Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
L’accélération des requêtes permet aux applications et aux infrastructures d’analytique d’optimiser considérablement le traitement des données en récupérant uniquement les données dont elles ont besoin pour effectuer une opération donnée. Cela réduit le temps et la puissance de traitement nécessaires pour obtenir des insights critiques sur les données stockées.
Aperçu
L’accélération des requêtes accepte le filtrage des prédicats et des projections de colonnes, ce qui permet aux applications de filtrer des lignes et des colonnes au moment où les données sont lues à partir du disque. Seules les données qui répondent aux conditions d’un prédicat sont transférées sur le réseau vers l’application. Cela réduit la latence du réseau et le coût de calcul.
Vous pouvez utiliser SQL pour spécifier les prédicats de filtre de lignes et les projections de colonnes dans une requête d’accélération de requête. Une requête traite un seul fichier. Par conséquent, les fonctionnalités relationnelles avancées de SQL, telles que les jointures et les groupes par agrégats, ne sont pas prises en charge. L’accélération des requêtes prend en charge les données au format CSV et JSON comme entrée dans chaque requête.
La fonctionnalité d’accélération des requêtes n’est pas limitée à Data Lake Storage (comptes de stockage sur montrant l’espace de noms hiérarchique activé). L’accélération des requêtes est compatible avec les objets blob dans les comptes de stockage qui n’ont pas d’espace de noms hiérarchique activé sur eux. Cela signifie que vous pouvez obtenir la même réduction de la latence réseau et des coûts de calcul lorsque vous traitez des données que vous avez déjà stockées en tant qu’objets blob dans des comptes de stockage.
Pour obtenir un exemple d’utilisation de l’accélération des requêtes dans une application cliente, consultez Filtrer les données à l’aide de l’accélération des requêtes Azure Data Lake Storage.
Flux de données
Le diagramme suivant illustre comment une application classique utilise l’accélération des requêtes pour traiter les données.
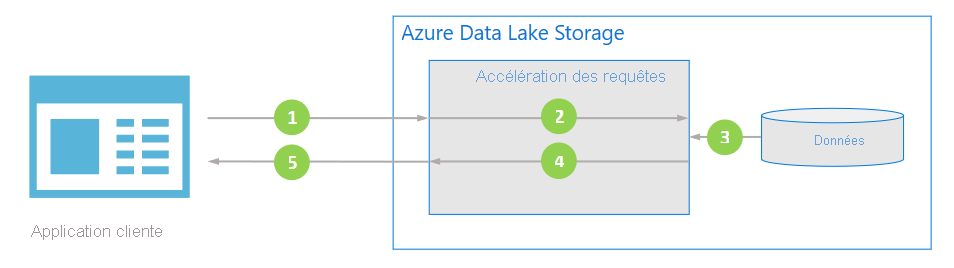
L’application cliente demande des données de fichier en spécifiant des prédicats et des projections de colonnes.
L’accélération des requêtes analyse la requête SQL spécifiée et distribue le travail pour analyser et filtrer les données.
Les processeurs lisent les données du disque, analysent les données à l’aide du format approprié, puis filtrent les données en appliquant les prédicats et projections de colonnes spécifiés.
L’accélération des requêtes combine les partitions de réponse à diffuser en continu vers l’application cliente.
L’application cliente reçoit et analyse la réponse diffusée. L’application n’a pas besoin de filtrer d’autres données et peut appliquer directement le calcul ou la transformation souhaités.
Meilleures performances à moindre coût
L’accélération des requêtes optimise les performances en réduisant la quantité de données transférées et traitées par votre application.
Pour calculer une valeur agrégée, les applications récupèrent généralement toutes les données d’un fichier, puis traitent et filtrent les données localement. Une analyse des modèles d’entrée/sortie pour les charges de travail d’analyse révèle que les applications nécessitent généralement seulement 20% des données qu’elles lisent pour effectuer un calcul donné. Cette statistique est vraie même après avoir appliqué des techniques telles que la taille de partition. Cela signifie que 80% de ces données sont transférées inutilement sur le réseau, analysées et filtrées par les applications. Ce modèle, conçu pour supprimer des données inutiles, entraîne un coût de calcul significatif.
Même si Azure dispose d’un réseau à la pointe du secteur, en termes de débit et de latence, le transfert inutile de données sur ce réseau est toujours coûteux pour les performances des applications. En filtrant les données indésirables pendant la demande de stockage, l’accélération des requêtes élimine ce coût.
En outre, la charge processeur requise pour analyser et filtrer les données inutiles nécessite que votre application approvisionne un plus grand nombre et plus de machines virtuelles afin d’effectuer son travail. En transférant cette charge de calcul à l’accélération des requêtes, les applications peuvent réaliser des économies significatives.
Applications qui peuvent tirer parti de l’accélération des requêtes
L’accélération des requêtes est conçue pour les infrastructures d’analytique distribuée et les applications de traitement des données.
Les frameworks d’analytique distribuée tels qu’Apache Spark et Apache Hive incluent une couche d’abstraction de stockage dans l’infrastructure. Ces moteurs incluent également des optimiseurs de requête qui peuvent incorporer des connaissances sur les fonctionnalités du service d’E/S sous-jacent lors de la détermination d’un plan de requête optimal pour les requêtes utilisateur. Ces frameworks commencent à intégrer l’accélération des requêtes. Par conséquent, les utilisateurs de ces frameworks voient une latence de requête améliorée et un coût total inférieur de possession sans avoir à apporter de modifications aux requêtes.
L’accélération des requêtes est également conçue pour les applications de traitement des données. Ces types d’applications effectuent généralement des transformations de données à grande échelle qui peuvent ne pas conduire directement à des insights analytiques afin qu’elles n’utilisent pas toujours des infrastructures d’analytique distribuée établies. Ces applications ont souvent une relation plus directe avec le service de stockage sous-jacent afin qu’elles puissent tirer parti directement des fonctionnalités telles que l’accélération des requêtes.
Pour obtenir un exemple de la façon dont une application peut intégrer l’accélération des requêtes, consultez Filtrer les données à l’aide de l’accélération des requêtes Azure Data Lake Storage.
Tarification
En raison de la charge de calcul accrue dans le service Azure Data Lake Storage, le modèle de tarification pour l’utilisation de l’accélération des requêtes diffère du modèle de transaction Azure Data Lake Storage normal. L’accélération des requêtes facture un coût pour la quantité de données analysées ainsi qu’un coût pour la quantité de données retournées à l’appelant. Pour plus d’informations, consultez la tarification d’Azure Data Lake Storage.
Malgré le changement de modèle de facturation, le modèle de tarification de l’accélération des requêtes est conçu pour réduire le coût total de possession d’une charge de travail, compte tenu de la réduction des coûts de machine virtuelle beaucoup plus coûteux.