Présentation du contrôle d’intégrité de Service Fabric
Azure Service Fabric introduit un modèle d’intégrité qui fournit une évaluation et des rapports d’intégrité riches, flexibles et extensibles. Ce modèle permet un contrôle quasiment en temps réel de l’état du cluster et des services qu’il exécute. Vous pouvez facilement obtenir les informations de contrôle d’intégrité et corriger les problèmes potentiels avant qu’ils ne s’enchaînent et ne provoquent des pannes massives. Dans le modèle standard, les services envoient des rapports en fonction de leur vue locale et les informations sont agrégées pour fournir une vue globale du cluster.
Les composants Service Fabric utilisent ce modèle d’intégrité enrichi pour signaler leur état actuel. Vous pouvez utiliser le même mécanisme pour établir des rapports sur l’intégrité de vos applications. Si vous investissez dans une fonction de création de rapports sur l’intégrité de qualité élevée, qui capture vos conditions personnalisées, vous pouvez plus facilement détecter et corriger les problèmes liés aux applications en cours d’exécution.
Notes
Nous avons créé le sous-système d’intégrité pour répondre au besoin des mises à niveau surveillées. Service Fabric offre des mises à niveau pour le cluster et les applications sous surveillance, qui offrent une disponibilité totale, sans temps d’arrêt, ainsi qu’une intervention de l’utilisateur réduite, voire inexistante. Pour atteindre ces objectifs, la mise à niveau vérifie l’intégrité en fonction des stratégies de mise à niveau configurées. La mise à niveau ne peut être effectuée que si l’intégrité respecte les seuils désirés. Sinon, la mise à niveau est automatiquement annulée ou suspendue pour offrir aux administrateurs la possibilité de corriger les problèmes. Pour en savoir plus sur les mises à niveau d’application, consultez cet article.
Magasin d’intégrité
Le magasin d’intégrité conserve des informations sur l’intégrité des entités du cluster pour faciliter la récupération et l’évaluation. Il est implémenté en tant que service Service Fabric persistant avec état pour garantir un haut niveau de disponibilité et d'extensibilité. Il fait partie de l’application fabric:/System et est disponible lorsque le cluster est opérationnel.
Entités d'intégrité et hiérarchie
Les entités d’intégrité sont organisées dans une hiérarchie logique qui capture les interactions et les dépendances entre les différentes entités. Le magasin d’intégrité génère automatiquement les entités d’intégrité et la hiérarchie en fonction des rapports provenant des composants Service Fabric.
Les entités d’intégrité reflètent les entités Service Fabric (par ex., l’entité application d’intégrité correspond à une instance d’application déployée dans le cluster, et l’entité nœud d’intégrité correspond à un nœud du cluster Service Fabric). La hiérarchie d’intégrité capture les interactions entre les entités système et constitue la base d’une évaluation avancée de l’intégrité. Vous pouvez découvrir les concepts clés de Service Fabric dans l’article Présentation technique de Service Fabric. Pour plus d’informations sur l’application, consultez Modèle d’application Service Fabric.
