Apache Spark Advisor dans Azure Synapse Analytics (préversion)
Le conseiller Apache Spark analyse les commandes et le code exécutés par Spark et affiche des conseils en temps réel pour les exécutions de notebooks. Le conseiller Spark a des modèles intégrés pour aider les utilisateurs à éviter les erreurs courantes, à proposer des recommandations pour l’optimisation du code, à effectuer une analyse des erreurs et à localiser la cause racine des échecs.
Conseils intégrés
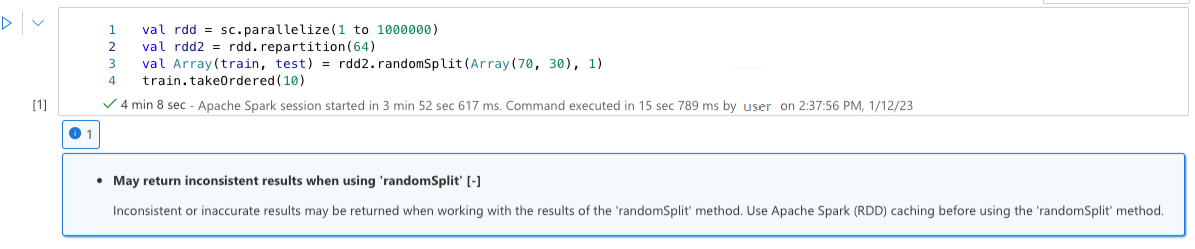
Peut retourner des résultats incohérents lors de l’utilisation de « randomSplit »
Des résultats incohérents ou incorrects peuvent être retournés lors de l’utilisation des résultats de la méthode « randomSplit ». Utilisez la mise en cache d’Apache Spark (RDD) avant d’utiliser la méthode « randomSplit ».
La méthode randomSplit() équivaut à effectuer des exemples() sur votre trame de données plusieurs fois, avec chaque exemple de refetching, de partitionnement et de tri de votre trame de données dans des partitions. La distribution de données entre les partitions et l’ordre de tri est importante pour randomSplit() et sample(). Si les modifications apportées à la récupération de données peuvent être modifiées, il peut y avoir des doublons ou des valeurs manquantes entre les fractionnements et le même échantillon à l’aide de la même semence peut produire des résultats différents.
Ces incohérences peuvent ne pas se produire sur chaque exécution, mais pour les éliminer complètement, mettre en cache votre trame de données, les repartitionner sur une ou plusieurs colonnes ou appliquer des fonctions d’agrégation telles que groupBy.
Le nom de la table/affichage est déjà utilisé
Une vue existe déjà avec le même nom que la table créée, ou une table existe déjà avec le même nom que la vue créée. Lorsque ce nom est utilisé dans les requêtes ou les applications, seul l’affichage est retourné, quel que soit le premier créé. Pour éviter les conflits, renommez la table ou la vue.
Impossible de reconnaître un conseil
La requête sélectionnée contient un indicateur qui n’est pas reconnu. Vérifiez que le conseil est correctement orthographié.
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Impossible de trouver un ou plusieurs noms de relation spécifiés
Impossible de trouver les relations spécifiées dans l’indicateur. Vérifiez que les relations sont correctement orthographiées et accessibles dans l’étendue de l’indicateur.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Un indicateur dans la requête empêche l’application d’un autre indicateur
La requête sélectionnée contient un indicateur qui empêche l’application d’un autre indicateur.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Activer « spark.advise.divisionExprConvertRule.enable » pour réduire la propagation d’erreurs d’arrondi
Cette requête contient l’expression avec un type double. Nous vous recommandons d’activer la configuration « spark.advise.divisionExprConvertRule.enable », ce qui peut vous aider à réduire les expressions de division et à réduire la propagation d’erreurs d’arrondi.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Activer « spark.advise.nonEqJoinConvertRule.enable » pour améliorer les performances des requêtes
Cette requête contient une jointure longue en raison d’une condition « Ou » dans la requête. Nous vous recommandons d’activer la configuration « spark.advise.nonEqJoinConvertRule.enable », qui peut vous aider à convertir la jointure déclenchée par la condition « Or » en SMJ ou BHJ pour accélérer cette requête.
Optimiser la table delta avec le compactage de petits fichiers
Cette requête se trouve sur une table delta avec de nombreux petits fichiers. Pour améliorer les performances des requêtes, exécutez la commande OPTIMIZE sur la table delta. Vous trouverez plus d’informations dans cet article.
Optimiser la table Delta avec ZOrder
Cette requête se trouve sur une table Delta et contient un filtre hautement sélectif. Pour améliorer les performances des requêtes, exécutez la commande OPTIMIZE ZORDER BY sur la table delta. Vous trouverez plus d’informations dans cet article.
Expérience de l'utilisateur
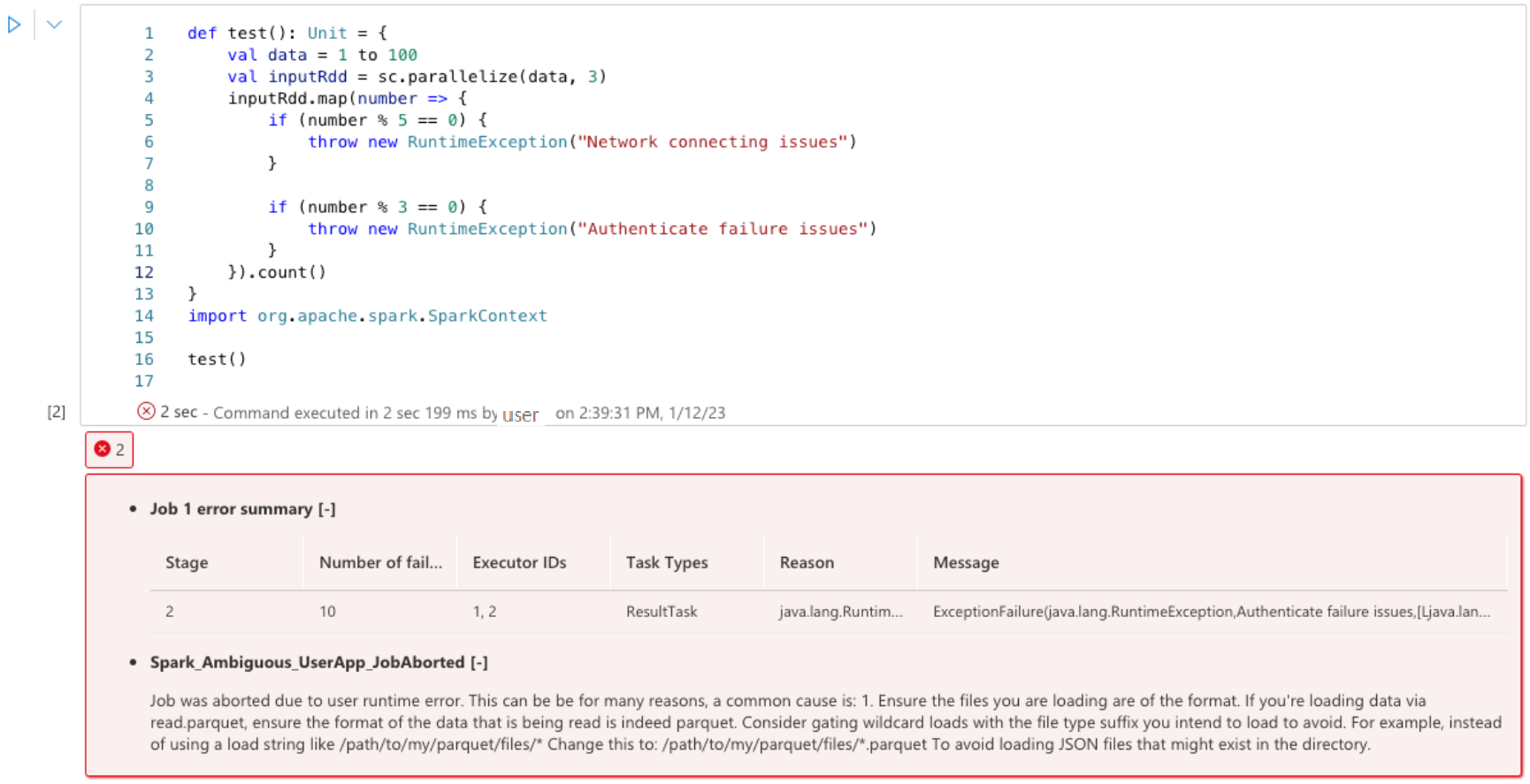
Le conseiller Apache Spark affiche les conseils, y compris les informations, les avertissements et les erreurs, dans sortie de la cellule notebook en temps réel.
Informations
Avertissement

Erreurs
Étapes suivantes
Pour plus d’informations sur l’analyse d’applications Apache Spark, consultez l’article Analyser des applications Apache Spark à l’aide de Synapse Studio.
Pour plus d’informations sur la création d’un notebook, consultez Procédure d’utilisation des notebooks Synapse.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour