Démarrage rapide : Ingérer des données à l’aide d’Azure Synapse Pipelines (préversion)
Dans ce démarrage rapide, vous allez apprendre à charger des données à partir d’une source de données dans un pool Azure Synapse Data Explorer.
Prérequis
Un abonnement Azure. Créez un compte Azure gratuit.
Créez un pool Data Explorer en utilisant Synapse Studio ou le portail Azure
Créez une base de données Data Explorer.
Dans Synapse Studio, dans le volet de gauche, sélectionnez Données.
Sélectionnez +(Ajouter une nouvelle ressource) >Pool Data Explorer et utilisez les informations suivantes :
Paramètre Valeur suggérée Description Nom du pool contosodataexplorer Nom du pool Data Explorer à utiliser Nom TestDatabase Ce nom de base de données doit être unique dans le cluster. Période de conservation par défaut 365 Intervalle de temps (en jours) pendant lequel vous avez la garantie d’avoir les données à disposition pour les interroger. Cet intervalle se mesure à partir du moment où les données sont ingérées. Période de cache par défaut 31 Intervalle de temps (en jours) pendant lequel les données fréquemment interrogées restent disponibles dans le stockage SSD ou la RAM, plutôt que dans un stockage à plus long terme. Sélectionnez Créer pour créer la base de données. La création prend généralement moins d’une minute.
Créer un tableau
- Dans Synapse Studio, dans le volet de gauche, sélectionnez Développer.
- Sous Scripts KQL, sélectionnez + (Ajouter une nouvelle ressource) >Script KQL. Dans le volet de droite, vous pouvez nommer votre script.
- Dans le menu Connecter à, sélectionnez contosodataexplorer.
- Dans le menu Utiliser la base de données, sélectionnez TestDatabase.
- Collez la commande suivante, puis sélectionnez Exécuter pour créer la table.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Conseil
Vérifiez que la table a bien été créée. Dans le volet gauche, sélectionnez Sonnées, sélectionnez le menu Plus contosodataexplorer, puis cliquez sur Actualiser. Sous contosodataexplorer, développez Tables et assurez-vous que la table StormEvents apparaît dans la liste.
Obtenez les points de terminaison de requête et d’ingestion de données. Vous aurez besoin du point de terminaison de requête pour configurer votre service lié.
Dans Synapse Studio, dans le volet de gauche, sélectionnez Gérer>Pools Data Explorer.
Sélectionnez le pool Data Explorer à utiliser pour voir ses détails.
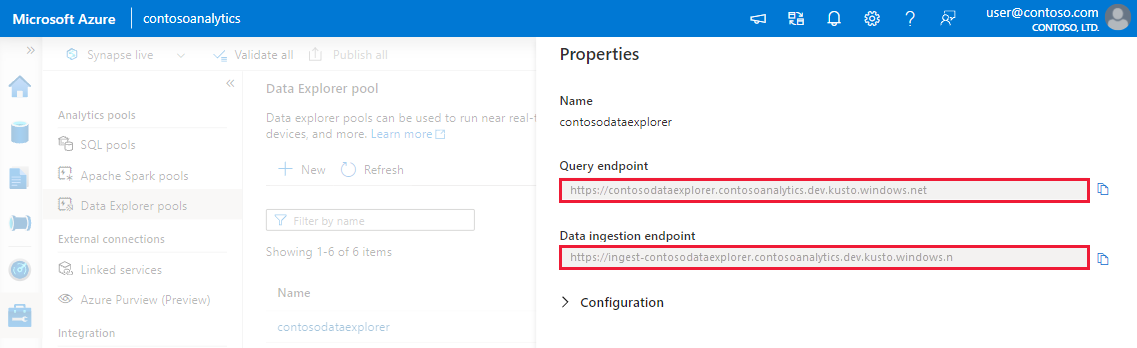
Notez les points de terminaison de requête et d’ingestion de données. Utilisez le point de terminaison de requête comme cluster pour la configuration des connexions à votre pool Data Explorer. Lors de la configuration des kits de développement logiciel (SDK) pour l’ingestion des données, utilisez le point de terminaison d’ingestion des données.
Créer un service lié
Dans Azure Synapse Analytics, un service lié vous permet de définir vos informations de connexion à d’autres services. Dans cette section, vous allez créer un service lié pour Azure Data Explorer.
Dans Synapse Studio, dans le volet de gauche, sélectionnez Gérer>Services liés.
Sélectionnez +Nouveau.

Sélectionnez le service Azure Data Explorer à partir de la galerie, puis sélectionnez Continuer.

Dans la page Nouveaux services liés, utilisez les informations suivantes :
Paramètre Valeur suggérée Description Nom contosodataexplorerlinkedservice Nom du nouveau service lié Azure Data Explorer. Méthode d'authentification Identité gérée Méthode d’authentification du nouveau service. Méthode de sélection du compte Entrer manuellement Méthode permettant de spécifier le point de terminaison de requête. Point de terminaison https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net Point de terminaison de requête que vous avez noté précédemment. Base de données TestDatabase Base de données dans laquelle vous souhaitez ingérer les données. 
Sélectionnez Tester la connexion pour vérifier les paramètres, puis sélectionnez Créer.
Créer un pipeline pour ingérer des données
Un pipeline contient le flux logique pour l’exécution d’un ensemble d’activités. Dans cette section, vous allez créer un pipeline contenant une activité de copie qui ingère les données de votre source préférée dans un pool Data Explorer.
Dans Synapse Studio, dans le volet de gauche, sélectionnez Intégrer.
Sélectionnez +>Pipeline. Dans le volet de droite, vous pouvez nommer votre pipeline.

Sous Activités>Déplacer et transformer, faites glisser Copier des données sur le canevas du pipeline.
Sélectionnez l’activité de copie et accédez à l’onglet Source. Sélectionnez ou créez un jeu de données source comme source de copie des données.
Accédez à l’onglet Récepteur. Sélectionnez Nouveau pour créer un jeu de données récepteur.

Sélectionnez le jeu de données Azure Data Explorer à partir de la galerie, puis sélectionnez Continuer.
Dans le volet Définir les propriétés, utilisez les informations suivantes, puis sélectionnez OK.
Paramètre Valeur suggérée Description Nom AzureDataExplorerTable Nom du nouveau pipeline. Service lié contosodataexplorerlinkedservice Service lié que vous avez créé précédemment. Table StormEvents Table que vous avez créée précédemment. 
Pour valider le pipeline, sélectionnez Valider dans la barre d’outils. Le résultat de la validation du pipeline s’affiche sur le côté droit de la page.
Déboguer et publier le pipeline
Une fois la configuration de votre pipeline terminée, avant de publier vos artefacts, vous pouvez exécuter un débogage pour vérifier que tout est correct.
Sélectionnez Déboguer dans la barre d’outils. L’état d’exécution du pipeline apparaît dans l’onglet Sortie au bas de la fenêtre.
Une fois que le pipeline s’exécute correctement, sélectionnez Publier tout dans la barre d’outils supérieure. Cette action publie les entités (jeux de données et pipelines) que vous avez créées dans le service Synapse Analytics.
Patientez jusqu’à voir le message Publication réussie. Pour voir les messages de notification, sélectionnez le bouton avec l’icône en forme de cloche en haut à droite.
Déclencher et surveiller le pipeline
Dans cette section, vous déclenchez manuellement le pipeline publié à l’étape précédente.
Sélectionnez Ajouter déclencheur dans la barre d’outils, puis Déclencher maintenant. Dans la page Exécution du pipeline, sélectionnez OK.
Accédez à l’onglet Surveiller dans la barre latérale gauche. Vous voyez un pipeline qui est déclenché par un déclencheur manuel.
Quand l’exécution du pipeline s’effectue correctement, sélectionnez le lien dans la colonne Nom du pipeline pour afficher les détails de l’exécution d’activité ou réexécuter le pipeline. Dans cet exemple, il n’y a qu’une seule activité, vous ne voyez donc qu’une seule entrée dans la liste.
Pour plus de détails sur l’opération de copie, sélectionnez le lien Détails (icône en forme de lunettes) dans la colonne Nom de l’activité. Vous pouvez suivre les informations détaillées comme le volume de données copiées à partir de la source dans le récepteur, le débit des données, les étapes d’exécution avec une durée correspondante et les configurations utilisées.
Pour revenir à l’affichage des exécutions du pipeline, sélectionnez le lien Toutes les exécutions de pipelines affiché en haut de la fenêtre. Sélectionnez Actualiser pour actualiser la liste.
Vérifiez que vos données sont correctement écrites dans le pool Data Explorer.