Les entités d’intégrité et la hiérarchie permettent un processus efficace de création de rapports, de débogage et d’analyse du cluster et des applications. Le modèle d’intégrité permet une représentation précise et granulaire de l’intégrité de nombreux éléments mobiles du cluster.
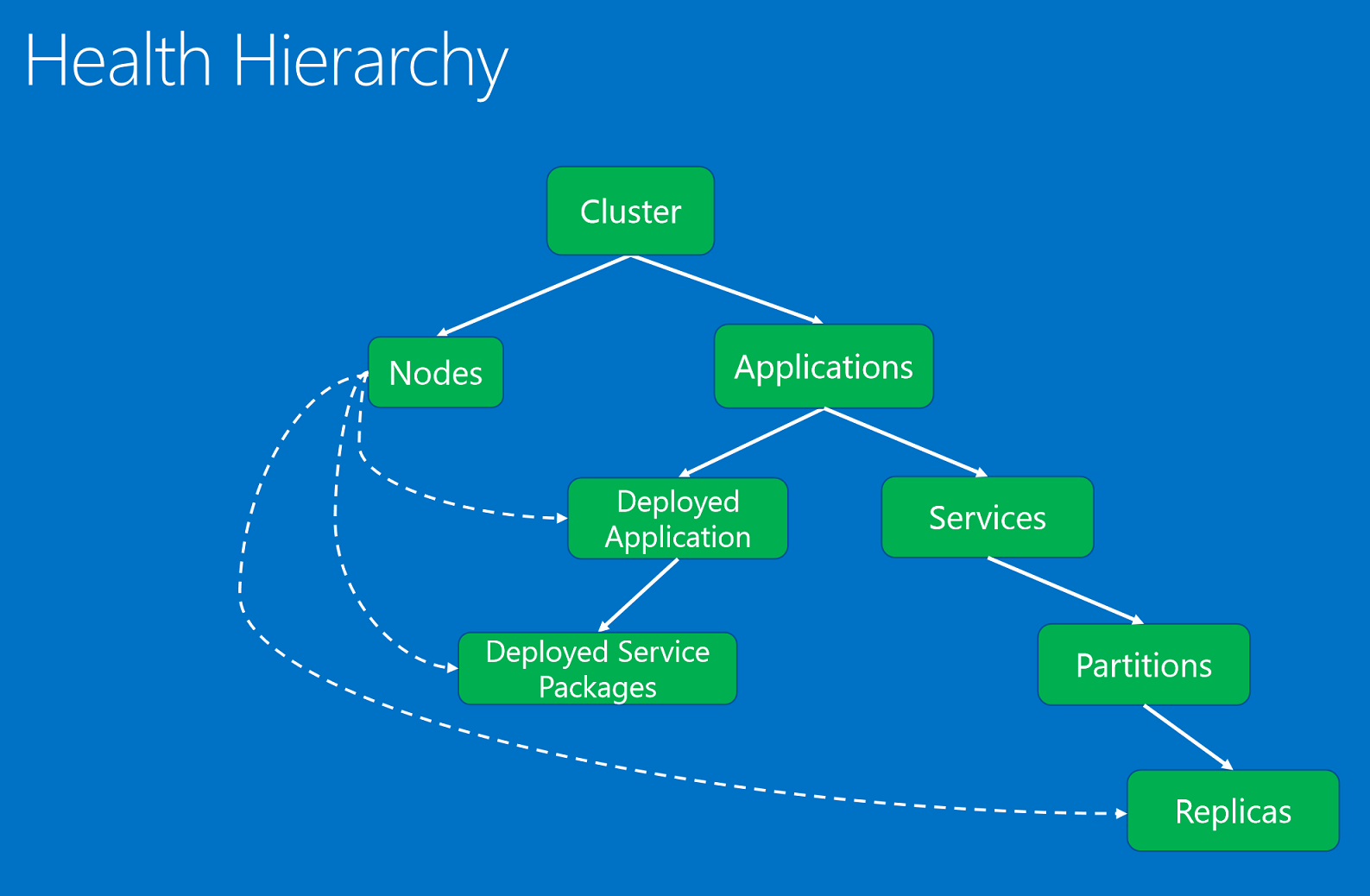 Entités d’intégrité, organisées dans une hiérarchie basée sur les relations parent-enfant.
Entités d’intégrité, organisées dans une hiérarchie basée sur les relations parent-enfant.
Les entités d'intégrité sont les suivantes :
- Cluster. Représente l'intégrité d'un cluster Service Fabric. Les rapports d’intégrité de cluster décrivent les conditions qui affectent l’ensemble du cluster. Ces conditions affectent plusieurs entités du cluster ou l’ensemble du cluster. En fonction de la condition, le rapporteur d’intégrité ne peut pas attribuer le problème à un ou plusieurs enfants non sains. Exemple : split-brain du cluster en raison de problèmes liés au partitionnement réseau ou à la communication.
- Node. Représente l'intégrité d'un nœud Service Fabric. Les rapports d’intégrité de partition décrivent les conditions qui affectent la fonctionnalité de nœud. En général, ces conditions affectent toutes les entités déployées qui sont exécutées sur ce nœud. Exemples : le nœud manque d’espace disque (ou d’une autre propriété au niveau de l’ordinateur comme la mémoire, les connexions, etc.) ou le nœud est inactif. L'entité de nœud est identifiée par le nom du nœud (chaîne).
- Application. Représente l'intégrité d'une instance d'application s'exécutant dans le cluster. Les rapports d’intégrité d’une application décrivent les conditions qui affectent l’intégrité globale de l’application. Ils ne peuvent pas être limités à des enfants particuliers (services ou applications déployées). Exemple : interaction de bout en bout entre les différents services de l’application. L’entité d’application est identifiée par le nom de l’application (URI).
- Service. Représente l'intégrité d'un service s'exécutant dans le cluster. Les rapports d’intégrité du service décrivent les conditions qui affectent l’intégrité globale du service. Le rapporteur ne peut pas attribuer le problème à une partition ou à un réplica non sains. Exemple : une configuration de service (par exemple, le partage de fichiers externes ou de ports) à l’origine de problèmes pour toutes les partitions. L’entité de service est identifiée par le nom du service (URI).
- Partition. Représente l'intégrité d'une partition de service. Les rapports d'intégrité de partition décrivent les conditions qui affectent le jeu entier de réplicas. Exemple : le nombre de réplicas est inférieur au nombre cible ou la partition est en perte de quorum. L’entité de partition est identifiée par l’ID de la partition (GUID).
- Réplica. Représente l'intégrité d'un réplica de service avec état ou d'une instance de service sans état. Le réplica est la plus petite unité sur laquelle les agents de surveillance et les composants système peuvent établir des rapports pour une application. Exemple : pour les services avec état, le réplica principal peut ne pas répliquer des opérations sur les réplicas secondaires et ralentir la réplication. Une instance sans état peut également signaler qu’elle manque de ressources ou présente des problèmes de connectivité. L’entité de réplica est identifiée par l’ID de la partition (GUID) et l’ID de l’instance ou du réplica (long).
- DeployedApplication. Représente l’intégrité d’une application s’exécutant sur un nœud. Les rapports d'intégrité d'application déployée décrivent les conditions propres à l'application sur le nœud. Ils ne peuvent pas être limités aux packages de service déployés sur le même nœud. Exemple : des erreurs surviennent lorsque le package d’application ne peut pas être téléchargé sur le nœud ou un problème se produit lors de la configuration des principaux de sécurité de l’application sur le nœud. L’application déployée est identifiée par le nom de l’application (URI) et le nom du nœud (chaîne).
- Package de service déployé. Représente l’intégrité d’un package de services s’exécutant sur un nœud du cluster. Il décrit les conditions propres à un package de service qui n'affectent pas les autres packages de service sur le même nœud pour la même application. Exemple : un package de code dans le package de service qui ne peut pas être démarré et un package de configuration qui ne peut pas être lu. Le package de service déployé est identifié par le nom de l’application (URI), le nom du nœud (chaîne), le nom du manifeste de service (chaîne) et l’ID d’activation du package de service (chaîne).
La granularité du modèle d'intégrité facilite la détection et la correction des problèmes. Par exemple, si un service ne répond pas, il est possible d’indiquer que l’instance d’application est défectueuse. Toutefois, la création de rapports à ce niveau n’est pas idéale, car le problème n’affecte peut-être pas tous les services au sein de cette application. Le rapport doit être appliqué sur le service défectueux ou sur une partition enfant spécifique, si plus d’informations pointent vers cette partition. Les données apparaissent automatiquement dans la hiérarchie ; une partition défectueuse est visible au niveau du service et de l’application. Cette agrégation permet d’identifier et de résoudre plus rapidement la cause principale d’un problème.
La hiérarchie d’intégrité est composée de relations parent-enfant. Un cluster est composé de nœuds et d’applications. Les applications contiennent des services et des applications déployées. Les applications déployées ont elles-mêmes déployé des packages de service. Les services contiennent des partitions, et chaque partition possède un ou plusieurs réplicas. Il existe une relation spéciale entre les nœuds et les entités déployées. Un nœud non sain est signalé par son composant système d’autorité (service Failover Manager) et affecte les applications déployées, les packages de services et les réplicas déployés sur celui-ci.
La hiérarchie d'intégrité représente le dernier état du système basé sur les derniers rapports d'intégrité, c'est-à-dire, des informations quasiment en temps réel. Les agents de surveillance internes et externes peuvent établir des rapports sur les mêmes entités en fonction de la logique spécifique de l’application ou des conditions personnalisées surveillées. Les rapports utilisateur coexistent avec les rapports système.
Nous vous encourageons à investir dans une fonction de création de rapports et de réponse aux problèmes d’intégrité lors de la conception d’un service cloud volumineux. Vous faciliterez ainsi le débogage, la surveillance et l'utilisation du service.
États d'intégrité
Service Fabric utilise trois états d'intégrité pour indiquer si une entité est saine ou non : OK, Warning et Error. Tous les rapports envoyés au magasin d’intégrité doivent spécifier l’un de ces états. Le résultat de l'évaluation d'intégrité est l'un de ces états.
Les états d’intégrité possibles sont les suivants :
- OK. L’entité est saine. Aucun problème connu n'est signalé sur elle ou ses enfants (le cas échéant).
- Warning. L’entité rencontre des erreurs, mais fonctionne encore correctement. Par exemple, elle connaît des retards, mais ceux-ci n’empêchent pas encore son bon fonctionnement. Dans certains cas, l’avertissement peut se résoudre tout seul sans intervention externe. Dans ce cas, les rapports d’intégrité vous informent de l’avertissement et expliquent ce qui se passe. Dans d’autres cas, la condition Warning peut se dégrader en un grave problème si l’utilisateur n’intervient pas.
- Error. L’entité est défectueuse. Une mesure doit être prise pour résoudre l’état de l’entité, car elle ne peut pas fonctionner correctement.
- Unknown. L’entité n’existe pas dans le magasin d’intégrité. Ce résultat peut être obtenu à partir des requêtes distribuées qui fusionnent les résultats de plusieurs composants. Par exemple, une requête portant sur l’obtention d’une liste de nœuds accède à FailoverManager, ClusterManager et HealthManager, alors qu’une requête portant sur l’obtention d’une liste d’applications accède à ClusterManager et à HealthManager. Cette fusion de requêtes est le résultat de plusieurs composants système. Si un autre composant système retourne une entité qui ne se trouve pas dans le magasin d’intégrité, le résultat fusionné présente un état d’intégrité inconnu. Une entité peut ne pas se trouver dans le magasin parce que les rapports d’intégrité n’ont pas encore été traités ou parce que l’entité a été nettoyée après sa suppression.
Stratégies d'intégrité
Le magasin d’intégrité applique des stratégies d’intégrité pour déterminer si une entité est saine en fonction de ses rapports et de ses enfants.
Notes
Les stratégies d’intégrité peuvent être spécifiées dans le manifeste de cluster (pour l’évaluation de l’intégrité des clusters et des nœuds) ou dans le manifeste d’application (pour l’évaluation de l’application et de tous ses enfants). Les demandes d’évaluation d’intégrité peuvent également transmettre des stratégies d’évaluation d’intégrité personnalisées, utilisées uniquement pour cette évaluation.
Par défaut, Service Fabric applique des règles strictes (tous les éléments doivent être sains) pour la relation hiérarchique parent-enfant. Si au moins un des enfants comporte un événement défectueux, le parent est considéré comme défectueux.
Stratégie d’intégrité de cluster
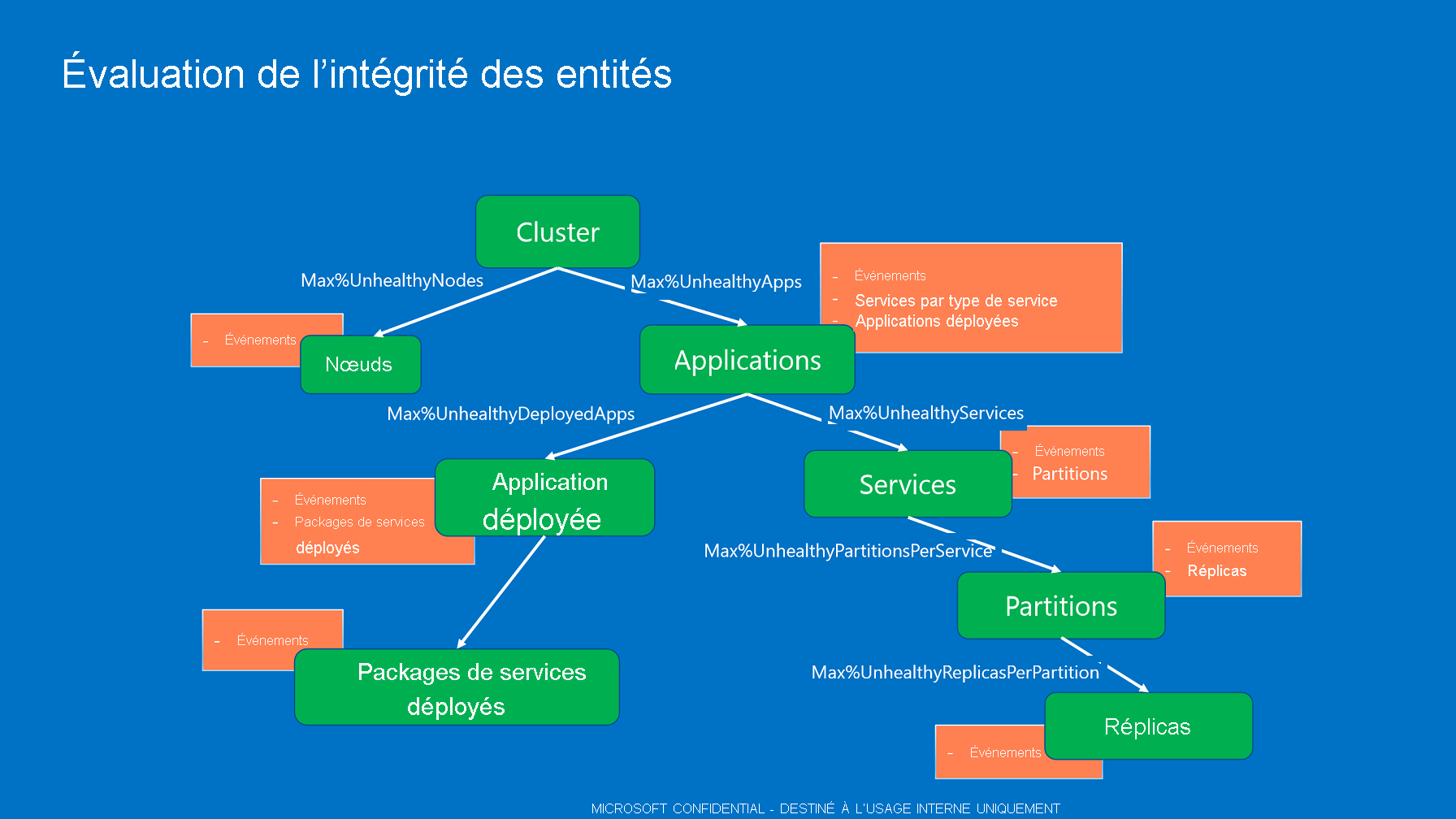
La stratégie d’intégrité de cluster est utilisée pour évaluer l’état d’intégrité du cluster et des nœuds. Elle peut être définie dans le manifeste de cluster. Si elle n’est pas spécifiée, la stratégie par défaut (aucun échec autorisé) est utilisée.
La stratégie d’intégrité de cluster contient :
ConsiderWarningAsError. Spécifie s’il faut traiter les rapports d’intégrité Warning comme des erreurs pendant l’évaluation de l’intégrité. Valeur par défaut : false.
MaxPercentUnhealthyApplications. Spécifie le pourcentage maximum toléré d’applications pouvant être défectueuses avant que l’intégrité du cluster ne soit considérée comme étant à l’état Error.
MaxPercentUnhealthyNodes. Spécifie le pourcentage maximum toléré de nœuds pouvant être défectueux avant que l’intégrité du cluster ne soit considérée comme étant à l’état Error. Dans les clusters de grande taille, certains nœuds sont toujours inactifs ou en réparation. Ce pourcentage doit donc être configuré pour tolérer cette condition.
ApplicationTypeHealthPolicyMap. Le mappage de stratégie d’intégrité de type application peut être utilisé lors de l’évaluation de l’intégrité du cluster pour décrire les types d’applications particuliers. Par défaut, toutes les applications sont placées dans un pool et évaluées avec MaxPercentUnhealthyApplications. Si certains types d’application doivent être traités différemment, ils peuvent être retirés du pool global. Au lieu de cela, ils sont évalués par rapport aux pourcentages associés à leur nom de type d’application dans le mappage. Par exemple, un cluster contient des milliers d’applications de types différents et plusieurs instances d’application de contrôle d’un type d’application particulier. Les applications de contrôle ne doivent jamais être erronées. Vous pouvez spécifier le pourcentage global MaxPercentUnhealthyApplications sur 20 % pour tolérer certains échecs, mais dans le cas du type d’application « ControlApplicationType » la valeur MaxPercentUnhealthyApplications doit être définie sur 0. De cette façon, si certaines des nombreuses applications sont défectueuses, mais que leur nombre est inférieur au pourcentage défectueux global, le cluster est évalué avec le niveau Warning (avertissement). Un état d’avertissement pour l’intégrité n’affecte pas la mise à niveau du cluster, ni les autres analyse déclenchées par l’état Error (erreur). Toutefois, même si une seule application de contrôle rencontre une erreur, le cluster dans son ensemble est défectueux, ce qui déclenche la restauration ou interrompt la mise à niveau du cluster, selon la configuration de cette dernière. Pour les types d’applications définis dans le mappage, toutes les instances d’applications sont retirées du pool d’applications global. Elles sont évalués en fonction du nombre total d’applications du type d’application, à l’aide de la valeur MaxPercentUnhealthyApplications spécifique issue du mappage. Toutes les autres applications restent dans le pool global et sont évaluées avec MaxPercentUnhealthyApplications.
Voici un extrait de manifeste de cluster. Pour définir des entrées dans le mappage du type d’application, ajoutez en préfixe « ApplicationTypeMaxPercentUnhealthyApplications-» au nom du paramètre, suivi du nom du type d’application.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Le mappage de stratégie d’intégrité de type de nœud peut être utilisé lors de l’évaluation de l’intégrité du cluster pour décrire les types de nœuds particuliers. Les types de nœuds sont évalués par rapport aux pourcentages associés à leur nom de type de nœud dans le mappage. La définition de cette valeur n’a aucun effet sur le pool global de nœuds utilisés pourMaxPercentUnhealthyNodes. Par exemple, un cluster compte des centaines de nœuds de types différents et quelques types de nœuds qui hébergent un travail important. Aucun nœud de ce type ne doit être arrêté. Vous pouvez spécifier la valeurMaxPercentUnhealthyNodesglobale sur 20 % pour tolérer certaines défaillances pour tous les nœuds, mais pour le type de nœudSpecialNodeType, définissez la valeur deMaxPercentUnhealthyNodessur 0. Ainsi, si certains des nombreux nœuds sont défectueux, mais que leur nombre est inférieur au pourcentage défectueux global, le cluster est évalué comme étant dans l’état d’intégrité Avertissement. Un état d’intégrité Avertissement n’affecte pas la mise à niveau du cluster, ou d’autres analyse déclenchées par un état d’intégrité Erreur. Toutefois, même un seul nœud de typeSpecialNodeTypedans un état d’intégrité Erreur rend le cluster défectueux et déclenche une restauration, ou suspend la mise à niveau du cluster, en fonction de la configuration de la mise à niveau. Inversement, la définition de la valeurMaxPercentUnhealthyNodesglobale sur 0 et la définition du pourcentage maximal de nœuds défectueuxSpecialNodeTypesur 100 avec un nœud de typeSpecialNodeTypedans un état d’erreur continueraient de mettre le cluster dans un état d’erreur, car la restriction globale est plus stricte dans ce cas.Voici un extrait de manifeste de cluster. Pour définir des entrées dans le mappage du type de nœud, ajoutez au nom du paramètre le préfixe « NodeTypeMaxPercentUnhealthyNodes- », suivi du nom du type de nœud.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Stratégie d’intégrité d’application
La stratégie d’intégrité d’application décrit la procédure d’évaluation des événements et une agrégation des états enfants est effectuée pour les applications et leurs enfants. Elle peut être définie dans le manifeste d’application, ApplicationManifest.xml, dans le package d’application. Si aucune stratégie n’est spécifiée, Service Fabric suppose que l’entité est défectueuse si elle (ou un de ses enfants) se trouve à l’état d’intégrité Warning ou Error. Les stratégies configurables sont les suivantes :
- ConsiderWarningAsError. Spécifie s’il faut traiter les rapports d’intégrité Warning comme des erreurs pendant l’évaluation de l’intégrité. Valeur par défaut : false.
- MaxPercentUnhealthyDeployedApplications. Spécifie le pourcentage maximum toléré d’applications déployées pouvant être défectueuses avant que l’application ne soit considérée comme étant à l’état Error. On calcule ce pourcentage en divisant le nombre d’applications déployées défectueuses par le nombre de nœuds sur lesquels les applications sont actuellement déployées dans le cluster. Le calcul est arrondi pour tolérer une défaillance sur un petit nombre de nœuds. Pourcentage par défaut : zéro.
- DefaultServiceTypeHealthPolicy. Spécifie la stratégie d’intégrité du type de service par défaut, qui remplacera la stratégie d’intégrité par défaut pour tous les types de service dans l’application.
- ServiceTypeHealthPolicyMap. Fournit une liste de stratégies d’intégrité de service par type de service. Ces stratégies remplacent les stratégies d’intégrité de type de service par défaut pour chaque type de service spécifié. Par exemple, si une application est associée à un type de service de passerelle sans état et à un type de service de moteur avec état, vous pouvez configurer différemment les stratégies de contrôle d’intégrité relatives à leur évaluation. La spécification d’une stratégie par type de service permet un contrôle plus précis de l’intégrité du service.
Stratégie d’intégrité de type de service
La stratégie d’intégrité de type de service spécifie comment évaluer et agréger les services et les enfants des services. La stratégie contient les éléments suivants :
- MaxPercentUnhealthyPartitionsPerService. Spécifie le pourcentage maximum toléré de partitions défectueuses avant qu’un service ne soit considéré comme étant défectueux. Pourcentage par défaut : zéro.
- MaxPercentUnhealthyReplicasPerPartition. Spécifie le pourcentage maximum toléré de réplicas défectueux avant qu’une partition ne soit considérée comme étant défectueuse. Pourcentage par défaut : zéro.
- MaxPercentUnhealthyServices. Spécifie le pourcentage maximum toléré de services défectueux avant que l’application ne soit considérée comme étant défectueuse. Pourcentage par défaut : zéro.
Voici un extrait de manifeste d’application :
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Évaluation de l'intégrité
Les utilisateurs et les services automatisés peuvent évaluer l’intégrité de toutes les entités à tout moment. Pour évaluer l’intégrité d’une entité, le magasin d’intégrité regroupe tous les rapports d’intégrité sur l’entité et évalue tous ses enfants (le cas échéant). L’algorithme d’agrégation d’intégrité utilise des stratégies d’intégrité qui spécifient comment évaluer les rapports d’intégrité et comment agréger les états d’intégrité des enfants (le cas échéant).
Agrégation de rapports d’intégrité
Une entité peut avoir plusieurs rapports d'intégrité envoyés par différents rapporteurs (composants système ou agents de surveillance) sur différentes propriétés. L’agrégation utilise les stratégies d’intégrité associées, en particulier le membre ConsiderWarningAsError de la stratégie d’intégrité d’application ou de cluster, qui spécifie la façon d’évaluer les avertissements.
L'état d'intégrité agrégé est déclenché par les pires rapports d'intégrité sur l'entité. S’il existe au moins un rapport d’intégrité Error, l’état d’intégrité agrégé sera Error.
Une entité d’intégrité qui inclut un ou plusieurs rapports d’intégrité en erreur est considérée comme à l’état Error. Il en va de même pour rapport d’intégrité ayant expiré, quel que soit son état d’intégrité.
S’il n’existe aucun rapport Error mais un ou plusieurs rapports Warning, l’état d’intégrité agrégé sera Warning ou Error, en fonction de l’indicateur de stratégie ConsiderWarningAsError.
Agrégation de rapports d’intégrité avec un état Warning et une valeur ConsiderWarningAsError définie sur false (par défaut).
Agrégation d’intégrité des enfants
L’état d’intégrité agrégé d’une entité reflète les états d’intégrité des enfants (le cas échéant). L’algorithme d’agrégation des états d’intégrité des enfants utilise les stratégies d’intégrité applicables selon le type d’entité.
Agrégation d’enfants basée sur les stratégies d’intégrité.
Une fois que le magasin d’intégrité a évalué tous les enfants, il agrège leurs états d’intégrité en fonction du pourcentage maximal d’enfants défectueux configuré. Ce pourcentage est dérivé de la stratégie basée sur le type d’entité et d’enfant.
