Optimiser les requêtes Apache Hive dans Azure HDInsight
Cet article décrit quelques-unes des optimisations du niveau de performance les plus courantes pour les requêtes Apache Hive.
Dans Azure HDInsight, il est possible d’exécuter des requêtes Apache Hive sur différents types de clusters.
Choisissez le type de cluster approprié pour optimiser le niveau de performance en fonction des besoins de votre charge de travail :
- Choisissez le type de cluster Interactive Query pour optimiser les requêtes interactives
ad hoc. - Choisissez le type de cluster Apache Hadoop pour optimiser les requêtes du répertoire de stockage utilisées comme un processus par lots.
- Les types de clusters Spark et HBase peuvent également exécuter des requêtes Hive. Ils sont appropriés si vous exécutez ces charges de travail.
Pour plus d’informations sur l’exécution de requêtes Hive sur les différents types de cluster HDInsight, consultez la rubrique Présentation d’Apache Hive et HiveQL sur Azure HDInsight.
L’augmentation du nombre de nœuds Worker d’un cluster HDInsight permet d’exécuter plusieurs mappeurs et réducteurs en parallèle. Il existe deux manières d’augmenter l’échelle dans HDInsight :
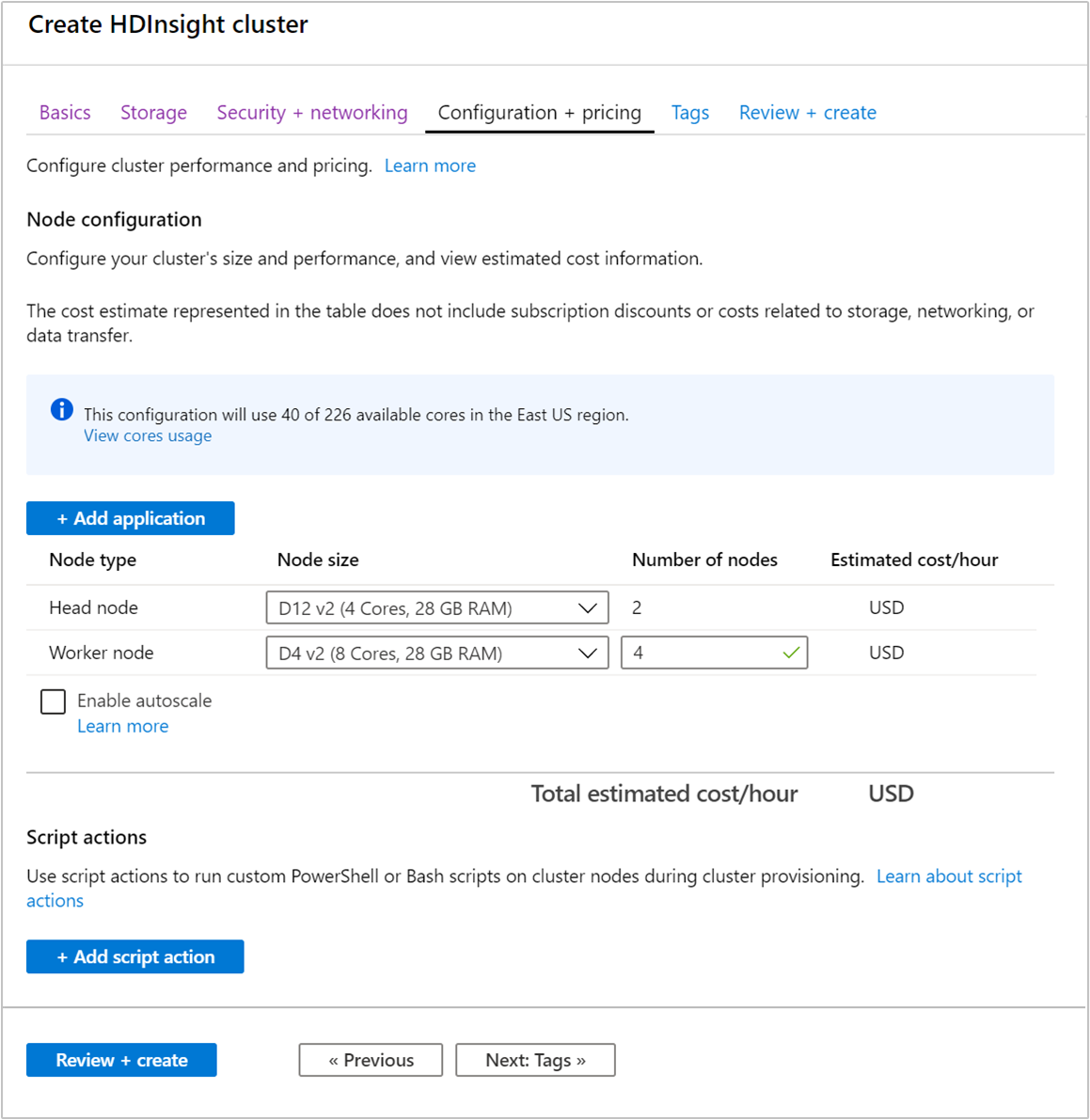
Lors de la création d’un cluster, vous pouvez spécifier le nombre de nœuds Worker à l’aide du portail Azure, d’Azure PowerShell ou d’une interface de ligne de commande. Pour plus d’informations, consultez la rubrique Création de clusters HDInsight. La capture d’écran suivante montre la configuration du nœud Worker sur le portail Azure :
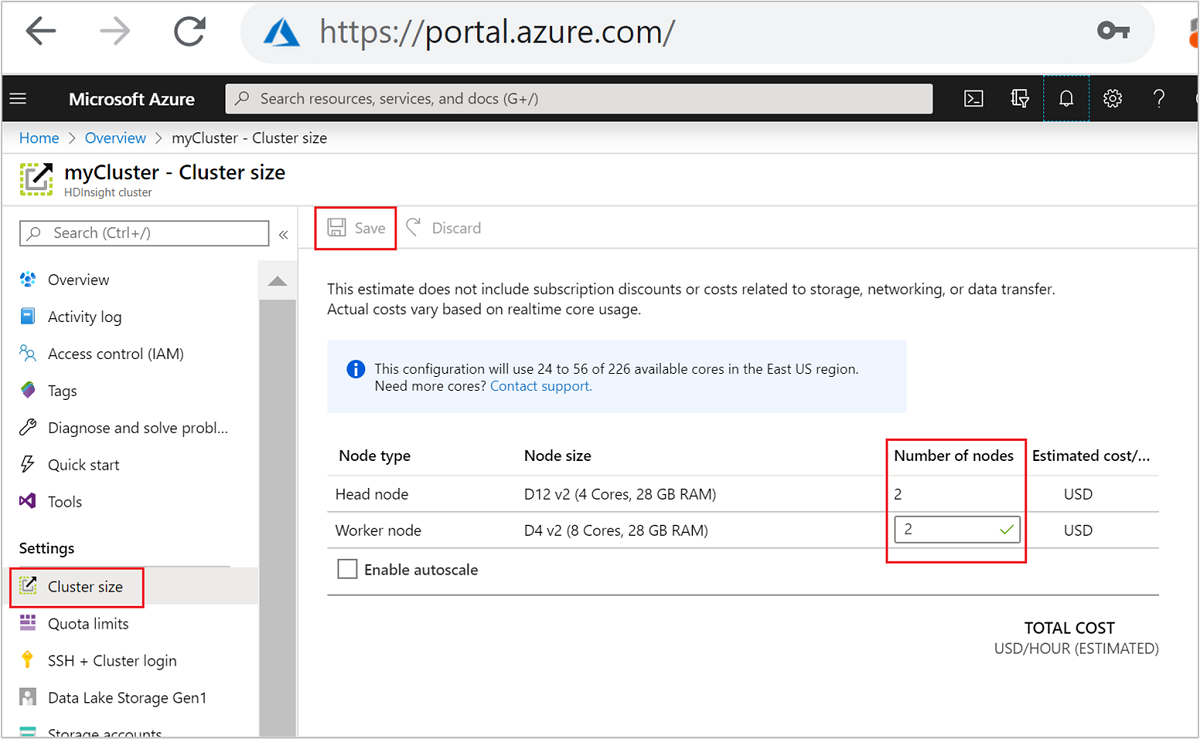
Une fois le cluster créé, vous pouvez également modifier le nombre de nœuds Worker pour effectuer un scale-out d’un cluster sans en recréer un autre :
Pour plus d’informations sur la mise à l’échelle de HDInsight, consultez la rubrique Mettre à l’échelle les clusters HDInsight
Apache Tez est un moteur d’exécution représentant une alternative au moteur MapReduce. Tez est activé par défaut pour les clusters HDInsight basés sur Linux.
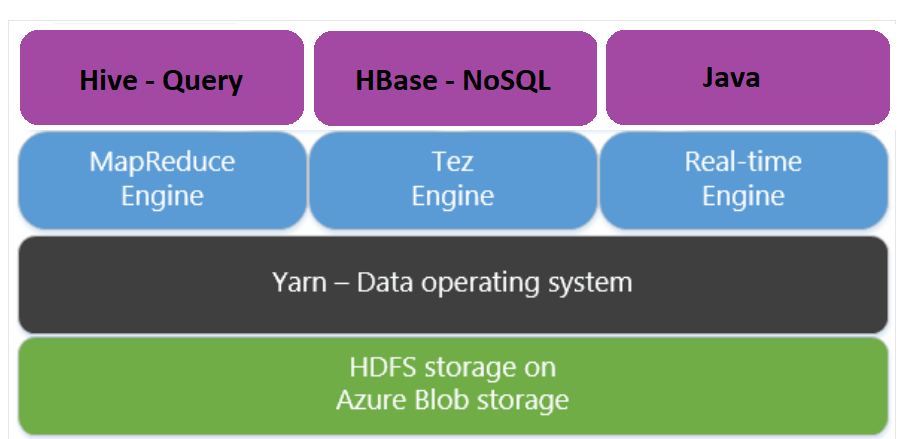
Tez est plus rapide pour les raisons suivantes :
- Il exécute un graphe orienté acyclique (DAG) en tant que tâche unique dans le moteur MapReduce. Le DAG requiert que chaque ensemble de mappeurs soit suivi par un ensemble de raccords de réduction. Cette exigence entraîne la préparation de plusieurs tâches MapReduce pour chaque requête Hive. Tez n’a pas de telles contraintes et peut traiter un graphique orienté acyclique en tant que tâche unique, ce qui réduit la surcharge de démarrage de tâche.
- Il évite les écritures inutiles. Plusieurs travaux sont utilisés pour traiter la même requête Hive dans le moteur MapReduce. La sortie de chaque travail MapReduce est écrite vers HDFS pour les données intermédiaires. Comme Tez réduit le nombre de tâches de chaque requête Hive, il est possible d’éviter de telles écritures inutiles.
- Il réduit les délais de démarrage. Tez peut réduire davantage le délai de démarrage en réduisant le nombre de mappeurs nécessaires au démarrage tout en améliorant l’optimisation tout au long du processus.
- Il réutilise les conteneurs. Dans la mesure du possible, Tez réutilise les conteneurs pour garantir que la latence de démarrage des conteneurs est réduite.
- Il utilise des techniques d’optimisation continue. Généralement, l’optimisation est effectuée lors de la compilation. Cependant, des informations supplémentaires sur les entrées sont disponibles pour améliorer l’optimisation durant le démarrage. Tez utilise des techniques d’optimisation continue qui permettent d’améliorer le plan lors de la phase de runtime.
Pour plus d’informations sur ces concepts, consultez Apache TEZ.
Vous pouvez activer n’importe quelle requête Hive pour Tez en faisant précéder la requête de la commande définie suivante :
set hive.execution.engine=tez;
Les opérations d’E/S constituent le principal goulot d’étranglement des performances pour l’exécution de requêtes Hive. Il est possible d’améliorer les performances en réduisant la quantité de données à lire. Par défaut, les requêtes Hive analysent l’ensemble des tables Hive. Cependant, ce comportement crée une surcharge inutile pour les requêtes analysant seulement une petite quantité de données (par exemple, les requêtes avec filtrage). Le partitionnement Hive permet aux requêtes Hive d’accéder uniquement à la quantité de données nécessaire dans les tables Hive.
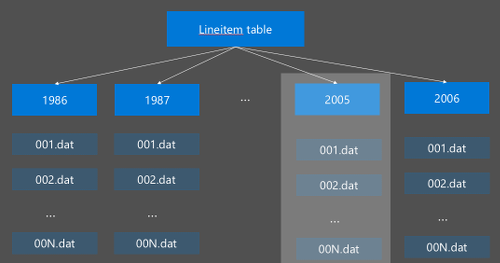
Le partitionnement Hive est implémenté en réorganisant les données brutes en nouveaux répertoires. Chaque partition a son propre répertoire de fichiers. L'utilisateur définit le partitionnement. Le schéma suivant illustre le partitionnement d’une table Hive selon la colonne Année. Un nouveau répertoire est créé pour chaque année.
Considérations relatives au partitionnement :
- Évitez les sous-partitionnements : les partitionnements appliqués à des colonnes contenant uniquement quelques valeurs peuvent entraîner quelques partitions. Par exemple, un partitionnement de genre crée uniquement deux partitions (masculin et féminin), ce qui réduit la latence de moitié seulement.
- Évitez les sur-partitionnements : l’autre extrême, le partitionnement appliqué à une colonne avec une valeur unique (par exemple, userid) entraîne de nombreuses partitions. Le sur-partitionnement communique un stress important au cluster namenode, car ce dernier doit gérer de grandes quantités de répertoires.
- Évitez le décalage de données : choisissez votre clé de partitionnement avec soin, pour que toutes les partitions soient de taille égale. Par exemple, le partitionnement sur la colonne État risque de fausser la répartition des données. Comme la Californie compte près de 30 fois plus d'habitants que le Vermont, la taille des partitions est potentiellement asymétrique et les performances peuvent considérablement varier.
Pour créer une table de partition, utilisez la clause Partitioned By :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Lorsque la table partitionnée est créée, vous pouvez créer un partitionnement statique ou dynamique.
Partitionnement statique signifie que vous avez déjà partagé des données dans des répertoires appropriés. Avec les partitions statiques, vous pouvez ajouter des partitions Hive manuellement en fonction de l’emplacement du répertoire. L’extrait de code suivant est un exemple.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Partitionnement dynamique signifie que vous voulez que Hive crée automatiquement des partitions pour vous. Étant donné que vous avez déjà créé la table de partitionnement à partir de la table intermédiaire, il vous suffit d’insérer des données dans la table partitionnée :
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Pour plus d’informations, consultez Tables partitionnées.
Hive prend en charge différents formats de fichier. Par exemple :
- Texte : format de fichier par défaut, qui fonctionne avec la plupart des scénarios.
- Avro : fonctionne bien avec les scénarios d’interopérabilité.
- ORC/Parquet : adapté pour les performances.
Le format ORC (Optimized Row Columnar) est un moyen très efficace pour stocker des données Hive. Par rapport aux autres formats, ORC présente les avantages suivants :
- prise en charge des types complexes, notamment les types DateTime, ainsi que les types complexes et semi-structurés.
- jusqu’à 70 % de compression.
- création d’index toutes les 10 000 lignes, ce qui permet d’ignorer des lignes.
- baisse significative de l’exécution du runtime.
Pour activer le format ORC, vous devez commencer par créer une table avec la clause Stored as ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Ensuite, vous devez insérer des données dans la table ORC à partir de la table de mise en lots. Par exemple :
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Vous trouverez plus d’informations sur le format ORC dans le manuel du langage Apache Hive.
La vectorisation permet à Hive de traiter un lot de 1024 lignes simultanément, au lieu d’une ligne à la fois. Cela signifie que les opérations simples sont effectuées plus rapidement, car elles requièrent moins d’exécution de code interne.
Pour activer la vectorisation, faites précéder vos requêtes Hive par le paramètre suivant :
set hive.vectorized.execution.enabled = true;
Pour plus d’informations, consultez la page Exécution de requêtes vectorisées.
Vous pouvez envisager plusieurs autres méthodes d’optimisation, par exemple :
- Création de compartiments Hive : cette technique permet de mettre en cluster ou de segmenter des jeux de données volumineux pour optimiser les performances des requêtes.
- Optimisation des jointures : une optimisation de la planification de l’exécution des requêtes Hive pour améliorer l’efficacité des jointures et réduire le besoin d’indicateurs utilisateur. Pour plus d’informations, consultez la page Optimisation des jointures.
- Augmentez les raccords de réduction.
Dans cet article, vous avez appris plusieurs méthodes d’optimisation courantes des requêtes. Pour en savoir plus, consultez les articles suivants :