Intégration et livraison continues pour un espace de travail Azure Synapse Analytics
L’intégration continue (CI) est le processus d’automatisation de création et de test du code chaque fois qu’un membre de l’équipe valide une modification apportée à la gestion de version. La livraison continue (CD) est le processus de création, de test, de configuration et de déploiement de plusieurs environnements de test ou intermédiaires vers un environnement de production.
Dans un espace de travail Azure Synapse Analytics, la CI/CD déplace toutes les entités d’un environnement (développement, test, production) vers un autre environnement. La promotion de votre espace de travail vers un autre espace de travail est un processus en deux parties. Tout d’abord, utilisez un modèle Azure Resource Manager (modèle ARM) pour créer ou mettre à jour des ressources d’espace de travail (pools et espace de travail). Ensuite, migrez les artefacts tels que les scripts et notebooks SQL, les définitions de tâche Spark, les pipelines, les jeux de données et autres artefacts en utilisant les outils de déploiement d’espace de travail Synapse dans Azure DevOps ou sur GitHub.
Cet article décrit comment utiliser un pipeline de mise en production Azure DevOps et GitHub Actions pour automatiser le déploiement d’un espace de travail Azure Synapse dans plusieurs environnements.
Prérequis
Pour automatiser le déploiement d’un espace de travail Azure Synapse dans plusieurs environnements, les conditions préalables et les configurations suivantes doivent être en place.
Azure DevOps
- Préparez un projet Azure DevOps pour l’exécution du pipeline de mise en production.
- Accordez à tous les utilisateurs qui enregistreront le code un accès De base au niveau de l’organisation, afin qu’ils puissent voir le référentiel.
- Accordez l’autorisation Propriétaire au référentiel Azure Synapse.
- Assurez-vous d’avoir créé un agent de machine virtuelle Azure DevOps auto-hébergé ou d’utiliser un agent hébergé Azure DevOps.
- Accordez les autorisations permettant de créer une connexion au service Azure Resource Manager pour le groupe de ressources.
- Un administrateur Microsoft Entra doit installer l’extension de l’agent de déploiement d’espace de travail Synapse Azure DevOps dans l’organisation Azure DevOps.
- Créez ou nommez un compte de service pour l’exécution du pipeline. Vous pouvez utiliser un jeton d’accès personnel au lieu d’un compte de service, mais vos pipelines ne fonctionneront pas une fois le compte d’utilisateur supprimé.
GitHub
- Créez un référentiel GitHub qui contient les artefacts de l’espace de travail Azure Synapse et le modèle d’espace de travail.
- Assurez-vous d’avoir créé un exécuteur auto-hébergé, ou utilisez un exécuteur hébergé par GitHub.
Microsoft Entra ID
- Si vous utilisez un principal de service, dans Microsoft Entra ID, créez un principal de service à utiliser pour le déploiement.
- Si vous utilisez une identité managée, activez l’identité managée affectée par le système sur votre machine virtuelle dans Azure en tant qu’agent ou exécuteur, puis ajoutez-la à Azure Synapse Studio en tant qu’administrateur Synapse.
- Utilisez le rôle d’administrateur Microsoft Entra pour effectuer ces actions.
Azure Synapse Analytics
Notes
Vous pouvez automatiser et déployer ces conditions préalables en utilisant le même pipeline, un modèle ARM ou Azure CLI, mais ces processus ne sont pas décrits dans cet article.
L’espace de travail « source » utilisé pour le développement doit être configuré avec un référentiel Git dans Azure Synapse Studio. Pour plus d’informations, consultez Contrôle de code source dans Azure Synapse Studio.
Configurez un espace de travail vierge pour le déploiement :
- Créez un nouvel espace de travail Azure Synapse.
- Accordez au principal du service les autorisations suivantes pour le nouvel espace de travail Synapse :
- Microsoft.Synapse/workspaces/integrationruntimes/write
- Microsoft.Synapse/workspaces/operationResults/read
- Microsoft.Synapse/workspaces/read
- Dans l’espace de travail, ne configurez pas la connexion au référentiel Git.
- Dans l’espace de travail Azure Synapse, accédez à Studio>Gérer>Contrôle d’accès. 4. Dans l’espace de travail Azure Synapse, accédez à Studio > Gérer > Contrôle d’accès. Affectez le « Serveur de publication d’artefact Synapse » au principal de service. Si le pipeline de déploiement doit déployer des points de terminaison privés gérés, assignez plutôt « Administrateur Synapse ».
- Lorsque vous utilisez des services liés dont les informations de connexion sont stockées dans Azure Key Vault, il est recommandé de conserver des coffres de clés distincts pour les différents environnements. Vous pouvez également configurer des niveaux d’autorisation distincts pour chaque coffre de clés. Par exemple, vous ne souhaitez peut-être pas que les membres de votre équipe disposent d’autorisations sur les secrets de production. Si vous suivez cette approche, nous vous recommandons de conserver les mêmes noms de secrets dans toutes les phases. Si vous conservez les mêmes noms secrets, vous n’avez pas besoin de paramétrer chaque chaîne de connexion dans les environnements d’intégration et de livraison continues, car la seule chose qui change est le nom du coffre de clés, qui est un paramètre distinct.
Autres conditions préalables
- Les pools Spark et les runtimes d’intégration auto-hébergés ne sont pas créés dans une tâche de déploiement de l’espace de travail. Si vous avez un service lié qui utilise un runtime d’intégration auto-hébergé, créez manuellement le runtime dans le nouvel espace de travail.
- Si les éléments de l’espace de travail de développement sont attachés à des pools spécifiques, assurez-vous de créer ou de paramétrer les mêmes noms pour les pools de l’espace de travail cible dans le fichier de paramètres.
- Si vos pools SQL approvisionnés sont suspendus lorsque vous tentez d’effectuer le déploiement, ce dernier peut échouer.
Pour plus d’informations, consultez CI/CD dans Azure Synapse Analytics, partie 4 : Le pipeline de mise en production.
Créer un pipeline de mise en production dans Azure DevOps
Dans cette section, vous apprendrez à déployer un espace de travail Azure Synapse dans Azure DevOps.
Dans Azure DevOps, ouvrez le projet que vous avez créé pour la mise en production.
Dans le menu de gauche, sélectionnez Pipelines>Mises en production.
Sélectionnez Nouveau pipeline. Si vous avez des pipelines existants, sélectionnez Nouveau>Nouveau pipeline de mise en version.
Sélectionnez le modèle Tâche vide.
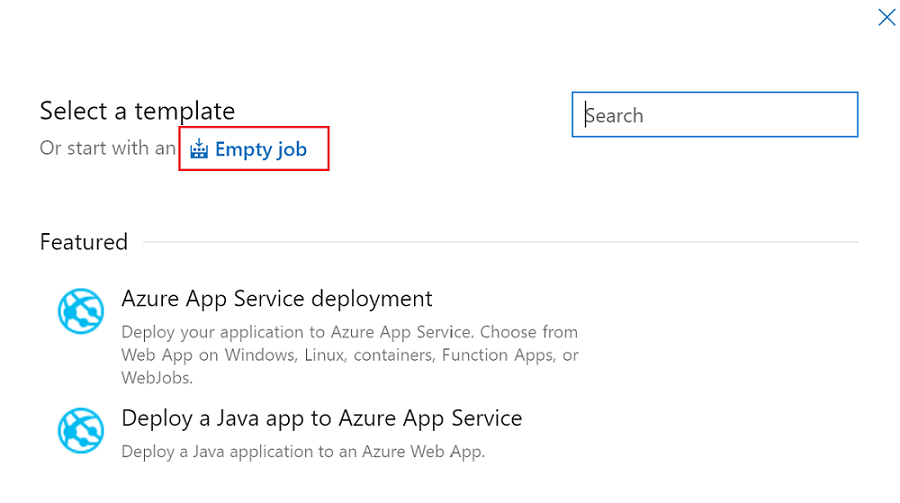
Dans Nom de la phase, entrez le nom de votre environnement.
