Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Synapse Analytics offre différents moteurs d’analytique pour vous aider à ingérer, transformer, modéliser et analyser vos données. Un pool SQL dédié offre des fonctionnalités de calcul et de stockage basées sur T-SQL. Après avoir créé un pool SQL dédié dans votre espace de travail Synapse, les données peuvent être chargées, modélisées, traitées et fournies pour obtenir des insights analytiques plus rapides.
Dans ce guide de démarrage rapide, vous allez apprendre à charger des données d’Azure SQL Database dans Azure Synapse Analytics. Vous pouvez procéder de même pour copier des données à partir d’autres types de banques de données. Ce flux similaire s’applique également à la copie de données pour d’autres sources et récepteurs.
Prerequisites
- Abonnement Azure : si vous n’avez pas d’abonnement Azure, créez un compte Azure gratuit avant de commencer.
- Espace de travail Azure Synapse : Créez un espace de travail Synapse à l’aide du portail Azure en suivant les instructions de démarrage rapide : Créer un espace de travail Synapse.
- Azure SQL Database : ce tutoriel copie les données de l’échantillon de jeu de données Adventure Works LT dans Azure SQL Database. Vous pouvez créer cet échantillon de base de données dans SQL Database en suivant les instructions données dans Création d’un échantillon de base de données dans Azure SQL Database. Vous pouvez également utiliser d’autres magasins de données en suivant des étapes similaires.
- Compte de stockage Azure : Le stockage Azure est utilisé comme zone d'intermédiaire dans l’opération de copie. Si vous ne possédez pas de compte de stockage Azure, consultez les instructions dans Créer un compte de stockage.
- Azure Synapse Analytics : vous utilisez un pool SQL dédié comme magasin de données récepteur. Si vous n’avez pas d’instance Azure Synapse Analytics, consultez Créer un pool SQL dédié pour en créer un.
Accédez à Synapse Studio
Une fois votre espace de travail Synapse créé, vous avez deux façons d’ouvrir Synapse Studio :
- Ouvrez votre espace de travail Synapse dans le portail Azure. Sélectionnez Ouvrir sur la carte Ouvrir Synapse Studio dans la section Démarrage.
- Ouvrez Azure Synapse Analytics et connectez-vous à votre espace de travail.
Dans ce guide de démarrage rapide, nous utilisons l’espace de travail nommé « adftest2020 » comme exemple. Il vous accède automatiquement à la page d’accueil de Synapse Studio.
Créez des services liés
Dans Azure Synapse Analytics, un service lié est l’endroit où vous définissez vos informations de connexion à d’autres services. Dans cette section, vous allez créer les deux types suivants de services liés : Azure SQL Database et Azure Data Lake Storage Gen2 (ADLS Gen2).
Dans la page d’accueil de Synapse Studio, sélectionnez l’onglet Gérer dans le volet de navigation gauche.
Sous Connexions externes, sélectionnez Services liés.
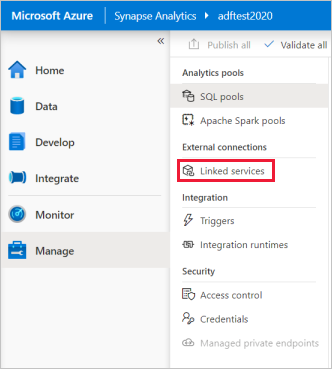
Pour ajouter un service lié, sélectionnez Nouveau.
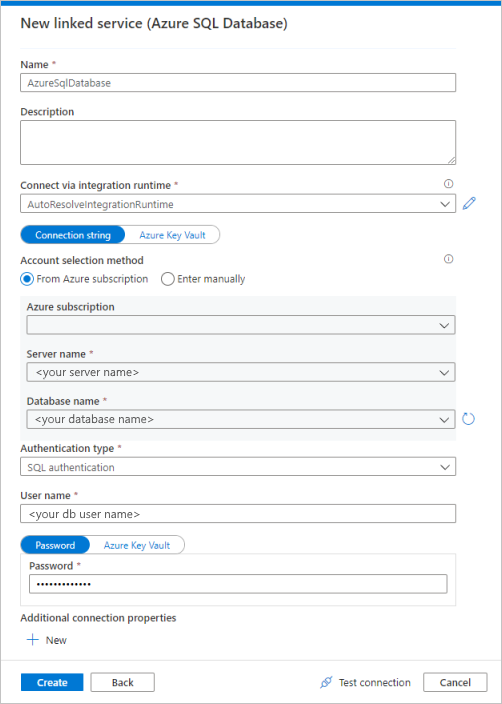
Sélectionnez Azure SQL Database dans la galerie, puis sélectionnez Continuer. Vous pouvez taper « sql » dans la zone de recherche pour filtrer les connecteurs.

Dans la page Nouveau service lié, sélectionnez le nom de votre serveur et le nom de la base de données dans la liste déroulante, puis spécifiez le nom d’utilisateur et le mot de passe. Cliquez sur Tester la connexion pour valider les paramètres, puis sélectionnez Créer.
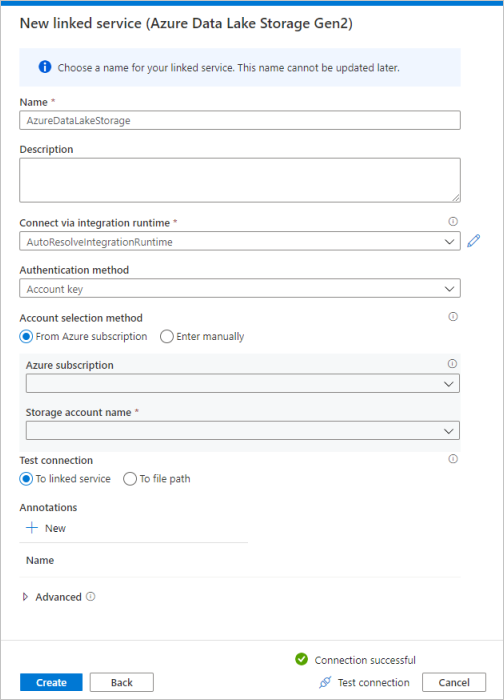
Répétez les étapes 3 à 4, mais sélectionnez Azure Data Lake Storage Gen2 à la place dans la galerie. Dans la page Nouveau service lié, sélectionnez le nom de votre compte de stockage dans la liste déroulante. Cliquez sur Tester la connexion pour valider les paramètres, puis sélectionnez Créer.
Créer une chaîne de traitement
Un pipeline contient le flux logique pour une exécution d’un ensemble d’activités. Dans cette section, vous allez créer un pipeline contenant une activité de copie qui ingère des données d’Azure SQL Database dans un pool SQL dédié.
Accédez à l’onglet Intégrer . Sélectionnez l’icône plus en regard de l’en-tête pipelines, puis sélectionnez Pipeline.
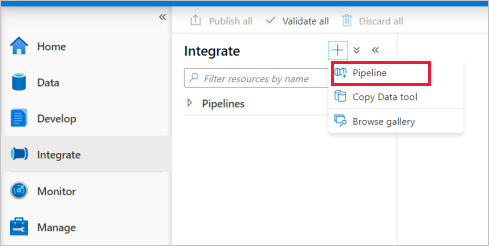
Sous Déplacer et transformer dans le volet Activités , faites glisser Copier des données sur le canevas du pipeline.
Sélectionnez l’activité de copie et accédez à l’onglet Source. Sélectionnez Nouveau pour créer un jeu de données source.
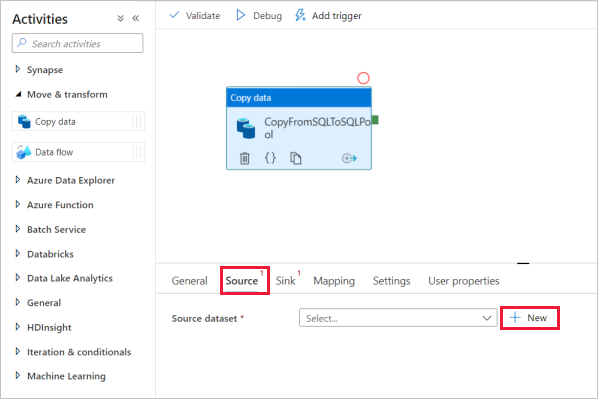
Sélectionnez Azure SQL Database comme magasin de données, puis continuez.
Dans le volet Définir les propriétés , sélectionnez le service lié Azure SQL Database que vous avez créé à l’étape précédente.
Sous Nom de table, sélectionnez un exemple de table à utiliser dans l’activité de copie suivante. Dans ce guide de démarrage rapide, nous utilisons la table « SalesLT.Customer » comme exemple.
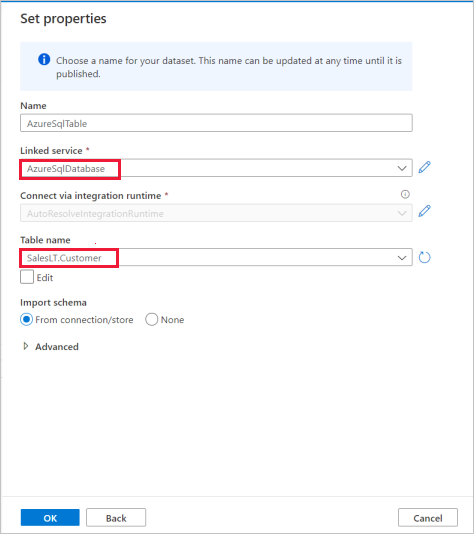
Quand vous avez terminé, sélectionnez OK.
Sélectionnez l’activité de copie et accédez à l’onglet Récepteur. Sélectionnez Nouveau pour créer un jeu de données récepteur.
Sélectionnez un pool SQL dédié Azure Synapse comme magasin de données et sélectionnez Continuer.
Dans le volet Définir les propriétés , sélectionnez le pool SQL Analytics que vous avez créé à l’étape précédente. Si vous écrivez dans une table existante, sous Nom de table , sélectionnez-la dans la liste déroulante. Sinon, cochez « Modifier » et entrez le nom de votre nouvelle table. Quand vous avez terminé, sélectionnez OK.
Pour les paramètres du jeu de données récepteur, activez Créer automatiquement une table dans le champ Option de table.
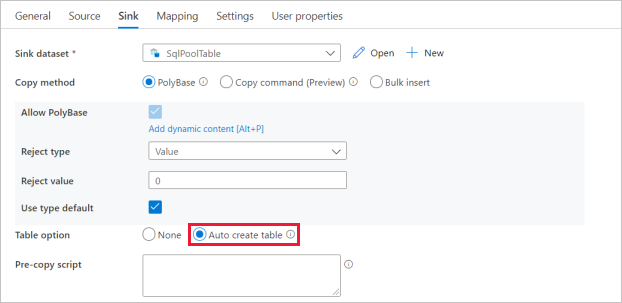
Dans la page Paramètres, cochez la case pour Activer la mise en scène. Cette option s’applique si vos données sources ne sont pas compatibles avec PolyBase. Dans la section Paramètres intermédiaires , sélectionnez le service lié Azure Data Lake Storage Gen2 que vous avez créé à l’étape précédente en tant que stockage intermédiaire.
Le stockage est utilisé pour les données en préproduction avant leur chargement dans Azure Synapse Analytics avec PolyBase. Une fois la copie terminée, les données intermédiaires dans Azure Data Lake Storage Gen2 sont automatiquement nettoyées.
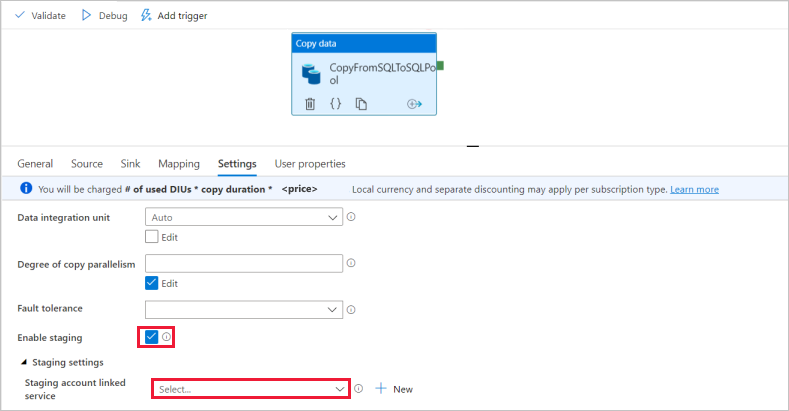
Pour valider le pipeline, sélectionnez Valider dans la barre d’outils. Vous voyez le résultat de la validation du pipeline sur le côté droit de la page.
Déboguer et publier le pipeline
Une fois que vous avez terminé de configurer votre pipeline, vous pouvez exécuter une exécution de débogage avant de publier vos artefacts pour vérifier que tout est correct.
Pour déboguer le pipeline, sélectionnez Déboguer dans la barre d’outils. L’état d’exécution du pipeline apparaît dans l’onglet Sortie au bas de la fenêtre.
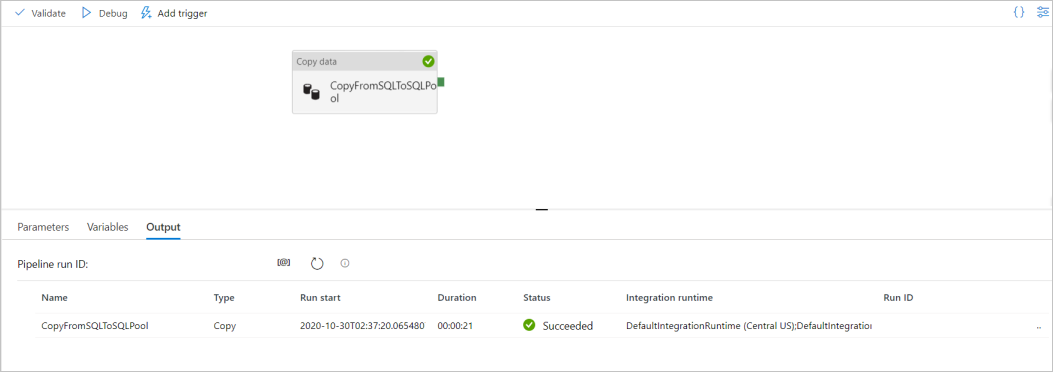
Une fois l’exécution du pipeline réussie, dans la barre d’outils supérieure, sélectionnez Publier tout. Cette action publie des entités (jeux de données et pipelines) que vous avez créées dans le service Synapse Analytics.
Patientez jusqu’à voir le message Publication réussie. Pour afficher les messages de notification, sélectionnez le bouton de cloche en haut à droite.
Déclencher et surveiller le pipeline
Dans cette section, vous déclenchez manuellement le pipeline publié à l’étape précédente.
Sélectionnez Ajouter déclencheur dans la barre d’outils, puis Déclencher maintenant. Dans la page Exécution du pipeline, sélectionnez OK.
Accédez à l’onglet Moniteur situé dans la barre latérale gauche. Vous voyez un pipeline qui est déclenché par un déclencheur manuel.
Une fois l’exécution du pipeline terminée, sélectionnez le lien sous la colonne Nom du pipeline pour afficher les détails de l’exécution de l’activité ou réexécuter le pipeline. Dans cet exemple, il n’y a qu’une seule activité, vous ne voyez donc qu’une seule entrée dans la liste.
Pour plus de détails sur l’opération de copie, sélectionnez le lien Détails (icône en forme de lunettes) dans la colonne Nom de l’activité. Vous pouvez suivre les informations détaillées comme le volume de données copiées à partir de la source dans le récepteur, le débit des données, les étapes d’exécution avec une durée correspondante et les configurations utilisées.
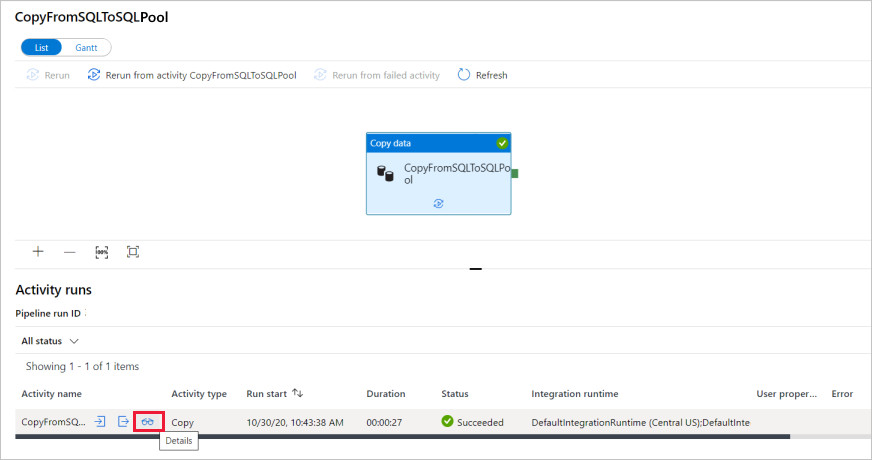
Pour revenir à l’affichage des exécutions du pipeline, sélectionnez le lien Toutes les exécutions de pipelines affiché en haut de la fenêtre. Sélectionnez Actualiser pour actualiser la liste.
Vérifiez que vos données sont correctement écrites dans le pool SQL dédié.
Étapes suivantes
Lisez l’article suivant pour en savoir plus sur la prise en charge d’Azure Synapse Analytics :