Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Dans cet article, vous apprendrez comment écrire une requête à l’aide du pool Synapse SQL serverless pour lire des fichiers Delta Lake. Delta Lake est une couche de stockage open source qui apporte des transactions ACID (atomicité, cohérence, isolation et durabilité) à Apache Spark et aux charges de travail Big Data. Pour en savoir plus, consultez la vidéo comment interroger des tables delta lake.
Important
Les pools SQL serverless peuvent interroger Delta Lake version 1.0. Les changements introduits depuis la version Delta Lake 1.2 (comme le renommage des colonnes) ne sont pas pris en charge dans serverless. Si vous utilisez les versions supérieures de Delta avec des vecteurs de suppression, les points de contrôle v2 et autres, vous devez envisager d’utiliser un autre moteur de requête comme le point de terminaison Microsoft Fabric SQL pour Lakehouses.
Le pool SQL serverless de l’espace de travail Synapse vous permet de lire les données stockées au format Delta Lake et de les traiter dans des outils de création de rapports. Un pool SQL serverless peut lire les fichiers Delta Lake créés à l’aide d’Apache Spark, Azure Databricks ou tout autre producteur du format Delta Lake.
Les pools Apache Spark dans Azure Synapse permettent aux ingénieurs des données de modifier les fichiers Delta Lake à l’aide de Scala, PySpark et .NET. Les pools SQL serverless aident les analystes de données à créer des rapports sur les fichiers Delta Lake créés par des ingénieurs de données.
Important
L’interrogation du format Delta Lake à l’aide d'un pool SQL sans serveur est une fonctionnalité généralement disponible. Toutefois, les requêtes des tables Delta Spark sont toujours en préversion publique et ne sont pas prêtes pour la production. Il existe des problèmes connus qui peuvent se produire si vous interrogez des tables Delta créées à l’aide des pools Spark. Consultez les problèmes connus dans l’aide relative aux pools SQL serverless.
Prérequis
Important
Les sources de données ne peuvent être créées que dans des bases de données personnalisées (et non dans la base de données Master ou dans les bases de données répliquées à partir de pools Apache Spark).
Pour utiliser les exemples de cet article, vous devez effectuer les étapes suivantes :
- Créez une base de données avec une source de données qui fait référence au compte de stockage NYC Yellow Taxi.
- Initialisez les objets en exécutant le script d’installation sur la base de données que vous avez créée à l’étape 1. Ce script crée les sources de données, les informations d’identification étendues à la base de données et les formats de fichiers externes utilisés dans ces exemples.
Si vous avez créé votre base de données et basculé le contexte vers votre base de données (à l’aide de l'instruction USE database_name ou de la liste déroulante pour sélectionner une base de données dans un éditeur de requête), vous pouvez créer votre source de données externe contenant l’URI racine de votre jeu de données et l’utiliser pour interroger les fichiers Delta Lake. Par exemple :
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Si une source de données est protégée par une clé SAS ou une identité personnalisée, vous pouvez configurer la source de données avec des informations d’identification à l'échelle de la base de données.
Vous pouvez créer une source de données externe avec l’emplacement qui pointe vers le dossier racine du stockage. Une fois que vous avez créé la source de données externe, utilisez la source de données et le chemin d’accès relatif au fichier dans la fonction OPENROWSET. De cette façon, vous n’avez pas besoin d’utiliser l’URI absolu complet pour vos fichiers. Vous pouvez également définir des informations d’identification personnalisées pour accéder à l’emplacement de stockage.
Lire le dossier Delta Lake
Important
Utilisez le script d’installation dans les conditions préalables pour configurer les exemples de sources de données et les tables.
La fonction OPENROWSET vous permet de lire le contenu d’un fichier Delta Lake en indiquant l’URL de votre dossier racine.
Le moyen le plus simple d’afficher le contenu de votre DELTAfichier consiste à spécifier l’URL du fichier dans la fonction OPENROWSET et à spécifier le format DELTA. Si le fichier est disponible publiquement ou si votre identité Microsoft Entra peut y accéder, vous devriez pouvoir voir le contenu du fichier à l’aide d’une requête comme celle montrée dans l’exemple suivant :
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Les noms de colonnes et les types de données sont automatiquement lus à partir des fichiers Delta Lake. La fonction OPENROWSET utilise les meilleurs types de suppositions comme VARCHAR(1000) pour les colonnes de chaîne.
L’URI de la fonction OPENROWSET doit référencer le dossier racine Delta Lake qui contient un sous-dossier appelé _delta_log.
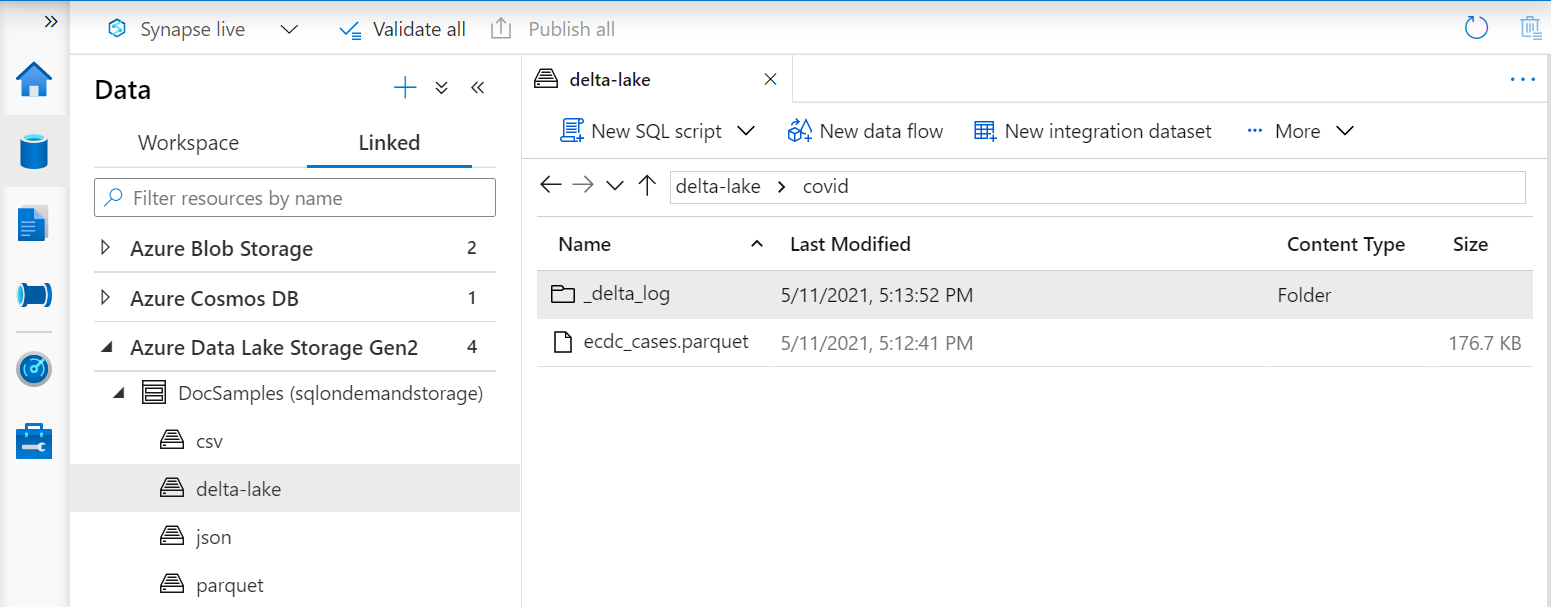
Si vous ne disposez pas de ce sous-dossier, vous n’utilisez pas le format Delta Lake. Vous pouvez convertir vos fichiers Parquet bruts dans le dossier au format Delta Lake en utilisant un script comme l'exemple suivant en Python Apache Spark :
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Pour améliorer les performances de vos requêtes, envisagez de spécifier des types explicites dans la clause WITH.
Note
Le pool SQL Synapse serverless utilise l’inférence de schéma pour déterminer automatiquement les colonnes et leurs types. Les règles d’inférence de schéma sont les mêmes que celles utilisées pour les fichiers Parquet. Pour le mappage de type Delta Lake en type SQL natif, sélectionnez Mappage de type pour Parquet.
Assurez-vous de pouvoir accéder à votre fichier. Si votre fichier est protégé par une clé SAP ou une identité Azure personnalisée, vous devez configurer les informations d’identification au niveau du serveur pour la connexion SQL.
Important
Assurez-vous que vous utilisez un classement de base de données UTF-8 (par exemple Latin1_General_100_BIN2_UTF8), car les valeurs de chaîne dans les fichiers Delta Lake sont encodées à l’aide d’un encodage UTF-8.
Une incompatibilité entre l’encodage de texte dans le fichier Delta Lake et le classement peut entraîner des erreurs de conversion inattendues.
Vous pouvez facilement modifier le classement par défaut de la base de données actuelle à l’aide de l’instruction T-SQL suivante :
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8;Pour plus d’informations sur les classements, consultez Types de classements pris en charge pour Synapse SQL.
Spécifier explicitement le schéma
OPENROWSET vous permet de spécifier explicitement les colonnes que vous souhaitez lire à partir du fichier à l’aide de la clause WITH :
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Avec la spécification explicite du schéma du jeu de résultats, vous pouvez réduire les tailles de type et utiliser les types plus précis VARCHAR(6) pour les colonnes de chaîne au lieu d’un VARCHAR(1000) pessimiste. La minimisation des types peut améliorer considérablement les performances de vos requêtes.
Important
Veillez à spécifier explicitement un classement UTF-8 (par exemple Latin1_General_100_BIN2_UTF8) pour toutes les colonnes de chaîne dans la clause WITH, ou définissez un classement UTF-8 au niveau de la base de données.
Une incompatibilité entre l’encodage de texte dans le fichier et le classement de colonne de chaîne peut entraîner des erreurs de conversion inattendues.
Vous pouvez facilement modifier le classement par défaut de la base de données actuelle à l’aide de l’instruction T-SQL suivante :
alter database current collate Latin1_General_100_BIN2_UTF8Vous pouvez facilement définir le classement sur les types de colonne à l’aide de la définition suivante : geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Ensemble de données
Le jeu de données NYC Yellow Taxi est utilisé dans cet exemple. Le jeu de données d’origine PARQUET est converti au format DELTA et la version DELTA est utilisée dans les exemples.
Interroger des données partitionnées
Le jeu de données fourni dans cet exemple est divisé (partitionné) en sous-dossiers distincts.
Contrairement au format Parquet, vous n’avez pas besoin de cibler des partitions spécifiques à l’aide de la fonction FILEPATH.
OPENROWSET identifie les colonnes de partitionnement dans votre structure de dossiers Delta Lake et vous permet d’interroger directement les données à l’aide de ces colonnes. Cet exemple montre les montants par année, par mois et par type de paiement pour les trois premiers mois de 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
La fonction OPENROWSET éliminera les partitions qui ne correspondent pas à year et month dans la clause where. Cette technique de nettoyage de fichiers/partitions réduira considérablement votre jeu de données, améliorera les performances et réduira le coût de la requête.
Le nom du dossier dans la fonction OPENROWSET (yellow dans cet exemple) est concaténé à l’aide de LOCATION dans la source de données DeltaLakeStorage, et doit faire référence au dossier racine Delta Lake qui contient un sous-dossier appelé _delta_log.
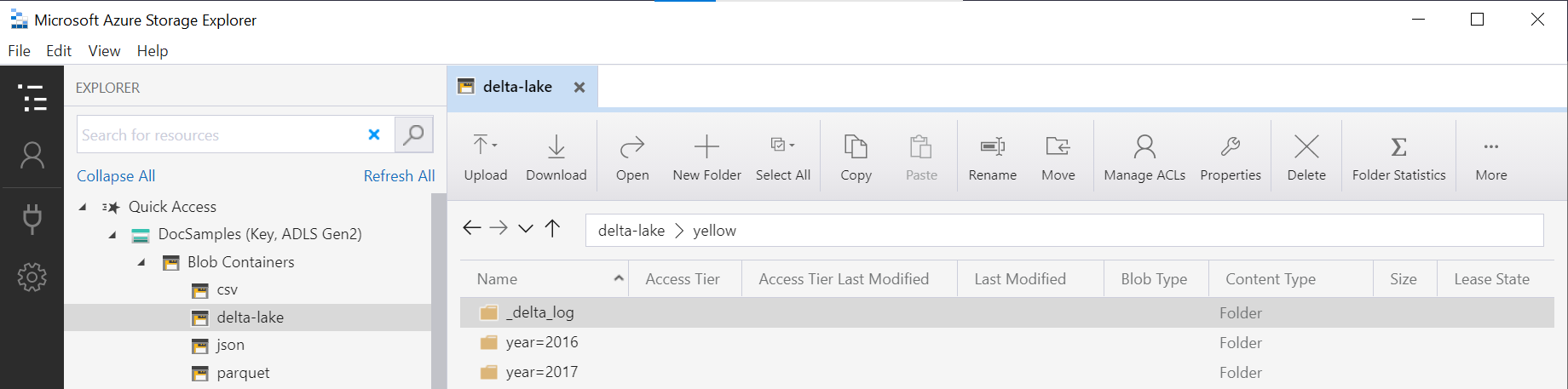
Si vous ne disposez pas de ce sous-dossier, vous n’utilisez pas le format Delta Lake. Vous pouvez convertir vos fichiers Parquet bruts dans le dossier au format Delta Lake à l’aide du script Python Apache Spark suivant :
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Le deuxième argument de la fonction DeltaTable.convertToDeltaLake représente les colonnes de partitionnement (année et mois) qui font partie du modèle de dossier (year=*/month=* dans cet exemple) et leurs types.
Limites
- Consultez les limitations et problèmes connus dans la page d’aide relative aux pools SQL serverless Synapse.
Contenu connexe
Passez à l’article suivant pour apprendre à interroger des types imbriqués Parquet. Si vous souhaitez continuer à créer une solution Delta Lake, découvrez comment créer des vues ou des tables externes dans le dossier Delta Lake.