Démarrage rapide : Ingérer des données à l’aide de l’ingestion en un clic (préversion)
L’ingestion en un clic rend le processus d’ingestion de données simple, rapide et intuitif. L’ingestion en un clic vous aide à ingérer des données, créer des tables de base de données et mapper des structures rapidement. Sélectionnez des données de différents types de sources dans des formats différents, qu’il s’agisse d’un processus d’ingestion unique ou continu.
Les fonctionnalités suivantes rendent l’ingestion en un clic particulièrement utile :
- Expérience intuitive guidée par l’Assistant Ingestion
- Ingestion des données en quelques minutes
- Ingestion des données de différents types de sources : fichier local, objets blob et conteneurs (jusqu’à 10 000 objets blob)
- Ingestion des données dans divers formats
- Ingestion des données dans des tables nouvelles ou existantes
- Schéma et mappage de table suggérés et faciles à changer
L’ingestion en un clic est particulièrement utile lorsque vous procédez à l’ingestion de données pour la première fois, ou lorsque le schéma de vos données ne vous est pas familier.
Prérequis
Un abonnement Azure. Créez un compte Azure gratuit.
Créez un pool Data Explorer en utilisant Synapse Studio ou le portail Azure
Créez une base de données Data Explorer.
Dans Synapse Studio, dans le volet de gauche, sélectionnez Données.
Sélectionnez +(Ajouter une nouvelle ressource) >Pool Data Explorer et utilisez les informations suivantes :
Paramètre Valeur suggérée Description Nom du pool contosodataexplorer Nom du pool Data Explorer à utiliser Nom TestDatabase Ce nom de base de données doit être unique dans le cluster. Période de conservation par défaut 365 Intervalle de temps (en jours) pendant lequel vous avez la garantie d’avoir les données à disposition pour les interroger. Cet intervalle se mesure à partir du moment où les données sont ingérées. Période de cache par défaut 31 Intervalle de temps (en jours) pendant lequel les données fréquemment interrogées restent disponibles dans le stockage SSD ou la RAM, plutôt que dans un stockage à plus long terme. Sélectionnez Créer pour créer la base de données. La création prend généralement moins d’une minute.
Créer un tableau
- Dans Synapse Studio, dans le volet de gauche, sélectionnez Développer.
- Sous Scripts KQL, sélectionnez + (Ajouter une nouvelle ressource) >Script KQL. Dans le volet de droite, vous pouvez nommer votre script.
- Dans le menu Connecter à, sélectionnez contosodataexplorer.
- Dans le menu Utiliser la base de données, sélectionnez TestDatabase.
- Collez la commande suivante, puis sélectionnez Exécuter pour créer la table.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Conseil
Vérifiez que la table a bien été créée. Dans le volet gauche, sélectionnez Sonnées, sélectionnez le menu Plus contosodataexplorer, puis cliquez sur Actualiser. Sous contosodataexplorer, développez Tables et assurez-vous que la table StormEvents apparaît dans la liste.
Accéder à l’Assistant Ingestion en un clic
L’Assistant Ingestion en un clic vous guide tout au long du processus d’ingestion en un clic.
Pour accéder à l’Assistant à partir d’Azure Synapse :
Dans Synapse Studio, dans le volet de gauche, sélectionnez Données.
Sous Bases de données de l’Explorateur de données, cliquez avec le bouton droit sur la base de données appropriée, puis sélectionnez Ouvrir dans Azure Data Explorer.
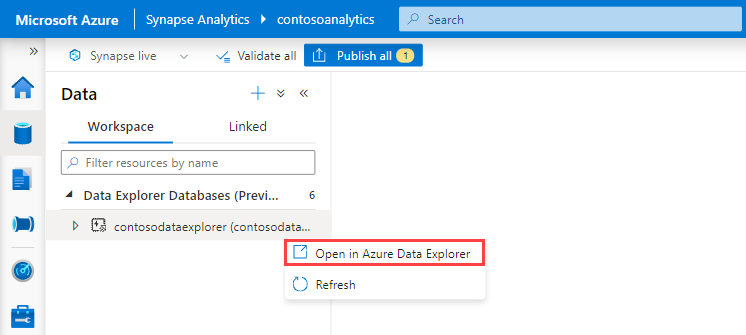
Cliquez avec le bouton droit sur le pool approprié, puis sélectionnez Ingérer de nouvelles données.
