Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel vous guide tout au long de l’utilisation d’un notebook Azure Databricks pour interroger des exemples de données stockés dans le catalogue Unity à l’aide de SQL, Python, Scala et R, puis visualiser les résultats de la requête dans le notebook.
Tip
Indiquez au code Genie (mode Agent) de le faire pour vous :
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
Spécifications
Pour effectuer les tâches décrites dans cet article, vous devez répondre aux exigences suivantes :
- Votre espace de travail doit avoir le catalogue Unity activé. Pour plus d’informations sur la prise en main du catalogue Unity, consultez Prise en main du catalogue Unity.
- Vous devez avoir l’autorisation d’utiliser une ressource de calcul existante ou d’en créer une. Consultez Calcul ou consultez votre administrateur Databricks.
Étape 1 : créer un notebook
Pour créer un bloc-notes dans votre espace de travail, cliquez sur ![]() dans la barre latérale, puis sur Bloc-notes. Un notebook vide s’ouvre dans l’espace de travail.
dans la barre latérale, puis sur Bloc-notes. Un notebook vide s’ouvre dans l’espace de travail.
Pour en savoir plus sur la création et la gestion de notebooks, consultez Gérer les notebooks Databricks.
Étape 2 : interroger une table
Interrogez la table samples.nyctaxi.trips dans Unity Catalog en utilisant le langage de votre choix. Ce tableau est l’un des exemples de jeux de données inclus dans le samples catalogue.
Copiez et collez le code suivant dans la nouvelle cellule de notebook vide. Ce code affiche les résultats de l’interrogation de la table
samples.nyctaxi.tripsdans Unity Catalog.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Langage de programmation Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Appuyez sur
Shift+Enterpour exécuter la cellule et passer à la cellule suivante.Les résultats de la requête s’affichent dans le notebook.
Étape 3 : afficher les données
Affichez le tarif moyen par distance du trajet, regroupés par le code postal de prise en charge.
En regard de l’onglet Tableau , cliquez + , puis cliquez sur Visualisation.
L'éditeur de visualisation est affiché.
Dans la liste déroulante Type de visualisation , vérifiez que la barre est sélectionnée.
Sélectionnez
fare_amountpour la colonne X.Sélectionnez
trip_distancepour la Colonne Y.Sélectionnez
Averagecomme type d’agrégation.Sélectionnez
pickup_zippour la colonne Regrouper par.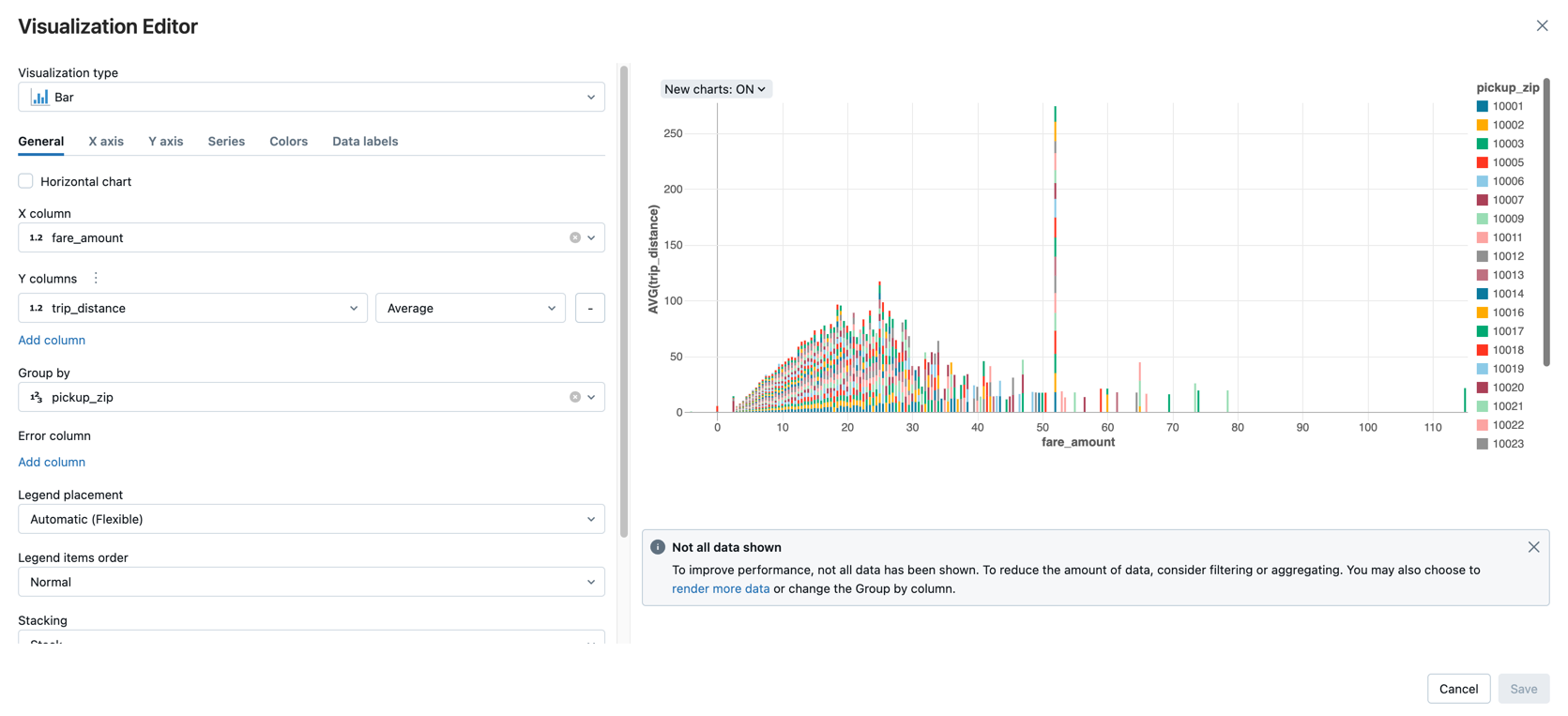
Cliquez sur Enregistrer.
Étapes suivantes
- Pour en savoir plus sur l’ajout de données d’un fichier CSV au catalogue Unity et la visualisation des données, consultez Tutoriel : Importer et visualiser des données CSV à partir d’un notebook.
- Pour savoir comment charger des données dans Databricks à l’aide d’Apache Spark, consultez Tutoriel : Charger et transformer des données à l’aide d’Apache Spark DataFrames.
- Pour en savoir plus sur l’ingestion de données dans Databricks, consultez connecteurs Standard dans Lakeflow Connect.
- Pour en savoir plus sur l’interrogation de données avec Databricks, consultez Données de requête.
- Pour en savoir plus sur les visualisations, consultez la section Visualisations dans les notebooks Databricks et l’éditeur SQL.
- Pour en savoir plus sur les techniques d’analyse exploratoire des données ( EDA), consultez Tutoriel : Techniques EDA à l’aide de notebooks Databricks.