- Si tous les enfants sont à l’état OK, l’état d’intégrité agrégé des enfants sera OK.
- Si des enfants ont des états OK et Warning, l’état d’intégrité agrégé des enfants sera Warning.
- S’il existe des enfants à l’état Error dont le nombre dépasse le pourcentage maximum autorisé d’enfants défectueux, l’état d’intégrité parent agrégé sera Error.
- Si le nombre d’enfants à l’état Error ne dépasse pas le pourcentage maximum autorisé d’enfants défectueux, l’état d’intégrité parent agrégé sera Warning.
Rapports d'intégrité
Les composants système, les applications System Fabric et les agents de surveillance internes/externes peuvent établir des rapports sur les entités Service Fabric. Les rapporteurs déterminent localement l’intégrité des entités analysées en fonction des conditions dans lesquelles elles sont contrôlées. Ils n’ont pas besoin d’examiner les données d’agrégation ou l’état global. Le comportement voulu consiste à disposer de rapporteurs simples, au lieu d’organismes complexes, qui doivent examiner de nombreux éléments pour en déduire les informations à envoyer.
Pour envoyer des données d’intégrité au magasin d’intégrité, le rapporteur doit identifier l’entité affectée et créer un rapport d’intégrité. Pour envoyer le rapport, utilisez l’API FabricClient.HealthClient.ReportHealth, les API de rapports d’intégrité exposées sur les objets Partition ou CodePackageActivationContext, les applets de commande PowerShell ou REST.
Rapports d'intégrité
Les rapports d'intégrité de chaque entité du cluster contiennent les informations suivantes :
SourceId. Chaîne qui identifie de façon unique le rapporteur de l'événement d'intégrité.
Entity identifier. Identifie l’entité sur laquelle le rapport est appliqué. Il diffère selon le type d'entité:
- Cluster. Aucun.
- Nœud. Nom du nœud (chaîne).
- console. Nom de l’application (URI). Représente le nom de l'instance d'application déployée dans le cluster.
- Service. Nom du service (URI). Représente le nom de l'instance de service déployée dans le cluster.
- Partition. ID de la partition (GUID). Représente l'identificateur de partition unique.
- Réplica. ID du réplica du service avec état ou ID de l’instance du service sans état (INT64).
- DeployedApplication. Nom de l’application (URI) et nom du nœud (chaîne).
- DeployedServicePackage. Nom de l’application (URI), nom du nœud (chaîne) et nom du manifeste de service (chaîne).
Property. Chaîne (et non énumération fixe) qui permet au rapporteur de classer l'événement d'intégrité pour une propriété spécifique de l'entité. Par exemple, le rapporteur A peut établir un rapport d’intégrité sur la propriété « stockage » du Nœud01 et le rapporteur B sur la propriété « connectivité » du Nœud01. Dans le magasin d’intégrité, ces rapports sont traités comme des événements d’intégrité pour l’entité Nœud01.
Description. Chaîne qui permet au rapporteur de fournir des informations détaillées sur l’événement d’intégrité. Les éléments SourceId, Property et HealthState doivent donner une description complète du rapport. La description ajoute des informations explicites sur le rapport, Ce texte facilite la compréhension du rapport d’intégrité pour les administrateurs et les utilisateurs.
HealthState. Énumération qui décrit l'état d'intégrité du rapport. Les valeurs acceptées sont OK, Warning et Error.
TimeToLive. Intervalle de temps indiquant la durée de validité du rapport d'intégrité. Associé à RemoveWhenExpired, il indique au magasin d’intégrité comment évaluer les événements expirés. Par défaut, la valeur est infinie et le rapport est toujours valide.
RemoveWhenExpired. Valeur booléenne. Si cette valeur est définie sur true, le rapport d’intégrité expiré est automatiquement supprimé du magasin d’état, sans impact sur l’évaluation de l’intégrité de l’entité. Ce paramètre est utilisé lorsque le rapport est valide pour une période donnée uniquement et que le rapporteur n’a pas besoin d’effacer explicitement. Il est également utilisé pour supprimer des rapports du magasin d’intégrité (par exemple, un agent de surveillance est modifié et cesse d’envoyer des rapports avec la source et la propriété précédentes). Il peut envoyer un rapport avec une faible valeur TimeToLive et avec le paramètre RemoveWhenExpired pour effacer les états précédents dans le magasin d’intégrité. Si la valeur est définie sur false, le rapport expiré est traité comme une erreur pendant l’évaluation de l’intégrité. La valeur false indique au magasin d’intégrité que la source doit établir périodiquement un rapport sur cette propriété. Si ce n’est pas le cas, l’agent de surveillance pose certainement problème. L’intégrité de l’agent de surveillance est capturée en tenant compte de l’événement en tant qu’erreur.