Pour accéder à l’Assistant à partir du portail Azure :
Dans le portail Azure, recherchez et sélectionnez l’espace de travail Synapse approprié.
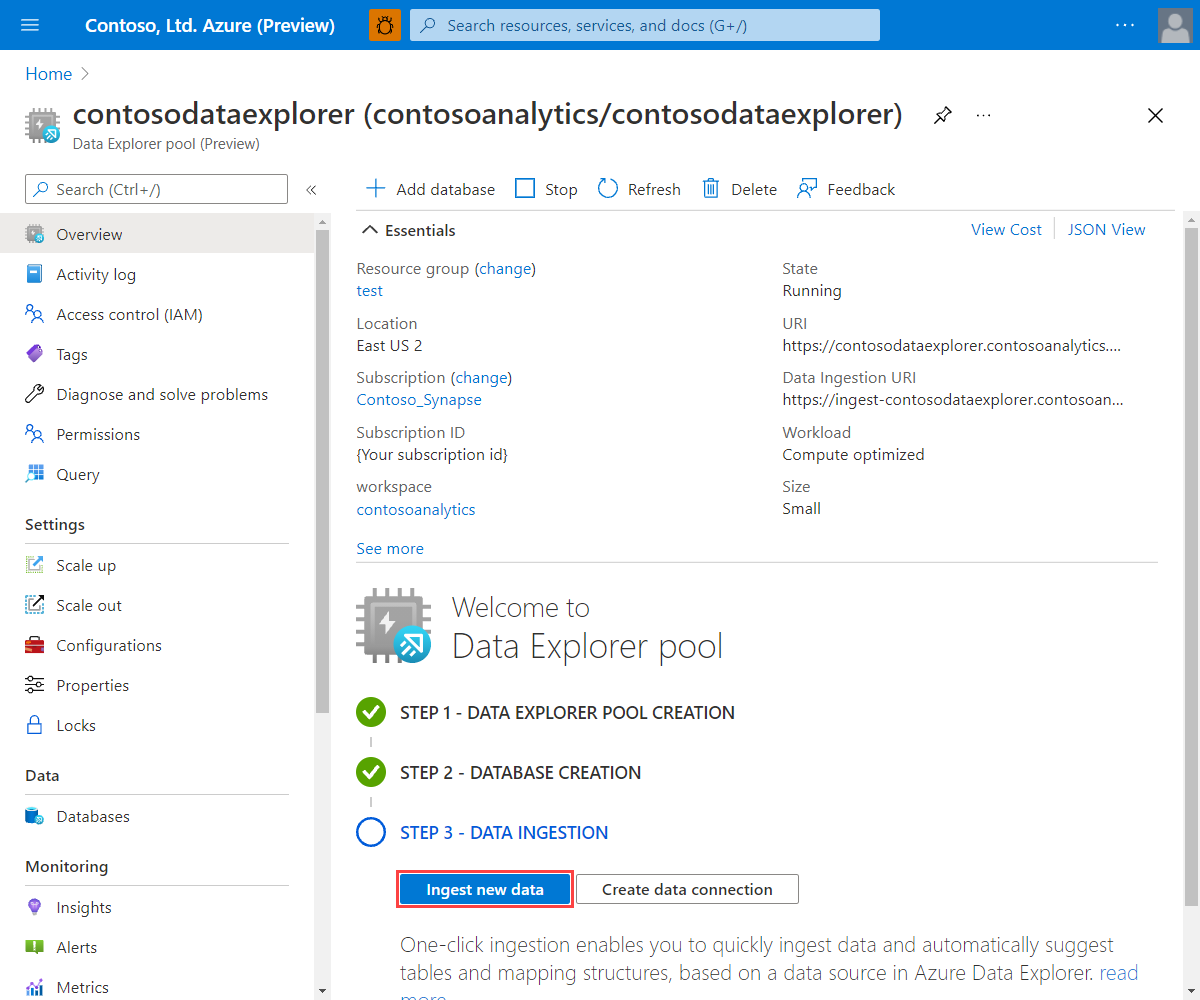
Sous Pools Data Explorer, sélectionnez le pool approprié.
Dans l’écran d’accueil Bienvenue dans le pool Data Explorer, sélectionnez Ingérer de nouvelles données.
Pour accéder à l’Assistant à partir de l’interface utilisateur web d’Azure Data Explorer :
- Avant de commencer, procédez comme suit pour obtenir les points de terminaison de requête et d’ingestion des données.
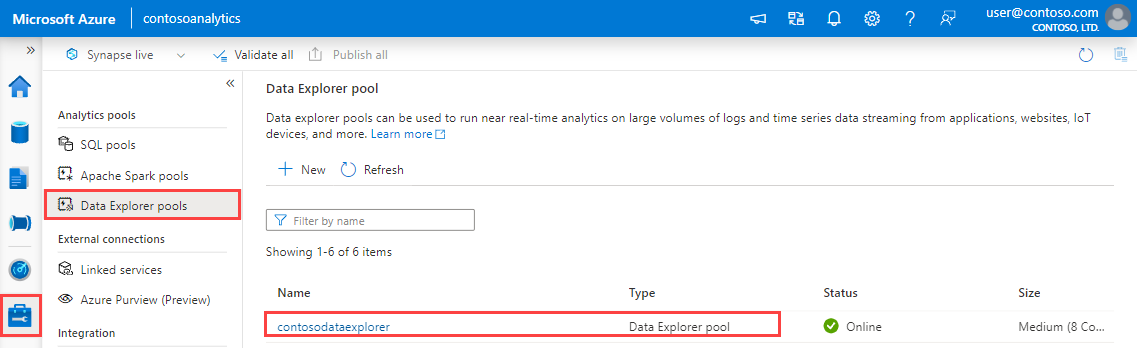
Dans Synapse Studio, dans le volet de gauche, sélectionnez Gérer>Pools Data Explorer.
Sélectionnez le pool Data Explorer à utiliser pour voir ses détails.
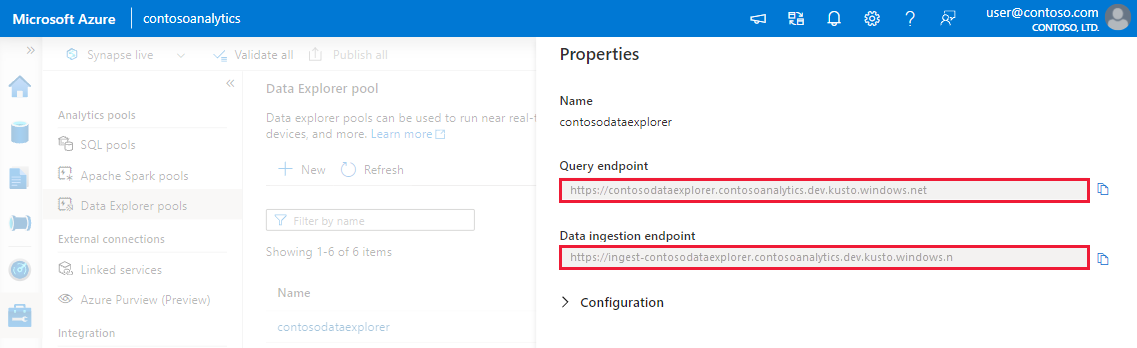
Notez les points de terminaison de requête et d’ingestion de données. Utilisez le point de terminaison de requête comme cluster pour la configuration des connexions à votre pool Data Explorer. Lors de la configuration des kits de développement logiciel (SDK) pour l’ingestion des données, utilisez le point de terminaison d’ingestion des données.
- Dans l’interface utilisateur web d’Azure Data Explorer, ajoutez une connexion au point de terminaison de requête.
- Sélectionnez Requête dans le menu gauche, cliquez avec le bouton droit sur la base de données ou la table, puis sélectionnez Ingérer de nouvelles données.
- Avant de commencer, procédez comme suit pour obtenir les points de terminaison de requête et d’ingestion des données.
Assistant Ingestion en un clic
Notes
Cette section décrit l’Assistant utilisant Event Hub comme source de données. Vous pouvez également utiliser ces étapes pour ingérer des données depuis un blob, un fichier, un conteneur de blobs et un conteneur ADLS Gen2.
Remplacez les valeurs d’exemple par les valeurs réelles de votre espace de travail Synapse.
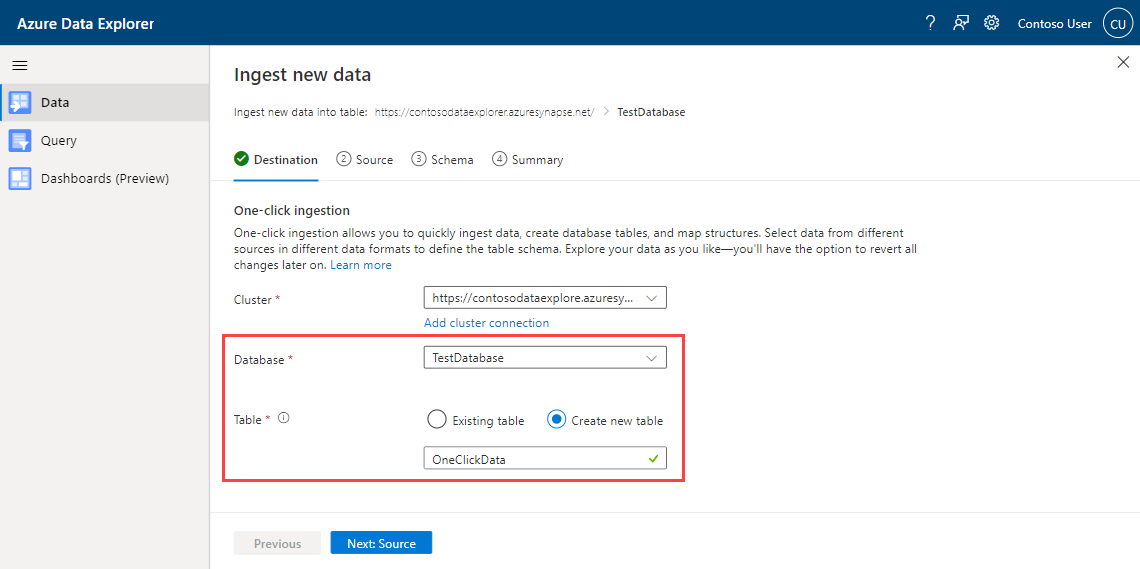
Dans l’onglet Destination, choisissez la base de données et la table des données ingérées.
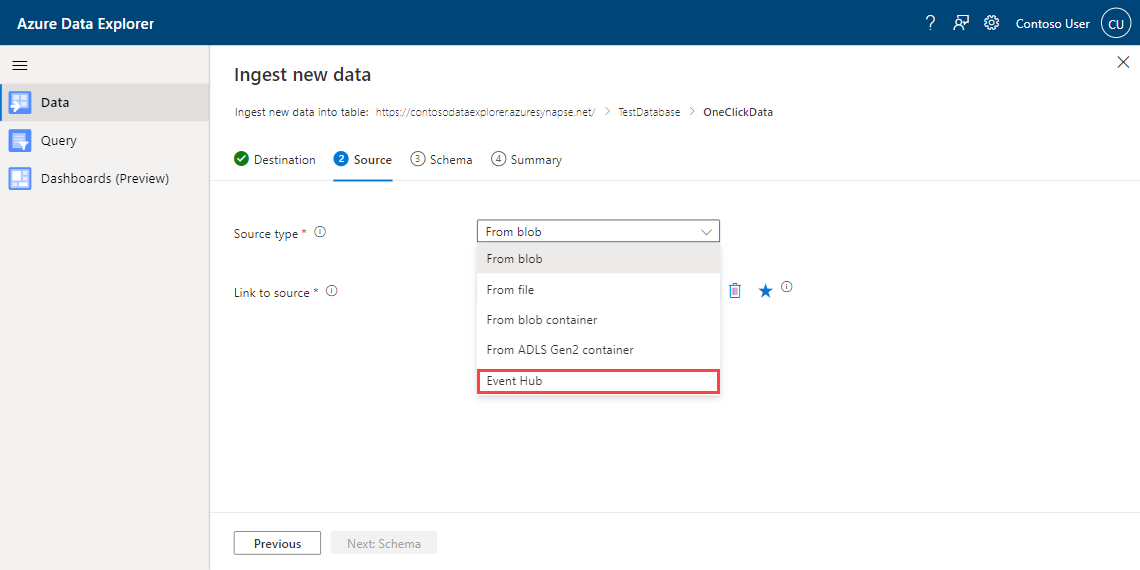
Sous l’onglet Source :
Sélectionnez Event Hub comme type de source pour l’ingestion.
Renseignez les détails de la connexion de données de l’Event Hub en utilisant les informations suivantes :
Paramètre Valeur d'exemple Description Nom de la connexion de données ContosoDataConnection Nom de la connexion de données de l’Event Hub. Abonnement Contoso_Synapse Abonnement dans lequel se trouve l’Event Hub. Espace de noms de l’Event Hub contosoeventhubnamespace Espace de noms de l’Event Hub. Groupe de consommateurs contosoconsumergroup Nom du groupe de consommateurs de l’Event Hub. 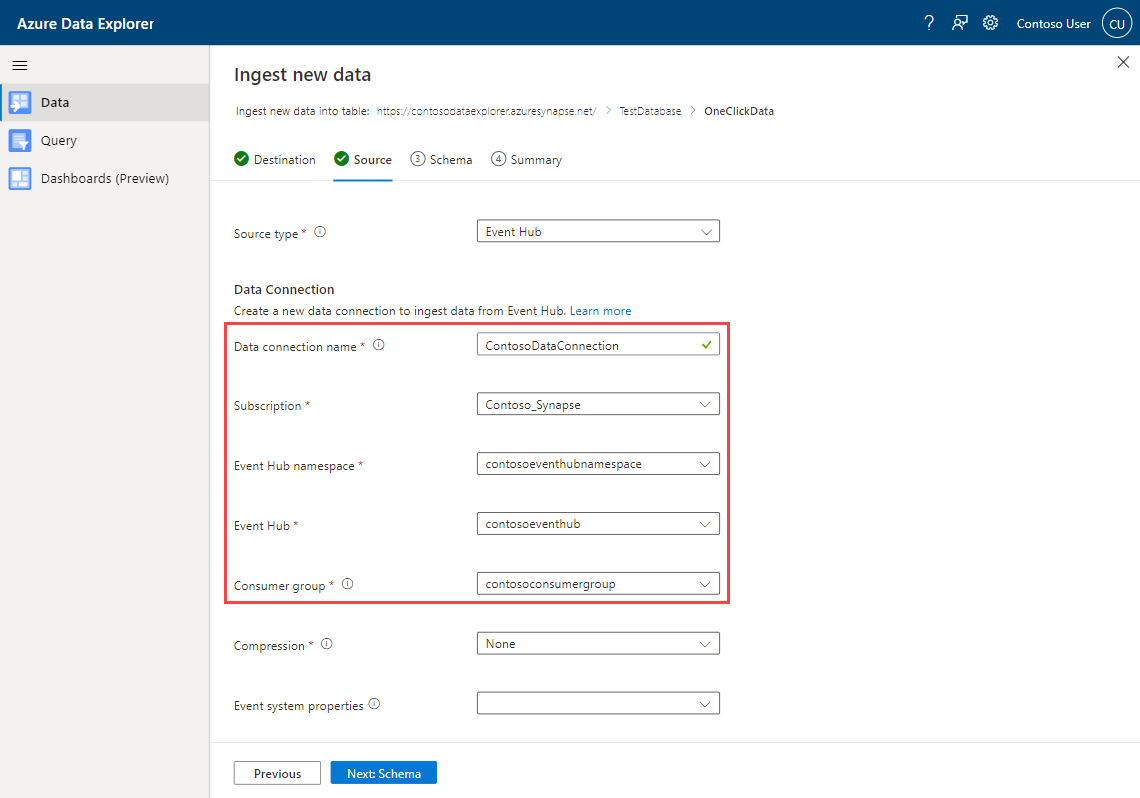
Sélectionnez Suivant.
Mappage de schéma
Le service génère automatiquement les propriétés de schéma et d’ingestion, que vous pouvez changer. Vous pouvez utiliser une structure de mappage existante ou en créer une, selon que l’ingestion est destinée à une table existante ou nouvelle.
Sous l’onglet Schéma, effectuez les actions suivantes :
- Vérifier le type de compression généré automatiquement
- Choisir le format de vos données Les formats différents vous permettront d’apporter des modifications supplémentaires.
- Changez le mappage dans la fenêtre Éditeur.
Formats de fichiers
L’ingestion en un clic prend en charge l’ingestion à partir de données sources sous tous les formats de données pris en charge par Data Explorer pour l’ingestion.
Fenêtre Éditeur
Dans la fenêtre Éditeur de l’onglet Schéma, vous pouvez ajuster les colonnes de la table de données, si nécessaire.
Les modifications que vous pouvez apporter dans une table dépendent des paramètres suivants :
- Si le type de la table est nouveau ou existant
- Si le type du mappage est nouveau ou existant
| Type de la table | Type de mappage | Ajustements disponibles |
|---|---|---|
| Nouvelle table | Nouveau mappage | Modifier le type de données, Renommer la colonne, Nouvelle colonne, Supprimer la colonne, Mettre à jour la colonne, Trier par ordre croissant, Trier par ordre décroissant |
| Table existante | Nouveau mappage | Nouvelle colonne (vous pourrez ensuite modifier le type de données, la renommer ou la mettre à jour) Mettre à jour la colonne, Tri croissant, Tri décroissant |
| Mappage existant | Tri croissant, Tri décroissant |
Notes
Lorsque vous ajoutez une nouvelle colonne ou mettez à jour une colonne, vous pouvez modifier les transformations de mappage. Pour plus d’informations, consultez Transformations de mappage.
Mappage des transformations
Certains mappages de format de données (Parquet, JSON et Avro) prennent en charge des transformations simples au moment de l’ingestion. Pour appliquer des transformations de mappage, créez ou mettez à jour une colonne dans la fenêtre de l’Éditeur.
Les transformations de mappage peuvent être effectuées sur une colonne de type string ou datetime, avec la source dont le type de données est int ou long. Les transformations de mappage prises en charge sont :
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Ingestion de données
Une fois que vous avez terminé le mappage de schéma et les manipulations de colonnes, l’Assistant Ingestion démarre le processus d’ingestion de données.
Quand l’ingestion de données provient de sources autres que des conteneurs, l’ingestion prend effet immédiatement.
Si la source de données est un conteneur :
- La stratégie de traitement par lot de Data Explorer agrège vos données.
- Après l’ingestion, vous pouvez télécharger le rapport d’ingestion et passer en revue les performances de chaque objet blob qui a été traité.
Exploration initiale des données
Une fois l’ingestion terminée, vous pouvez effectuer une exploration initiale de vos données à l’aide des commandes rapides que l’Assistant met à votre disposition.