Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article est la première partie d’une série de sept parties qui fournit des conseils sur la migration de Teradata vers Azure Synapse Analytics. Cet article est consacré aux meilleures pratiques pour la conception et les performances.
Vue d’ensemble
De nombreux utilisateurs existants des systèmes d’entrepôt de données Teradata souhaitent tirer parti des innovations qu’offrent les environnements cloud modernes. Les environnements cloud IaaS (Infrastructure as a Service) et PaaS (Platform-as-a-Service) vous permettent de déléguer des tâches telles que la maintenance de l’infrastructure et le développement de plateforme au fournisseur cloud.
Conseil
Plus qu’une base de données, l’environnement Azure inclut un ensemble complet de fonctionnalités et d’outils.
Teradata et Azure Synapse Analytics sont dans les deux cas des bases de données SQL conçues pour utiliser des techniques de traitement massivement parallèle (MPP, Massively Parallel Processing), lesquelles permettent d’obtenir des performances de requête élevées sur d’énormes volumes de données. Il y a toutefois quelques différences d’approche fondamentales entre les deux :
Les systèmes Teradata hérités sont souvent installés localement et utilisent du matériel propriétaire, tandis qu’Azure Synapse est basé sur le cloud et utilise les ressources de stockage et de calcul d’Azure.
Étant donné que les ressources de stockage et de calcul sont séparées dans l’environnement Azure et qu’elles disposent d’une capacité de mise à l’échelle, il est facile de les mettre à l’échelle vers le haut et vers le bas.
Vous pouvez suspendre ou redimensionner Azure Synapse en fonction des besoins afin de réduire la consommation des ressources et par là-même, le coût.
La mise à niveau d’une configuration Teradata constitue une tâche majeure qui nécessite du matériel physique supplémentaire et une reconfiguration ou un rechargement potentiellement longs des bases de données.
Microsoft Azure est un environnement cloud disponible dans le monde entier, hautement sécurisé et scalable, qui comprend Azure Synapse et un écosystème d’outils et de capacités qui le complètent. Le diagramme suivant récapitule l’écosystème Azure Synapse.
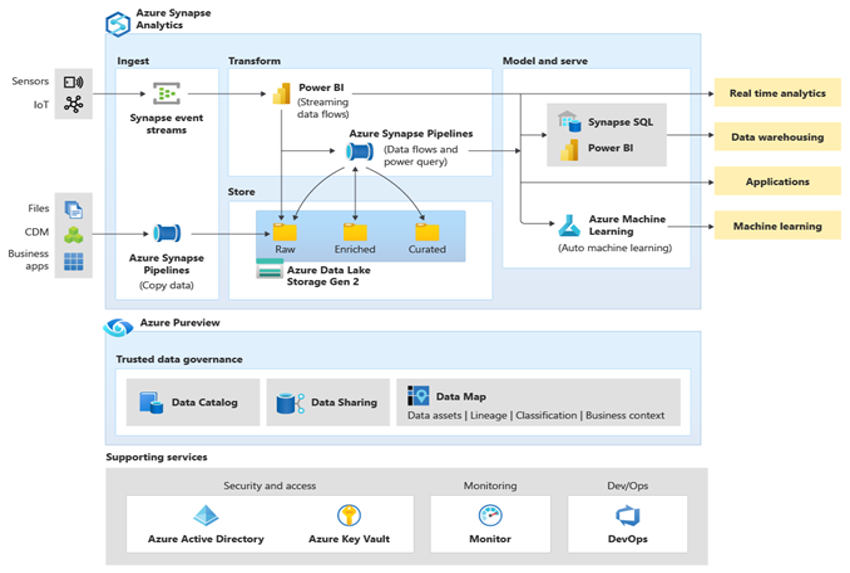
Azure Synapse offre d’excellentes performances de bases de données relationnelles en utilisant des techniques telles que le traitement MPP et plusieurs niveaux de mise en cache automatisée pour les données fréquemment utilisées. Vous pouvez constater les résultats de ces techniques dans des benchmarks indépendants, comme celui récemment réalisé par GigaOm, qui compare Azure Synapse à d’autres offres populaires d’entrepôt de données dans le cloud. Les clients qui migrent vers l’environnement Azure Synapse voient de nombreux avantages, notamment :
Amélioration des performances et du rapport prix/performance.