SequenceNumber. Entier positif qui doit être croissant, car il représente l’ordre des rapports. Ce paramètre est utilisé par le magasin d’intégrité pour détecter les rapports obsolètes, qui ont été reçus tardivement en raison de délais sur le réseau ou d’autres problèmes. Un rapport est rejeté si le numéro de séquence est inférieur ou égal au dernier numéro appliqué aux mêmes entité, source et propriété. S’il n’est pas spécifié, le numéro de séquence est généré automatiquement. Il est nécessaire de le placer dans le numéro de séquence uniquement lors de la création de rapports sur les transitions d’état. Dans ce cas, la source doit mémoriser les rapports qu’elle a envoyés et conserver les informations de récupération en cas de basculement.
Les informations SourceId, entity identifier, Property et HealthState sont requises pour tous les rapports d’intégrité. La chaîne SourceId ne doit pas commencer par le préfixe «System. », car il est réservé aux rapports système. Pour la même entité, un seul rapport couvre les mêmes source et propriété. Plusieurs rapports générés pour la même source et la même propriété se remplacent l’un l’autre, du côté du client d’intégrité (s’ils sont traités par lot) ou du côté du magasin d’intégrité. Le remplacement s’effectue en fonction du numéro de séquence : les rapports les plus récents (avec un numéro de séquence supérieur) remplacent les rapports les plus anciens.
Événements d'intégrité
En interne, le magasin d’intégrité conserve les événements d’intégrité, qui contiennent toutes les informations des rapports, ainsi que d’autres métadonnées, lesquelles indiquent l’heure à laquelle le rapport a été remis au client d’intégrité et l’heure de sa modification côté serveur. Les événements d’intégrité sont retournés par des requêtes d’intégrité.
Les métadonnées ajoutées sont notamment :
- SourceUtcTimestamp. Heure à laquelle le rapport a été remis au client d’intégrité (UTC).
- LastModifiedUtcTimestamp. Heure à laquelle le rapport a été modifié côté serveur (UTC).
- IsExpired. Indique si le rapport avait expiré au moment où la requête a été exécutée par le magasin d’intégrité. Un événement peut avoir expiré uniquement si RemoveWhenExpired a la valeur false. Sinon, l’événement n’est pas retourné par la requête et est supprimé du magasin.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Dernières transitions des états OK/Warning/Error. Ces champs fournissent l’historique de la transition des états d’intégrité de l’événement.
Les champs de transition d’état peuvent être utilisés pour des niveaux d’alerte plus intelligents ou pour des informations sur les événements d’intégrité « historiques ». Ils permettent les scénarios suivants :
- Alerte quand une propriété a eu la valeur Error/Warning pendant plus de X minutes. En vérifiant la condition du système pendant une période donnée, vous évitez la génération d’alertes sur des conditions temporaires. Par exemple, une alerte indiquant que l’état d’intégrité a eu la valeur Warning pendant plus de 5 minutes peut être traduite en (HealthState == Warning and Now - LastWarningTransitionTime > 5 minutes).
- Alerte uniquement sur les conditions modifiées au cours des X dernières minutes. Si un rapport indiquait déjà l’état Error avant la période spécifiée, il peut être ignoré car il a déjà été signalé précédemment.
- Si une propriété oscille entre Warning et Error, détermine la durée pendant laquelle elle a été défectueuse (donc pas à l’état OK). Par exemple, une alerte indiquant que la propriété est non saine depuis plus de 5 minutes peut être traduite en (HealthState != Ok and Now - LastOkTransitionTime > 5 minutes).
Exemple : évaluer et établir un rapport sur l'intégrité de l'application
L’exemple suivant envoie un rapport d’intégrité via PowerShell sur l’application fabric:/WordCount à partir de la source MyWatchdog. Le rapport d’intégrité contient des informations sur la « disponibilité » de la propriété d’intégrité dans un état d’intégrité Error avec une valeur TimeToLive infinie. Il interroge ensuite l’intégrité de l’application, qui retourne l’état d’intégrité agrégé Error et les événements d’état signalés dans la liste des événements d’intégrité.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Utilisation du modèle d'intégrité
Le modèle d’intégrité permet aux services cloud et à la plateforme sous-jacente Service Fabric de monter en charge, car les déterminations de la surveillance et de l’intégrité sont réparties entre les différents moniteurs au sein du cluster. D’autres systèmes disposent d’un service centralisé unique au niveau du cluster, qui analyse toutes les informations potentiellement utiles émises par les services. Cette approche empêche leur évolutivité. Elle ne leur permet pas de collecter des informations spécifiques pour aider à identifier les problèmes réels ou potentiels aussi près de la cause principale que possible.
Le modèle d’intégrité est très utilisé pour la surveillance et le diagnostic, pour évaluer l’intégrité du cluster et des applications, et pour les mises à niveau surveillées. D’autres services utilisent les données d’intégrité pour effectuer des réparations automatiques, générer l’historique d’intégrité du cluster et émettre des alertes sous certaines conditions.
Étapes suivantes
Affichage rapports d’intégrité de Service Fabric
Utilisation des rapports d’intégrité système pour la résolution des problèmes
Comment signaler et contrôler l’intégrité du service
Ajout de rapports d’intégrité Service Fabric personnalisés
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour