Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Azure Synapse Analytics offre différents moteurs d’analytique pour vous aider à ingérer, transformer, modéliser, analyser et distribuer vos données. Un pool Apache Spark fournit des fonctionnalités de calcul Big Data open source. Après avoir créé un pool Apache Spark dans votre espace de travail Synapse, les données peuvent être chargées, modélisées, traitées et distribuées pour accélérer l’analyse.
Dans ce guide de démarrage rapide, vous allez apprendre à utiliser le portail Azure pour créer un pool Apache Spark dans un espace de travail Synapse.
Important
La facturation des instances Spark est calculée au prorata des minutes écoulées, que vous les utilisiez ou non. Veillez à arrêter votre instance Spark une fois que vous avez fini de l’utiliser, ou définissez un délai d’expiration court. Pour plus d’informations, consultez la section Nettoyer les ressources de cet article.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Conditions préalables
- Vous aurez besoin d’un abonnement Azure. Si besoin, Créez un compte Azure gratuit
- Vous utiliserez l'espace de travail Synapse.
Se connecter au portail Azure
Connectez-vous au portail Azure
Accéder à l’espace de travail Synapse
Accédez à l’espace de travail Synapse dans lequel vous allez créer le pool Apache Spark en saisissant le nom du service (ou directement le nom de la ressource) dans la barre de recherche.
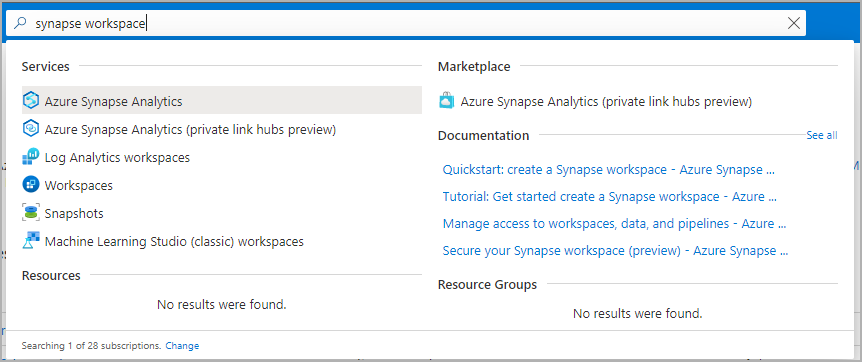
Dans la liste des espaces de travail, saisissez le nom (ou une partie du nom) de l’espace de travail à ouvrir. Pour cet exemple, nous utilisons un espace de travail nommé contosoanalytics.


Créer un pool Apache Spark
Dans l’espace de travail Synapse dans lequel vous souhaitez créer le pool Apache Spark, sélectionnez Nouveau pool Apache Spark.

Sous l’onglet Informations de base, entrez ce qui suit :
Réglage Valeur suggérée Description Nom du pool Apache Spark Un nom de pool valide, comme contososparkIl s’agit du nom du pool Apache Spark. Taille du nœud Petite (4 processeurs virtuels/32 Go) Définissez ce paramètre sur la plus petite taille pour réduire les coûts de ce guide de démarrage rapide. Autoscale Handicapé Ce démarrage rapide ne nécessite pas de mise à l’échelle automatique Nombre de nœuds 5 Utiliser une petite taille afin de limiter les coûts pour ce démarrage rapide. 
Important
Il existe des limitations spécifiques concernant les noms que les pools Apache Spark peuvent utiliser. Les noms doivent contenir uniquement des lettres ou des chiffres, ne doivent pas comporter plus de 15 caractères, doivent commencer par une lettre, ne pas contenir de mots réservés et être uniques dans l’espace de travail.
Sélectionnez Suivant : paramètres supplémentaires et passez en revue les paramètres par défaut. Ne modifiez aucun paramètre par défaut.

Sélectionnez Suivant : balises. Envisagez d’utiliser des étiquettes Azure. Par exemple, l’étiquette « Owner » ou « CreatedBy » pour identifier qui a créé la ressource, et l’étiquette « Environment » pour identifier si cette ressource est en production, développement, etc. Pour plus d’informations, consultez Développer une stratégie de nommage et d’étiquetage des ressources Azure.

Sélectionnez Vérifier + créer.
Vérifiez que les détails sont corrects en fonction de ce qui a été entré précédemment, puis sélectionnez Créer.

À ce stade, le flux d'approvisionnement des ressources va commencer, et il indiquera lorsqu'il sera terminé.

Une fois l’approvisionnement terminé, la navigation vers l’espace de travail affiche une nouvelle entrée pour le pool Apache Spark nouvellement créé.

À ce stade, il n’existe aucune ressource en cours d’exécution, sans frais pour Spark, vous avez créé des métadonnées sur les instances Spark que vous souhaitez créer.







Nettoyer les ressources
Les étapes suivantes suppriment le pool Apache Spark de l’espace de travail.
Avertissement
La suppression d’un pool Apache Spark supprime le moteur d’analyse de l’espace de travail. Il n’est plus possible de se connecter au pool, et toutes les requêtes, pipelines et notebooks qui utilisent ce pool Apache Spark ne fonctionneront plus.
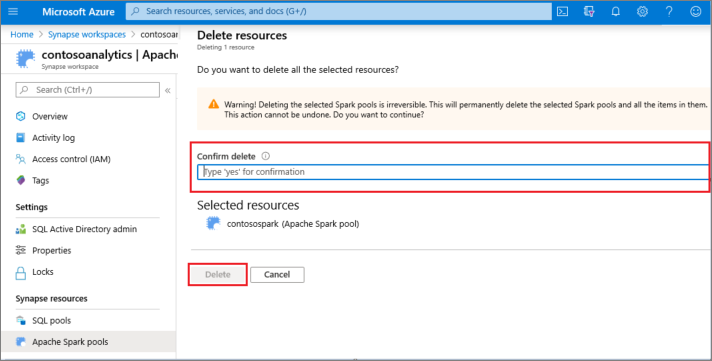
Si vous souhaitez supprimer le pool Apache Spark, procédez comme suit :
- Accédez au volet Pools Apache Spark dans l’espace de travail.
- Sélectionnez le pool Apache Spark à supprimer (dans ce cas, contosospark).
- Sélectionnez Supprimer.

- Confirmez la suppression, puis sélectionnez Bouton Supprimer .
- Une fois le processus terminé, le pool Apache Spark ne figure plus dans la liste des ressources de l’espace de travail.
