Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
La fonction OPENROWSET(BULK...) vous permet d’accéder à des fichiers dans Stockage Azure. La fonction OPENROWSET lit le contenu d’une source de données distante (par exemple, un fichier) et retourne le contenu sous la forme d’un ensemble de lignes. Dans la ressource du pool SQL serverless, le fournisseur d’ensembles de lignes en bloc OPENROWSET est accessible en appelant la fonction OPENROWSET et en spécifiant l’option BULK.
Il est possible de référencer la fonction OPENROWSET dans la clause FROM d’une requête comme s’il s’agissait d’un nom de table OPENROWSET. Elle prend en charge les opérations en bloc par l’intermédiaire d’un fournisseur BULK intégré qui permet de lire les données d’un fichier et de les retourner sous la forme d’un ensemble de lignes.
Note
La fonction OPENROWSET n’est pas prise en charge dans le pool SQL dédié.
Source de données
La fonction OPENROWSET dans Synapse SQL lit le contenu des fichiers à partir d’une source de données. La source de données est un compte de stockage Azure et peut être référencée explicitement dans la fonction OPENROWSET ou être déduite de façon dynamique à partir de l’URL des fichiers que vous souhaitez lire.
La fonction OPENROWSET peut éventuellement contenir un paramètre DATA_SOURCE pour spécifier la source de données contenant des fichiers.
Vous pouvez utiliser la fonction
OPENROWSETsans le paramètreDATA_SOURCEpour lire directement le contenu des fichiers à partir de l’emplacement d’URL spécifié en tant qu’optionBULK:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Il s’agit d’un moyen simple et rapide de lire le contenu des fichiers sans configuration préalable. Cette option vous permet d’utiliser l’option d’authentification de base pour accéder au stockage (pass-through Microsoft Entra pour les connexions Microsoft Entra et jeton SAP pour les connexions SQL).
Vous pouvez utiliser la fonction
OPENROWSETavec le paramètreDATA_SOURCEpour accéder aux fichiers sur un compte de stockage spécifié :SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Cette option vous permet de configurer l’emplacement du compte de stockage dans la source de données et de spécifier la méthode d’authentification à utiliser pour accéder au stockage.
Important
La fonction
OPENROWSETsans le paramètreDATA_SOURCEfournit un moyen simple et rapide d’accéder aux fichiers de stockage, mais offre des options d’authentification limitées. Par exemple, les principaux Microsoft Entra peuvent accéder aux fichiers uniquement à l’aide de leur identité Microsoft Entra ou des fichiers disponibles publiquement. Si vous avez besoin d’options d’authentification plus puissantes, utilisez l’optionDATA_SOURCEet définissez les informations d’identification que vous souhaitez utiliser pour accéder au stockage.
Sécurité
Un utilisateur de base de données doit disposer de l’autorisation ADMINISTER BULK OPERATIONS pour utiliser la fonction OPENROWSET.
L’administrateur de stockage doit également permettre à un utilisateur d’accéder aux fichiers en fournissant un jeton SAP valide ou en permettant au principal Microsoft Entra d’accéder aux fichiers de stockage. Pour en savoir plus sur le contrôle d’accès au stockage, consultez cet article.
La fonction OPENROWSET utilise les règles suivantes pour déterminer comment s’authentifier auprès du stockage :
- Dans
OPENROWSETsansDATA_SOURCE, le mécanisme d’authentification dépend du type d’appelant.- Tout utilisateur peut utiliser
OPENROWSETsansDATA_SOURCEpour lire des fichiers accessibles publiquement sur le stockage Azure. - Les connexions Microsoft Entra peuvent accéder à des fichiers protégés en utilisant leur propre identité Microsoft Entra si le stockage Azure permet à l’utilisateur Microsoft Entra d’accéder aux fichiers sous-jacents (par exemple, si l’appelant dispose de l’autorisation
Storage Readersur le stockage Azure). - Des connexions SQL peuvent également recourir à
OPENROWSETsansDATA_SOURCEpour accéder à des fichiers en disponibilité publique, à des fichiers protégés par jeton SAP ou à l’identité managée d’un espace de travail Synapse. Vous devez créer des informations d’identification à l’échelle du serveur pour autoriser l’accès aux fichiers de stockage.
- Tout utilisateur peut utiliser
- Dans
OPENROWSETavecDATA_SOURCE, le mécanisme d’authentification est défini dans les informations d’identification étendues à la base de données affectées à la source de données référencée. Cette option vous permet d’accéder au stockage publiquement disponible, ou d’accéder au stockage à l’aide du jeton SAP, de l’identité managée de l’espace de travail ou de l’identité Microsoft Entra de l’appelant (si celui-ci est un principal Microsoft Entra). SiDATA_SOURCEfait référence à un stockage Azure qui n’est pas public, vous devez créer des informations d’identification étendues à la base de données et y faire référence dansDATA SOURCEpour autoriser l’accès aux fichiers de stockage.
L’appelant doit disposer de l’autorisation REFERENCES sur les informations d’identification afin de pouvoir les utiliser pour l’authentification auprès du stockage.
Syntaxe
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Arguments
Vous avez trois possibilités pour les fichiers d’entrée qui contiennent les données cibles à interroger. Les valeurs autorisées sont :
'CSV' - Comprend tout fichier texte délimité par des séparateurs de lignes/colonnes. N’importe quel caractère peut être utilisé comme séparateur de champs, par exemple TSV : FIELDTERMINATOR = tab.
'PARQUET' : fichier binaire au format Parquet.
'DELTA' : ensemble de fichiers Parquet organisés au format Delta Lake (version préliminaire).
Les valeurs comportant des espaces ne sont pas valides. Par exemple, ’CSV ’ n’est pas une valeur valide.
'unstructured_data_path'
L’élément unstructured_data_path qui établit un chemin d’accès aux données peut être un chemin d’accès absolu ou relatif :
- Un chemin absolu au format
\<prefix>://\<storage_account_path>/\<storage_path>permet à un utilisateur de lire directement les fichiers. - Un chemin relatif au format
<storage_path>doit être utilisé avec le paramètreDATA_SOURCEet décrit le modèle de fichier dans l’emplacement <storage_account_path> défini dansEXTERNAL DATA SOURCE.
Vous trouverez ci-dessous les valeurs des <chemins de compte de stockage> appropriées qui seront liées à votre source de données externe particulière.
| Source de données externe | Préfixe | Chemin de compte de stockage |
|---|---|---|
| Stockage Blob Azure | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Stockage Blob Azure | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | <storage_account>.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | |
'<storage_path>'
Spécifie un chemin au sein de votre stockage qui pointe vers le dossier ou le fichier que vous souhaitez lire. Si le chemin pointe vers un conteneur ou un dossier, tous les fichiers sont lus à partir de ce conteneur ou dossier particulier. Les fichiers des sous-dossiers ne sont pas inclus.
Vous pouvez utiliser des caractères génériques pour cibler plusieurs fichiers ou dossiers. L’utilisation de plusieurs caractères génériques non consécutifs est autorisée.
Dans l’exemple ci-dessous, tous les fichiers csv sont lus en débutant par population à partir de tous les dossiers en débutant par /csv/population :
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Si vous spécifiez que unstructured_data_path est un dossier, une requête de pool SQL serverless récupère des fichiers auprès de ce dossier.
Vous pouvez indiquer au pool SQL serverless de parcourir les dossiers en spécifiant /* à la fin du chemin, comme dans l’exemple suivant : https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Note
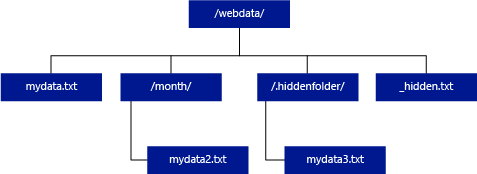
Contrairement à Hadoop et à PolyBase, un pool SQL serverless ne retourne pas de sous-dossiers, sauf si vous spécifiez /** à la fin du chemin. Tout comme Hadoop et PolyBase, il ne retourne pas de fichiers dont le nom commence par un trait de soulignement (_) ou un point (.).
Dans l’exemple ci-dessous, si le chemin_données_non_structurées=https://mystorageaccount.dfs.core.windows.net/webdata/, une requête de pool SQL sans serveur retournera des lignes de mydata.txt. Il ne retourne pas mydata2.txt et mydata3.txt, car ces fichiers se trouvent dans un sous-dossier.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
La clause WITH vous permet de préciser les colonnes que vous souhaitez lire des fichiers.
Pour les fichiers de données CSV, si vous souhaitez lire toutes les colonnes, indiquez les noms des colonnes et leur type de données. Si vous désirez un sous-ensemble de colonnes, utilisez des nombres ordinaux pour sélectionner les colonnes des fichiers de données d’origine par ordinal. Les colonnes sont ainsi liées par la désignation ordinale. Si HEADER_ROW = TRUE est utilisé, la liaison de colonne est effectuée par nom de colonne au lieu de la position ordinale.
Conseil
Vous pouvez aussi omettre la clause WITH pour les fichiers CSV. Les types de données sont inférés automatiquement du contenu du fichier. Vous pouvez utiliser l’argument HEADER_ROW pour spécifier l’existence d’une ligne d’en-tête, auquel cas les noms de colonnes seront lus à partir de cette ligne. Pour plus d’informations, consultez Découverte automatique du schéma.
Pour les fichiers Parquet ou Delta Lake, fournissez des noms de colonne qui correspondent aux noms des colonnes des fichiers de données d’origine. Les colonnes sont liées sur la base du nom et sont sensibles à la casse. Si la clause WITH est omise, toutes les colonnes des fichiers Parquet seront retournées.
Important
Les noms de colonnes dans les fichiers Parquet et Delta Lake sont sensibles à la casse. Si vous spécifiez un nom de colonne avec une casse différente de la casse du nom de colonne dans les fichiers, des valeurs
NULLsont retournées pour cette colonne.
column_name = Nom de la colonne de sortie. S’il est fourni, ce nom remplace le nom de colonne dans le fichier source et le nom de colonne fourni dans le chemin JSON, le cas échéant. Si json_path n’est pas fourni, il est automatiquement ajouté sous la forme '$.column_name'. Vérifiez l’argument json_path pour le comportement.
column_type = Type de données de la colonne de sortie. La conversion implicite du type de données aura lieu ici.
column_ordinal = Nombre ordinal de la colonne dans le ou les fichiers sources. Cet argument est ignoré pour les fichiers Parquet, car la liaison est effectuée par nom. L’exemple suivant retourne une deuxième colonne uniquement depuis un fichier CSV :
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = expression de chemin JSON vers la colonne ou la propriété imbriquée. Le mode de chemin par défaut est lax.
Note
En mode strict, la requête échoue avec une erreur si le chemin fourni n’existe pas. En mode lax, la requête aboutit et l’expression de chemin JSON prend la valeur NULL.
<options_groupées>
FIELDTERMINATOR ='field_terminator'
Spécifie le délimiteur de champ à utiliser. La marque de fin de champ par défaut est une virgule (« , »).
ROWTERMINATOR ='row_terminator'`
Spécifie l’indicateur de fin de ligne à utiliser. Si la marque de fin de ligne n’est pas spécifiée, l’une des marques par défaut sera utilisée. Les indicateurs de fin par défaut pour PARSER_VERSION = ’1.0’ sont \r\n, \n et \r. Les indicateurs de fin par défaut pour PARSER_VERSION = ’2.0’ sont \r\n et \n.
Note
Quand vous utilisez PARSER_VERSION=‘1.0’ et que vous spécifiez le caractère de saut de ligne \n en tant qu’indicateur de fin de ligne, celui-ci est automatiquement précédé du caractère \r (retour chariot), modifiant ainsi l’indicateur de fin de ligne en \r\n.
ESCAPE_CHAR = « char »
Spécifie le caractère dans le fichier qui est utilisé pour se placer lui-même dans une séquence d’échappement ainsi que toutes les valeurs de délimiteur dans le fichier. Si le caractère d’échappement est suivi d’une valeur autre que lui-même, ou que l’une des valeurs de délimiteur, le caractère d’échappement est supprimé lors de la lecture de la valeur.
Le paramètre ESCAPECHAR est appliqué, que FIELDQUOTE soit ou non activé. Il ne sera pas utilisé comme caractère d’échappement devant le caractère de délimitation. Le caractère de délimitation doit être placé dans une séquence d’échappement avec un autre caractère de délimitation. Le caractère de délimitation peut apparaître dans la valeur de colonne seulement si la valeur est encapsulée avec des caractères de délimitation.
FIRSTROW = 'first_row'
Numéro de la première ligne à charger. La valeur par défaut est 1, et indique la première ligne du fichier de données spécifié. Les numéros des lignes sont déterminés en comptant les indicateurs de fin de ligne. FIRSTROW commence à 1.
FIELDQUOTE = 'field_quote'
Spécifie un caractère qui sera utilisé comme caractère de guillemet dans le fichier CSV. S’il n’est pas spécifié, le guillemet (") sera utilisé.
DATA_COMPRESSION = ’data_compression_method’
Spécifie la méthode de compression. Pris en charge seulement dans PARSER_VERSION = '1.0'. La méthode de compression suivante est prise en charge :
- GZIP
PARSER_VERSION = ’parser_version’
Spécifie la version d’analyseur à utiliser lors de la lecture de fichiers. Sont actuellement prises en charge les versions 1.0 et 2.0 de l’analyseur CSV :
- PARSER_VERSION = ’1.0’
- PARSER_VERSION = ’2.0’
La version 1.0 de l’analyseur CSV, qui est la version par défaut, est riche en fonctionnalités. La version 2.0, conçue pour les performances, ne prend pas en charge l’ensemble des options et des codages.
Informations détaillées sur l’analyseur CSV version 1.0 :
- Les options suivantes ne sont pas prises en charge : HEADER_ROW.
- Les indicateurs de fin de ligne par défaut sont \r\n, \n et \r.
- Si vous spécifiez le caractère de saut de ligne \n en tant qu’indicateur de fin de ligne, celui-ci est automatiquement précédé du caractère \r (retour chariot), modifiant ainsi l’indicateur de fin de ligne en \r\n.
Les caractéristiques de la version 2.0 de l’analyseur CSV :
- Certains types de données ne sont pas pris en charge.
- La longueur maximale des colonnes de caractères est de 8 000.
- La limite maximale de taille de ligne est de 8 Mo.
- Les options suivantes ne sont pas prises en charge : DATA_COMPRESSION.
- La chaîne vide entre guillemets ("") est interprétée comme une chaîne vide.
- L’option DATEFORMAT SET n’est pas respectée.
- Format pris en charge pour le type de données DATE : AAAA-MM-JJ
- Format pris en charge pour le type de données TIME : HH:MM:SS[.fractions de seconde]
- Format pris en charge pour le type de données DATETIME2 : YYYY-MM-DD HH:MM:SS[.fractions de seconde]
- Les indicateurs de fin de ligne par défaut sont \r\n et \n.
HEADER_ROW = { VRAI | FAUX }
Spécifie si un fichier CSV contient une ligne d’en-tête. La valeur par défaut est FALSE.. Elle est prise en charge dans PARSER_VERSION='2.0'. Si la valeur est TRUE, les noms de colonnes sont lus à partir de la première ligne en fonction de l’argument FIRSTROW. Si la valeur est TRUE et que le schéma est spécifié à l’aide de WITH, la liaison des noms de colonnes s’effectue par nom de colonne, et non par positions ordinales.
DATAFILETYPE = { 'char' | 'widechar' }
Spécifie le codage : char est utilisé pour les fichiers UTF8, widechar pour les fichiers UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Indique la page de codes des données dans le fichier. La valeur par défaut est 65001 (encodage UTF-8). Cliquez ici pour en savoir plus sur cette option.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Cette option désactive la vérification des modifications de fichier au moment de l’exécution de la requête, et lit les fichiers mis à jour durant l’exécution de la requête. Il s’agit d’une option utile quand vous devez lire des fichiers pour ajout uniquement qui sont ajoutés durant l’exécution de la requête. Dans les fichiers annexes, le contenu existant n'est pas mis à jour, et seules de nouvelles lignes sont ajoutées. Par conséquent, la probabilité de résultats incorrects est réduite par rapport aux fichiers avec modification des données. Cette option peut vous permettre de lire les fichiers auxquels des données sont fréquemment ajoutées sans gérer les erreurs. Pour plus d’informations, consultez la section relative à l’interrogation de fichiers CSV pouvant être ajoutés.
Options de rejet
Note
La fonctionnalité de lignes rejetées est en préversion publique. Notez que la fonctionnalité de lignes rejetées marche avec des fichiers texte délimités et PARSER_VERSION 1.0.
Vous pouvez spécifier les paramètres REJECT qui déterminent la façon dont le service traite les enregistrements incorrects qu’il récupère de la source de données externe. Un enregistrement de données est considéré comme « incorrect » si les types de données actuels ne correspondent pas aux définitions de colonne de la table externe.
Si vous ne spécifiez pas ou ne modifiez pas les options Rejeter, le service utilise les valeurs par défaut. Le service utilisera les options Rejeter pour déterminer le nombre de lignes qui peuvent être rejetées avant l’échec de la requête réelle. La requête retourne des résultats (partiels) jusqu’à ce que le seuil de rejet soit dépassé. Ensuite, elle échoue avec le message d’erreur correspondant.
MAXERRORS = reject_value
Spécifie le nombre de lignes pouvant être rejetées avant l’échec de la requête. MAXERRORS doit être un entier compris entre 0 et 2 147 483 647.
ERRORFILE_DATA_SOURCE = source de données
Spécifie la source de données dans laquelle les lignes rejetées et le fichier d’erreur correspondant doivent être écrits.
ERRORFILE_LOCATION = Emplacement du répertoire
Spécifie le répertoire dans DATA_SOURCE ou ERROR_FILE_DATASOURCE, si spécifié, dans lequel les lignes rejetées et le fichier d’erreur correspondant doivent être écrits. Si le chemin spécifié n’existe pas, le service en crée un en votre nom. Un répertoire enfant est créé sous le nom « rejectedrows ». Ce nom de répertoire garantit qu’il est ignoré lors du traitement d’autres données, sauf si le nom est explicitement défini dans le paramètre d’emplacement. Dans ce répertoire figure un dossier qui est créé d’après l’heure de soumission de la charge au format AnnéeMoisJour_HeureMinuteSeconde_IDInstruction (par exemple 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Vous pouvez utiliser l’ID d’instruction pour corréler le dossier avec la requête qui l’a généré. Dans ce dossier, deux fichiers sont écrits : le fichier error.json et le fichier de données.
Le fichier error.json contient un tableau json avec des erreurs rencontrées qui sont liées aux lignes rejetées. Chaque élément représentant une erreur contient les attributs suivants :
| Attribut | Description |
|---|---|
| Erreur | Raison pour laquelle la ligne est rejetée. |
| Ligne | Nombre ordinal de lignes rejetées dans le fichier. |
| Colonne | Nombre ordinal de colonnes rejetées. |
| Valeur | Valeur de colonne rejetée. Si la valeur est supérieure à 100 caractères, seuls les 100 premiers caractères seront affichés. |
| Fichier | Chemin d’accès au fichier auquel la ligne appartient. |
Analyse rapide du texte délimité
Il existe deux versions de l’analyseur de texte délimité que vous pouvez utiliser. La version 1.0 de l’analyseur CSV est la version par défaut et est riche en fonctionnalités, tandis que sa version 2.0 est conçue pour les performances. L’amélioration des performances dans l’analyseur 2.0 provient de techniques d’analyse avancées et du multithreading. La différence de rapidité s’accroît à mesure que la taille du fichier augmente.
Découverte automatique du schéma
Vous pouvez facilement interroger des fichiers CSV et Parquet sans connaître ou spécifier le schéma en omettant la clause WITH. Les noms de colonnes et les types de données seront inférés à partir des fichiers.
Les fichiers Parquet contiennent des métadonnées de colonne qui seront lues. Les mappages de types se trouvent dans mappages de type pour Parquet. Pour obtenir des exemples, consultez La lecture de fichiers Parquet sans spécifier de schéma.
Pour les fichiers CSV, les noms de colonnes peuvent être lus à partir de la ligne d’en-tête. Vous pouvez spécifier s’il existe une ligne d’en-tête en utilisant l’argument HEADER_ROW. Si HEADER_ROW = FALSE, des noms de colonnes génériques sont utilisés : C1, C2, ... Cn, où n est le nombre de colonnes dans le fichier. Les types de données seront inférés à partir des 100 premières lignes de données. Pour obtenir des exemples, consultez Lecture de fichiers CSV sans spécifier de schéma.
N’oubliez pas que si vous lisez plusieurs fichiers à la fois, le schéma sera déduit du premier fichier que le service reçoit du stockage. Cela peut signifier que certaines des colonnes attendues seront omises, tout cela parce que le fichier utilisé par le service pour définir le schéma ne contenait pas ces colonnes. Dans ce cas, utilisez la clause OPENROWSET WITH.
Important
Dans certains cas, le type de données approprié ne peut pas être inféré en raison d’un manque d’informations : un type de données plus grand est alors utilisé à la place. Cela entraîne une surcharge de performance et est particulièrement important pour les colonnes de caractères qui seront considérées comme varchar(8000). Pour des performances optimales, vérifiez les types de données inférés et utilisez les types de données appropriés.
Mappage de type pour Parquet
Les fichiers Parquet et Delta Lake contiennent des descriptions de type pour chaque colonne. Le tableau suivant explique comment les types Parquet sont mappés aux types SQL natifs.
| Type Parquet | Type logique Parquet (annotation) | Type de données SQL |
|---|---|---|
| booléen | bit | |
| BINARY / BYTE_ARRAY | varbinary | |
| DOUBLE | flottant | |
| Flottant | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binaire | |
| Binaire | UTF8 | varchar *(classement UTF8) |
| Binaire | STRING | varchar *(classement UTF8) |
| Binaire | ENUM | varchar *(classement UTF8) |
| FIXED_LEN_BYTE_ARRAY | Identifiant Unique Universel (UUID) | identifiant unique |
| Binaire | DECIMAL | Décimal |
| Binaire | JSON | varchar(8000) *(classement UTF8) |
| Binaire | BSON | Non pris en charge |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | Décimal |
| BYTE_ARRAY | INTERVALLE | Non pris en charge |
| INT32 | INT(8, vrai) | smallint |
| INT32 | INT(16, vrai) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, faux) | tinyint |
| INT32 | INT(16, faux) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATE | Date |
| INT32 | DECIMAL | Décimal |
| INT32 | TIME (MILLIS) | temps |
| INT64 | INT(64, vrai) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | Décimal |
| INT64 | TIME (MICROS) | temps |
| INT64 | Temps (NANOS) | Non pris en charge |
| INT64 | TIMESTAMP (normalisé en UTC) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (non normalisé en UTC) (MILLIS / MICROS) | bigint : veillez à ajuster la valeur bigint explicitement avec le décalage de fuseau horaire avant de la convertir en valeur datetime. |
| INT64 | TIMESTAMP (NANOS) | Non pris en charge |
| Type complexe | Liste | varchar(8000), sérialisé en JSON |
| Type complexe | Carte | varchar(8000), sérialisé en JSON |
Exemples
Lire des fichiers CSV sans spécifier le schéma
L’exemple suivant lit un fichier CSV qui contient une ligne d’en-tête sans spécifier les noms de colonnes et les types de données :
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
L’exemple suivant lit un fichier CSV qui ne contient pas de ligne d’en-tête sans spécifier les noms de colonnes et les types de données :
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Lire des fichiers Parquet sans spécifier le schéma
L’exemple suivant retourne toutes les colonnes de la première ligne du jeu de données de recensement, au format Parquet, et sans spécifier les noms des colonnes et les types de données :
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Lire des fichiers Delta Lake sans spécifier le schéma
L’exemple suivant retourne toutes les colonnes de la première ligne du jeu de données de recensement, au format Delta Lake, et sans spécifier les noms des colonnes et les types de données :
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Lire des colonnes spécifiques dans un fichier CSV
L’exemple suivant retourne seulement deux colonnes avec les nombres ordinaux 1 et 4 à partir des fichiers population*.csv. Étant donné qu’il n’y a pas de ligne d’en-tête dans les fichiers, la lecture commence à la première ligne :
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Lire des colonnes spécifiques dans un fichier Parquet
Dans l’exemple suivant, seules deux colonnes de la première rangée du jeu de données de recensement au format Parquet sont renvoyées :
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Spécifier des colonnes à l’aide de chemins JSON
L’exemple suivant montre comment vous pouvez utiliser des expressions de chemin JSON dans la clause WITH, et il illustre la différence entre les modes de chemin strict et lax :
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Spécifier plusieurs fichiers/dossiers dans le chemin d’accès BULK
L’exemple suivant montre comment vous pouvez utiliser plusieurs chemins d’accès de fichier/dossier dans le paramètre BULK :
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Étapes suivantes
Pour obtenir d’autres exemples, consultez le Guide de démarrage rapide du stockage de données de requête pour savoir comment utiliser OPENROWSET pour lire les formats de fichiers CSV, PARQUET, DELTA LAKE et JSON. Consultez les bonnes pratiques pour obtenir des performances optimales. Vous pouvez également apprendre à enregistrer les résultats de votre requête dans Stockage Azure à l’aide de CETAS.