Une plus grande souplesse et un temps de valorisation plus court.
Déploiement de serveur et d’applications plus rapide.
Scalabilité élastique : payez uniquement pour l’utilisation réelle.
Amélioration de la conformité/sécurité.
Réduction des coûts de stockage et de récupération d’urgence.
Réduction du coût total de possession, meilleur contrôle des coûts et dépenses opérationnelles (OPEX) simplifiées.
Pour optimiser ces avantages, migrez les données et applications nouvelles ou existantes vers la plateforme Azure Synapse. Dans de nombreuses organisations, la migration comprend la migration d’un entrepôt de données existant à partir d’une plateforme sur site existante telle que Teradata vers Azure Synapse. En général, le processus de migration comprend les étapes suivantes :
Préparation 🡆
Définissez l’étendue de ce qui doit être migré.
Créez un inventaire des données et processus pour la migration.
Définissez les modifications de modèle de données (le cas échéant).
Définissez le mécanisme d’extraction de données sources.
Identifiez les outils et fonctionnalités Azure (et tiers) à utiliser.
Formez le personnel à un stade précoce sur la nouvelle plateforme.
Configurez la plateforme cible Azure.
Migration 🡆
Commencez par une migration simple et à petite échelle.
Automatisez autant que possible.
Utilisez les outils et fonctionnalités Azure intégrés pour réduire l’effort de migration.
Migrez les métadonnées des tables et des vues.
Migrez les données historique à conserver.
Migrez ou refactorisez les procédures stockées et les processus métier.
Migrer ou refactoriser les processus de charge incrémentielle ETL/ELT
Tâches de post-migration
Surveillez et documenter toutes les étapes du processus.
Servez-vous de l’expérience acquise pour créer un modèle en vue de futures migrations.
Remaniez le modèle de données si nécessaire, en exploitant les performances et la scalabilité de la nouvelle plateforme.
Testez les applications et les outils de requête.
Évaluez et optimisez les performances des requêtes.
Cet article fournit des informations générales et des instructions relatives à l’optimisation des performances lors de la migration d’un entrepôt de données d’un environnement Netezza existant vers Azure Synapse. L’objectif de l’optimisation des performances est d’obtenir les mêmes performances d’entrepôt de données dans Azure Synapse après la migration du schéma.
Remarques relatives à la conception
Étendue de la migration
Lorsque vous préparez la migration à partir d’un environnement Teradata, tenez compte des choix de migration suivants.
Choisir la charge de travail pour la migration initiale
Habituellement, les environnements Teradata hérités ont évolué au fil du temps pour englober plusieurs domaines thématiques et charges de travail mixtes. Quand vous décidez de commencer un projet de migration, choisissez un domaine qui pourra :
Prouver la viabilité de la migration vers Azure Synapse en tirant rapidement parti des avantages du nouvel environnement.
Permettre à votre personnel technique interne d’acquérir une expérience adaptée aux processus et aux outils qu’il utilisera lors de la migration d’autres domaines.
Créer un modèle pour d’autres migrations propres à l’environnement Teradata source et aux outils et processus déjà en place.
Être un bon candidat pour une migration initiale à partir d’un environnement Teradata prend en charge les éléments précédents et :
Implémente une charge de travail BI/Analytics plutôt qu’une charge de travail OLTP (Online Transaction Processing).
Possède un modèle de données, par exemple un schéma en étoile ou en flocons qui peut être migré avec un minimum de modifications.
Conseil
Créez un inventaire des objets à migrer et documentez le processus de migration.
Le volume de données migrées dans la migration initiale doit être suffisamment important pour illustrer les fonctionnalités et les avantages de l’environnement Azure Synapse, mais pas trop volumineux pour illustrer rapidement la valeur. La valeur typique se situe dans la plage de 1 à 10 téraoctets.
