Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment accéder à une base de données Azure Data Explorer à partir de Synapse Studio à l’aide d’Apache Spark pour Azure Synapse Analytics.
Prérequis
- Créez un cluster et une base de données Azure Data Explorer.
- Disposez d’un espace de travail Azure Synapse Analytics ou créez un nouvel espace de travail en suivant les étapes décrites dans Démarrage rapide : Créer un espace de travail Azure Synapse.
- Disposez d’un pool Apache Spark ou créez un nouveau pool en suivant les étapes décrites dans Démarrage rapide : Créer un pool Apache Spark à l’aide du portail Azure.
- Créez une application Microsoft Entra en approvisionnant une application Microsoft Entra.
- Accordez à votre application Microsoft Entra l’accès à votre base de données en suivant les étapes décrites dans Gérer les autorisations de bases de données d’Azure Data Explorer.
Accéder à Synapse Studio
Dans un espace de travail Azure Synapse, sélectionnez Lancer Synapse Studio. Dans la page d’accueil de Synapse Studio, sélectionnez Données pour accéder à l’Explorateur d’objets de données.
Connecter une base de données Azure Data Explorer à un espace de travail Azure Synapse
La connexion d’une base de données Azure Data Explorer à un espace de travail s’effectue via un service lié. Avec un service lié Azure Data Explorer, vous pouvez parcourir et explorer des données, ainsi que lire et écrire à partir d’Apache Spark pour Azure Synapse. Vous pouvez également exécuter des travaux d’intégration dans un pipeline.
À partir de l’Explorateur d’objets de données, procédez comme suit pour connecter directement un cluster Azure Data Explorer :
Sélectionnez l’icône + à proximité de Données.
Sélectionnez Se connecter pour vous connecter à des données externes.
Sélectionnez Azure Data Explorer (Kusto) .
Sélectionnez Continuer.
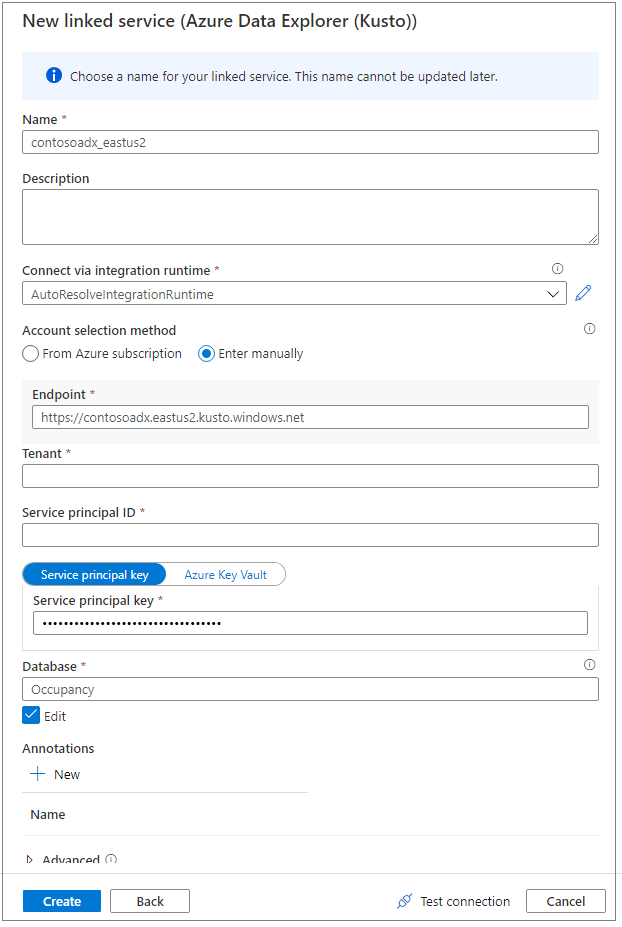
Utilisez un nom convivial pour nommer le service lié. Le nom sera affiché dans l’Explorateur d’objets de données et les runtimes Azure Synapse l’utiliseront pour se connecter à la base de données.
Sélectionnez le cluster Azure Data Explorer dans votre abonnement ou entrez l’URI.
Entrez l’ID du principal de service et la clé du principal de service. Vérifiez que ce principal de service dispose d’un accès en affichage à la base de données pour l’opération de lecture et d’un accès à l’ingéreur pour l’ingestion des données.
Entrez le nom de la base de données Azure Data Explorer.
Sélectionnez Tester la connexion pour vérifier que vous disposez des autorisations appropriées.
Cliquez sur Créer.
Remarque
(Facultatif) L’option Tester la connexion ne valide pas l’accès en écriture. Assurez-vous que votre ID de principal de service dispose d’un accès en écriture à la base de données Azure Data Explorer.
Les clusters et bases de données Azure Data Explorer apparaissent sous l’onglet Lié dans la section Azure Data Explorer.

Avant de pouvoir interagir avec le service lié à partir d’un notebook, vous devez le publier dans l’espace de travail. Cliquez sur Publier dans la barre d’outils, vérifiez les changements en attente et cliquez sur OK.
Remarque
Dans la version actuelle, les objets de bases de données sont renseignés en fonction des autorisations de votre compte Microsoft Entra sur les bases de données Azure Data Explorer. Lorsque vous exécutez les travaux d’intégration ou les notebooks Apache Spark, les informations d’identification du service de liaison sont utilisées (par exemple, le principal de service).
Interagir rapidement avec des actions générées par le code
Lorsque vous cliquez avec le bouton droit sur une base de données ou une table, une liste d’exemples de notebooks Spark s’affiche. Sélectionnez une option pour lire, écrire ou diffuser en continu des données vers Azure Data Explorer.

Voici un exemple de lecture de données. Attachez le notebook à votre pool Spark et exécutez la cellule.

Remarque
La première exécution peut prendre plus de trois minutes pour lancer la session Spark. Les exécutions suivantes seront beaucoup plus rapides.
Limites
Le connecteur Azure Data Explorer n’est actuellement pas pris en charge avec les réseaux virtuels managés Azure Synapse.