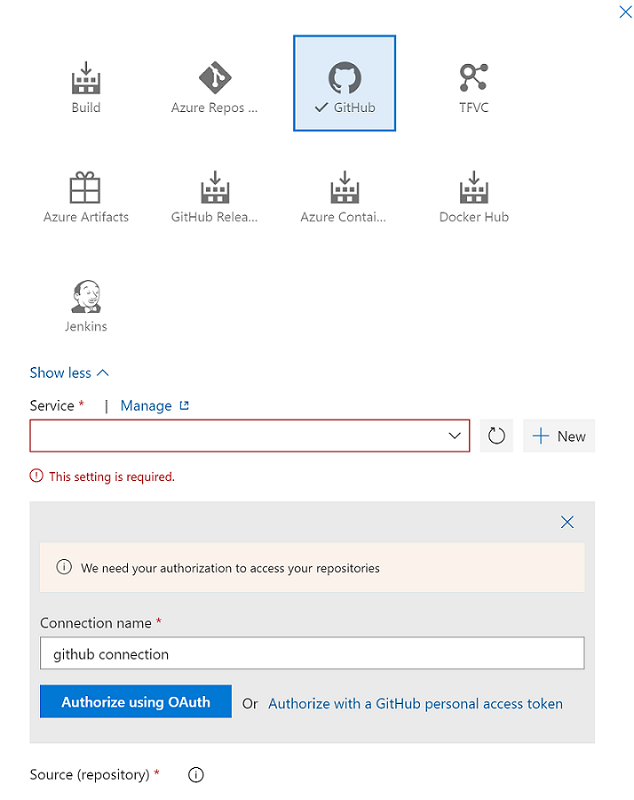
Sélectionnez Ajouter un artefact, puis choisissez le référentiel Git qui est configuré avec Azure Synapse Studio dans votre environnement de développement. Sélectionnez le référentiel Git dans lequel vous gérez vos pools et votre modèle ARM d’espace de travail. Si vous utilisez GitHub comme source, créez une connexion de service pour votre compte GitHub et les référentiels d’extraction. Pour plus d’informations, consultez Connexions de service.
Sélectionnez la branche du modèle ARM de ressource. Pour Version par défaut, sélectionnez La dernière de la branche par défaut.
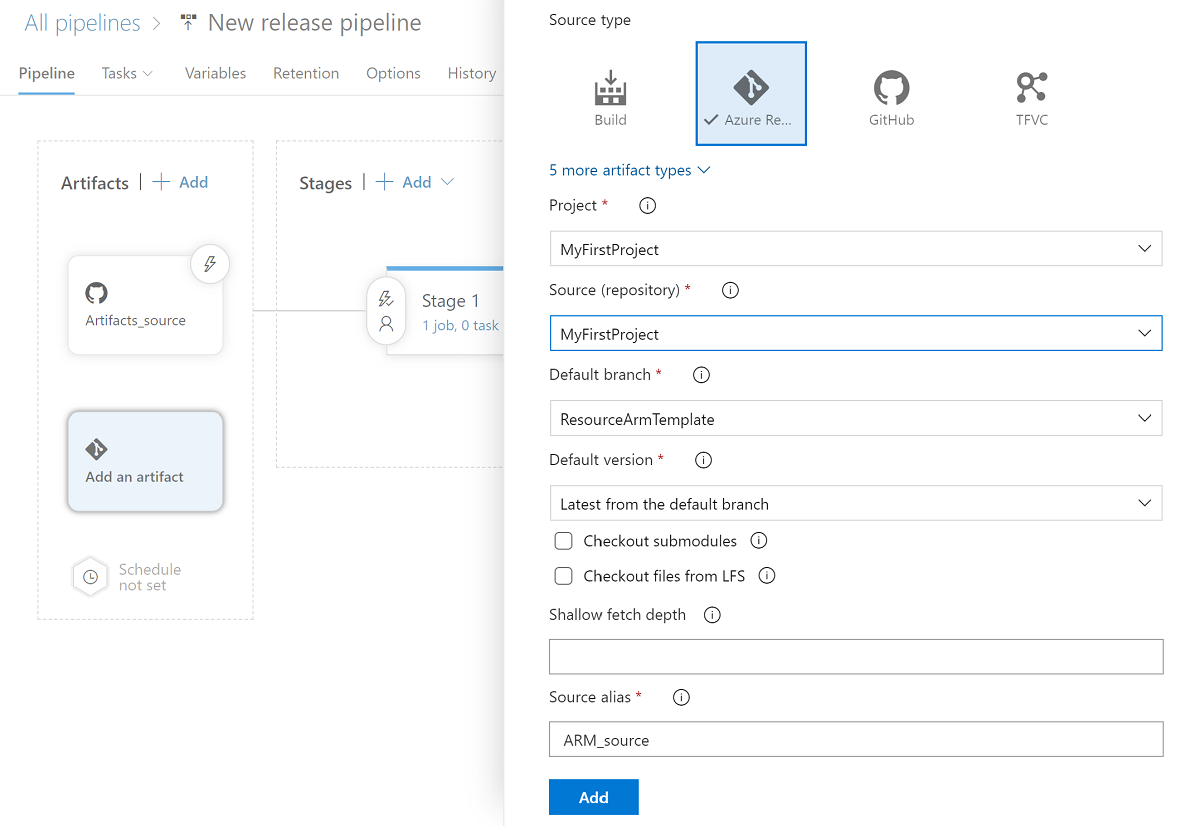
Pour la branche par défaut des artefacts, sélectionnez la branche de publication du dépôt ou d’autres branches de non-publication comprenant des artefacts Synapse. Par défaut, la branche de publication est
workspace_publish. Pour Version par défaut, sélectionnez La dernière de la branche par défaut.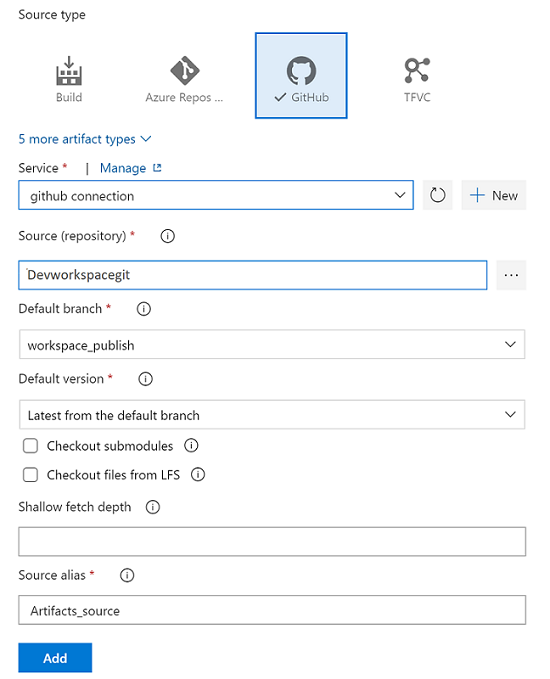

Configurer une tâche intermédiaire pour un modèle ARM afin de créer et mettre à jour une ressource
Si vous avez un modèle ARM qui déploie une ressource, telle qu’un espace de travail Azure Synapse, un pool Spark et SQL ou un coffre de clés, ajoutez une tâche de déploiement Azure Resource Manager pour créer ou mettre à jour ces ressources :
Dans la vue des phases, sélectionnez Afficher les tâches de phase.
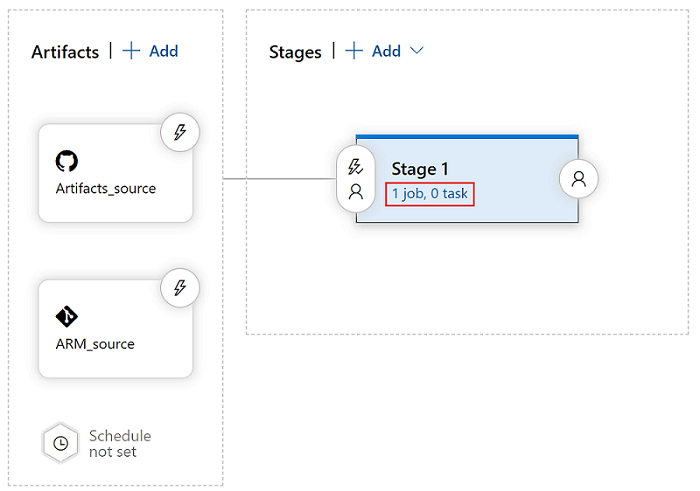
Créer une tâche. Recherchez Déploiement de modèles ARM, puis sélectionnez Ajouter.
Dans l’onglet Tâches du déploiement, sélectionnez l’abonnement, le groupe de ressources et l’emplacement de l’espace de travail. Fournissez les informations d’identification si nécessaire.
Pour Action, sélectionnez Créer ou mettre à jour un groupe de ressources.
Pour Modèle, sélectionnez les points de suspension ( … ). Accédez au modèle ARM de l’espace de travail.
Pour Paramètres du modèle, sélectionnez ... et choisissez le fichier de paramètres.
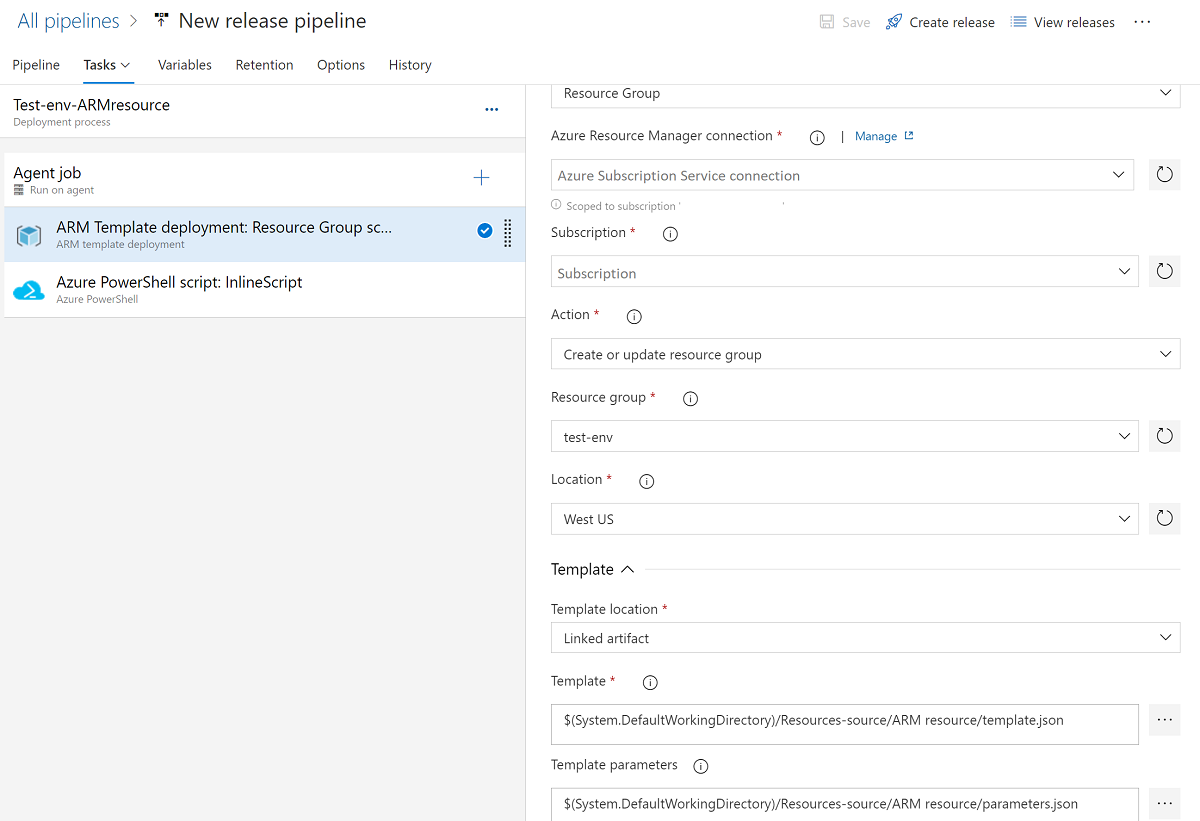
Pour Remplacer les paramètres du modèle, sélectionnez le bouton … , puis entrez les valeurs de paramètres que vous souhaitez utiliser pour l’espace de travail.
Pour Mode de déploiement, sélectionnez Incrémentiel.
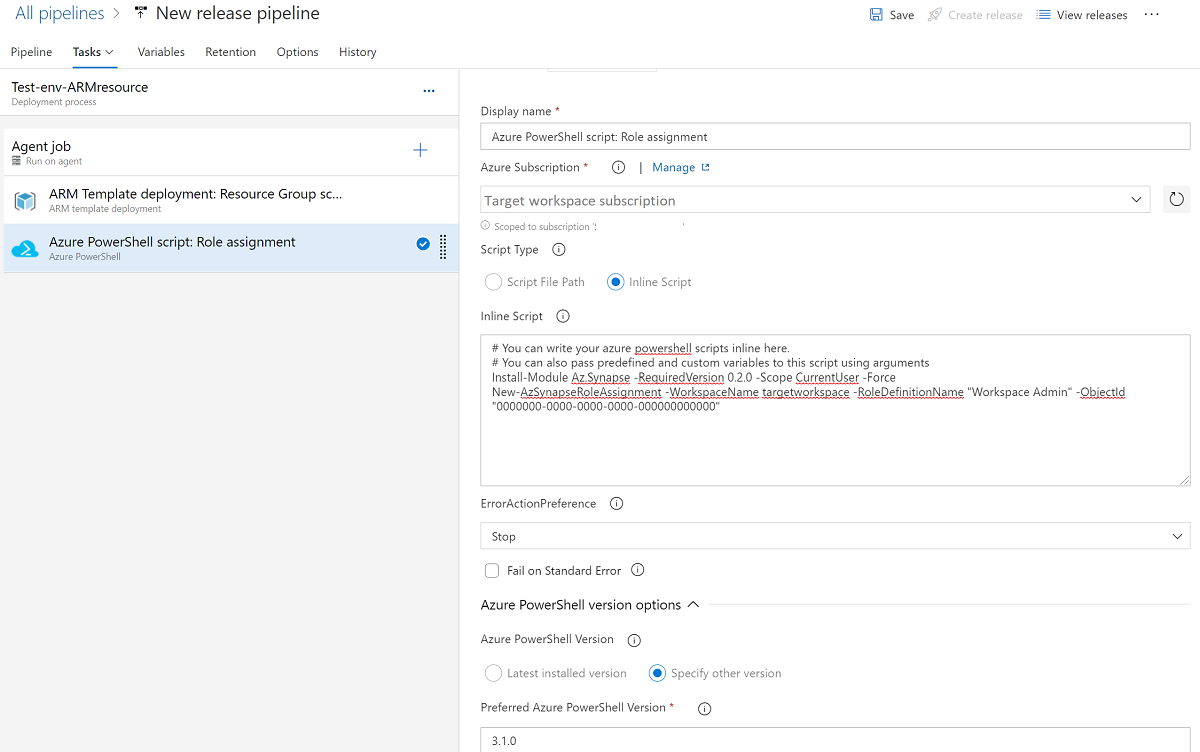
(Facultatif) Ajoutez Azure PowerShell pour l’octroi et la mise à jour de l’attribution de rôle de l’espace de travail. Si vous utilisez un pipeline de mise en production pour créer un espace de travail Azure Synapse, le principal de service du pipeline est ajouté comme administrateur de l’espace de travail par défaut. Vous pouvez exécuter PowerShell pour accorder à d’autres comptes l’accès à l’espace de travail.


Avertissement
En mode de déploiement complet, les ressources du groupe de ressources qui ne sont pas spécifiées dans le nouveau modèle ARM sont supprimées. Pour plus d’informations, consultez Modes de déploiement Azure Resource Manager.
Configurer une tâche intermédiaire pour le déploiement d’artefacts Azure Synapse
Utilisez l’extension de déploiement de l’espace de travail Synapse pour déployer d’autres éléments dans votre espace de travail Azure Synapse. Voici les éléments que vous pouvez déployer : jeux de données, scripts SQL et notebooks, définitions de travaux Spark, runtime d’intégration, flux de données, informations d’identification et autres artefacts dans l’espace de travail.
Installer et ajouter une extension de déploiement
Recherchez et obtenez l’extension à partir de Visual Studio Marketplace.
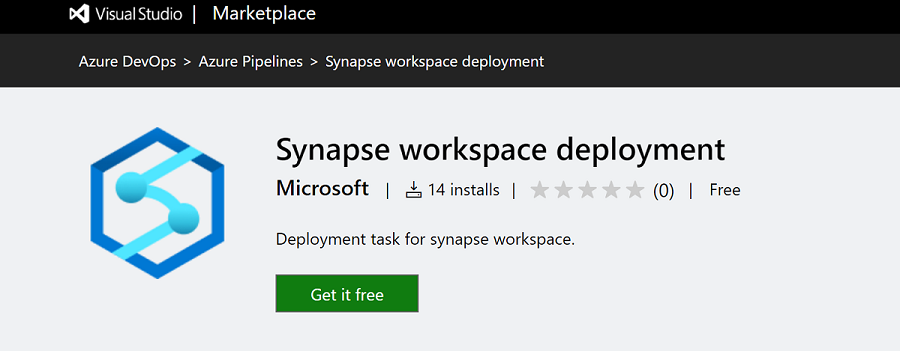
Sélectionnez l’organisation Azure DevOps dans laquelle vous souhaitez installer l’extension.
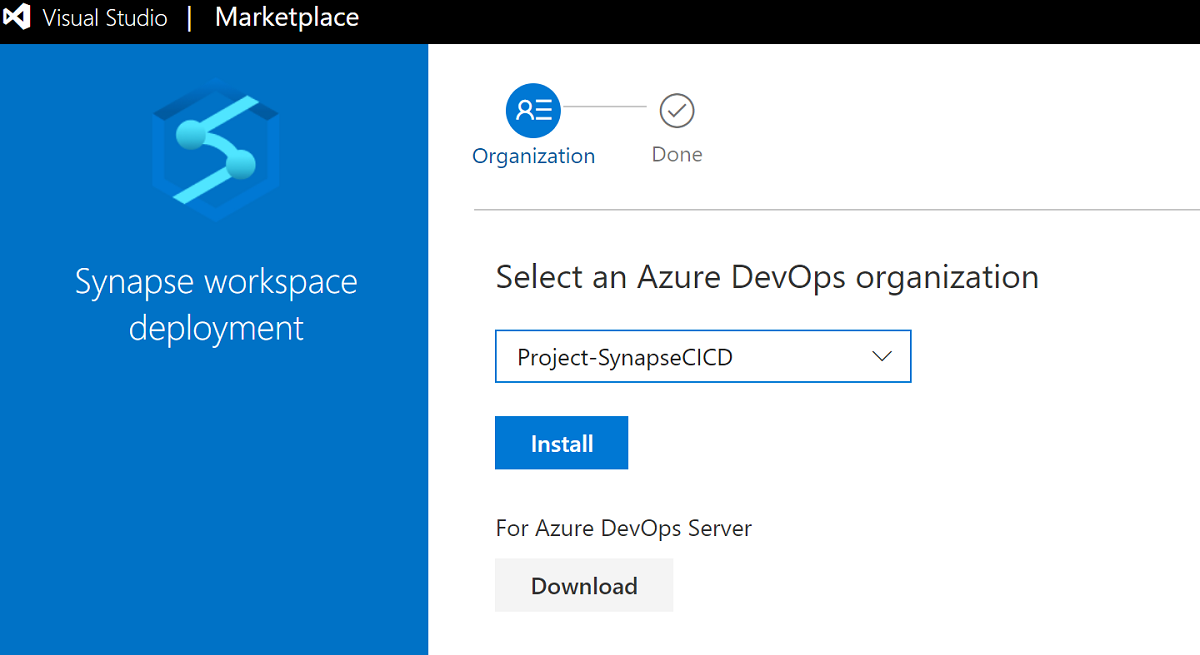
Assurez-vous que le principal de service du pipeline Azure DevOps a reçu l’autorisation Abonnement et qu’il est désigné comme administrateur de l’espace de travail Synapse pour l’espace de travail.
Pour créer une nouvelle tâche, recherchez Déploiement de l’espace de travail Synapse, puis sélectionnez Ajouter.

Configurer la tâche de déploiement
La tâche de déploiement prend en charge 3 types d’opérations : valider uniquement, déployer et valider et déployer.
Notes
Cette extension de déploiement d’espace de travail n’est pas compatible avec les versions antérieures. Vérifiez que la version la plus récente est installée et utilisée. Vous pouvez lire la note de publication dans la vue d’ensemble d’Azure DevOps et la dernière version dans l’action GitHub.
Valider consiste à valider les artefacts Synapse dans la branche de non-publication avec la tâche et à générer le modèle d’espace de travail et le fichier de modèle de paramètre. L’opération de validation fonctionne uniquement dans le pipeline YAML. L’exemple de fichier YAML est le suivant :
pool:
vmImage: ubuntu-latest
resources:
repositories:
- repository: <repository name>
type: git
name: <name>
ref: <user/collaboration branch>
steps:
- checkout: <name>
- task: Synapse workspace deployment@2
continueOnError: true
inputs:
operation: 'validate'
ArtifactsFolder: '$(System.DefaultWorkingDirectory)/ArtifactFolder'
TargetWorkspaceName: '<target workspace name>'
Valider et déployer Permet de déployer directement l’espace de travail à partir d’une branche de non-publication avec le dossier racine de l’artefact.
Notes
La tâche de déploiement doit télécharger les fichiers JS de dépendance à partir de ce point de terminaison web.azuresynapse.net lorsque le type d’opération est sélectionné comme Valider ou Valider et déployer. Vérifiez que le point de terminaison web.azuresynapse.net est autorisé si les stratégies réseau sont activées sur la machine virtuelle.
L’opération de validation et de déploiement fonctionne à la fois dans le pipeline classique et YAML. L’exemple de fichier YAML est le suivant :
pool:
vmImage: ubuntu-latest
resources:
repositories:
- repository: <repository name>
type: git
name: <name>
ref: <user/collaboration branch>
steps:
- checkout: <name>
- task: Synapse workspace deployment@2
continueOnError: true
inputs:
operation: 'validateDeploy'
ArtifactsFolder: '$(System.DefaultWorkingDirectory)/ArtifactFolder'
TargetWorkspaceName: 'target workspace name'
azureSubscription: 'target Azure resource manager connection name'
ResourceGroupName: 'target workspace resource group'
DeleteArtifactsNotInTemplate: true
OverrideArmParameters: >
-key1 value1
-key2 value2
Déployer Les entrées de l’opération de déploiement incluent le modèle d’espace de travail Synapse et le modèle de paramètre, qui peuvent être créés après la publication dans la branche de publication de l’espace de travail ou après la validation. Identique à la version 1.x.
Vous pouvez choisir les types d’opérations en fonction du cas d’usage. Ce qui suit est un exemple de déploiement.
Dans la tâche, sélectionnez Déployer comme type d’opération.
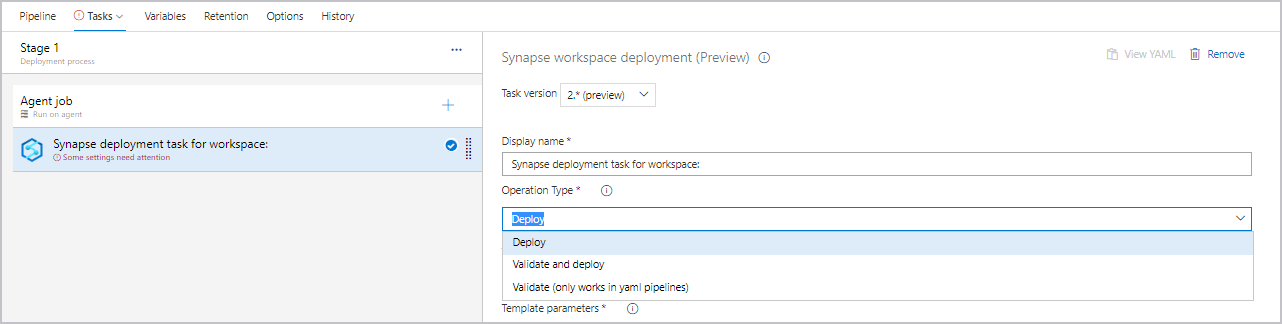
Dans la tâche, à côté de Modèle, sélectionnez ... pour choisir le fichier de modèle.
À côté de Paramètres du modèle, sélectionnez ... pour choisir le fichier de paramètres.
Sélectionnez une connexion, un groupe de ressources et un nom pour l’espace de travail.
À coté de Remplacer les paramètres du modèle, sélectionnez .... Entrez les valeurs de paramètre que vous souhaitez utiliser pour l’espace de travail, notamment les chaînes de connexion et les clés de compte qui sont utilisées dans vos services liés. Pour plus d’informations, consultez l’article CI/CD dans Azure Synapse Analytics.
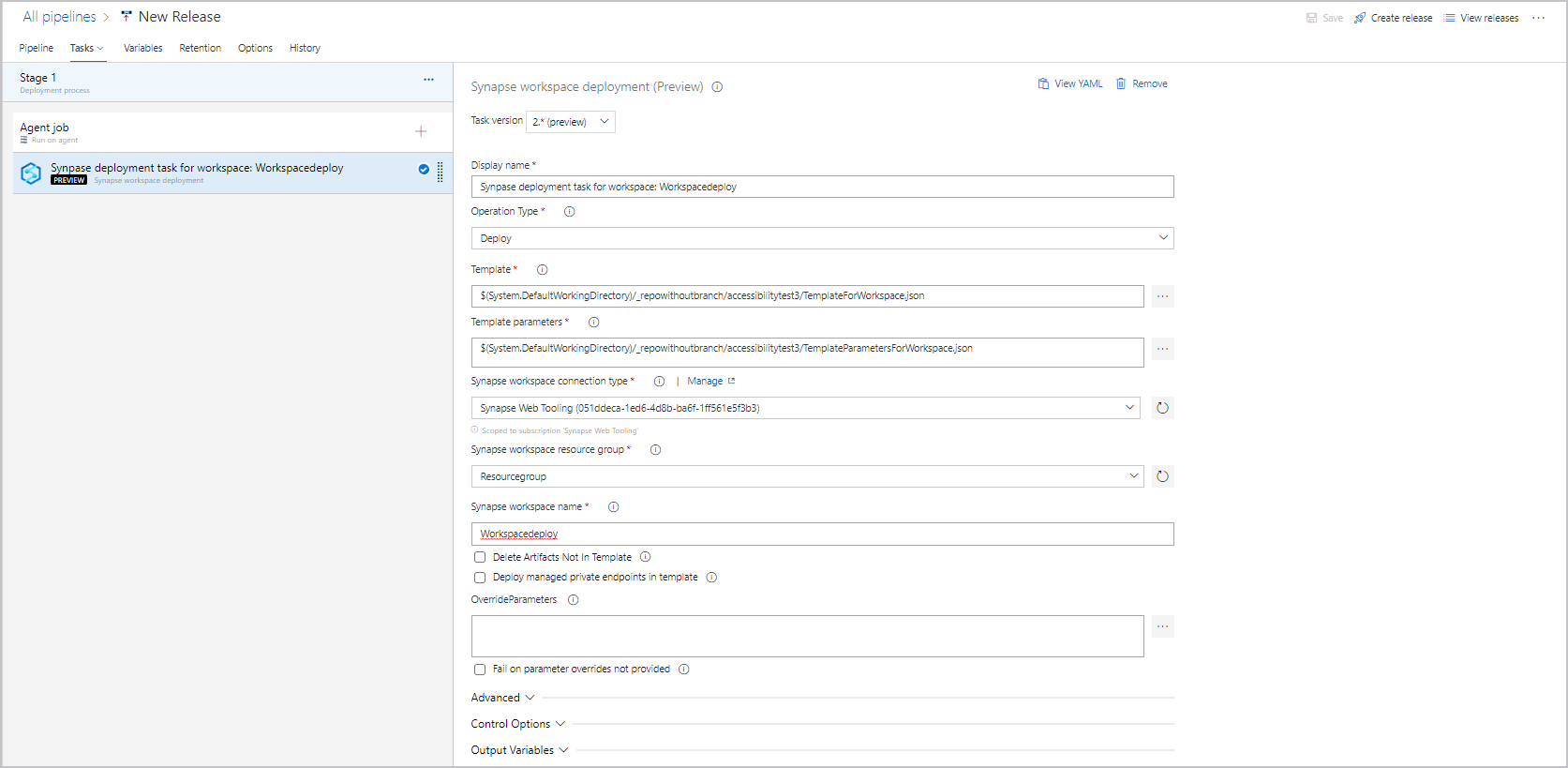
Le déploiement du point de terminaison privé managé est pris en charge uniquement dans la version 2.x. Veillez à sélectionner la bonne version et cochez la case Déployer les points de terminaison privés managés dans le modèle.
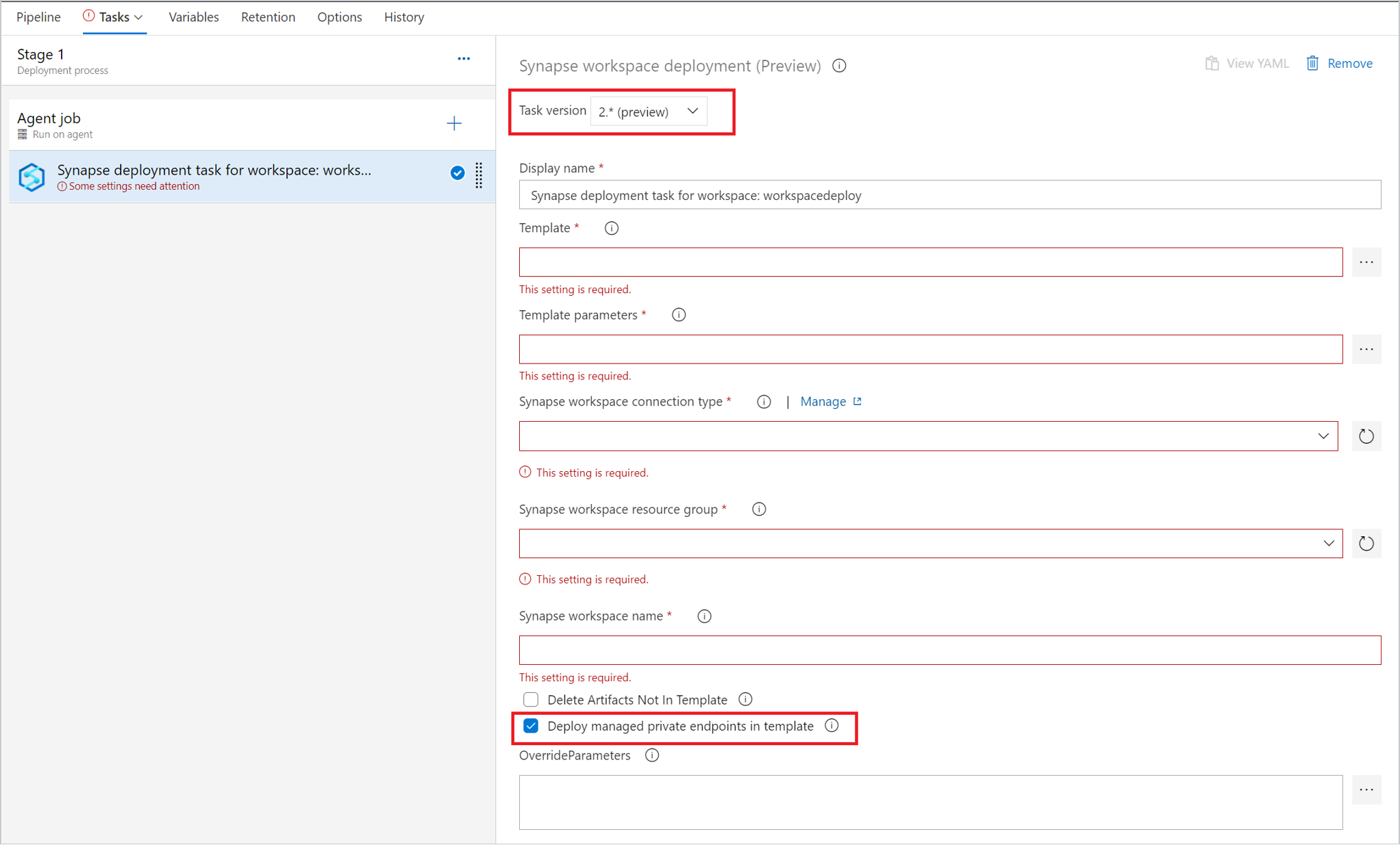
Pour gérer les déclencheurs, vous pouvez utiliser le bouton bascule pour arrêter les déclencheurs avant le déploiement. Vous pouvez également ajouter une tâche pour redémarrer les déclencheurs après la tâche de déploiement.
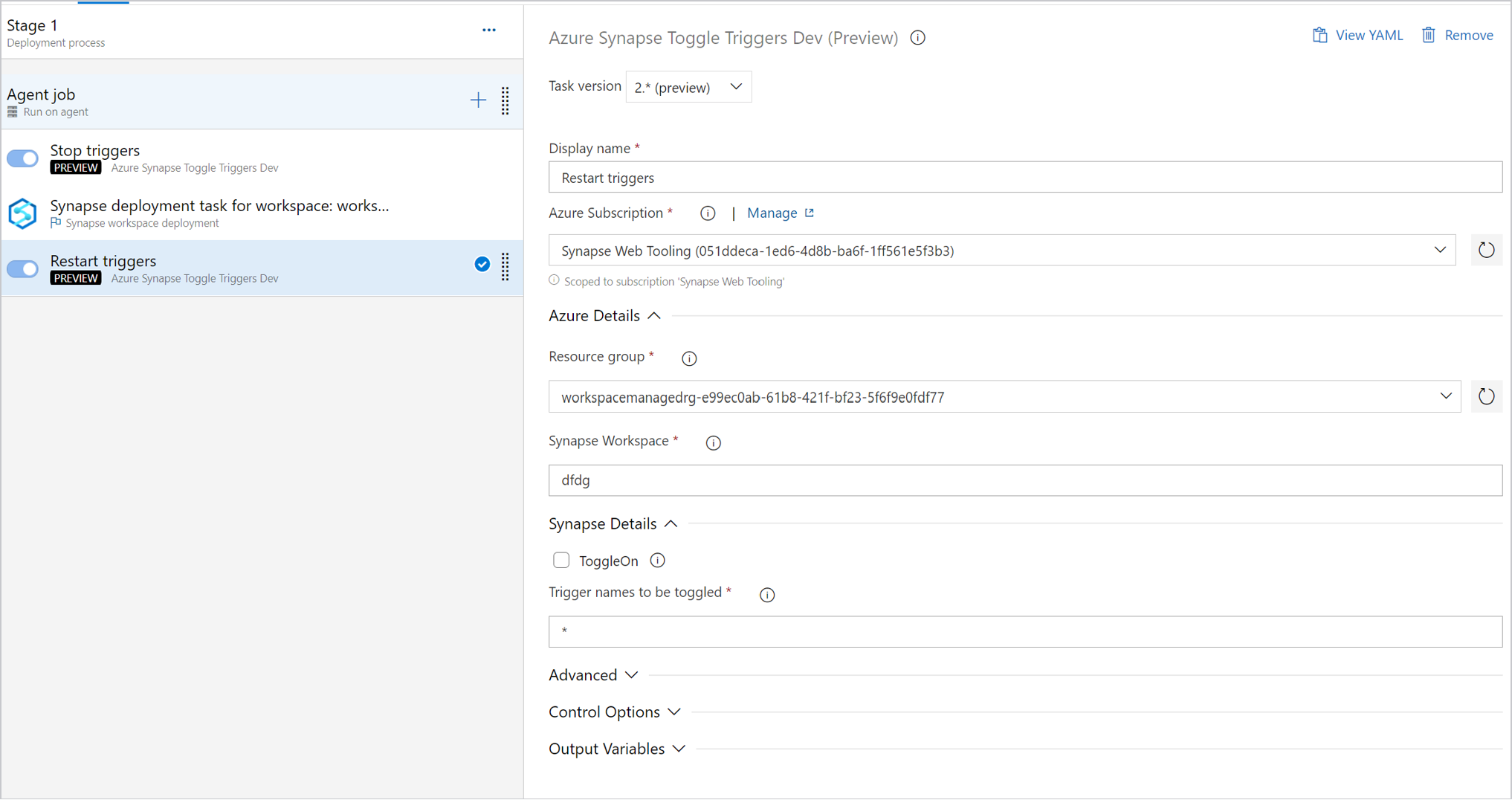


Important
Dans les scénarios de CI/CD, le type de runtime d’intégration doit être le même dans les différents environnements. Par exemple, si vous avez un runtime d’intégration auto-hébergé dans l’environnement de développement, le même runtime d’intégration doit être auto-hébergé dans les autres environnements, tels que les environnements de test et de production. De même, si vous partagez des runtimes d’intégration entre plusieurs phases, les runtimes d’intégration doivent être liés et auto-hébergés dans tous les environnements, tels que les environnements de développement, de test et de production.
Créer une mise en production pour le déploiement
Après avoir enregistré toutes les modifications, vous pouvez sélectionner Créer une mise en production pour créer manuellement une mise en production. Pour savoir comment automatiser la création d’une mise en production, consultez les déclencheurs de mise en production Azure DevOps.

Configurer une mise en production dans GitHub Actions
Dans cette section, vous apprendrez à créer des workflows GitHub en utilisant GitHub Actions pour le déploiement d’un espace de travail Azure Synapse.
Vous pouvez utiliser le modèle GitHub Actions pour Azure Resource Manager pour automatiser le déploiement d’un modèle ARM sur Azure pour l’espace de travail et les pools de calcul.
Fichier de workflow
Définissez un workflow GitHub Actions dans un fichier YAML (.yml) sous le chemin /.github/workflows/ de votre référentiel. La définition contient les étapes et les paramètres qui composent le workflow.
Le fichier .yml comporte deux sections :
| Section | Tâches |
|---|---|
| Authentification | 1. Définissez un principal de service. 2. Créez un secret GitHub. |
| Déployer | Déployez les artefacts d’espace de travail. |
Configurer des secrets GitHub Actions
Les secrets GitHub Actions sont des variables d’environnement qui sont chiffrées. Toute personne disposant d’une autorisation Collaborateur sur ce référentiel peut utiliser ces secrets pour interagir avec Actions dans le référentiel.
Dans le référentiel GitHub, sélectionnez l’onglet Paramètres, puis sélectionnez Secrets>Nouveau secret de référentiel.
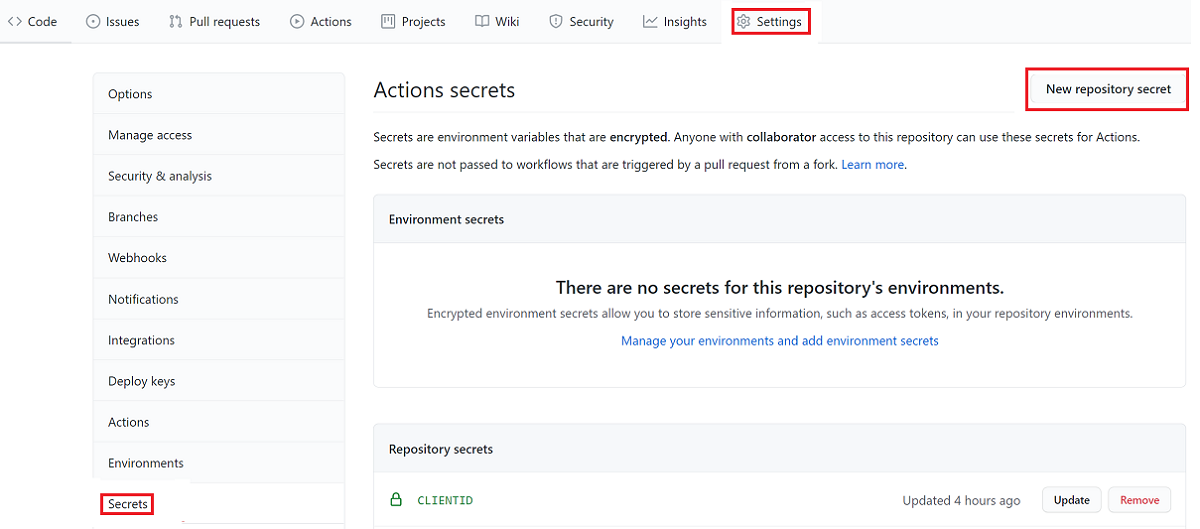
Ajoutez un nouveau secret pour l’ID client, et ajoutez une nouvelle clé secrète client si vous utilisez le principal de service pour le déploiement. Vous pouvez également choisir d’enregistrer l’ID d’abonnement et l’ID de locataire en tant que secrets.

Ajouter votre workflow
Dans votre référentiel GitHub, accédez à Actions.
Sélectionnez Configurer vous-même un workflow.
Dans le fichier de workflow, supprimez tout ce qui se trouve après la section
on:. Par exemple, votre workflow restant pourrait ressembler à cet exemple :name: CI on: push: branches: [ master ] pull_request: branches: [ master ]Renommez votre workflow. Dans l’onglet Marketplace, recherchez l’action de déploiement de l’espace de travail Synapse, puis ajoutez l’action.

Définissez les valeurs requises et le modèle d’espace de travail :
name: workspace deployment on: push: branches: [ publish_branch ] jobs: release: # You also can use the self-hosted runners. runs-on: windows-latest steps: # Checks out your repository under $GITHUB_WORKSPACE, so your job can access it. - uses: actions/checkout@v2 - uses: azure/synapse-workspace-deployment@release-1.0 with: TargetWorkspaceName: 'target workspace name' TemplateFile: './path of the TemplateForWorkspace.json' ParametersFile: './path of the TemplateParametersForWorkspace.json' OverrideArmParameters: './path of the parameters.yaml' environment: 'Azure Public' resourceGroup: 'target workspace resource group' clientId: ${{secrets.CLIENTID}} clientSecret: ${{secrets.CLIENTSECRET}} subscriptionId: 'subscriptionId of the target workspace' tenantId: 'tenantId' DeleteArtifactsNotInTemplate: 'true' managedIdentity: 'False'Vous êtes prêt à valider vos modifications. Sélectionnez Start commit (Démarrer la validation), entrez le titre, puis ajoutez une description (facultatif). Ensuite, sélectionnez Commit new file (Valider le nouveau fichier).

Le fichier apparaît dans le dossier .github/workflows de votre référentiel.
Notes
L’identité managée est pris en charge uniquement avec les machines virtuelles auto-hébergées dans Azure. Veillez à définir l’exécuteur sur auto-hébergé. Activez l’identité managée affectée par le système pour votre machine virtuelle, puis ajoutez-la à Azure Synapse Studio en tant qu’administrateur Synapse.


Vérifier votre déploiement
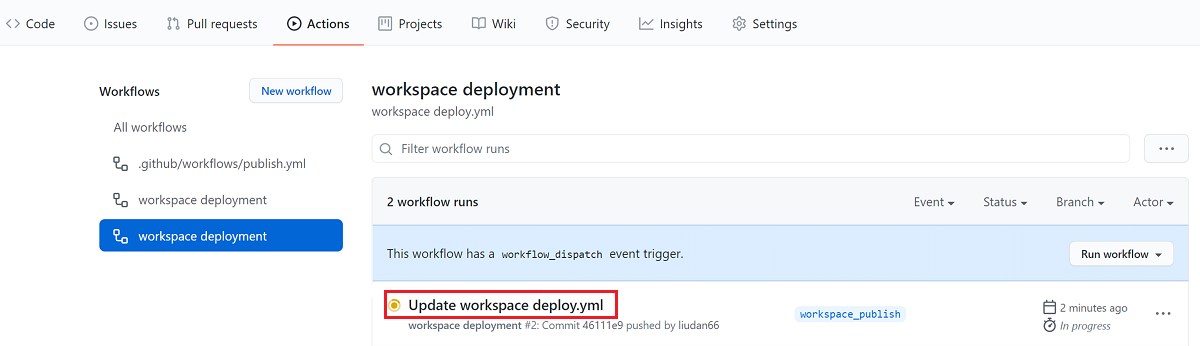
Dans votre référentiel GitHub, accédez à Actions.
Pour voir les journaux détaillés de l’exécution de votre workflow, ouvrez le premier résultat :

Créer des paramètres personnalisés dans le modèle d’espace de travail
Si vous utilisez la CI/CD automatisée et que vous souhaitez modifier certaines propriétés pendant le déploiement, mais que ces propriétés ne sont pas paramétrisées par défaut, vous pouvez remplacer le modèle de paramètres par défaut.
Pour remplacer le modèle de paramètres par défaut, créez un modèle de paramètres personnalisé nommé template-parameters-definition.json dans le dossier racine de votre branche Git. Vous devez utiliser ce nom de fichier exact. Quand l’espace de travail Azure Synapse publie à partir de la branche de collaboration ou que la tâche de déploiement valide les artefacts dans d’autres branches, il lit ce fichier et utilise sa configuration pour générer les paramètres. Si l’espace de travail Azure Synapse ne trouve pas ce fichier, il utilise le modèle de paramètres par défaut.
Syntaxe de paramètre personnalisé
Vous pouvez utiliser les instructions suivantes pour créer un fichier de paramètres personnalisés :
- Entrez le chemin d’accès de propriété sous le type d’entité correspondant.
- Définir un nom de propriété sur
*indique que vous souhaitez paramétrer toutes les propriétés sous la propriété en question (uniquement jusqu’au premier niveau, pas de manière récursive). Vous pouvez définir des exceptions à cette configuration. - Définir la valeur d’une propriété sous forme de chaîne indique que vous souhaitez paramétrer la propriété. Utilisez le format
<action>:<name>:<stype>.<action>peut être l’un des caractères suivants :=permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre.-permet de ne pas conserver la valeur par défaut pour le paramètre.|est un cas particulier pour les secrets Azure Key Vault pour les chaînes de connexion ou les clés.
<name>correspond au nom du paramètre. S’il est vide, il prend le nom du Si la valeur commence par un caractère-, le nom est abrégé. Par exemple,AzureStorage1_properties_typeProperties_connectionStringserait abrégé enAzureStorage1_connectionString.<stype>correspond au type de paramètre. Si<stype>est vide, le type par défaut eststring. Valeurs prises en charge :string,securestring,int,bool,object,secureobjectetarray.
- La spécification d’un tableau dans le fichier indique que la propriété correspondante dans le modèle est un tableau. Azure Synapse itère au sein de tous les objets du tableau à l’aide de la définition spécifiée. Le second objet, une chaîne, correspond alors au nom de la propriété et sert de nom au paramètre pour chaque itération.
- Une définition ne peut pas être spécifique à une instance de ressource. Toute définition s’applique à toutes les ressources de ce type.
- Par défaut, toutes les chaînes sécurisées (telles que les secrets Key Vault) et les chaînes sécurisées (telles que les chaînes de connexion, les clés et les jetons) sont paramétrisées.
Exemple de définition de modèle de paramètres
Voici un exemple de définition de modèle de paramètres :
{
"Microsoft.Synapse/workspaces/notebooks": {
"properties": {
"bigDataPool": {
"referenceName": "="
}
}
},
"Microsoft.Synapse/workspaces/sqlscripts": {
"properties": {
"content": {
"currentConnection": {
"*": "-"
}
}
}
},
"Microsoft.Synapse/workspaces/pipelines": {
"properties": {
"activities": [{
"typeProperties": {
"waitTimeInSeconds": "-::int",
"headers": "=::object",
"activities": [
{
"typeProperties": {
"url": "-:-webUrl:string"
}
}
]
}
}]
}
},
"Microsoft.Synapse/workspaces/integrationRuntimes": {
"properties": {
"typeProperties": {
"*": "="
}
}
},
"Microsoft.Synapse/workspaces/triggers": {
"properties": {
"typeProperties": {
"recurrence": {
"*": "=",
"interval": "=:triggerSuffix:int",
"frequency": "=:-freq"
},
"maxConcurrency": "="
}
}
},
"Microsoft.Synapse/workspaces/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"connectionString": "|:-connectionString:secureString",
"secretAccessKey": "|"
}
}
},
"AzureDataLakeStore": {
"properties": {
"typeProperties": {
"dataLakeStoreUri": "="
}
}
},
"AzureKeyVault": {
"properties": {
"typeProperties": {
"baseUrl": "|:baseUrl:secureString"
},
"parameters": {
"KeyVaultURL": {
"type": "=",
"defaultValue": "|:defaultValue:secureString"
}
}
}
}
},
"Microsoft.Synapse/workspaces/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.Synapse/workspaces/credentials" : {
"properties": {
"typeProperties": {
"resourceId": "="
}
}
}
}
Voici une explication de la façon dont le modèle précédent est construit, par type de ressource.
notebooks
- Toute propriété du chemin d’accès
properties/bigDataPool/referenceNameest paramétrisée avec sa valeur par défaut. Vous pouvez paramétriser le pool Spark attaché pour chaque fichier de notebook.
sqlscripts
- Dans le chemin d’accès
properties/content/currentConnection, les propriétéspoolNameetdatabaseNamesont paramétrisées en tant que chaînes sans les valeurs par défaut du modèle.
pipelines
- Toute propriété du chemin d’accès
activities/typeProperties/waitTimeInSecondsest paramétrisée. Toute activité dans un pipeline qui a une propriété au niveau du code nomméewaitTimeInSeconds(par exemple, l’activitéWait) est paramétrable en tant que nombre, avec un nom par défaut. La propriété n’aura pas de valeur par défaut dans le modèle Resource Manager. Au lieu de cela, l’entrée de la propriété devra être saisie pendant le déploiement Resource Manager. - La propriété
headers(par exemple, dans une activitéWeb) est paramétrisée avec le typeobject(Objet). La propriétéheadersa une valeur par défaut qui est la même valeur que la fabrique source.
integrationRuntimes
- Toutes les propriétés du chemin
typePropertiessont paramétrisées avec leurs valeurs par défaut respectives. Par exemple, deux propriétés existent sous les propriétés de typeIntegrationRuntimes:computePropertiesetssisProperties. Les deux types de propriété sont créés avec leurs valeurs et types (objet) par défaut respectifs.
triggers
Sous
typeProperties, deux propriétés sont paramétrisées :- La propriété
maxConcurrencya une valeur par défaut et est de typestring. Le nom du paramètre par défaut de la propriétémaxConcurrencyest<entityName>_properties_typeProperties_maxConcurrency. - La propriété
recurrenceest également paramétrable. Toutes les propriétés sous la propriétérecurrencesont définies pour être paramétrisées en tant que chaînes, avec des valeurs par défaut et des noms de paramètres. La propriétéintervalest une exception, qui est paramétrisée en tant que typeint. Le nom du paramètre a pour suffixe<entityName>_properties_typeProperties_recurrence_triggerSuffix. De même, la propriétéfreqest une chaîne et peut être paramétrée en tant que chaîne. La propriétéfreqest toutefois paramétrable sans valeur par défaut. Le nom est abrégé et suivi d’un suffixe, tel que<entityName>_freq.
Remarque
Actuellement, un maximum de 50 déclencheurs est pris en charge.
- La propriété
linkedServices
- Les services liés sont uniques. Étant donné que les services liés et les jeux de données sont de types différents, vous pouvez fournir une personnalisation spécifique au type. Dans l’exemple précédent, pour tous les services liés de type
AzureDataLakeStore, un modèle spécifique est appliqué. Pour tous les autres (identifiés par l’utilisation du caractère*), un modèle différent est appliqué. - La propriété
connectionStringest paramétrisée en tant que valeursecurestring. Elle n’a pas de valeur par défaut. Le nom du paramètre est abrégé et suivi du suffixeconnectionString. - La propriété
secretAccessKeyest paramétrisée en tant que valeurAzureKeyVaultSecret(par exemple, dans un service lié Amazon S3). La propriété est paramétrisée automatiquement en tant que secret Azure Key Vault et extraite du coffre de clés configuré. Vous pouvez également paramétriser le coffre de clés proprement dit.
datasets
- Bien que vous puissiez personnaliser les types dans les jeux de données, une configuration de niveau explicite n’est pas nécessaire. Dans l’exemple précédent, toutes les propriétés du jeu de données sous
typePropertiessont paramétrables.
Meilleures pratiques pour CI/CD
Si vous utilisez l’intégration de Git à votre espace de travail Azure Synapse et que vous disposez d’un pipeline CI/CD qui déplace vos modifications de l’environnement de développement à celui de test, puis à celui de production, nous vous recommandons les meilleures pratiques suivantes :
- Intégrez uniquement l’espace de travail de développement à Git. Si vous utilisez l’intégration de Git, intégrez uniquement votre espace de travail Azure Synapse de développement à Git. Les modifications au niveau des espaces de travail de test et de production sont déployées via CI/CD et ne nécessitent pas d’intégration Git.
- Préparez les pools avant de migrer les artefacts. Si vous disposez d’un script ou notebook SQL attaché à des pools dans l’espace de travail de développement, utilisez les mêmes noms de pools dans différents environnements.
- Synchronisez le contrôle de version dans les scénarios « infrastructure as code » . Pour gérer l’infrastructure (réseaux, machines virtuelles, équilibreurs de charge et topologie de connexion) dans un modèle descriptif, utilisez le même contrôle de version que celui que l’équipe DevOps utilise pour le code source.
- Passez en revue les meilleures pratiques d’Azure Data Factory. Si vous utilisez Data Factory, consultez les meilleures pratiques relatives aux artefacts Data Factory.
Résoudre les problèmes de déploiement d’artefacts
Utiliser la tâche de déploiement d’espace de travail Synapse pour déployer des artefacts Synapse
Contrairement à Data Factory, dans Azure Synapse, les artefacts ne sont pas des ressources Resource Manager. Vous ne pouvez pas utiliser la tâche de déploiement d’un modèle ARM pour déployer des artefacts Azure Synapse. Utilisez plutôt la tâche de déploiement d’espace de travail Synapse pour déployer les artefacts et utilisez la tâche de déploiement ARM pour le déploiement de ressources ARM (pools et espace de travail). Cette tâche prend uniquement en charge les modèles Synapse dont les ressources sont de type Microsoft.Synapse. Avec cette tâche, les utilisateurs peuvent déployer automatiquement des modifications à partir de toutes les branches, sans cliquer manuellement sur la publication dans Synapse Studio. Voici quelques problèmes fréquemment signalés.
1. Échec de la publication : Le fichier arm de l’espace de travail est supérieur à 20 Mo
Il existe une limitation de taille de fichier dans le fournisseur Git. Par exemple, dans Azure DevOps, la taille maximale autorisée d’un fichier est de 20 Mo. Quand la taille du fichier de modèle d’espace de travail dépasse 20 Mo, cette erreur se produit lorsque vous publiez des modifications dans Synapse Studio, où le fichier de modèle d’espace de travail est généré et synchronisé avec Git. Pour résoudre ce problème, vous pouvez utiliser la tâche de déploiement Synapse avec l’opération validation ou l’opération validation et déploiement afin d’enregistrer le fichier de modèle d’espace de travail directement dans l’agent de pipeline, sans publier manuellement dans Synapse Studio.
2. Erreur de jeton inattendu dans la mise en production
Si votre fichier de paramètres contient des valeurs de paramètres qui ne sont pas échappées, le pipeline de mise en production ne parvient pas à analyser le fichier et génère une erreur unexpected token. Nous vous suggérons de remplacer les paramètres ou d’utiliser Key Vault pour récupérer les valeurs des paramètres. Vous pouvez également utiliser des caractères d’échappement doubles pour résoudre le problème.
3. Échec du déploiement du runtime d’intégration
Si vous disposez du modèle d’espace de travail généré à partir d’un espace de travail VNET managé et que vous essayez d’effectuer le déploiement sur un espace de travail normal, ou vice versa, cette erreur se produira.
4. Caractère inattendu rencontré lors de l’analyse de la valeur
Le modèle ne peut pas être analysé. Essayez d’échapper les barres obliques inverses : \\Test01\Test
5. Impossible de récupérer les informations de l’espace de travail - Introuvable
Les informations de l’espace de travail cible ne sont pas correctement configurées. Vérifiez que la connexion de service que vous avez créée est limitée au groupe de ressources qui comprend l’espace de travail.
6. Échec de la suppression de l’artefact
L’extension compare les artefacts présents dans la branche de publication aux artefacts du modèle, et supprime ceux qui ne se trouvent pas dans le modèle, le cas échéant. Vérifiez que vous n’essayez pas de supprimer un artefact qui est présent dans la branche de publication et dont d’autres artefacts dépendent.
8. Échec du déploiement avec l’erreur : position json 0
Cette erreur se produit lorsque vous tentez de mettre à jour manuellement le modèle. Veillez à ne pas modifier manuellement le modèle.
9. La création ou la mise à jour du document a échoué en raison d’une référence non valide
Dans Synapse, un artefact peut être référencé par un autre artefact. Si vous avez paramétrisé un attribut qui est référencé dans un artefact, veillez à lui fournir une valeur correcte et non Null.
10. Impossible de récupérer l’état du déploiement dans le déploiement de notebook
Le notebook que vous essayez de déployer est attaché à un pool Spark dans le fichier de modèle d’espace de travail, alors que dans le déploiement, le pool n’existe pas dans l’espace de travail cible. Si vous ne paramétrisez pas le nom du pool, veillez à utiliser le même nom pour les pools des différents environnements.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour