentiel en alternance à ActorId2.
- De même, l’accès concurrentiel en alternance est également appliqué à ActorId1, comme l’illustrent l’exécution en série de Method1 / Method2 et le rappel de minuterie pour le compte d’ActorId1.
- L'exécution de Method1 pour le compte d'ActorId1 se chevauche avec son exécution pour le compte d'ActorId2. En effet, l’accès concurrentiel en alternance est appliqué uniquement au sein d’un acteur et non entre les acteurs.
- Dans certaines exécutions de méthode/de rappel, le
Task(C#)/CompletableFuture(Java) retourné par la méthode/le rappel se termine après le retour de la méthode. Dans d’autres exécutions, l’opération asynchrone est déjà terminée au moment du retour de la méthode/du rappel. Dans les deux cas, le verrou par acteur n’est relâché qu’après le retour de la méthode/du rappel et la fin de l’opération asynchrone.
Réentrance
Le runtime Actors autorise la réentrance par défaut. Cela signifie que, si une méthode de l’acteur A appelle une méthode sur l’acteur B, qui appelle à son tour une autre méthode sur l’acteur A, cette méthode peut s’exécuter. En effet, elle fait partie du même contexte de chaîne d’appel logique. Tous les appels du minuteur et du rappel démarrent avec le nouveau contexte d'appel logique. Pour plus d’informations, consultez Réentrance Reliable Actors .
Étendue des garanties d'accès concurrentiel
Le runtime Actors fournit ces garanties d'accès concurrentiel dans les situations où il contrôle l'appel de ces méthodes. Par exemple, il fournit ces garanties pour les appels de méthode effectués en réponse à une demande du client, ainsi que pour les rappels de minuterie et de rappel. Toutefois, si le code de l'acteur appelle directement ces méthodes en dehors des mécanismes fournis par le runtime Actors, celui-ci ne peut pas fournir de garanties d'accès concurrentiel. Par exemple, si la méthode est appelée dans le contexte d’une tâche qui n’est pas associée à la tâche retournée par les méthodes d’acteur, le runtime ne peut pas fournir de garantie d’accès concurrentiel. Il en va de même si la méthode est appelée à partir d’un thread créé par l’acteur de son côté. Ainsi, pour effectuer des opérations d’arrière-plan, les acteurs doivent utiliser les minuteurs d’acteur et les rappels d’acteur , qui respectent l’accès concurrentiel en alternance.
Étapes suivantes
Commencez par créer votre premier service Reliable Actors :