Pour votre projet de migration initial, réduisez les risque, les efforts et le temps de migration afin que vous puissiez rapidement bénéficier des avantages de l’environnement cloud Azure, limitez l’étendue de la migration aux magasins de données, tels que la partie OLAP DB d’un entrepôt Teradata. Les approches de migration progressive et lift-and-shift limitent l’étendue de la migration initiale aux magasins de données et ne traitent pas des aspects de migration plus larges, tels que la migration ETL et la migration des données historiques. Toutefois, vous pouvez traiter ces aspects dans les phases ultérieures du projet une fois que la couche de magasin de données migrée est répliquée avec les données et les processus de génération requis.
Migration lift-and-shift et approche par phase
En règle générale, il existe deux types de migration, quel que soit l’objectif et l’étendue de la migration planifiée : le lift-and-shift en l’état et une approche par phases qui incorpore les modifications.
Migration lift-and-shift
Dans la migration lift-and-shift, le modèle de données existant, par exemple le schéma en étoile, est migré sans modifications vers la nouvelle plateforme Azure Synapse. Cette approche réduit les risques et la durée de la migration en diminuant le travail nécessaire pour profiter pleinement des avantages du passage à l’environnement cloud Azure. La migration lift-and-shift est adaptée à ces scénarios :
- Vous disposez d’un environnement Teradata existant avec un seul magasin de données à migrer ou
- Vous disposez d’un environnement Teradata existant avec des données qui se trouvent déjà dans un schéma en étoile ou en flocon bien conçu, ou
- Vous êtes sous pression, du point de vue de la planification, mais aussi du point de vue financier, pour passer à un environnement cloud moderne.
Conseil
La migration lift-and-shift est un bon point de départ, même si les phases suivantes implémentent des modifications apportées au modèle de données.
Approche par phases qui incorpore les modifications
Si un entrepôt de données hérité a évolué sur une longue période, vous devrez peut-être le reconcevoir pour maintenir les niveaux de performances requis. Vous devrez peut-être également le retravailler pour prendre en charge de nouvelles données telles que celles de l’Internet des objets (IoT). Dans le cadre du processus de retravail, migrez vers Azure Synapse pour profiter des avantages d’un environnement cloud scalable. La migration peut aussi inclure un changement dans le modèle de données sous-jacent, par exemple un déplacement d’un modèle Inmon vers un coffre de données.
Microsoft recommande de déplacer le modèle de données existant tel quel vers Azure (en utilisant éventuellement une instance Teradata de machine virtuelle dans Azure) et d’exploiter les performances et la flexibilité de l’environnement Azure pour appliquer les modifications de réingénierie. De cette façon, vous bénéficiez des fonctionnalités d’Azure pour apporter les modifications sans affecter le système source existant.
Utiliser une instance Teradata de machine virtuelle dans le cadre d’une migration
Lors de la migration à partir d’un environnement Teradata local, vous pouvez tirer parti du stockage cloud et de l’extensibilité élastique dans Azure pour créer une instance Teradata au sein d’une machine virtuelle. Cette approche colocalise l’instance Teradata avec l’environnement Azure Synapse cible. Vous pouvez utiliser des utilitaires Teradata standard, tels que Teradata Parallel Data Transporter, pour déplacer efficacement le sous-ensemble de tables Teradata migrées vers l’instance de machine virtuelle. Ensuite, toutes les autres tâches de migration peuvent avoir lieu dans l’environnement Azure. Cette approche présente plusieurs avantages :
Après la réplication initiale des données, le système source n’est pas affecté par les tâches de migration.
Les interfaces, outils et utilitaires Teradata familiers sont disponibles dans l’environnement Azure.
Dans l’environnement Azure, il n’y a plus de problèmes potentiels liés à la disponibilité de la bande passante réseau entre le système source local et le système cible dans le cloud.
Des outils comme Azure Data Factory peuvent appeler des utilitaires tels que Teradata Parallel Transporter pour migrer les données de façon rapide et efficace.
Vous pouvez entièrement orchestrer et contrôler le processus de migration dans l’environnement Azure.
Conseil
Utilisez des machines virtuelles Azure pour créer une instance Teradata temporaire en vue d’accélérer la migration et de réduire l’impact sur le système source.
Implémentation d’une migration pilotée par les métadonnées avec Azure Data Factory
Vous pouvez automatiser et orchestrer le processus de migration en utilisant les fonctionnalités de l’environnement Azure. Cette approche permet de réduire l’impact sur les performances dans l’environnement Netezza existant, qui est peut-être déjà près de sa pleine capacité.
Azure Data Factory est un service d’intégration de données basé sur le cloud qui vous permet de créer des flux de travail orientés données dans le cloud pour orchestrer et automatiser le déplacement des données et la transformation des données. Vous pouvez utiliser Azure Data Factory pour créer et planifier des workflows pilotés par les données (les pipelines) qui ingèrent des données provenant de différents magasins de données. Data Factory peut traiter et transformer les données à l’aide de services de calcul tels que Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics et Azure Machine Learning.
Lorsque vous envisagez d’utiliser Data Factory pour gérer le processus de migration, créez des métadonnées qui répertorient toutes les tables de données à migrer et leur emplacement.
Différences de conception entre Teradata et Azure Synapse Analytics
Comme mentionné précédemment, il existe quelques différences de base dans l’approche entre les bases de données Teradata et Azure Synapse Analytics et ces différences sont abordées ci-dessous.
Plusieurs bases de données ou une seule base de données et des schémas
L’environnement Teradata contient souvent plusieurs bases de données distinctes. Par exemple, il peut y avoir des bases de données distinctes pour : l’ingestion des données et les tables intermédiaires, les tables d’entrepôt de base et les magasins de données (parfois appelés couche sémantique). Les processus de pipeline ETL ou ELT peuvent implémenter des jointures entre bases de données et déplacer des données entre les différentes bases de données.
Par contre, l’environnement Azure Synapse contient une seule base de données et utilise des schémas pour séparer les tables en groupes séparés logiquement. Nous vous recommandons d’utiliser une série de schémas dans la base de données Azure Synapse cible pour imiter toutes les bases de données séparées qui sont migrées à partir de l’environnement Teradata. Si l’environnement Teradata utilise déjà des schémas, il se peut que vous deviez employer une nouvelle convention d’affectation de noms pour déplacer les tables et vues Teradata existantes vers le nouvel environnement. Par exemple, vous pouvez concaténer le noms de table et de schéma Teradata existants dans le nouveau nom de table Azure Synapse, puis utiliser les noms de schéma dans le nouvel environnement pour conserver les noms initiaux des bases de données séparées. Si le nommage de consolidation de schéma comporte des points, Azure Synapse Spark peut rencontrer des problèmes. Bien que vous puissiez utiliser des vues SQL sur les tables sous-jacentes pour maintenir les structures logiques, cette approche présente certains inconvénients :
Les vues dans Azure Synapse étant en lecture seule, toutes les mises à jour des données doivent avoir lieu sur les tables de base sous-jacentes.
S’il y a déjà une ou plusieurs couches de vues, l’ajout d’une couche supplémentaire de vues peut affecter les performances et la prise en charge, car les problèmes de vues imbriquées sont difficiles à résoudre.
Conseil
Combinez plusieurs bases de données en une seule dans Azure Synapse et utilisez des noms de schémas pour créer une séparation logique des tables.
Considérations relatives aux tables
Lorsque vous migrez des tables entre différents environnements, seules les données brutes et les métadonnées qui les décrivent physiquement sont migrées. Les autres éléments de base de données du système source, tels que les index, ne sont généralement pas migrés, car ils peuvent être inutiles ou implémentés différemment dans le nouvel environnement. Les optimisations des performances dans l’environnement source, telles que les index, indiquent où vous pouvez ajouter l’optimisation des performances dans le nouvel environnement. Par exemple, si une table dans l’environnement Teradata source a un index secondaire non unique (NUSI), cela suggère qu’un index non cluster doit être créé dans Azure Synapse. D’autres techniques d’optimisation des performances natives, telles que la réplication de table, peuvent être plus applicables qu’une création d’index « like for like ».
Conseil
Les index existants marquent les candidats à l’indexation dans l’entrepôt migré.
Haute disponibilité pour la base de données
Teradata prend en charge la réplication de données entre nœuds via l’option FALLBACK, qui réplique les lignes de table qui résident physiquement sur un nœud donné vers un autre nœud à l’intérieur du système. Cette approche empêche toute perte de données en cas d’échec d’un nœud, et fournit une base pour des scénarios de basculement.
L’objectif de l’architecture haute disponibilité dans Azure Synapse Analytics est de garantir que votre base de données est opérationnelle 99,9 % du temps, sans que vous deviez vous préoccuper de l’incidence des pannes et des opérations de maintenance. Pour plus d’informations sur le SLA, consultez Contrat SLA d’Azure Synapse Analytics. Azure gère automatiquement les tâches de maintenance critiques telles que la mise à jour corrective, les sauvegardes et les mises à niveau de Windows et de SQL. Azure gère également automatiquement les événements non planifiés tels que les défaillances dans le matériel, les logiciels ou le réseau sous-jacents.
Le stockage de données dans Azure Synapse est automatiquement sauvegardé avec des captures instantanées. Les captures instantanées sont une fonctionnalité intégrée du service qui crée des points de restauration. Il n’est pas nécessaire d’activer cette capacité. Les utilisateurs ne peuvent pas supprimer actuellement les points de restauration automatiques que le service utilise pour maintenir des contrats de niveau de service (SLA) pour la récupération.
Le pool SQL dédié Azure Synapse prend des captures instantanées de l’entrepôt de données à longueur de journée en créant des points de restauration qui restent disponibles pendant sept jours. Cette période de conservation ne peut pas être modifiée. Azure Synapse prend en charge un objectif de point de récupération de huit heures. Vous pouvez restaurer votre entrepôt de données dans la région primaire à partir de n’importe quelle capture instantanée prise au cours des sept derniers jours. Si vous avez besoin de sauvegardes plus précises, vous pouvez utiliser une autre option définie par l’utilisateur.
Types de tables Teradata non pris en charge
Teradata prend en charge des types de tables spéciaux pour les données temporelles et de séries chronologiques. La syntaxe et certaines des fonctions de ces types de tables ne sont pas directement prises en charge dans Azure Synapse. Toutefois, vous pouvez migrer les données dans une table standard dans Azure Synapse en les mappant avec les types de données appropriés et avec l’indexation ou le partitionnement de la colonne date/heure.
Conseil
Les tables standard dans Azure Synapse peuvent prendre en charge les données temporelles et de séries chronologiques Teradata ayant migré.
Teradata implémente la fonctionnalité de requête temporelle via la réécriture de requête pour ajouter des filtres dans une requête temporelle afin de limiter la plage de dates applicable. Si vous envisagez de migrer cette fonctionnalité à partir de l’environnement Teradata source, ajoutez le filtrage supplémentaire dans les requêtes temporelles pertinentes.
L’environnement Azure prend en charge les insights de série chronologique pour l’analytique complexe sur les données de série chronologique à grande échelle. Cette fonctionnalité est destinée aux applications d’analyse des données IoT.
Différences de syntaxe SQL DML
Il existe des différences de syntaxe DML (SQL Data Manipulation Language) entre Teradata SQL et Azure Synapse T-SQL :
QUALIFY: Teradata prend en charge l’opérateurQUALIFY. Par exemple :SELECT col1 FROM tab1 WHERE col1='XYZ' QUALIFY ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) = 1;L’équivalent dans la syntaxe Azure Synapse est le suivant :
SELECT * FROM ( SELECT col1, ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) rn FROM tab1 WHERE col1='XYZ' ) WHERE rn = 1;Date arithmétique : Azure Synapse comporte des opérateurs tels que
DATEADDetDATEDIFFqui peuvent être utilisés sur les champsDATEouDATETIME. Teradata prend en charge la soustraction directe des dates, tels queSELECT DATE1 - DATE2 FROM...GROUP BY: pour l’ordinalGROUP BY, fournissez explicitement le nom de colonne T-SQL.LIKE ANY: Teradata prend en charge la syntaxeLIKE ANYtelle que :SELECT * FROM CUSTOMER WHERE POSTCODE LIKE ANY ('CV1%', 'CV2%', 'CV3%');L’équivalent dans la syntaxe Azure Synapse est le suivant :
SELECT * FROM CUSTOMER WHERE (POSTCODE LIKE 'CV1%') OR (POSTCODE LIKE 'CV2%') OR (POSTCODE LIKE 'CV3%');Selon les paramètres système, les comparaisons de caractères dans Teradata peuvent ignorer la casse par défaut. Dans Azure Synapse, les comparaisons de caractères respectent toujours la casse.
Fonctions, procédures stockées, déclencheurs et séquences
Quand vous migrez un entrepôt de données à partir d’un environnement hérité mature comme Teradata, vous devez la plupart du temps migrer d’autres éléments que des tables et vues simples. C’est le cas, par exemple, des fonctions, des procédures stockées, des déclencheurs et des séquences. Vérifiez si les outils dans l’environnement Azure peuvent remplacer les fonctionnalités des fonctions, des procédures stockées et des séquences, car il est généralement plus efficace d’utiliser des outils Azure intégrés que de recoder ces éléments pour Azure Synapse.
Dans le cadre de votre phase de préparation, créez un inventaire des objets qui doivent être migrés, définissez une méthode pour les gérer et allouez les ressources appropriées dans votre plan de migration.
Les partenaire d’intégration de données proposent des outils et des services qui automatisent la migration des fonctions, des procédures stockées et des séquences.
Les sections suivantes décrivent plus en détail la migration des fonctions, des procédures stockées et des séquences.
Fonctions
Comme la plupart des produits de base de données, Teradata prend en charge les fonctions système et les fonctions définies par l’utilisateur dans l’implémentation SQL. Lorsque vous migrez une plateforme de base de données héritée vers Azure Synapse, les fonctions système courantes peuvent généralement être migrées sans modification. D’autres présentent une syntaxe légèrement différente, mais les modifications requises sont automatisables.
Pour les fonctions système Teradata ou les fonctions arbitraires définies par l’utilisateur qui n’ont pas d’équivalent dans Azure Synapse, recodez ces fonctions à l’aide d’un langage d’environnement cible. Azure Synapse utilise le langage Transact-SQL pour implémenter les fonctions définies par l’utilisateur.
Procédures stockées
La plupart des produits de base de données modernes offrent la possibilité de stocker des procédures. À cette fin, Teradata fournit le langage SPL. Une procédure stockée contient généralement les instructions SQL et la logique procédurale et peut retourner des données ou un état.
Azure Synapse prend en charge les procédures stockées à l’aide de T-SQL. Vous devez donc recoder toutes les procédures stockées migrées dans ce langage.
Déclencheurs
Azure Synapse ne prend pas en charge la création de déclencheur, mais cette fonctionnalité peut être implémentée avec Azure Data Factory.
Séquences
Azure Synapse gère les séquences de la même façon que Teradata, et vous pouvez implémenter des séquences à l’aide de colonnes IDENTITY ou de code SQL qui génère le numéro de séquence suivant dans une série. Une séquence fournit des valeurs numériques uniques que vous pouvez utiliser comme valeurs de clé de substitution pour les clés primaires.
Extraire des métadonnées et des données à partir d’un environnement Teradata
Génération de langage de définition de données (Data Definition Language, DDL)
La norme ANSI SQL définit la syntaxe de base pour les commandes DDL (Data Definition Language). Certaines commandes DDL, telles que CREATE TABLE et CREATE VIEW, sont communes à Teradata et Azure Synapse, mais fournissent également des fonctionnalités spécifiques à l’implémentation telles que l’indexation, la distribution des tables et les options de partitionnement.
