Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans cet article, vous découvrez les étapes de base permettant de charger et d’analyser des données avec Data Explorer pour Azure Synapse.
Créer un pool Data Explorer
Dans Synapse Studio, dans le volet de gauche, sélectionnez Gérer>Pools Data Explorer.
Sélectionnez Nouveau, puis entrez les informations suivantes dans l’onglet Informations de base :
Paramètre Valeur suggérée Description Nom du pool Data Explorer contosodataexplorer Il s'agit du nom que portera le pool Data Explorer. Charge de travail Optimisé pour le calcul Cette charge de travail offre un ratio plus élevé entre le CPU et le stockage SSD. Taille du nœud Petite (4 cœurs) Définissez ce paramètre sur la plus petite taille pour réduire les coûts de ce guide de démarrage rapide. Important
Notez qu'il existe des limitations spécifiques concernant les noms que les pools Data Explorer peuvent utiliser. Les noms ne doivent contenir que des lettres minuscules et des chiffres. Ils doivent comporter entre 4 et 15 caractères, et commencer par une lettre.
Sélectionnez Vérifier + créer>Créer. Votre pool Data Explorer commencera le processus d’approvisionnement.
Créer une base de données Data Explorer
Dans Synapse Studio, dans le volet de gauche, sélectionnez Données.
Sélectionnez + (Ajouter une nouvelle ressource) >Base de données Data Explorer et collez les informations suivantes :
Paramètre Valeur suggérée Description Nom du pool contosodataexplorer Nom du pool Data Explorer à utiliser Nom TestDatabase Ce nom de base de données doit être unique dans le cluster. Période de conservation par défaut 365 Intervalle de temps (en jours) pendant lequel vous avez la garantie d’avoir les données à disposition pour les interroger. Cet intervalle se mesure à partir du moment où les données sont ingérées. Période de cache par défaut 31 Intervalle de temps (en jours) pendant lequel les données fréquemment interrogées restent disponibles dans le stockage SSD ou la RAM, plutôt que dans un stockage à plus long terme. Sélectionnez Créer pour créer la base de données. La création prend généralement moins d’une minute.
Ingérer des exemples de données et les analyser à l’aide d’une requête simple
Une fois votre pool déployé, dans la fonctionnalité Synapse Studio du volet de gauche, sélectionnez Développer.
Sélectionnez + (Ajouter une nouvelle ressource) >Script KQL. Dans le volet de droite, vous pouvez nommer votre script.
Dans le menu Connecter à, sélectionnez contosodataexplorer.
Dans le menu Utiliser la base de données, sélectionnez TestDatabase.
Collez la commande suivante, puis sélectionnez Exécuter pour créer une table StormEvents.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Conseil
Vérifiez que la table a bien été créée. Dans le volet gauche, sélectionnez Sonnées, sélectionnez le menu Plus contosodataexplorer, puis cliquez sur Actualiser. Sous contosodataexplorer, développez Tables et assurez-vous que la table StormEvents apparaît dans la liste.
Collez la commande suivante, puis sélectionnez Exécuter pour ingérer des données dans la table StormEvents.
.ingest into table StormEvents 'https://kustosamples.blob.core.windows.net/samplefiles/StormEvents.csv' with (ignoreFirstRecord=true)Une fois l’ingestion terminée, collez la requête suivante, sélectionnez la requête dans la fenêtre, puis Exécuter.
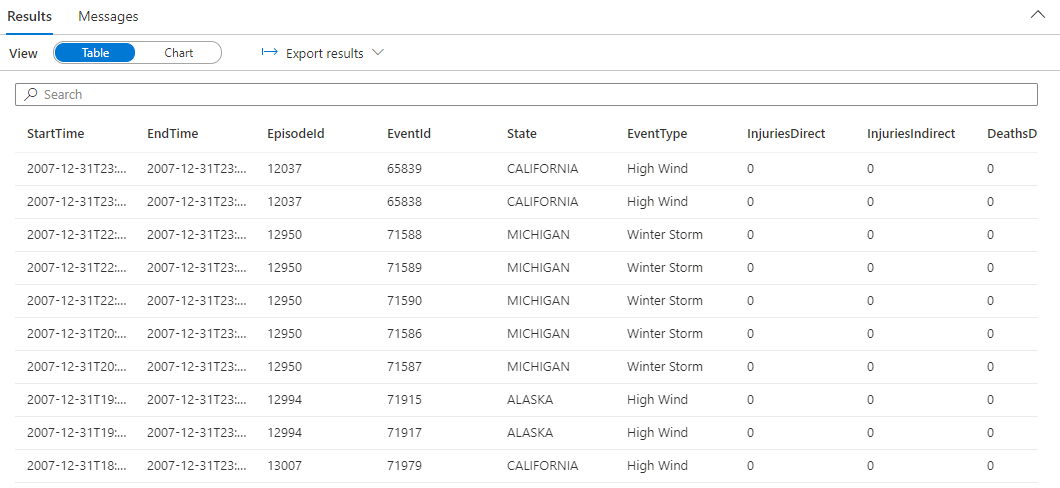
StormEvents | sort by StartTime desc | take 10La requête retourne les résultats suivants à partir des exemples de données ingérés.