Haute disponibilité du système de montée en charge SAP HANA sur Red Hat Enterprise Linux
Cet article explique comment déployer un système de SAP HANA à haut niveau de disponibilité dans une configuration avec montée en puissance parallèle. Plus précisément, la configuration utilise la réplication de système HANA (HSR) et Pacemaker sur les machines virtuelles (vm) Azure Red Hat Enterprise Linux. Les systèmes de fichiers partagés dans l’architecture présentée sont montés sur NFS et sont fournis par Azure NetApp Files ou le partage NFS sur Azure Files.
Dans les exemples de configurations et de commandes d’installation, l’instance HANA est 03 et l’ID système Hana est HN1 .
Prérequis
Certains lecteurs tirent parti de la consultation d’une série de notes et de ressources SAP avant de continuer à utiliser les rubriques de cet article :
- La note SAP 1928533 comprend :
- Liste des tailles de machines virtuelles Azure prises en charge pour le déploiement de logiciels SAP.
- Des informations importantes sur la capacité en fonction de la taille des machines virtuelles Azure.
- Logiciels SAP pris en charge, et combinaisons de systèmes d’exploitation et de bases de données.
- La version du noyau SAP requise pour Windows et Linux sur Microsoft Azure.
- Note SAP 2015553: répertorie les conditions préalables pour les déploiements de logiciels SAP pris en charge par SAP dans Azure.
- Note SAP [2002167] : possède les paramètres de système d’exploitation recommandés pour RHEL.
- Note SAP 2009879: possède les instructions SAP Hana pour RHEL.
- La note SAP 3108302 contient des instructions concernant SAP HANA pour Red Hat Enterprise Linux 9.x.
- Note SAP 2178632: contient des informations détaillées sur toutes les métriques de surveillance signalées pour SAP dans Azure.
- Note SAP 2191498: contient la version requise de l’agent hôte SAP pour Linux dans Azure.
- Note SAP 2243692: contient des informations sur la gestion des licences SAP sur Linux dans Azure.
- Note SAP 1999351: contient des informations supplémentaires sur la résolution des problèmes liés à l’extension d’analyse Azure améliorée pour SAP.
- Note SAP 1900823: contient des informations sur les exigences de stockage SAP Hana.
- Wiki de la communauté SAP : contient toutes les notes SAP nécessaires pour Linux.
- Planification et implémentation de machines virtuelles Azure pour SAP sur Linux.
- Déploiement de machines virtuelles Azure pour SAP sur Linux.
- Déploiement SGBD de machines virtuelles Azure pour SAP sur Linux.
- Configuration requise pour le réseau SAP HANA.
- Documentation RHEL générale :
- Vue d’ensemble du module complémentaire haute disponibilité.
- Administration du module complémentaire haute disponibilité.
- Référence du module complémentaire haute disponibilité.
- Guide de mise en réseau Red Hat Enterprise Linux.
- Comment configurer la réplication du système de montée en charge SAP HANA dans un cluster Pacemaker avec les systèmes de fichiers HANA sur des partages NFS.
- Active/active (accessible en lecture) : solution de haute disponibilité RHEL pour la réplication du système et la montée en charge SAP HANA.
- Documentation RHEL spécifique à Azure :
- Documentation Azure NetApp Files.
- Volumes NFS v 4.1 sur Azure NetApp Files pour SAP Hana.
- Documentation Azure Files
Vue d’ensemble
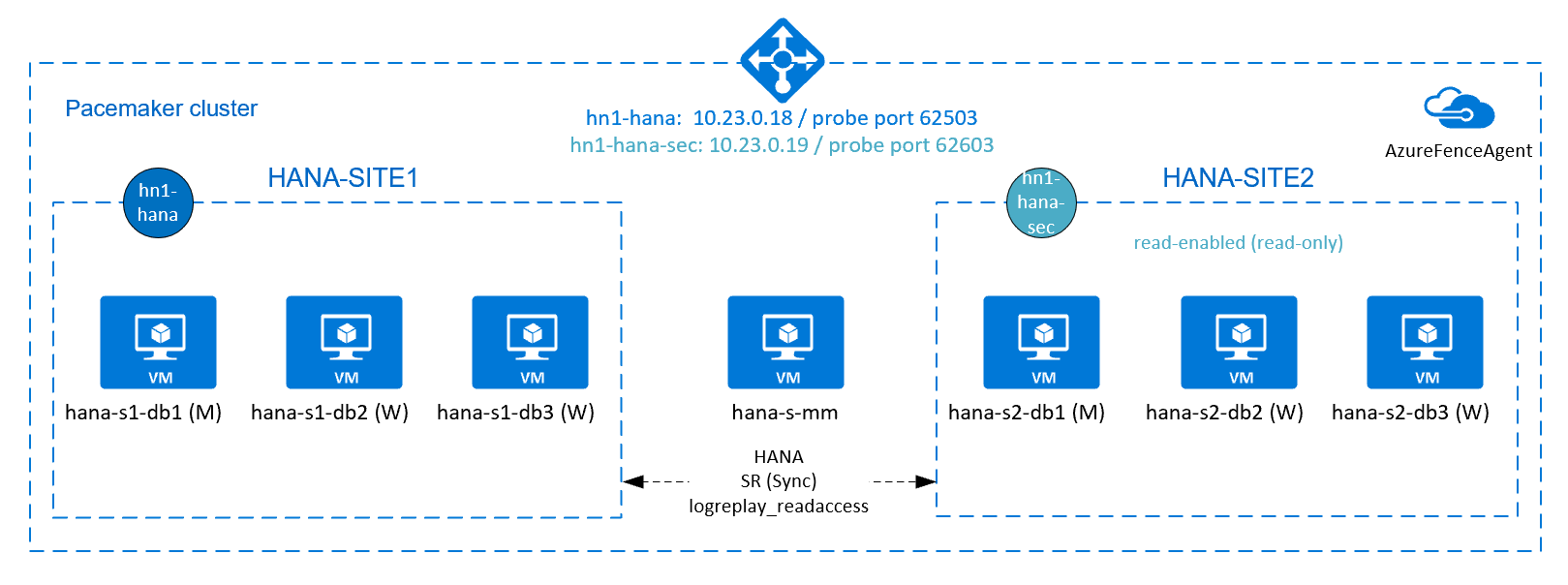
Pour obtenir une haute disponibilité HANA pour les installations avec montée en charge HANA, vous pouvez configurer la réplication du système HANA et protéger la solution avec un cluster Pacemaker afin d’autoriser le basculement automatique. En cas de défaillance d’un nœud actif, le cluster bascule les ressources HANA vers l’autre site.