Vous pouvez modifier les scripts Teradata CREATE TABLE et CREATE VIEW existants pour obtenir les mêmes définitions dans Azure Synapse. Pour ce faire, vous devrez peut-être utiliser des types de données modifiés et supprimer ou modifier des clauses spécifiques à Teradata, telles que FALLBACK.
Toutefois, toutes les informations qui spécifient les définitions actuelles des tables et des vues au sein de l’environnement Teradata existant sont conservées dans les tables du catalogue système. Ces tables sont la meilleure source pour ces informations, car elles sont toujours à jour et complètes. Il peut en effet arriver que la documentation gérée par l’utilisateur ne soit pas synchronisée avec les définitions actuelles des tables.
Dans l’environnement Teradata, les tables de catalogue système spécifient la définition actuelle de la table et de la vue. Contrairement à la documentation gérée par l’utilisateur, les informations du catalogue système sont toujours complètes et synchronisées avec les définitions de table actuelles. En utilisant des vues dans le catalogue, par exemple DBC.ColumnsV, vous pouvez accéder aux informations du catalogue système pour générer des instructions DDL CREATE TABLE qui créent des tables équivalentes dans Azure Synapse.
Conseil
Utilisez les métadonnées Teradata existantes pour automatiser la génération de CREATE TABLE et CREATE VIEW DDL pour Azure Synapse.
Vous pouvez également utiliser des outils de migration tiers et des outils ETL qui traitent les informations du catalogue système pour obtenir des résultats similaires.
Extraction de données à partir de Teradata
Vous pouvez extraire des données de table brutes de tables Teradata vers des fichiers délimités plats, tels que des fichiers CSV, à l’aide d’utilitaires Teradata standard tels que Basic Teradata Query (BTEQ), Teradata FastExport ou Teradata Parallel Transporter (TPT). Utilisez TPT pour extraire les données des tables aussi efficacement que possible. TPT utilise plusieurs flux FastExport parallèles pour atteindre le débit le plus élevé.
Conseil
Utilisez Teradata Parallel Transporter pour extraire les données de façon plus efficace.
Appelez TPT directement à partir d’Azure Data Factory. Il s’agit de l’approche recommandée pour la migration de données d’instances Teradata locales et d’instances Teradata qui s’exécutent dans une machine virtuelle dans l’environnement Azure.
Les fichiers de données extraits doivent contenir du texte délimité au format CSV, ORC (Optimized Row Columnar) ou Parquet.
Pour plus d’informations sur le processus de migration des données et ETL (extraction, transformation et chargement) à partir d’un environnement Teradata, consultez Migration de données, ETL et chargement pour la migration Teradata.
Recommandations en matière de performances pour les migrations Teradata
L’objectif de l’optimisation des performances est de même ou de meilleures performances d’entrepôt de données après la migration vers Azure Synapse.
Conseil
Hiérarchisez les options de paramétrage dans Azure Synapse au début d’une migration.
Différences dans l’approche du réglage des performances
Cette section détaille les différences d’implémentation du réglage du niveau de performance entre Teradata et Azure Synapse.
Options de distribution de données
Pour les performances, Azure Synapse a été conçu avec une architecture à plusieurs nœuds et utilise un traitement parallèle. Pour optimiser les performances des tables dans Azure Synapse, vous pouvez définir une option de distribution de données dans les instructions CREATE TABLE à l’aide de l’instruction DISTRIBUTION. Par exemple, vous pouvez spécifier une table distribuée par hachage, qui distribue les lignes de la table entre les nœuds de calcul à l’aide d’une fonction de hachage déterministe. L’objectif est de réduire la quantité de données déplacées entre les nœuds de traitement lors de l’exécution d’une requête.
Pour des jointures entre deux tables volumineuses, faites une distribution par hachage de l’une des tables, ou idéalement des deux, sur l’une des colonnes de jointure (qui contient une large plage de valeurs pour une distribution plus uniforme). Effectuez le traitement des jointures localement. De cette façon, les lignes de données à joindre seront déjà colocalisées sur le même nœud de traitement.
Azure Synapse prend également en charge les jointures locales entre une petite table et une grande table via la réplication de la petite table. Par exemple, prenons une petite table de dimension et une table de faits volumineuse dans un modèle de schéma en étoile. Azure Synapse pouvez répliquer la plus petite table de dimension sur tous les nœuds pour garantir que la valeur de n’importe quelle clé de jointure pour la table volumineuse a une ligne de dimension correspondante disponible localement. La surcharge de la réplication de table de dimension est relativement faible pour une petite table de dimension. Pour les tables de dimensions volumineuses, l’approche par distribution de hachage est plus appropriée. Pour plus d’informations sur les options de distribution de données, consultez Conseils de conception pour l’utilisation de tables répliquées et Conseils sur la conception de tables distribuées.
Indexation des données
Azure Synapse fournit plusieurs options d’indexation différentes des options d’indexation implémentées dans Teradata. Pour plus d’informations sur les différentes options d’indexation dans Azure Synapse, consultez Index sur les tables de pool SQL dédiées.
Les index existants dans l’environnement Teradata source peuvent fournir des indications utiles sur la façon dont les données sont utilisées et sur les colonnes candidates à l’indexation dans l’environnement Azure Synapse.
Partitionnement des données
Dans un entrepôt de données d’entreprise, les tables de faits peuvent contenir des milliards de lignes. Le partitionnement constitue un moyen d’optimiser la maintenance et les performances d’interrogation de ces tables en les fractionnant en parties séparées afin de réduire la quantité de données traitées. Dans Azure Synapse, l’instruction CREATE TABLE définit la spécification du partitionnement d’une table. Partitionnez uniquement les tables très volumineuses et assurez-vous que chaque partition contient au moins 60 millions de lignes.
Vous ne pouvez utiliser qu’un seul champ par table pour le partitionnement. Ce champ est souvent un champ de date, car de nombreuses requêtes sont filtrées par date ou plage de dates. Vous avez la possibilité de changer le partitionnement d’une table après le chargement initial en recréant la table avec la nouvelle distribution. Pour cela, vous utilisez l’instruction CREATE TABLE AS (ou CTAS). Pour une présentation détaillée du partitionnement dans Azure Synapse, consultez Partitionnement de tables dans un pool SQL dédié.
Statistiques de table de données
Assurez-vous que les statistiques sur les tables de données sont à jour en créant une étape statistiques pour les travaux ETL/ELT.
PolyBase ou COPY INTO pour le chargement des données
PolyBase prend en charge le chargement efficace de grandes quantités de données dans un entrepôt de données à l’aide de flux de chargement parallèles. Pour plus d’informations, consultez Stratégie de chargement des données PolyBase.
COPY INTO prend également en charge l’ingestion de données à haut débit et les opérations suivantes :
Extraction de données à partir de tous les fichiers dans un dossier et ses sous-dossiers.
Extraction de données à partir de plusieurs emplacements dans le même compte de stockage. Vous pouvez spécifier plusieurs emplacements à l’aide de chemins séparés par des virgules.
Azure Data Lake Storage (ADLS) et Stockage Blob Azure.
Formats de fichier CSV, PARQUET et ORC.
Gestion des charges de travail
L’exécution de charges de travail mixtes peut poser des problèmes de ressources sur les systèmes chargés. Un schéma de gestion des charges de travail réussi gère efficacement les ressources, garantit une utilisation hautement efficace des ressources et optimise le retour sur investissement (ROI). La classification de la charge de travail, l’importance de la charge de travail et l’isolation de la charge de travail donnent plus de contrôle sur la façon dont la charge de travail utilise les ressources système.
Le guide de gestion des charges de travail décrit les techniques permettant d’analyser la charge de travail, de gérer et de superviser l’importance de la charge de travail ainsi que les étapes de conversion d’une classe de ressources en groupe de charge de travail. Utilisez le Portail Azure et les requêtes T-SQL sur les DMV pour surveiller la charge de travail pour vous assurer que les ressources applicables sont utilisées efficacement.
Étapes suivantes
Pour en savoir plus sur ETL et le chargement dans le cadre d’une migration Teradata, consultez l’article suivant de cette série : Migration de données, ETL et chargement pour la migration Teradata.