Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Cet article contient des recommandations pour la conception de tables distribuées par hachage et par tourniquet (round robin) dans des pools SQL dédiés.
Cet article suppose que les concepts de distribution et de déplacement de données dans un pool SQL dédié vous sont familiers. Pour plus d'informations, consultez Architecture Azure Synapse Analytics.
Qu’est-ce qu’une table distribuée ?
Une table distribuée apparaît sous la forme d’une table unique, mais les lignes sont en réalité stockées sur 60 distributions. Les lignes sont distribuées avec un algorithme de hachage ou de round-robin.
La distribution par hachage, qui est au cœur de cet article, améliore les performances des requêtes sur des tables de faits volumineuses. La distribution round-robin est utile pour améliorer la vitesse de chargement. Ces choix de conception ont un effet significatif sur l'amélioration des performances de requête et de chargement.
Une autre option de stockage de table est de répliquer une petite table sur tous les nœuds de calcul. Pour plus d’informations, consultez Guide de conception pour les tables répliquées. Pour choisir rapidement parmi les trois options, consultez Tables distribuées dans la vue d’ensemble des tables.
Dans le cadre de la conception d’une table, essayez d’en savoir autant que possible sur vos données et la façon dont elles sont interrogées. Considérez par exemple les questions suivantes :
- Quelle est la taille de la table ?
- Quelle est la fréquence de mise à jour du tableau ?
- Est-ce que je dispose de tables de faits et de dimension dans un pool SQL dédié ?
Distribution par hachage
Une table distribuée par hachage distribue les lignes de la table sur les nœuds de calcul à l’aide d’une fonction de hachage déterministe pour affecter chaque ligne à une distribution.
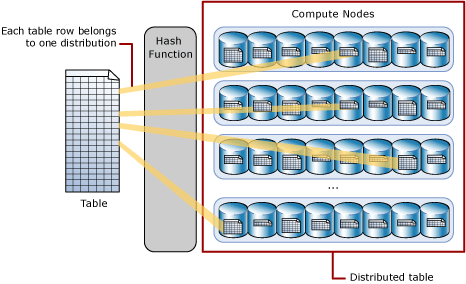
Comme les valeurs identiques sont toujours hachées sur la même distribution, SQL Analytics dispose d'une connaissance intégrée de l'emplacement des lignes. Dans un pool SQL dédié, ces informations sont utilisées pour réduire le déplacement des données pendant les requêtes, ce qui améliore les performances de ces dernières.
Les tables distribuées par hachage fonctionnent correctement pour des tables de faits volumineuses dans un schéma en étoile. Elles peuvent contenir un très grand nombre de lignes et réaliser néanmoins des performances élevées. Certaines considérations sur la conception peuvent vous aider à obtenir les performances que le système distribué doit fournir. Le choix d’une ou de plusieurs colonnes de distribution appropriées est l’une de ces considérations décrite dans cet article.
Envisagez d’utiliser une table distribuée par hachage quand :
- La taille de la table sur le disque est supérieure à 2 Go.
- La table est l’objet d’opérations d’insertion, de mise à jour et de suppression fréquentes.
Distribution par tourniquet
Une table distribuée par tourniquet distribue les lignes de la table uniformément sur toutes les distributions. L’attribution de lignes aux distributions est aléatoire. Contrairement aux tables distribuées par hachage, il n’est pas garanti que les lignes avec des valeurs égales soient affectées à la même distribution.
Par conséquent, le système doit parfois appeler une opération de déplacement des données pour mieux organiser vos données avant de pouvoir résoudre une requête. Cette étape supplémentaire peut ralentir vos requêtes. Par exemple, la jointure d’une table distribuée par tourniquet nécessite généralement un remaniement des lignes, ce qui entraîne une baisse des performances.
Vous pouvez envisager une distribution par tourniquet des données de votre table dans les cas suivants :
- lors de la mise en route sous forme de point de départ simple, puisqu’il s’agit de l’option par défaut ;
- s’il n’existe aucune clé de jointure évidente ;
- s’il n’existe aucune colonne adaptée à la distribution par hachage de la table ;
- si la table ne partage aucune clé de jointure avec d’autres tables ;
- Si la jointure est moins significative que d’autres jointures dans la requête.
- lorsque la table est une table temporaire intermédiaire ;
Le tutoriel Chargement des données des taxis new-yorkais donne un exemple de chargement de données dans une table de mise en lots distribuée par tourniquet (round robin).
Choisir une colonne de distribution
Une table distribuée par hachage a une colonne ou un ensemble de colonnes de distribution correspondant à la clé de hachage. Par exemple, le code suivant crée une table distribuée par hachage avec ProductKey en tant que colonne de distribution.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
La distribution par hachage peut être appliquée à plusieurs colonnes pour une distribution plus uniforme de la table de base. La distribution multicolonne vous permet de choisir jusqu’à huit colonnes pour la distribution. Cela réduit non seulement l’asymétrie des données au fil du temps, mais améliore également les performances des requêtes. Par exemple :
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Note
La distribution multi-colonnes dans Azure Synapse Analytics peut être activée en remplaçant le niveau de compatibilité de la base de données par 50 avec cette commande.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50;Pour plus d’informations sur le paramètre du niveau de compatibilité de la base de données, consultez l’article ALTER DATABASE SCOPED CONFIGURATION. Pour plus d’informations sur la distribution multicolonne, voir CREATE MATERIALIZED VIEW, CREATE TABLE ou CREATE TABLE AS SELECT.
Les données stockées dans les colonnes de distribution peuvent être mises à jour. Les mises à jour des données dans les colonnes de distribution peuvent entraîner une opération de redistribution des données.
Le choix des colonnes de distribution est une décision de conception importante, car les valeurs des colonnes de hachage déterminent la façon dont les lignes sont distribuées. Le meilleur choix dépend de plusieurs facteurs et implique généralement des compromis. Une fois la colonne ou l’ensemble de colonnes de distribution choisi, vous ne pouvez pas le changer. Si vous n’avez pas choisi les meilleures colonnes la première fois, vous pouvez utiliser CREATE TABLE AS SELECT (CTAS) pour recréer la table avec la clé de hachage de distribution souhaitée.
Choisir une colonne de distribution avec des données distribuées de manière uniforme
Pour obtenir des performances optimales, toutes les distributions doivent avoir environ le même nombre de lignes. Quand une ou plusieurs distributions ont un nombre disproportionné de lignes, certaines distributions terminent leur segment de requête parallèle avant les autres. Comme la requête ne peut pas aboutir tant que toutes les distributions n’ont pas terminé le traitement, chaque requête est seulement aussi rapide que la distribution la plus lente.
- L’asymétrie des données signifie que les données ne sont pas réparties uniformément entre les distributions
- Le décalage de traitement signifie que certaines distributions prennent plus de temps que d’autres lors de l’exécution de requêtes parallèles. Cela peut se produire quand les données sont asymétriques.
Pour équilibrer le traitement parallèle, sélectionnez une colonne ou un ensemble de colonnes de distribution qui :
- Possède de nombreuses valeurs uniques. Une ou plusieurs colonnes de distribution peuvent avoir des valeurs dupliquées. Toutes les lignes ayant la même valeur sont affectées à la même distribution. Étant donné qu’il existe 60 distributions, certaines peuvent avoir des valeurs uniques égales à 1 >, tandis que d’autres peuvent se terminer par des valeurs égales à zéro.
- N’a pas de valeurs NULL, ou a uniquement quelques valeurs NULL. Pour prendre un exemple extrême, si toutes les valeurs des colonnes de distribution sont NULLES, toutes les lignes sont affectées à la même distribution. Par conséquent, le traitement des requêtes est limité à une distribution et ne bénéficie pas du traitement parallèle.
- N’est pas une colonne de date. Toutes les données correspondant à la même date sont situées dans la même distribution, ou clusterisent les enregistrements par date. Si plusieurs utilisateurs effectuent tous un filtrage à la même date (par exemple la date du jour), seule 1 des 60 distributions effectue tout le travail de traitement.
Choisir une colonne de distribution qui réduit le déplacement des données
Pour obtenir un résultat de requête correct, les requêtes peuvent déplacer des données d’un nœud de calcul à un autre. Le déplacement des données se produit généralement quand les requêtes possèdent des jointures et agrégations sur des tables distribuées. Le choix d’une colonne ou d’un ensemble de colonnes de distribution permettant de réduire le déplacement des données est l’une des stratégies les plus importantes pour l’optimisation des performances de votre pool SQL dédié.
Pour réduire le déplacement des données, sélectionnez une colonne ou un ensemble de colonnes de distribution qui :
- Est utilisée dans les clauses
JOIN,GROUP BY,DISTINCT,OVERetHAVING. Quand deux tables de faits volumineuses ont des jointures fréquentes, la distribution des deux tables sur l’une des colonnes de jointure permet d’améliorer les performances des requêtes. Quand une table n’est pas utilisée dans les jointures, distribuez-la sur une colonne ou un ensemble de colonnes qui figure fréquemment dans la clauseGROUP BY. - N’est pas utilisée dans les clauses
WHERE. Lorsque la clause d’une requêteWHEREet les colonnes de distribution de la table se trouvent sur la même colonne, la requête peut rencontrer une asymétrie des données élevée, ce qui entraîne une baisse de la charge de traitement sur seulement quelques distributions. Cela affecte les performances des requêtes. Dans l’idéal, plusieurs distributions partagent la charge de traitement. - N’est pas une colonne de date. Les clauses
WHEREfiltrent souvent par date. Dans ce cas, l’ensemble du traitement peut être exécuté sur quelques distributions uniquement et affecter ainsi les performances de la requête. Dans l’idéal, plusieurs distributions partagent la charge de traitement.
Une fois que vous avez conçu une table distribuée par hachage, l’étape suivante consiste à charger des données dans la table. Pour obtenir des conseils de chargement, consultez Vue d’ensemble du chargement.
Comment savoir si votre distribution est judicieuse
Une fois que les données sont chargées dans une table distribuée par hachage, vérifiez si les lignes sont réparties uniformément entre les 60 distributions. Les lignes par distribution peuvent varier jusqu’à 10 % sans un impact perceptible sur les performances.
Tenez compte des façons suivantes pour évaluer vos colonnes de distribution.
Déterminer si la table présente une asymétrie des données
Un moyen rapide de rechercher une asymétrie des données consiste à utiliser DBCC PDW_SHOWSPACEUSED. Le code SQL suivant retourne le nombre de lignes de la table qui sont stockées dans chacune des 60 distributions. Pour obtenir des performances équilibrées, les lignes de votre table distribuée doivent être partagées uniformément entre toutes les distributions.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Pour identifier les tables avec une asymétrie des données supérieure à 10 % :
- Créez la vue
dbo.vTableSizesqui figure dans l’article Vue d’ensemble des tables. - Exécutez la requête suivante :
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Vérifier les plans de requête pour le déplacement des données
Un ensemble de colonnes de distribution approprié permet de réduire au minimum le déplacement des données lors des jointures et des agrégations. Cela affecte la façon dont les jointures doivent être écrites. Pour minimiser le déplacement des données lors d’une jointure entre deux tables distribuées par hachage, l’une des colonnes de la jointure doit se trouver dans la ou les colonnes de distribution. Lors de la jointure de deux tables distribuées par hachage sur une colonne de distribution du même type de données, la jointure ne nécessite aucun déplacement des données. Les jointures peuvent utiliser des colonnes supplémentaires sans entraîner de déplacement des données.
Pour éviter le déplacement des données au cours d’une jointure :
- Les tables impliquées dans la jointure doivent être réparties par hachage sur l’une des colonnes participant à la jointure.
- Les types de données des colonnes de jointure doivent être identiques dans les deux tables.
- Les colonnes doivent être jointes avec un opérateur d’égalité.
- Le type de jointure ne peut pas être un
CROSS JOIN.
Pour savoir si les requêtes subissent un déplacement des données, vous pouvez examiner le plan de requête.
Résoudre un problème de colonne de distribution
Il n’est pas nécessaire de résoudre tous les cas d’asymétrie des données. La distribution de données consiste à trouver le juste équilibre entre la réduction de l’asymétrie des données et la réduction du déplacement des données. Il n’est pas toujours possible de réduire à la fois l’asymétrie des données et le déplacement des données. L’avantage d’un déplacement des données minimal peut parfois compenser l’effet d’une asymétrie des données.
Pour déterminer si vous devez résoudre un décalage des données dans une table, vous devez comprendre au mieux les volumes de données et les requêtes dans votre charge de travail. Vous pouvez utiliser les étapes décrites dans l’article Surveillance des requêtes pour monitorer l’effet de l’asymétrie sur les performances des requêtes. En particulier, recherchez la durée de l’exécution des requêtes volumineuses sur les distributions individuelles.
Comme vous ne pouvez pas modifier les colonnes de distribution sur une table existante, la manière classique de résoudre l’asymétrie des données consiste à recréer la table avec des colonnes de distribution différentes.
Recréer la table avec un nouvel ensemble de colonnes de distribution
Cet exemple utilise CREATE TABLE AS SELECT pour recréer une table avec des colonnes de distribution par hachage différentes.
Utilisez d’abord CREATE TABLE AS SELECT (CTAS) pour créer une autre table avec une autre clé. Recréez ensuite les statistiques et enfin permutez les tables en les renommant.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Contenu connexe
Pour créer une table distribuée, utilisez l’une de ces instructions :