Dans le diagramme suivant, il existe trois nœuds HANA sur chaque site, et un nœud de fabricant majoritaire pour empêcher un scénario de « Split-Brain ». Les instructions peuvent être adaptées pour inclure davantage de machines virtuelles en tant que nœuds HANA DB.
Le système de fichiers partagé HANA /hana/shared dans l’architecture présentée peut être fourni par Azure NetApp Files ou le partage NFS sur Azure Files. Le système de fichiers partagé HANA est monté sur NFS sur chaque nœud HANA dans le même site de réplication système HANA. Les systèmes de fichiers /hana/data et /hana/log sont des systèmes de fichiers locaux et ne sont pas partagés entre les nœuds de base de données HANA. SAP HANA sera installé en mode non partagé.
Pour des configurations de stockage recommandées SAP HANA, consultez Configurations de stockage SAP HANA des machines virtuelles Azure.
Important
Si vous déployez tous les systèmes de fichiers HANA sur Azure NetApp Files pour des systèmes de production pour lesquels les performances sont essentielles, nous vous recommandons d’évaluer et d’envisager d’utiliser le groupe de volumes d’application Azure NetApp Files pour SAP HANA.

Le diagramme précédent illustre trois sous-réseaux représentés dans un réseau virtuel Azure, suivant les recommandations de réseau SAP HANA :
- Pour la communication client :
client10.23.0.0/24 - Pour la communication interne entre les nœuds HANA :
inter10.23.1.128/26 - Pour la réplication du système HANA :
hsr10.23.1.192/26
Étant donné que /hana/data et /hana/log sont déployés sur des disques locaux, il n’est pas nécessaire de déployer un sous-réseau et des cartes réseau virtuelles distincts pour la communication avec le stockage.
Si vous utilisez Azure NetApp Files, les volumes NFS pour /hana/shared sont déployés dans un sous-réseau distinct, délégué à Azure NetApp Files : anf 10.23.1.0/26.
Configurer l’infrastructure
Les instructions suivantes supposent que vous avez déjà créé le groupe de ressources, le réseau virtuel Azure avec les trois sous-réseaux de réseau Azure : client, inter et hsr.
Déployer des machines virtuelles Linux via le Portail Azure
Déployer les machines virtuelles Azure. Pour cette configuration, déployez sept machines virtuelles :
- Trois machines virtuelles pour servir de nœuds HANA DB pour le site de réplication HANA 1 : hana-s1-db1, hana-s1-db2 et hana-s1-db3.
- Trois machines virtuelles pour servir de nœuds HANA DB pour le site de réplication HANA 2 : hana-s2-db1, hana-s2-db2 et hana-s2-db3.
- Une petite machine virtuelle pour servir de fabricant majoritaire : hana-s-mm.
Les machines virtuelles déployées en tant que nœuds SAP DB HANA doivent être certifiées par SAP pour HANA, telles qu’elles sont publiées dans le répertoire matériel SAP HANA. Lorsque vous déployez les nœuds HANA DB, veillez à sélectionner réseau accéléré.
Pour le nœud de fabricant majoritaire, vous pouvez déployer une petite machine virtuelle, car cette machine virtuelle n’exécute aucune des ressources SAP HANA. La machine virtuelle de fabricant majoritaire est utilisée dans la configuration du cluster pour obtenir un nombre impair de nœuds de cluster dans un scénario de fractionnement. La machine virtuelle de créateur de majorité n’a besoin que d’une seule interface réseau virtuelle dans le sous-réseau
clientdans cet exemple.Déployer des disques managés locaux pour
/hana/dataet/hana/log. La configuration de stockage minimale recommandée pour/hana/dataet/hana/logest décrite dans Configurations de stockage SAP HANA des machines virtuelles Azure.Déployez l’interface réseau principale pour chaque machine virtuelle dans le sous-réseau du réseau virtuel
client. Lorsque la machine virtuelle est déployée via le Portail Azure, le nom de l’interface réseau est généré automatiquement. Dans cet article, nous allons faire référence aux interfaces réseau principales générées automatiquement en tant que hana-s1-db1-client, hana-s1-db2-client, hana-s1-db3-client, et ainsi de suite. Ces interfaces réseau sont attachées auclientsous-réseau du réseau virtuel Azure.Important
Assurez-vous que le système d’exploitation que vous sélectionnez est certifié SAP pour SAP HANA sur les types de machines virtuelles spécifiques que vous utilisez. Pour obtenir la liste des types de machines virtuelles SAP HANA certifiées et des versions du système d’exploitation pour ces types, consultez les plateformes IaaS SAP Hana certifiées. Explorez les détails du type de machine virtuelle répertorié pour obtenir la liste complète des versions du système d’exploitation prises en charge par SAP HANA pour ce type.
Créez six interfaces réseau, une pour chaque machine virtuelle de base de données HANA, dans le sous-réseau
interdu réseau virtuel (dans cet exemple, hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-inter, et hana-s2-db3-inter).Créez six interfaces réseau, une pour chaque machine virtuelle de base de données HANA, dans le sous-réseau
hsrdu réseau virtuel (dans cet exemple, hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-db2-hsr, et hana-s2-db3-hsr).Attachez les interfaces réseau virtuelles nouvellement créées aux machines virtuelles correspondantes :
- Accédez à la machine virtuelle sur le Portail Azure.
- Dans le volet gauche, sélectionnez Machines virtuelles. Filtrez sur le nom de la machine virtuelle (par exemple, hana-s1-db1), puis sélectionnez la machine virtuelle.
- Dans le volet Vue d’ensemble, sélectionnez Arrêter pour libérer la machine virtuelle.
- Sélectionnez Mise en réseau, puis attachez l’interface réseau. Dans la liste déroulante Attacher une interface réseau, sélectionnez les interfaces réseau déjà créées pour les sous-réseaux
interethsr. - Sélectionnez Enregistrer.
- Répétez les étapes b à e pour les machines virtuelles restantes (dans notre exemple, hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 et hana-s2-db3).
- Laissez les machines virtuelles à l’état arrêté pour l’instant.
Activez la mise en réseau accélérée pour les interfaces réseau supplémentaires pour les sous-réseaux
interethsren procédant comme suit :Ouvrez Azure Cloud Shell dans le Portail Azure.
Exécutez les commandes suivantes pour activer la mise en réseau accélérée pour les interfaces réseau supplémentaires, qui sont attachées aux sous-réseaux
interethsr.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
Démarrez les machines virtuelles HANA DB.
Configurer l’équilibrage de charge Azure
Pendant la configuration de la machine virtuelle, vous avez la possibilité de créer ou de sélectionner un équilibreur de charge existant dans la section réseau. Suivez les étapes ci-dessous pour configurer l’équilibreur de charge standard pour la configuration de la haute disponibilité de la base de données HANA.
Remarque
- Pour le scale-out HANA, sélectionnez la carte réseau du sous-réseau
clientlors de l’ajout des machines virtuelles dans le pool de back-ends. - L’ensemble complet de commandes dans Azure CLI et PowerShell ajoute les machines virtuelles avec une carte réseau principale dans le pool de back-ends.
- Portail Azure
- Azure CLI
- PowerShell
Suivez les étapes dans Créer un équilibreur de charge pour configurer un équilibreur de charge standard pour un système SAP à haute disponibilité à l’aide du portail Azure. Pendant la configuration de l’équilibreur de charge, tenez compte des points suivants :
- Configuration d’une adresse IP front-end : créez une adresse IP front-end. Sélectionnez le même nom de réseau virtuel et de sous-réseau que vos machines virtuelles de base de données.
- Pool back-end : créez un pool back-end et ajoutez des machines virtuelles de base de données.
- Règles de trafic entrant : créez une règle d’équilibrage de charge. Suivez les mêmes étapes pour les deux règles d’équilibrage de charge.
- Adresse IP front-end : sélectionnez une adresse IP front-end.
- Pool back-end : sélectionnez un pool back-end.
- Ports haute disponibilité : sélectionnez cette option.
- Protocole : sélectionnez TCP.
- Sonde d’intégrité : créez une sonde d’intégrité avec les détails suivants :
- Protocole : sélectionnez TCP.
- Port : par exemple, 625<numéro-instance>.
- Intervalle : entrez 5.
- Seuil de sonde : entrez 2.
- Délai d'inactivité (minutes) : entrez 30.
- Activer l’adresse IP flottante : sélectionnez cette option.
Remarque
La propriété de configuration de la sonde d’intégrité numberOfProbes, également appelée Seuil de défaillance sur le plan de l’intégrité dans le portail, n’est pas respectée. Pour contrôler le nombre de sondes consécutives qui aboutissent ou qui échouent, définissez la propriété probeThreshold sur 2. Il n’est actuellement pas possible de définir cette propriété à l’aide du portail Azure. Utilisez donc l’interface Azure CLI ou la commande PowerShell.
Remarque
Lorsque vous utilisez l’équilibreur de charge standard, vous devez être conscient de la limitation suivante. Lorsque vous placez des machines virtuelles sans adresses IP publiques dans le pool principal d’un équilibreur de charge interne, il n’y a aucune connectivité Internet sortante. Pour autoriser le routage vers des points de terminaison publics, vous devez effectuer une configuration supplémentaire. Pour plus d’informations, consultez Connectivité de point de terminaison public pour les machines virtuelles avec Azure Standard Load Balancer dans les scénarios de haute disponibilité SAP.
Important
N’activez pas les horodateurs TCP sur les machines virtuelles Azure placées derrière l’Équilibreur de charge Azure. L’activation des horodateurs TCP provoque l’échec des sondes d’intégrité. Affectez au paramètre net.ipv4.tcp_timestampsla valeur 0. Pour plus d’informations, consultez les sondes d’intégrité de l’Équilibreur de charge et la note SAP 2382421.
Déployer NFS
Deux options permettent de déployer le NFS natif Azure pour /hana/shared. Vous pouvez déployer un volume NFS sur Azure NetApp Files ou le partage NFS sur Azure Files. Azure Files prend en charge le protocole NFSv4.1, NFS sur NetApp Azure Files prend en charge NFSv4.1 et NFSv3.
Les sections suivantes décrivent les étapes de déploiement de NFS : vous devez sélectionner une seule des options.
Conseil
Vous avez choisi de déployer /hana/shared sur le partage NFS sur Azure Files ou le volume NFS sur Azure NetApp Files.
Déployer l’infrastructure Azure NetApp Files
Déployez les volumes Azure NetApp Files pour le /hana/shared système de fichiers. Vous avez besoin d’un /hana/shared volume distinct pour chaque site de réplication du système HANA. Pour plus d’informations, consultez Configurer l’infrastructure Azure NetApp Files.
Dans cet exemple, les volumes Azure NetApp Files suivants ont été utilisés :
- volume HN1-shared-s1 (nfs://10.23.1.7/HN1-shared-s1)
- volume HN1-shared-s2 (nfs://10.23.1.7/HN1-shared-s2)
Déployer le NFS sur l’infrastructure Azure Files
Déployez des partages NFS Azure Files pour le système de fichiers /hana/shared. Vous avez besoin d’un partage NFS Azure Files /hana/shared distinct pour chaque site de réplication de système HANA. Pour plus d’informations, consultez Comment créer un partage NFS.
Dans cet exemple, les partages NFS Azure Files suivants ont été utilisés :
- share hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- share hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
Configuration et préparation du système d’exploitation
Les instructions des sections suivantes sont précédées de l’une des abréviations suivantes :
- [A] : applicable à tous les nœuds
- [AH] : applicable à tous les nœuds de base de données HANA
- [M] : applicable au nœud de créateur de majorité
- [AH1] : applicable à tous les nœuds de base de données HANA sur le SITE 1
- [AH2] : applicable à tous les nœuds de base de données HANA sur le SITE 2
- [1] : applicable uniquement au nœud de base de données HANA 1, SITE 1
- [2] : applicable uniquement au nœud de base de données HANA 1, SITE 2
Configurez et préparez votre système d’exploitation en procédant comme suit :
[A] Conservez les fichiers hôtes sur les machines virtuelles. Incluez des entrées pour tous les sous-réseaux. Les entrées suivantes sont ajoutées à
/etc/hostspour cet exemple.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Créez un fichier de configuration /etc/sysctl.d/ms-az.conf avec les paramètres de configuration Microsoft Azure.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Conseil
Évitez de définir
net.ipv4.ip_local_port_rangeetnet.ipv4.ip_local_reserved_portsde manière explicite dans lessysctlfichiers de configuration, pour permettre à l’agent hôte SAP de gérer les plages de ports. Pour plus d’informations, consultez la note SAP 2382421.[A] Installer le package client NFS.
yum install nfs-utils[AH] Red Hat pour la configuration HANA.
Configurez RHEL, comme décrit dans le portail client Red Hat et dans les notes SAP suivantes :
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (SAP HANA DB : Paramètres de système d’exploitation recommandés pour RHEL 7)
- 2777782 - SAP HANA DB: Paramètres de système d’exploitation recommandés pour RHEL 8
- 2455582 – Linux : Exécution d’applications SAP compilées avec GCC 6.x
- 2593824 – Linux : Exécution d’applications SAP compilées avec GCC 7.x
- 2886607 – Linux : Exécution d’applications SAP compilées avec GCC 9.x
Préparer les systèmes de fichiers
Les sections suivantes décrivent les étapes de préparation de vos systèmes de fichiers. Vous avez choisi de déployer '/hana/shared' sur le partage NFS sur Azure Files ou le volume NFS sur Azure NetApp Files.
Monter les systèmes de fichiers partagés (NFS Azure NetApp Files)
Dans cet exemple, les systèmes de fichiers HANA partagés sont déployés sur Azure NetApp Files et montés sur NFSv4.1. Suivez les étapes décrites dans cette section uniquement si vous utilisez NFS sur Azure NetApp Files.
[AH] Préparez le système d’exploitation pour l’exécution de SAP HANA sur les systèmes NetApp avec NFS, comme indiqué dans la note SAP 3024346 - Paramètres du noyau Linux pour NetApp NFS. Créez un fichier de configuration /etc/sysctl.d/91-NetApp-HANA.conf pour les paramètres de configuration de NetApp.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] Réglez les paramètres de sunrpc, comme recommandé dans la note SAP 3024346 - Paramètres du noyau Linux pour NetApp NFS.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] Créez des points de montage pour les volumes de base de données HANA.
mkdir -p /hana/shared[AH] Vérifiez le paramètre de domaine NFS. Assurez-vous que le domaine est configuré en tant que domaine par défaut Azure NetApp Files :
defaultv4iddomain.com. Assurez-vous que le mappage est défini surnobody.
(Cette étape n’est nécessaire que si vous utilisez Azure NetAppFiles NFS v 4.1.)Important
Veillez à définir le domaine NFS dans
/etc/idmapd.confsur la machine virtuelle pour qu’elle corresponde à la configuration de domaine par défaut sur Azure NetApp Files :defaultv4iddomain.com. En cas de discordance entre la configuration de domaine sur le client NFS et le serveur NFS, les autorisations pour les fichiers sur les volumes Azure NetApp montés sur les machines virtuelles s’affichent sous la formenobody.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] Vérifiez
nfs4_disable_idmapping. Sa valeur doit êtreY. Pour créer la structure de répertoire où se trouvenfs4_disable_idmapping, exécutez la commande mount. Vous ne pouvez pas créer manuellement le répertoire sous /sys/modules, car l’accès est réservé pour le noyau ou les pilotes.
Cette étape n’est nécessaire que si vous utilisez Azure NetAppFiles NFSv4.1.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPour plus d’informations sur la modification du
nfs4_disable_idmappingparamètre, consultez le portail client Red Hat.[AH1] Montez les volumes Azure NetApp Files partagés sur les machines virtuelles du SITE 1 de base de données HANA.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] Montez les volumes Azure NetApp Files partagés sur les machines virtuelles du SITE 2 de base de données HANA.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] Vérifiez que les
/hana/shared/systèmes de fichiers correspondants sont montés sur toutes les machines virtuelles HANA DB, avec la version de protocole NFS NFSv4.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
Monter les systèmes de fichiers partagés (NFS Azure Files)
Dans cet exemple, les systèmes de fichiers HANA partagés sont déployés sur NFS sur Azure Files. Suivez les étapes décrites dans cette section uniquement si vous utilisez NFS sur Azure Files.
[AH] Créez des points de montage pour les volumes de base de données HANA.
mkdir -p /hana/shared[AH1] Montez les volumes Azure NetApp Files partagés sur les machines virtuelles du SITE 1 de base de données HANA.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] Montez les volumes Azure NetApp Files partagés sur les machines virtuelles du SITE 2 de base de données HANA.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] Vérifiez que les systèmes de fichiers
/hana/shared/correspondants sont montés sur toutes les machines virtuelles de base de données HANA avec la version de protocole NFS NFSv4.1.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
Préparer les données et enregistrer les systèmes de fichiers locaux
Dans la configuration présentée, vous déployez des systèmes de fichiers /hana/data et /hana/log sur un disque géré, et vous associez ces systèmes de fichiers localement à chaque machine virtuelle HANA DB. Procédez comme suit pour créer les volumes de données et de journaux locaux sur chaque machine virtuelle HANA DB.
Configurez la disposition du disque avec le Gestionnaire de volumes logiques (LVM) . L’exemple suivant suppose que chaque machine virtuelle HANA est attachée à trois disques de données, et que ces disques sont utilisés pour créer deux volumes.
[AH] Répertoriez tous les disques disponibles :
ls /dev/disk/azure/scsi1/lun*Exemple de sortie :
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] Créez des volumes physiques pour tous les disques que vous souhaitez utiliser :
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] Créez un groupe de volume pour les fichiers de données. Utilisez un groupe de volume pour les fichiers journaux et un autre pour le répertoire partagé de SAP HANA :
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] Créez les volumes logiques. Un volume linéaire est créé lorsque vous utilisez
lvcreatesans le-icommutateur. Nous vous suggérons de créer un volume agrégé par bandes pour améliorer les performances d’E/S. Alignez les tailles des bandes sur les valeurs documentées dans les configurations de stockage de machine virtuelle SAP HANA. L’argument-idoit indiquer le nombre de volumes physiques sous-jacents et l’argument-Ila taille de bande. Dans cet article, deux volumes physiques sont utilisés pour le volume de données.-il’argument de commutateur est donc défini sur2. La taille de bande pour le volume de données est de256 KiB. Un volume physique est utilisé pour le volume du journal. Vous n’avez donc pas besoin d’utiliser des commutateurs-iou-Iexplicites pour les commandes de volume du journal.Important
Utilisez le commutateur
-iet définissez sa valeur sur le nombre de volumes physiques sous-jacents lorsque vous utilisez plusieurs volumes physiques pour chaque volume de données ou de journal. Utilisez le commutateur-Ipour spécifier la taille de bande lors de la création d’un volume agrégé par bandes. Pour connaître les configurations de stockage recommandées, notamment les tailles de bande et le nombre de disques, consultez Configurations de stockage de machines virtuelles SAP HANA.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] Créez les répertoires de montage et copiez l’UUID de tous les volumes logiques :
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] Créez des entrées
fstabpour les volumes logiques et le montage :sudo vi /etc/fstabInsérez la ligne suivante dans le fichier
/etc/fstab:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2Montez les nouveaux volumes :
sudo mount -a
Installation
Dans cet exemple, pour le déploiement de SAP HANA dans une configuration de montée en charge avec HSR sur des machines virtuelles Azure, vous utilisez HANA 2.0 SP4.
