Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Cet article explique comment estimer et gérer les coûts du pool SQL serverless dans Azure Synapse Analytics :
- Estimer la quantité de données traitées avant d’émettre une requête
- Utiliser la fonctionnalité de contrôle des coûts pour définir le budget
Comprenez que les coûts du pool SQL serverless dans Azure Synapse Analytics ne sont qu’une partie des coûts mensuels dans votre facture Azure. Si vous utilisez d’autres services Azure, vous êtes facturé pour tous les services et ressources Azure utilisés dans votre abonnement Azure, y compris les services tiers. Cet article explique comment planifier et gérer les coûts pour le pool SQL serverless dans Azure Synapse Analytics.
Données traitées
Les données traitées sont la quantité de données que le système stocke temporairement pendant l’exécution d’une requête. Les données traitées se composent des quantités suivantes :
- Quantité de données lues à partir du stockage. Ce montant inclut :
- Données lues lors de la lecture des données.
- Données lues lors de la lecture des métadonnées (pour les formats de fichier qui contiennent des métadonnées, telles que Parquet).
- Quantité de données dans les résultats intermédiaires. Ces données sont transférées entre les nœuds pendant l’exécution de la requête. Il inclut le transfert de données vers votre point de terminaison, dans un format non compressé.
- Quantité de données écrites dans le stockage. Si vous utilisez CETAS pour exporter votre jeu de résultats vers le stockage, la quantité de données écrites est ajoutée à la quantité de données traitées pour la partie SELECT de CETAS.
La lecture de fichiers à partir du stockage est hautement optimisée. Le processus utilise :
- La prérécupération (prefetching), susceptible d’ajouter à la quantité de données lues. Si une requête lit un fichier entier, il n’y a pas de surcharge. Si un fichier est lu partiellement, comme dans les requêtes TOP N, un peu plus de données sont lues à l’aide de la prérécupération.
- Analyseur de valeurs séparées par des virgules (CSV) optimisé. Si vous utilisez PARSER_VERSION='2.0' pour lire des fichiers CSV, les quantités de données lues à partir du stockage augmentent légèrement. Un analyseur CSV optimisé lit les fichiers en parallèle, en blocs de taille égale. Ces blocs ne contiennent pas nécessairement des lignes entières. Pour vous assurer que toutes les lignes sont analysées, l’analyseur CSV optimisé lit également de petits fragments de blocs adjacents. Ce processus ajoute une petite quantité de surcharge.
Statistiques
L’optimiseur de requête de pool SQL serverless s’appuie sur des statistiques pour générer des plans d’exécution de requête optimaux. Vous pouvez créer manuellement des statistiques. Sinon, le pool SQL serverless les crée automatiquement. Dans les deux cas, les statistiques sont créées en exécutant une requête distincte qui retourne une colonne spécifique à un taux d’échantillonnage fourni. Cette requête a une quantité associée de données traitées.
Si vous exécutez la même requête ou toute autre requête qui tirerait parti des statistiques créées, les statistiques sont réutilisées si possible. Aucune donnée supplémentaire n’est traitée pour la création de statistiques.
Lorsque des statistiques sont créées pour une colonne Parquet, seule la colonne pertinente est lue à partir de fichiers. Lorsque des statistiques sont créées pour une colonne CSV, les fichiers entiers sont lus et analysés.
Arrondi
La quantité de données traitées est arrondie au mo le plus proche par requête. Chaque requête a un minimum de 10 Mo de données traitées.
Données non traitées
- Métadonnées au niveau du serveur (telles que les connexions, les rôles et les informations d’identification au niveau du serveur).
- Bases de données que vous créez dans votre point de terminaison. Ces bases de données contiennent uniquement des métadonnées (comme les utilisateurs, les rôles, les schémas, les vues, les fonctions table inline [TVFs], les procédures stockées, les informations d’identification délimitées à la base de données, les sources de données externes, les formats de fichiers externes et les tables externes).
- Si vous utilisez l’inférence de schéma, les fragments de fichier sont lus pour déduire les noms de colonnes et les types de données, et la quantité de données lues est ajoutée à la quantité de données traitées.
- Instructions DDL (Data Definition Language), à l’exception de l’instruction CREATE STATISTICS, car elle traite les données du stockage en fonction du pourcentage d’échantillon spécifié.
- Requêtes de métadonnées uniquement.
Réduction de la quantité de données traitées
Vous pouvez optimiser votre quantité de données par requête traitée et améliorer les performances en partitionnant et en convertissant vos données dans un format compressé basé sur des colonnes comme Parquet.
Exemples
Imaginez trois tables.
- La table population_csv est sauvegardée par 5 To de fichiers CSV. Les fichiers sont organisés en cinq colonnes de taille égale.
- La table population_parquet a les mêmes données que la table population_csv. Elle est sauvegardée par 1 To de fichiers Parquet. Ce tableau est inférieur à celui précédent, car les données sont compressées au format Parquet.
- La table very_small_csv est sauvegardée par 100 Ko de fichiers CSV.
Requête 1 : SELECT SUM(population) FROM population_csv
Cette requête lit et analyse des fichiers entiers pour obtenir des valeurs pour la colonne population. Les nœuds traitent les fragments de cette table, et la somme de la population pour chaque fragment est transférée entre les nœuds. La somme finale est transférée vers votre point de terminaison.
Cette requête traite 5 To de données, plus une petite quantité supplémentaire pour transférer les sommes des fragments.
Requête 2 : SELECT SUM(population) FROM population_parquet
Lorsque vous interrogez des formats compressés et basés sur des colonnes comme Parquet, moins de données sont lues que dans la requête 1. Vous voyez ce résultat, car le pool SQL serverless lit une seule colonne compressée au lieu de l’ensemble du fichier. Dans ce cas, 0,2 To de données sont lues. (Cinq colonnes de taille égale sont 0,2 To chacune.) Les nœuds traitent les fragments de cette table, et la somme de la population pour chaque fragment est transférée entre les nœuds. La somme finale est transférée vers votre point de terminaison.
Cette requête traite 0,2 To, plus une petite quantité supplémentaire pour transférer les sommes des fragments.
Requête 3 : SELECT * FROM population_parquet
Cette requête lit toutes les colonnes et transfère toutes les données dans un format non compressé. Si le format de compression est 5:1, la requête traite 6 To, car elle lit 1 To et transfère 5 To de données non compressées.
Requête 4 : SELECT COUNT(*) FROM very_small_csv
Cette requête lit des fichiers entiers. La taille totale des fichiers dans le stockage pour cette table est de 100 Ko. Les nœuds traitent les fragments de cette table et la somme de chaque fragment est transférée entre les nœuds. La somme finale est transférée vers votre point de terminaison.
Cette requête traite un peu plus de 100 Ko de données. La quantité de données traitées pour cette requête est arrondie à 10 Mo, comme spécifié dans la section Arrondi de cet article.
Contrôle des coûts
La fonctionnalité de contrôle des coûts dans le pool SQL serverless vous permet de définir le budget pour la quantité de données traitées. Vous pouvez définir le budget en To des données traitées pour un jour, une semaine et un mois. En même temps, vous pouvez avoir un ou plusieurs budgets définis. Pour configurer le contrôle des coûts pour le pool SQL serverless, vous pouvez utiliser Synapse Studio ou T-SQL.
Configurer le contrôle des coûts pour le pool SQL serverless dans Synapse Studio
Pour configurer le contrôle des coûts pour le pool SQL serverless dans Synapse Studio, accédez à l'élément Gérer dans le menu de gauche, puis sélectionnez l'élément SQL pool sous les pools d'analytique. Lorsque vous pointez sur le pool SQL serverless, vous remarquerez une icône pour le contrôle des coûts. Cliquez sur cette icône.
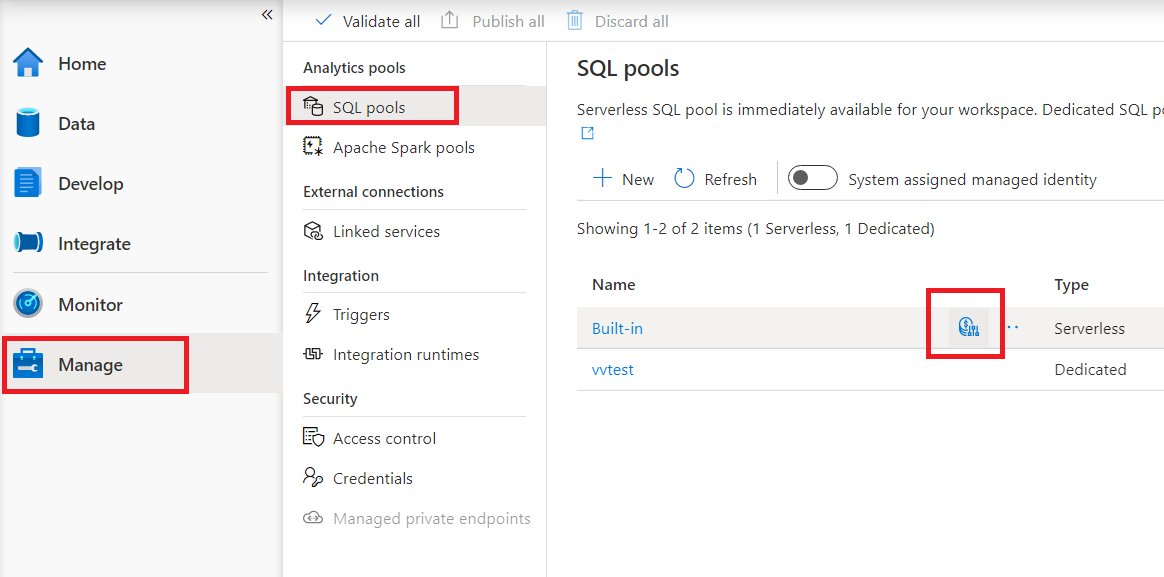
Une fois que vous avez cliqué sur l’icône de contrôle des coûts, une barre latérale s’affiche :
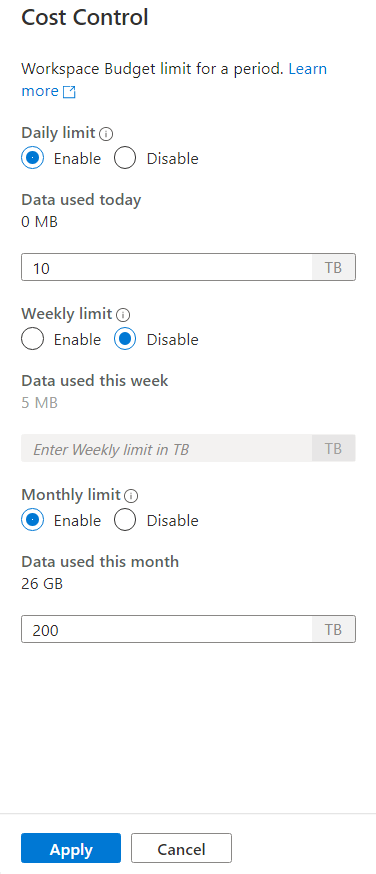
Pour définir un ou plusieurs budgets, cliquez d’abord sur Activer le bouton radio pour un budget que vous souhaitez définir, puis entrer la valeur entière dans la zone de texte. L’unité de la valeur est des TBs. Une fois que vous avez configuré les budgets que vous vouliez cliquer sur le bouton Appliquer en bas de la barre latérale. C’est ça, votre budget est maintenant défini.
Configurer le contrôle des coûts pour le pool SQL serverless dans T-SQL
Pour configurer le contrôle des coûts pour le pool SQL serverless dans T-SQL, vous devez exécuter une ou plusieurs des procédures stockées suivantes.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Pour afficher la configuration actuelle, exécutez l’instruction T-SQL suivante :
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Pour voir la quantité de données traitées pendant le jour, la semaine ou le mois en cours, exécutez l’instruction T-SQL suivante :
SELECT * FROM sys.dm_external_data_processed
Dépassement des limites définies dans le contrôle des coûts
Si une limite est dépassée pendant l’exécution de la requête, la requête n’est pas arrêtée.
Lorsque la limite est dépassée, la nouvelle requête est rejetée avec le message d’erreur qui contient des détails sur la période, la limite définie pour cette période et les données traitées pour cette période. Par exemple, si une nouvelle requête est exécutée, où la limite hebdomadaire est définie sur 1 To et qu’elle a été dépassée, le message d’erreur sera :
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Étapes suivantes
Pour savoir comment optimiser vos requêtes pour les performances, consultez les meilleures pratiques pour le pool SQL serverless.