Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Ce tutoriel vous montre comment collecter des statistiques sur vos conteneurs à l’aide de l’inventaire Stockage Blob Azure et Azure Databricks.
Dans ce tutoriel, vous allez apprendre à :
- Générer un rapport d’inventaire
- Créer un espace de travail et un notebook Azure Databricks
- Lire le fichier d’inventaire des objets blob
- Obtenir le nombre et la taille totale des objets blob, des instantanés et des versions
- Obtenir le nombre d’objets blob par type d’objet blob et type de contenu
Prérequis
Abonnement Azure : créer un compte gratuitement
Un compte de stockage Azure : créez un compte de stockage
Vérifiez que le rôle Contributeur aux données Blob du stockage est attribué à l’identité d’utilisateur.
Générer un rapport d’inventaire
Activez les rapports d’inventaire des objets blob à votre compte de stockage. Voir Activer les rapports d’inventaire d’objets blob de stockage Azure.
Utilisez les paramètres de configuration suivants :
| Paramètre | Valeur |
|---|---|
| Nom de la règle | blobinventory |
| Conteneur | <nom de votre conteneur> |
| Type d’objet à l’inventaire | Objet blob |
| Types d’objet blob | Objets blob de blocs, objets blob de pages et objets blob d’ajout |
| Sous-types | inclure des versions d’objets blob, inclure des instantanés, inclure des objets blob supprimés |
| Champs d’inventaire de blob | Tous |
| Fréquence d’inventaire | Quotidien |
| Format d'exportation | CSV |
Vous devrez peut-être attendre jusqu’à 24 heures après avoir activé les rapports d’inventaire pour que votre premier rapport soit généré.
Configurer Azure Databricks
Dans cette section, vous créerez un espace de travail, un cluster et un notebook Azure Databricks. Plus loin dans ce tutoriel, vous collerez des extraits de code dans des cellules de notebook, puis vous les exécuterez pour collecter des statistiques de conteneur.
Créer un espace de travail Azure Databricks. Consultez Créer un espace de travail Azure Databricks.
Créez un nouveau notebook. Consultez Création d’un notebook.
Choisissez Python comme langage par défaut du notebook.
Lire le fichier d’inventaire des objets blob
Copiez et collez le bloc de code suivant dans la première cellule, mais n’exécutez pas ce code pour l’instant.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')Dans ce bloc de code, remplacez les valeurs suivantes :
Remplacez la valeur d’espace réservé
<storage-account-name>par le nom de votre compte de stockage.Remplacez la valeur d’espace réservé
<storage-account-key>par le nom de votre compte de stockage.Remplacez la valeur de l’espace
<container-name>réservé par le conteneur qui contient les rapports d’inventaire.Remplacez l’espace
<blob-inventory-file-name>réservé par le nom complet du fichier d’inventaire (par exemple :2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv).Si votre compte a un espace de noms hiérarchique, définissez la
hierarchical_namespace_enabledvariable surTrue.
Appuyez sur le bouton Exécuter pour exécuter le code dans cette cellule.
Obtenir le nombre et taille des objets blob
Dans une nouvelle cellule, collez le code suivant :
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Appuyez sur le bouton Exécuter pour exécuter la cellule.
Le notebook affiche le nombre d’objets blob dans un conteneur et le nombre d’octets occupés par les objets blob dans le conteneur.

Obtenir le nombre et la taille des instantanés
Dans une nouvelle cellule, collez le code suivant :
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Appuyez sur le bouton Exécuter pour exécuter la cellule.
Le notebook affiche le nombre d’instantanés et le nombre total d’octets occupés par les instantanés d’objets blob.

Obtenir le nombre et la taille des versions
Dans une nouvelle cellule, collez le code suivant :
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Appuyez sur Maj+Entrée pour exécuter la cellule.
Le notebook affiche le nombre de versions d’objets blob et le nombre total d’octets occupés par les versions d’objets blob.

Obtenir le nombre d’objets blob par type d’objet blob
Dans une nouvelle cellule, collez le code suivant :
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))Appuyez sur Maj+Entrée pour exécuter la cellule.
Le notebook affiche le nombre de types d’objets blob par type.

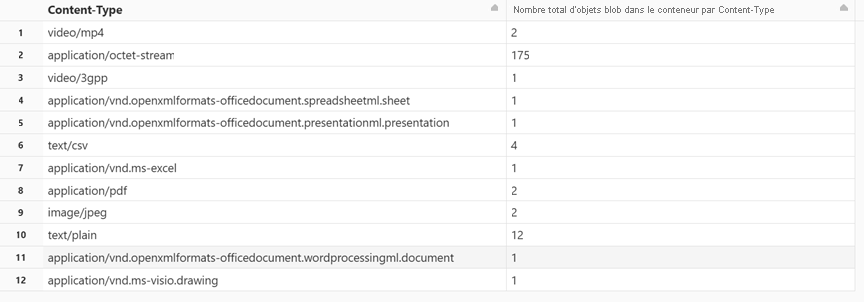
Obtenir le nombre d’objets blob par type de contenu
Dans une nouvelle cellule, collez le code suivant :
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))Appuyez sur Maj+Entrée pour exécuter la cellule.
Le notebook affiche le nombre d’objets blob associés à chaque type de contenu.
Arrêtez le cluster
Pour éviter toute facturation inutile, arrêtez votre ressource de calcul. Consultez Arrêter un calcul.
Étapes suivantes
Apprenez à utiliser Azure Synapse pour calculer le nombre et la taille totale des objets blob par conteneur. Consultez Calculer le nombre et la taille totale des blobs par conteneur à l’aide de l’inventaire de Stockage Azure
Découvrez comment générer et visualiser des statistiques qui décrivent des conteneurs et des objets blob. Consultez Tutoriel : Analyser les rapports d’inventaire d’objets blob
Découvrez les façons d’optimiser vos coûts en fonction de l’analyse de vos objets blob et conteneurs. Reportez-vous aux articles suivants :
Planifier et gérer les coûts du Stockage Blob Azure
Estimer le coût de l’archivage des données
Optimiser les coûts en gérant automatiquement le cycle de vie des données