Préparer l’installation de HANA
[AH] Avant l’installation de HANA, définissez le mot de passe racine. Vous pouvez désactiver le mot de passe racine une fois l’installation terminée.
rootCommandepasswdexécuter en tant que pour définir le mot de passe.[1, 2] Modifiez les autorisations sur
/hana/shared.chmod 775 /hana/shared[1] Vérifiez que vous pouvez vous connecter à hana-s1-db2 et hana-s1-db3 via Secure Shell (SSH), sans être invité à entrer un mot de passe. Si ce n’est pas le cas, échangez les
sshclés, comme indiqué dans l’ Utilisation de l'authentification basée sur les clés.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] Vérifiez que vous pouvez vous connecter à hana-s2-db2 et hana-s2-db3 via SSH, sans être invité à entrer un mot de passe. Si ce n’est pas le cas, échangez les
sshclés, comme indiqué dans l’ Utilisation de l'authentification basée sur les clés.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] Installez des packages supplémentaires, qui sont nécessaires pour HANA 2.0 SP4. Pour plus d’informations, consultez la note SAP 2593824 pour RHEL 7.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] Désactivez temporairement le pare-feu, afin qu’il n’interfère pas avec l’installation de HANA. Vous pouvez le réactiver une fois l’installation de HANA terminée.
# Execute as root systemctl stop firewalld systemctl disable firewalld
Installation de HANA sur le premier nœud de chaque site
[1] Installez SAP HANA en suivant les instructions fournies dans le Guide d’installation et de mise à jour de SAP HANA 2.0. Les instructions suivantes indiquent l’installation de SAP HANA sur le premier nœud sur le SITE 1.
Démarrez le
hdblcmprogramme en tant querootà partir du répertoire du logiciel d’installation HANA. Utilisez le paramètreinternal_networket transmettez l’espace d’adressage pour le sous-réseau, qui est utilisé pour la communication interne HANA entre les nœuds../hdblcm --internal_network=10.23.1.128/26À l’invite, entrez les valeurs suivantes :
- Pour Choisir une action, entrez 1 (pour l’installation).
- Pour les composants supplémentaires pour l’installation, entrez 2, 3.
- Pour le chemin d’installation, appuyez sur Entrée (la valeur par défaut est /hana/shared).
- Pour le Nom d’hôte local : appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Voulez-vous ajouter des hôtes au système ? , entrez n.
- Pour l’ID système SAP HANA, entrez HN1.
- Pour le numéro d’instance [00], entrez 03.
- Pour le Groupe de travail de l’hôte local [par défaut], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Sélectionner l’Utilisation du système/Entrer l’index [4] , entrez 4 (pour personnalisé).
- Pour l’Emplacement des Volumes de données [/hana/data/HN1], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour l’Emplacement des Volumes de journaux [/hana/log/HN1], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Restreindre l’allocation de mémoire maximale ? [n], entrez n.
- Pour le Nom d’hôte de certificat pour l’Hôte hana-s1-db1 [hana-s1-db1], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour le Mot de passe de l'utilisateur de l’agent hôte SAP (sapadm) , entrez le mot de passe.
- Pour Confirmer le Mot de passe de l’Utilisateur de l’agent hôte SAP (sapadm) , entrez le mot de passe.
- Pour le Mot de passe de l’Administrateur système (hn1adm) , entrez le mot de passe.
- Pour le Répertoire de démarrage de l’Administrateur système [/usr/SAP/HN1/Home], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour l’Environnement de connexion de l’Administrateur système [/bin/sh], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour l’ID utilisateur de l’Administrateur système [1001], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer l’ID du groupe d’utilisateurs (sapsys) [79], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour le Mot de passe de l’Utilisateur de la base de données système (système) , entrez le mot de passe du système.
- Pour Confirmer le Mot de passe de l’Utilisateur de la base de données système (système) , entrez le mot de passe du système.
- Pour Redémarrer le système après le redémarrage de la machine ? [n], entrez n.
- Pour Voulez-vous continuer (y/n) , validez le résumé et si tout semble correct, entrez y.
[2] Répétez l’étape précédente pour installer SAP HANA sur le premier nœud sur le SITE 2.
[1, 2] Vérifiez global.ini.
Affichez global.ini et assurez-vous que la configuration de la communication interne SAP HANA entre les nœuds est en place. Vérifiez la
communicationsection. Elle doit comporter un espace d’adressage pour le sous-réseauinteretlisteninterfacedoit être défini sur.internal. Vérifiez lainternal_hostname_resolutionsection. Elle doit comporter les adresses IP des machines virtuelles HANA qui appartiennent au sous-réseauinter.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1, 2] Préparez global.ini pour l’installation dans un environnement non partagé, comme décrit dans la note SAP 2080991.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] Redémarrez SAP HANA pour activer les modifications.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1, 2] Vérifiez que l’interface client utilise les adresses IP du sous-réseau
clientpour la communication.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"Pour plus d’informations sur la vérification de la configuration, consultez la note SAP 2183363 - Configuration du réseau interne SAP HANA.
[Ah] Modifiez les autorisations sur les répertoires de données et de journaux pour éviter une erreur d’installation HANA.
sudo chmod o+w -R /hana/data /hana/log[1] Installez les nœuds HANA secondaires. Les exemples d’instructions de cette étape sont pour le SITE 1.
Démarrez le programme
hdblcmrésident en tant queroot.cd /hana/shared/HN1/hdblcm ./hdblcmÀ l’invite, entrez les valeurs suivantes :
- Pour Choisir une action, entrez 2 (pour ajouter des hôtes).
- Pour Entrer les noms d’hôte séparés par une virgule pour ajouter, entrez hana-s1-db2, hana-s1-db3
- Pour les Composants supplémentaires pour l’installation, entrez 2, 3.
- Pour Entrer le Nom d’utilisateur racine [root] , appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Sélectionner des rôles pour l’hôte 'hana-s1-db2' [1] , sélectionnez 1 (pour Worker).
- Pour Entrer le Groupe de basculement hôte pour l’hôte 'hana-s1-db2' [par défaut] , appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer le numéro de partition de stockage pour l’hôte 'hana-s1-db2' [<<attribuer automatiquement>>], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer le Groupe de basculement hôte pour l’hôte 'hana-s1-db2' [par défaut] , appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Sélectionner des rôles pour l’hôte 'hana-s1-db3' [1] , sélectionnez 1 (pour Worker).
- Pour Entrer le Groupe de basculement hôte pour l’hôte 'hana-s1-db3' [par défaut] , appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer le numéro de partition de stockage pour l’hôte 'hana-s1-db3' [<<attribuer automatiquement>>], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Entrer le Groupe de travail pour l’hôte 'hana-s1-db3' [par défaut] , appuyez sur Entrée pour accepter la valeur par défaut.
- Pour le Mot de passe de l’Administrateur système (hn1adm) , entrez le mot de passe.
- Pour Entrer le Mot de passe de l’Utilisateur de l’agent hôte SAP (sapadm) , entrez le mot de passe.
- Pour Confirmer le Mot de passe de l’Utilisateur de l’agent hôte SAP (sapadm) , entrez le mot de passe.
- Pour le Nom d’hôte du certificat pour l’hôte hana-s1-db2 [hana-s1-db2], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour le Nom d’hôte du certificat pour l’hôte hana-s1-db3 [hana-s1-db3], appuyez sur Entrée pour accepter la valeur par défaut.
- Pour Voulez-vous continuer (y/n) , validez le résumé et si tout semble correct, entrez y.
[2] Répétez l’étape précédente pour installer les nœuds SAP HANA secondaires sur le SITE 2.
Configurer la réplication de système SAP HANA 2.0
La procédure suivante vous permet de configurer la réplication du système :
[1] Configurez la réplication de système sur le SITE 1 :
Sauvegardez les bases de données en tant que hn1adm :
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"Copiez les fichiers d’infrastructure à clé publique du système sur le site secondaire :
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Créez le site principal :
hdbnsutil -sr_enable --name=HANA_S1[2] Configurez la réplication de système sur le SITE 2 :
Inscrivez le second site pour démarrer la réplication de système. Exécutez la commande suivante en tant que <hanasid>adm :
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] Vérifiez l’état de la réplication et attendez que toutes les bases de données soient synchronisées.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] Modifiez la configuration HANA afin que la communication pour la réplication du système HANA soit dirigée via les interfaces de réseau virtuel de réplication du système HANA.
Arrêtez HANA sur les deux sites.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBModifiez global.ini pour ajouter le mappage d’hôte pour la réplication de système HANA. Utilisez les adresses IP du
hsrsous-réseau.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3Démarrez HANA sur les deux sites.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
Pour plus d’informations, consultez la Résolution de noms d’hôtes pour la réplication de système.
[Ah] Réactivez le pare-feu et ouvrez les ports nécessaires.
Réactivez le pare-feu.
# Execute as root systemctl start firewalld systemctl enable firewalldOuvrez les ports de pare-feu nécessaires. Vous devrez ajuster les ports pour votre numéro d’instance HANA.
Important
Créez des règles de pare-feu pour autoriser la communication entre nœuds HANA et le trafic client. Les ports requis sont répertoriés sur les ports TCP/IP de tous les produits SAP. Les commandes suivantes sont simplement des exemples. Dans ce scénario, vous utilisez le numéro système 03.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Créez un cluster Pacemaker
Pour créer un cluster Pacemaker de base, suivez les étapes décrites dans Configuration de Pacemaker sur Red Hat Enterprise Linux dans Azure. Incluez toutes les machines virtuelles, y compris le créateur de majorité dans le cluster.
Important
Ne définissez pas quorum expected-votes sur 2. Il ne s’agit pas d’un cluster à deux nœuds. Assurez-vous que la propriété cluster concurrent-fencing est activée, afin que le délimiteur de nœud soit désérialisé.
Créer des ressources de système de fichiers
Pour la partie suivante de ce processus, vous devez créer des ressources de système de fichiers. Voici comment procéder :
[1,2] Arrêtez SAP HANA sur les deux sites de réplication. Exécutez en tant que <sid>adm.
sapcontrol -nr 03 -function StopSystem[Ah] Démontez le système de fichiers
/hana/shared, qui a été temporairement monté pour l’installation sur toutes les machines virtuelles HANA DB. Avant de pouvoir le démonter, vous devez arrêter les processus et les sessions qui utilisent le système de fichiers.umount /hana/shared[1] Créez les ressources de cluster du système de fichiers pour
/hana/shareddans un état désactivé. Vous utilisez--disabledcar vous devez définir les contraintes d’emplacement pour que les montages soient activés.
Vous avez choisi de déployer '/hana/shared' sur le partage NFS sur Azure Files ou le volume NFS sur Azure NetApp Files.Dans cet exemple, le système de fichiers '/hana/shared' est déployé sur Azure NetApp Files et monté sur NFSv4.1. Suivez les étapes décrites dans cette section uniquement si vous utilisez NFS sur Azure NetApp Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
Les valeurs de délai d’expiration suggérées permettent aux ressources de cluster de résister à une pause propre au protocole, liée aux renouvellements de bail NFSv4.1 sur Azure NetApp Files. Pour plus d’informations, consultez les bonnes pratiques relatives à NFS dans NetApp.
Dans cet exemple, le système de fichiers '/hana/shared' est déployé sur NFS sur Azure Files. Suivez les étapes décrites dans cette section uniquement si vous utilisez NFS sur Azure Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueL’attribut
OCF_CHECK_LEVEL=20est ajouté à l’opération d’analyse afin que les opérations d’analyse effectuent un test en lecture/écriture sur le système de fichiers. Sans cet attribut, l’opération d’analyse vérifie uniquement que le système de fichiers est monté. Cela peut être un problème car, en cas de perte de connectivité, le système de fichiers peut rester monté, bien qu’il soit inaccessible.L’attribut
on-fail=fenceest également ajouté à l’opération d’analyse. Avec cette option, si l’opération d’analyse échoue sur un nœud, ce dernier est immédiatement isolé. Sans cette option, le comportement par défaut consiste à arrêter toutes les ressources qui dépendent de la ressource défaillante, puis à redémarrer la ressource qui a échoué, puis à démarrer toutes les ressources qui dépendent de la ressource qui a échoué. Non seulement ce comportement peut prendre beaucoup de temps lorsqu’une ressource SAP HANA dépend de la ressource qui a échoué, mais elle peut également échouer complètement. La ressource SAP HANA ne peut pas s’arrêter correctement, si le partage NFS contenant les binaires HANA est inaccessible.Vous devrez peut-être adapter les délais d’expiration des configurations ci-dessus à la configuration SAP spécifique.
[1] Configurez et vérifiez les attributs du nœud. Tous les nœuds de base de données SAP HANA sur le site de réplication 1 reçoivent l’attribut
S1et tous les nœuds de base de données SAP HANA sur le site de réplication 2 se voient attribuer l’attributS2.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] Configurez les contraintes qui déterminent où les systèmes de fichiers NFS seront montés, et activez les ressources du système de fichiers.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2Lorsque vous activez les ressources du système de fichiers, le cluster monte les systèmes de fichiers
/hana/shared.[Ah] Vérifiez que les volumes de Azure NetApp Files sont montés sous
/hana/shared, sur toutes les machines virtuelles HANA DB sur les deux sites.Par exemple, si vous utilisez Azure NetApp Files :
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Par exemple, si vous utilisez Azure Files NFS :
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] Configurez et clonez les ressources d’attribut et configurez les contraintes comme suit :
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneConseil
Si votre configuration inclut des systèmes de fichiers autres que /
hana/shared, et que ces systèmes de fichiers sont montés par NFS, alors incluez l'optionsequential=false. Cette option permet de s’assurer qu’il n’existe aucune dépendance de classement entre les systèmes de fichiers. Tous les systèmes de fichiers montés par NFS doivent démarrer avant la ressource d’attribut correspondante, mais ils n’ont pas besoin de démarrer dans un ordre particulier les uns par rapport aux autres. Pour plus d’informations, consultez Comment configurer la HSR de montée en charge SAP HANA dans un cluster Pacemaker lorsque les systèmes de fichiers HANA sont des partages NFS.[1] Placez Pacemaker en mode maintenance, en vue de la création des ressources de cluster HANA.
pcs property set maintenance-mode=true
Créer les ressources de cluster SAP HANA
Vous êtes maintenant prêt à créer les ressources de cluster :
[A] Installez l’agent de ressource de montée en charge HANA sur tous les nœuds de cluster, y compris le créateur de majorité.
yum install -y resource-agents-sap-hana-scaleoutNotes
Pour obtenir la version minimale prise en charge du package
resource-agents-sap-hana-scaleoutpour votre version du système d’exploitation, consultez les Stratégies de support pour les clusters à haute disponibilité RHEL - Gestion des SAP HANA dans un cluster.[1, 2] Installez le hook de réplication système HANA sur un nœud HANA DB sur chaque site de réplication système. SAP HANA doit toujours être en cours d’arrêt.
Préparer le hook en tant que
root.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR-ScaleOut/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooksAjusterz
global.ini.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[AH] [AH] Le cluster nécessite une configuration de sudoers sur le nœud de cluster pour <sid>adm. Dans cet exemple, vous obtenez cela en créant un nouveau fichier. Exécutez les commandes en tant que
root.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL Defaults!SOK, SFAIL !requiretty[1,2] Démarrez SAP HANA sur les deux sites de réplication. Exécutez en tant que <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Vérifiez l’installation de hook. Exécutez en tant que <sid>adm sur le site de réplication du système HANA actif.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:32.364379 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:46.905661 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.092016 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] Créez les ressources de cluster HANA. Exécutez les commandes suivantes en tant que
root.Assurez-vous que le cluster est déjà en mode maintenance.
Ensuite, créez la ressource de topologie HANA.
Si vous créez un cluster RHEL 7. x, utilisez les commandes suivantes :pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueSi vous créez un cluster RHEL >= 8.x, utilisez les commandes suivantes :
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueCréez la ressource d’instance HANA.
Remarque
Cet article contient des références à un terme qui n’est plus utilisé par Microsoft. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Si vous créez un cluster RHEL 7. x, utilisez les commandes suivantes :
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueSi vous créez un cluster RHEL >= 8.x, utilisez les commandes suivantes :
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueImportant
Il est judicieux de définir
AUTOMATED_REGISTERsurfalse, pendant que vous effectuez des tests de basculement, afin d’éviter qu’une instance principale défaillante ne s’inscrive automatiquement comme secondaire. Après le test, il est recommandé de définirAUTOMATED_REGISTERsurtrue, afin qu’après la prise en charge, la réplication du système puisse reprendre automatiquement.Créez l’adresse IP virtuelle et les ressources associées.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03Créez les contraintes de cluster.
Si vous créez un cluster RHEL 7. x, utilisez les commandes suivantes :
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueSi vous créez un cluster RHEL >= 8.x, utilisez les commandes suivantes :
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] Placez le cluster en mode maintenance. Assurez-vous que l’état du cluster est
oket que toutes les ressources sont démarrées.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupNotes
Les délais d’expiration de la configuration précédente sont simplement des exemples et doivent peut-être être adaptés à la configuration HANA spécifique. Par exemple, vous devrez peut-être augmenter le délai de démarrage, si le démarrage de la base de données SAP HANA prend plus de temps.
Configurez la réplication du système HANA actif/en lecture activée
À compter de SAP HANA 2.0 SPS 01, SAP autorise les configurations actives/en lecture activées pour la réplication du système SAP HANA. Avec cette fonctionnalité, vous pouvez utiliser activement les systèmes secondaires de la réplication système SAP HANA pour les charges de travail nécessitant beaucoup de ressources de lecture. Pour prendre en charge une configuration de ce type dans un cluster, vous avez besoin d’une deuxième adresse IP virtuelle, qui permet aux clients d’accéder à la base de données SAP HANA compatible avec la lecture secondaire. Pour vous assurer que le site de réplication secondaire est toujours accessible après une prise en charge, le cluster doit déplacer l’adresse IP virtuelle avec le réplica secondaire de la ressource SAP HANA.
Cette section décrit les étapes supplémentaires que vous devez suivre pour gérer ce type de réplication système dans un cluster haute disponibilité Red Hat avec la deuxième adresse IP virtuelle.
Avant de poursuivre, assurez-vous que vous avez entièrement configuré un cluster Red Hat haute disponibilité, en gérant une base de données SAP HANA, comme décrit précédemment dans cet article.
Configuration supplémentaire dans l’Équilibreur de charge Azure pour une installation active/en lecture activée
Pour poursuivre la configuration de votre deuxième adresse IP virtuelle, assurez-vous d’avoir configuré Azure Load Balancer comme décrit dans Configurer Azure Load Balancer.
Pour l’équilibreur de charge standard, suivez ces étapes supplémentaires sur le même équilibreur de charge que vous avez créé dans la section précédente.
Créez un deuxième pool d’adresses IP frontales :
- Ouvrez l’équilibrage de charge, sélectionnez le Pool d’adresses IP frontales, puis cliquez sur Ajouter.
- Entrez le nom du deuxième pool d’adresses IP frontales (par exemple hana-secondaryIP).
- Définissez l’Affectation sur Statique et entrez l’adresse IP (par exemple, 10.23.0.19).
- Sélectionnez OK.
- Une fois le pool d’adresses IP frontal créé, notez son adresse IP.
Créez ensuite une sonde d’intégrité :
- Ouvrez l’équilibrage de charge, sélectionnez les sondes d’intégrité, puis cliquez sur Ajouter.
- Entrez le nom de la nouvelle sonde d’intégrité (par exemple, hana-secondaryhp).
- Sélectionnez TCP comme protocole et le port 62603. Consersez la valeur Intervalle à 5, et la valeur Seuil de défaillance à 2.
- Sélectionnez OK.
Ensuite, créez les règles d’équilibrage de charge :
- Ouvrez l’équilibrage de charge, sélectionnez Règles d’équilibrage de charge, puis cliquez sur Ajouter.
- Entrez le nom de la nouvelle règle d’équilibrage de charge (par exemple, hana-secondarylb).
- Sélectionnez l’adresse IP frontale, le pool principal et la sonde d’intégrité que vous avez créés (par exemple,hana-secondaryIP, hana-backend et hana-secondaryhp).
- Sélectionnez Ports HA.
- Veillez à activer l’IP flottante .
- Sélectionnez OK.
Configurez la réplication du système HANA actif/en lecture activée
La procédure de configuration de la réplication du système HANA est décrite dans la section Configurer la réplication du système SAP HANA 2.0 . Si vous déployez un scénario secondaire avec accès en lecture, pendant que vous configurez la réplication du système sur le second nœud, exécutez la commande suivante en tant que hanasidadm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
Ajoutez une ressource d’adresse IP virtuelle secondaire pour une installation active/en lecture activée
Vous pouvez configurer la deuxième adresse IP virtuelle et les contraintes supplémentaires avec les commandes suivantes. Si l’instance secondaire est en panne, l’adresse IP virtuelle secondaire sera basculée sur l’instance primaire.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
Assurez-vous que l’état du cluster est ok et que toutes les ressources sont démarrées. La deuxième adresse IP virtuelle s’exécutera sur le site secondaire avec la ressource secondaire SAP HANA.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
Dans la section suivante, vous trouverez l’ensemble typique de tests de basculement à exécuter.
Lorsque vous testez un cluster HANA configuré avec un réplica secondaire accessible en lecture, tenez compte du comportement suivant de la deuxième adresse IP virtuelle :
Lorsque la ressource de cluster SAPHana_HN1_HDB03 est déplacée vers le site secondaire (S2), la deuxième adresse IP virtuelle est déplacée vers l’autre site, hana-s1-db1. Si vous avez configuré
AUTOMATED_REGISTER="false"et que la réplication du système HANA n’est pas inscrite automatiquement, la deuxième adresse IP virtuelle s’exécutera sur hana-s2-db1.Lorsque vous testez une panne de serveur, les ressources de la seconde adresse IP virtuelle (secvip_HN1_03) et les ressources de port de l’Équilibreur de charge Azure (secnc_HN1_03) s’exécutent sur le serveur principal, en plus des ressources IP virtuelles principales. Si le serveur secondaire est défaillant, les applications qui sont connectées à la base de données HANA activée par la lecture se connectent à la base de données HANA primaire. Il s’agit du comportement attendu. Il permet aux applications qui sont connectées à la base de données HANA activée en lecture de fonctionner lorsqu’un serveur secondaire n’est pas disponible.
Pendant le basculement et le secours, les connexions existantes pour les applications qui utilisent la seconde adresse IP virtuelle pour se connecter à la base de données HANA peuvent être interrompues.
Test de basculement SAP HANA
Avant de commencer un test, vérifiez l’état du cluster et de la réplication de système SAP HANA.
Vérifiez qu’aucune action de cluster n’a échoué.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Vérifiez que la réplication du système SAP HANA est synchronisée.
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
Vérifiez la configuration du cluster pour un scénario d’échec lorsqu’un nœud perd l’accès au partage NFS (
/hana/shared).Les agents de ressource SAP HANA dépendent des fichiers binaires, stockés sur
/hana/shared, pour effectuer des opérations pendant le basculement. Le système de fichiers/hana/sharedest monté sur NFS dans la configuration présentée. Un test qui peut être effectué consiste à créer une règle de pare-feu temporaire pour bloquer l’accès au système de fichiers monté sur NFS/hana/sharedet sur une des machines virtuelles du site principal. Cette approche valide le basculement du cluster en cas de perte de l’accès à/hana/sharedsur le site de réplication de système actif.Résultat attendu : lorsque vous bloquez l’accès au système de fichiers monté sur NFS
/hana/sharedsur l’une des machines virtuelles du site principal, l’opération d’analyse qui effectue une opération de lecture/écriture sur le système de fichiers échoue, car elle n’est pas en mesure d’accéder au système de fichiers et déclenche le basculement de ressource HANA. Le même résultat est attendu lorsque votre nœud HANA perd l’accès au partage NFS.Vous pouvez vérifier l’état des ressources du cluster en exécutant
crm_monoupcs status. État des ressources avant le début du test :# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Pour simuler une défaillance pour
/hana/shared:- Si vous utilisez NFS sur ANF, commencez par confirmer l’adresse IP du volume ANF
/hana/sharedsur le site principal. Pour ce faire, exécutezdf -kh|grep /hana/shared. - Si vous utilisez NFS sur Azure Files, commencez par déterminer l’adresse IP du point de terminaison privé de votre compte de stockage.
Ensuite, configurez une règle de pare-feu temporaire pour bloquer l’accès à l’adresse IP du système de fichiers NFS
/hana/shareden exécutant la commande suivante sur l’une des machines virtuelles du site de réplication de système HANA principal.Dans cet exemple, la commande a été exécutée sur hana-s1-db1 pour le volume ANF
/hana/shared.iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROPLe redémarrage ou l’arrêt de la machine virtuelle HANA qui a perdu l’accès vers
/hana/shareddépend de la configuration du cluster. Les ressources de cluster sont migrées vers l’autre site de réplication de système HANA.Si le cluster n’a pas démarré sur la machine virtuelle qui a été redémarrée, démarrez le cluster en exécutant la commande suivante :
# Start the cluster pcs cluster startAu démarrage du cluster, le système de fichiers
/hana/sharedest automatiquement monté. Si vous définissezAUTOMATED_REGISTER="false", vous devez configurer la réplication du système SAP HANA sur le site secondaire. Dans ce cas, vous pouvez exécuter ces commandes pour reconfigurer SAP HANA comme secondaire.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03État des ressources, après le test :
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- Si vous utilisez NFS sur ANF, commencez par confirmer l’adresse IP du volume ANF
Il est judicieux de tester minutieusement la configuration des clusters SAP HANA, en effectuant également les tests décrits dans HA pour SAP HANA sur des machines virtuelles Azure sur RHEL.
Étapes suivantes
- Planification et implémentation de machines virtuelles Azure pour SAP
- Déploiement de machines virtuelles Azure pour SAP
- Déploiement SGBD de machines virtuelles Azure pour SAP
- Volumes NFS v4.1 sur Azure NetApp Files pour SAP HANA
- Pour savoir comment établir une haute disponibilité et planifier la récupération d’urgence de SAP HANA sur des machines virtuelles Azure, consultez Haute disponibilité de SAP HANA sur des machines virtuelles Azure.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour