Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Arrêtez ce que vous faites et demandez à vos collègues de définir le terme « Cloud Native ». Il y a une bonne chance que vous obteniez plusieurs réponses différentes.
Commençons par une définition simple :
L’architecture et les technologies natives cloud constituent une approche de la conception, de la construction et de l’exploitation des charges de travail intégrées au cloud et tirent pleinement parti du modèle de cloud computing.
Cloud Native Computing Foundation fournit la définition officielle :
Les technologies natives cloud permettent aux organisations de créer et d’exécuter des applications évolutives dans des environnements modernes, dynamiques tels que des clouds publics, privés et hybrides. Les conteneurs, les maillages de service, les microservices, l’infrastructure immuable et les API déclaratives illustrent cette approche.
Ces techniques permettent des systèmes faiblement couplés qui sont résilients, gérables et observables. Combinés à une automatisation robuste, ils permettent aux ingénieurs d’apporter des modifications à impact élevé fréquemment et prévisibles avec un minimum de peine.
Le cloud natif est à propos de la vitesse et de l’agilité. Les systèmes métier évoluent de l’activation des capacités métier aux armes de transformation stratégique qui accélèrent la vitesse et la croissance de l’entreprise. Il est impératif de mettre sans délai de nouvelles idées sur le marché.
En même temps, les systèmes métier sont devenus de plus en plus complexes avec les utilisateurs exigeant plus. Ils s’attendent à une réactivité rapide, à des fonctionnalités innovantes et à un temps d’arrêt nul. Les problèmes de performances, les erreurs récurrentes et l’incapacité à se déplacer rapidement ne sont plus acceptables. Vos utilisateurs visiteront votre concurrent. Les systèmes natifs cloud sont conçus pour adopter des changements rapides, une grande échelle et une résilience.
Voici quelques entreprises qui ont implémenté des techniques natives cloud. Réfléchissez à la vitesse, à l’agilité et à la scalabilité qu’elles ont obtenues.
| Entreprise | Expérience |
|---|---|
| Netflix | Dispose de plus de 600 services en production. Déploie 100 fois par jour. |
| Uber | Dispose de plus de 1 000 services en production. Déploie plusieurs milliers de fois par semaine. |
| Dispose de plus de 3 000 services en production. Déploie 1 000 fois par jour. |
Comme vous pouvez le voir, Netflix, Uber et WeChat exposent des systèmes natifs cloud qui se composent de nombreux services indépendants. Ce style architectural leur permet de répondre rapidement aux conditions du marché. Ils mettent instantanément à jour de petites zones d’une application dynamique et complexe, sans redéploiement complet. Ils adaptent individuellement les services en fonction des besoins.
Les piliers du cloud computing natif
La vitesse et l’agilité du cloud natif dérivent de nombreux facteurs. Avant tout, l’infrastructure cloud. Mais il y en a plus : cinq autres piliers fondamentaux présentés dans la figure 1-3 fournissent également la pierre angulaire des systèmes natifs cloud.
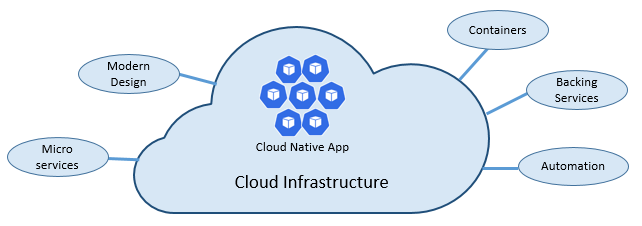
Figure 1-3. Piliers fondamentaux natifs du cloud
Prenons un certain temps pour mieux comprendre l’importance de chaque pilier.
Le cloud
Les systèmes natifs cloud tirent pleinement parti du modèle de service cloud.
Conçus pour prospérer dans un environnement cloud dynamique et virtualisé, ces systèmes utilisent largement l’infrastructure de calcul PaaS (Platform as a Service) et les services managés. Ils considèrent l’infrastructure sous-jacente comme jetable - approvisionnée en quelques minutes et redimensionnée, mise à l’échelle ou détruite à la demande via l’automatisation.
Considérez la différence entre la façon dont nous traitons les animaux de compagnie et les produits de base. Dans un centre de données traditionnel, les serveurs sont traités comme des animaux de compagnie : une machine physique, avec un nom explicite et une prise en charge. Vous effectuez une mise à l’échelle en ajoutant d’autres ressources à la même machine (scale-up). Si le serveur tombe malade, vous le soignez pour qu'il retrouve la santé. Si le serveur n’est pas disponible, tout le monde remarque.
Le modèle de service des produits de base est différent. Vous approvisionnez chaque instance en tant que machine virtuelle ou conteneur. Ils sont identiques et attribués à un identificateur système tel que Service-01, Service-02, etc. Vous effectuez une mise à l’échelle en créant davantage d’instances (scale-out). Personne ne remarque quand une instance devient indisponible.
Le modèle de produits de base embrasse l’infrastructure immuable. Les serveurs ne sont pas réparés ou modifiés. Si l'une échoue ou nécessite une mise à jour, elle est détruite et une nouvelle est approvisionnée, et tout cela est effectué par automatisation.
Les systèmes natifs cloud adoptent le modèle de service des produits de base. Ils continuent à s’exécuter à mesure que l’infrastructure est mise à l’échelle ou hors service, sans tenir compte des machines sur lesquelles elles s’exécutent.
La plateforme cloud Azure prend en charge ce type d’infrastructure hautement élastique avec des fonctionnalités de mise à l’échelle, d’auto-réparation et de supervision automatiques.
Conception moderne
Comment concevoir une application native cloud ? À quoi ressemble votre architecture ? À quels principes, modèles et bonnes pratiques respecteriez-vous ? Quelles sont les préoccupations liées à l’infrastructure et aux opérations ?
L'application Twelve-Factor
Une méthodologie largement acceptée pour la construction d’applications basées sur le cloud est l’applicationTwelve-Factor. Il décrit un ensemble de principes et de pratiques que les développeurs suivent pour construire des applications optimisées pour les environnements cloud modernes. Une attention particulière est accordée à la portabilité entre les environnements et l’automatisation déclarative.
S’il s’applique à n’importe quelle application web, de nombreux praticiens considèrent Twelve-Factor une base solide pour la création d’applications natives cloud. Les systèmes basés sur ces principes peuvent déployer et mettre à l’échelle rapidement et ajouter des fonctionnalités pour réagir rapidement aux changements du marché.
Le tableau suivant met en évidence la méthodologie de Twelve-Factor :
| Facteur | Explication |
|---|---|
| 1 - Base de code | Base de code unique pour chaque microservice, stockée dans son propre référentiel. Suivi avec le contrôle de version, il peut être déployé sur plusieurs environnements (QA, Préproduction, Production). |
| 2 - Dépendances | Chaque microservice isole et emballe ses propres dépendances, adopte les modifications sans avoir d’impact sur l’ensemble du système. |
| 3 - Configurations | Les informations de configuration sont déplacées hors du microservice et externalisées par le biais d’un outil de gestion de configuration en dehors du code. Le même déploiement peut se propager entre les environnements avec la configuration appropriée appliquée. |
| 4 - Services de stockage | Les ressources auxiliaires (magasins de données, caches, répartiteurs de messages) doivent être exposées via une URL adressable. Cela dissocie la ressource de l’application, ce qui lui permet d’être interchangeable. |
| 5 - Construire, Publier, Exécuter | Chaque version doit appliquer une séparation stricte entre les phases de génération, de mise en production et d’exécution. Chacun doit être étiqueté avec un ID unique et être capable de revenir en arrière. Les systèmes CI/CD modernes aident à respecter ce principe. |
| 6 – Processus | Chaque microservice doit s’exécuter dans son propre processus, isolé des autres services en cours d’exécution. Externalisez l’état requis à un service de stockage tel qu’un cache distribué ou un magasin de données. |
| 7 – Liaison de port | Chaque microservice doit être autonome avec ses interfaces et ses fonctionnalités exposées sur son propre port. Cela permet d’isoler d’autres microservices. |
| 8 – Concurrence | Lorsque la capacité doit augmenter, effectuez une mise à l'échelle horizontale des services sur plusieurs processus identiques (copies) plutôt que d'opérer une mise à l'échelle verticale d'une seule grande instance sur l'ordinateur le plus puissant disponible. Développez l’application pour qu’elle effectue un scale-out simultané dans des environnements cloud transparents. |
| 9 – Élimination | Les instances de service doivent pouvoir être éliminées. Privilégiez le démarrage rapide pour augmenter les opportunités d’extensibilité et les arrêts en douceur pour que le système reste dans un état correct. Les conteneurs Docker ainsi qu’un orchestrateur répondent intrinsèquement à cette exigence. |
| 10 - La parité entre le développement et la production | Conservez les environnements dans le cycle de vie de l’application aussi similaire que possible, ce qui évite les raccourcis coûteux. Ici, l’adoption des conteneurs peut considérablement contribuer en favorisant le même environnement d’exécution. |
| 11 – Journalisation | Traitez les journaux générés par les microservices en tant que flux d’événements. Traitez-les avec un agrégateur d’événements. Propager les données de journal vers des outils d'analyse et de gestion des journaux comme Azure Monitor ou Splunk, et finalement vers un archivage à long terme. |
| 12 - Processus d’administration | Exécutez des tâches d’administration/gestion, telles que le nettoyage des données ou l’analytique informatique, en tant que processus ponctuels. Utilisez des outils indépendants pour appeler ces tâches à partir de l’environnement de production, mais séparément de l’application. |
Dans le livre, Beyond the Twelve-Factor App, auteur Kevin Hoffman détaille chacun des 12 facteurs originaux (écrits en 2011). En outre, il aborde trois facteurs supplémentaires qui reflètent la conception moderne de l’application cloud d’aujourd’hui.
| Nouveau facteur | Explication |
|---|---|
| 13 - API First | Transformez tout en service. Supposons que votre code sera consommé par un client frontal, une passerelle ou un autre service. |
| 14 - Télémétrie | Sur une station de travail, vous avez une visibilité approfondie sur votre application et son comportement. Dans le cloud, cela n’est pas le cas. Assurez-vous que votre conception inclut la collecte de données de surveillance, spécifiques au domaine, ainsi que de données de santé/système. |
| 15 - Authentification/ Autorisation | Implémentez l’identité à partir du début. Considérez les fonctionnalités RBAC (contrôle d’accès en fonction du rôle) disponibles dans les clouds publics. |
Nous allons faire référence à un grand nombre des 12 facteurs de ce chapitre et tout au long du livre.
Azure Well-Architected Framework
La conception et le déploiement de charges de travail basées sur le cloud peuvent être difficiles, en particulier lors de l’implémentation de l’architecture native cloud. Microsoft fournit des meilleures pratiques standard pour vous aider et votre équipe à fournir des solutions cloud robustes.
Microsoft Well-Architected Framework fournit un ensemble d’ensembles guidants qui peuvent être utilisés pour améliorer la qualité d’une charge de travail native cloud. Le framework se compose de cinq piliers de l’excellence de l’architecture :
| Principes | Descriptif |
|---|---|
| Gestion des coûts | Concentrez-vous sur la génération anticipée de la valeur incrémentielle. Appliquez les principes Build-Measure-Learn pour accélérer le temps de commercialisation tout en évitant les solutions gourmandes en capital. À l’aide d’une stratégie de paiement selon l'utilisation, investissez à mesure que vous augmentez vos capacités, plutôt que de faire un investissement important dès le départ. |
| excellence opérationnelle | Automatisez l’environnement et les opérations pour augmenter la vitesse et réduire l’erreur humaine. Restaurez les mises à jour des problèmes ou restaurez-les par progression rapidement. Implémentez la surveillance et les diagnostics dès le début. |
| Efficacité des performances | Répondez efficacement aux demandes placées sur vos charges de travail. Privilégiez la mise à l’échelle horizontale (scale-out) et concevez-la dans vos systèmes. Effectuez continuellement des tests de performances et de charge pour identifier les goulots d’étranglement potentiels. |
| Fiabilité | Créez des charges de travail résilientes et disponibles. La résilience permet aux charges de travail de récupérer des défaillances et de continuer à fonctionner. La disponibilité garantit aux utilisateurs l’accès à votre charge de travail à tout moment. Concevoir des applications pour s’attendre à des échecs et à les récupérer. |
| Sécurité | Implémentez la sécurité tout au long du cycle de vie d’une application, de la conception et de l’implémentation au déploiement et aux opérations. Faites attention à la gestion des identités, à l’accès à l’infrastructure, à la sécurité des applications et à la souveraineté et au chiffrement des données. |
Pour commencer, Microsoft fournit un ensemble d’évaluations en ligne pour vous aider à évaluer vos charges de travail cloud actuelles par rapport aux cinq piliers bien conçus.
Microservices
Les systèmes natifs cloud adoptent les microservices, un style architectural populaire pour construire des applications modernes.
Construit en tant qu’ensemble distribué de petits services indépendants qui interagissent via une infrastructure partagée, les microservices partagent les caractéristiques suivantes :
Chacun implémente une fonctionnalité métier spécifique dans un contexte de domaine plus grand.
Chacun est développé de manière autonome et peut être déployé indépendamment.
Chacun est autonome encapsulant sa propre technologie de stockage de données, ses dépendances et sa plateforme de programmation.
Chacune s’exécute dans son propre processus et communique avec d’autres utilisateurs à l’aide de protocoles de communication standard tels que HTTP/HTTPS, gRPC, WebSockets ou AMQP.
Ils composent ensemble pour former une application.
La figure 1-4 contraste une approche d’application monolithique avec une approche de microservices. Notez comment le monolithe est composé d’une architecture en couches, qui s’exécute dans un seul processus. Il consomme généralement une base de données relationnelle. Toutefois, l’approche de microservice sépare les fonctionnalités en services indépendants, chacune avec sa propre logique, son état et ses données. Chaque microservice héberge son propre magasin de données.
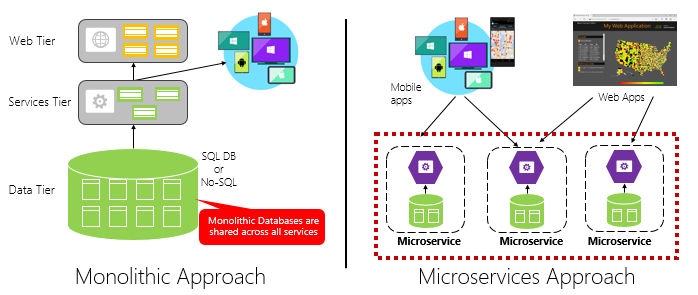
Figure 1-4. Architecture monolithique et microservices
Notez comment les microservices favorisent le principe processus de l’applicationTwelve-Factor, décrit plus haut dans le chapitre.
Factor #6 spécifie « Chaque microservice doit s’exécuter dans son propre processus, isolé des autres services en cours d’exécution ».
Pourquoi les microservices ?
Les microservices offrent une agilité.
Plus haut dans le chapitre, nous avons comparé une application eCommerce créée en tant que monolithe à celle des microservices. Dans l’exemple, nous avons vu quelques avantages clairs :
Chaque microservice a un cycle de vie autonome et peut évoluer indépendamment et déployer fréquemment. Vous n’avez pas besoin d’attendre une version trimestrielle pour déployer une nouvelle fonctionnalité ou une mise à jour. Vous pouvez mettre à jour une petite zone d’une application dynamique avec moins de risque de perturber l’ensemble du système. La mise à jour peut être effectuée sans redéploiement complet de l’application.
Chaque microservice peut être mis à l’échelle indépendamment. Au lieu de mettre à l’échelle l’ensemble de l’application en tant qu’unité unique, vous effectuez un scale-out uniquement de ces services qui nécessitent plus de puissance de traitement pour répondre aux niveaux de performances souhaités et aux contrats de niveau de service. La mise à l’échelle affinée offre un meilleur contrôle de votre système et permet de réduire les coûts globaux à mesure que vous mettez à l’échelle des parties de votre système, pas tout.
Un excellent guide de référence pour comprendre les microservices est .NET Microservices : Architecture pour les applications .NET conteneurisées. Le livre explore en détail la conception et l’architecture des microservices. Il s’agit d’un compagnon pour une architecture de référence de microservices complète disponible en téléchargement gratuit depuis Microsoft.
Développement de microservices
Les microservices peuvent être créés sur n’importe quelle plateforme de développement moderne.
La plateforme Microsoft .NET est un excellent choix. Gratuit et open source, il dispose de nombreuses fonctionnalités intégrées qui simplifient le développement de microservice. .NET est multiplateforme. Les applications peuvent être créées et exécutées sur Windows, macOS et la plupart des versions de Linux.
.NET est très performant et s’est bien marqué par rapport à Node.js et à d’autres plateformes concurrentes. Il est intéressant de noter que TechEmpower a mené un vaste ensemble de benchmarks de performances sur de nombreuses plateformes et infrastructures d’applications web. .NET s’est marqué dans le top 10 - bien au-dessus de Node.js et d’autres plateformes concurrentes.
.NET est géré par Microsoft et la communauté .NET sur GitHub.
Défis liés aux microservices
Bien que les microservices cloud natifs distribués puissent fournir une agilité et une vitesse immenses, ils présentent de nombreux défis :
Communication
Comment les applications clientes front-end communiquent-elles avec les microservices principaux back-end ? Allez-vous autoriser la communication directe ? Ou bien, allez-vous faire abstraction des microservices back-end avec une façade de passerelle qui offre une flexibilité, un contrôle et une sécurité ?
Comment les microservices principaux principaux communiqueront-ils entre eux ? Autoriserez-vous des appels HTTP directs qui peuvent augmenter le couplage et avoir un impact sur les performances et l’agilité ? Ou pouvez-vous envisager de dissocier la messagerie avec des technologies de file d’attente et de rubrique ?
La communication est abordée dans le chapitre des modèles de communication natifs cloud .
Résilience
Une architecture de microservices déplace votre système de la communication réseau au sein du processus vers une hors processus. Dans une architecture distribuée, que se passe-t-il quand le service B ne répond pas à un appel réseau à partir du service A ? Ou, que se passe-t-il lorsque le service C devient temporairement indisponible et que d’autres services qui l’appellent deviennent bloqués ?
La résilience native au cloud est abordée dans le chapitre Cloud-native resiliency.
Données distribuées
Par conception, chaque microservice encapsule ses propres données, exposant les opérations via son interface publique. Si c’est le cas, comment interroger des données ou implémenter une transaction entre plusieurs services ?
Les données distribuées sont traitées dans le chapitre des modèles de données natifs cloud .
Secrets
Comment vos microservices stockent-ils et gèrent-ils en toute sécurité les secrets et les données de configuration sensibles ?
Les secrets sont couverts en détail dans la sécurité native du cloud.
Gérer la complexité avec Dapr
Dapr est un runtime d’application open source distribué. Grâce à une architecture de composants enfichables, il simplifie considérablement le raccordement derrière les applications distribuées. Il fournit un collage dynamique qui lie votre application avec des fonctionnalités d’infrastructure et des composants prédéfinis à partir du runtime Dapr. La figure 1-5 montre Dapr de 20 000 pieds.
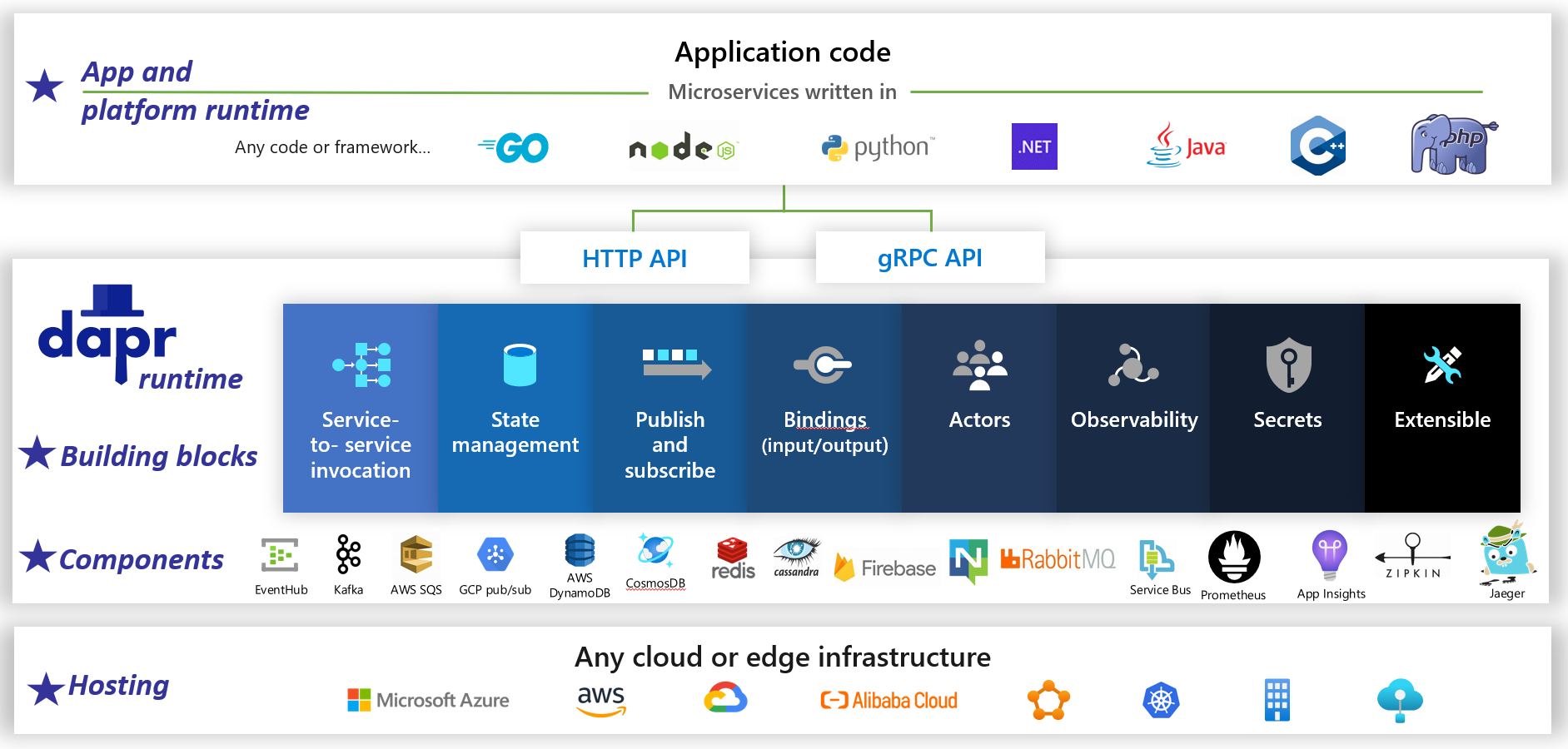 Figure 1-5. Dapr à 20 000 pieds.
Figure 1-5. Dapr à 20 000 pieds.
Dans la ligne supérieure de la figure, notez comment Dapr fournit des kits SDK spécifiques au langage pour les plateformes de développement populaires. Dapr v1 inclut la prise en charge de .NET, Go, Node.js, Python, PHP, Java et JavaScript.
Bien que les kits SDK spécifiques au langage améliorent l’expérience du développeur, Dapr est indépendant de la plateforme. Sous le capot, le modèle de programmation de Dapr expose les fonctionnalités par le biais de protocoles de communication HTTP/gRPC standard. Toute plateforme de programmation peut appeler Dapr via ses API HTTP et gRPC natives.
Les boîtes bleues situées au centre de la figure représentent les blocs de construction Dapr. Chacune expose du code de plomberie prédéfini pour une fonctionnalité d’application distribuée que votre application peut consommer.
La ligne composants représente un grand ensemble de composants d’infrastructure prédéfinis que votre application peut consommer. Considérez les composants comme du code d’infrastructure que vous n’avez pas besoin d’écrire.
La ligne inférieure met en évidence la portabilité de Dapr et les différents environnements dans lesquels il peut s’exécuter.
À l’avenir, Dapr a le potentiel d’avoir un impact profond sur le développement d’applications natives cloud.
Conteneurs
Il est naturel d’entendre le terme conteneur mentionné dans n’importe quelle conversation cloud native. Dans le livre, Cloud Native Patterns, l’auteur Cornelia Davis observe que « Les conteneurs sont un excellent outil de logiciel natif cloud ». Cloud Native Computing Foundation place la conteneurisation de microservice comme première étape de leur Cloud-Native Trail Map - conseils pour les entreprises qui commencent leur parcours cloud natif.
{kind=link}
La conteneurisation d'un microservice est facile et directe. Le code, ses dépendances et son runtime sont empaquetés dans un fichier binaire appelé image conteneur. Les images sont stockées dans un registre de conteneurs, qui joue le rôle de référentiel ou de bibliothèque pour les images. Un registre peut se trouver sur votre ordinateur de développement, dans votre centre de données ou dans un cloud public. Docker gère lui-même un registre public via Docker Hub. Le cloud Azure propose un registre de conteneurs privé pour stocker des images conteneur proches des applications cloud qui les exécuteront.
Quand une application démarre ou augmente, vous convertissez l’image conteneur en une instance de conteneur en cours d’exécution. L’instance s’exécute sur n’importe quel ordinateur sur lequel un moteur d’exécution de conteneur est installé. Vous pouvez avoir autant d’instances du service conteneurisé que nécessaire.
La figure 1-6 montre trois microservices différents, chacun dans son propre conteneur, qui s’exécutent sur un seul hôte.
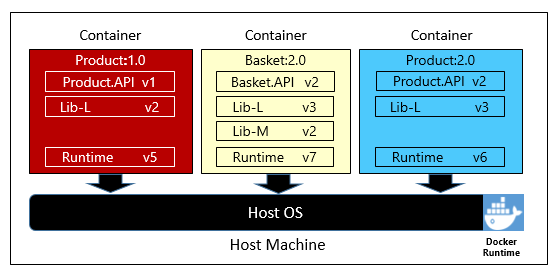
Figure 1-6. plusieurs conteneurs s’exécutant sur un hôte de conteneurs
Notez comment chaque conteneur conserve son propre ensemble de dépendances et d’exécution, qui peuvent être différents des uns des autres. Ici, nous voyons différentes versions du microservice Product s’exécutant sur le même hôte. Chaque conteneur partage une tranche du système d’exploitation hôte sous-jacent, de la mémoire et du processeur, mais il est isolé les uns des autres.
Notez comment le modèle de conteneur adopte le principe dépendances de l’applicationTwelve-Factor.
Factor #2 spécifie que « Chaque microservice isole et packages ses propres dépendances, embrassant les modifications sans avoir d’impact sur l’ensemble du système ».
Les conteneurs prennent en charge les charges de travail Linux et Windows. Le cloud Azure s’intègre ouvertement aux deux. Il est intéressant de noter que c’est Linux, et non Windows Server, qui est devenu le système d’exploitation le plus populaire dans Azure.
Bien que plusieurs fournisseurs de conteneurs existent, Docker a capturé la part du lion du marché. L’entreprise est pionnière dans le mouvement des conteneurs de logiciels. Il est devenu la norme de facto pour l’empaquetage, le déploiement et l’exécution d’applications natives cloud.
Pourquoi les conteneurs ?
Les conteneurs offrent une portabilité et garantissent la cohérence entre les environnements. Encapsulant tout dans un seul package, vous isolez le microservice et ses dépendances de l’infrastructure sous-jacente.
Vous pouvez déployer le conteneur dans n’importe quel environnement qui héberge le moteur d’exécution Docker. Les charges de travail conteneurisées éliminent également les frais de préconfigurer chaque environnement avec des infrastructures, des bibliothèques de logiciels et des moteurs d’exécution.
En partageant le système d’exploitation sous-jacent et les ressources hôtes, un conteneur a une empreinte beaucoup plus petite qu’une machine virtuelle complète. La plus petite taille augmente la densité, ou le nombre de microservices, qu’un hôte donné peut exécuter à la fois.
Orchestration de conteneurs
Bien que les outils tels que Docker créent des images et exécutent des conteneurs, vous avez également besoin d’outils pour les gérer. La gestion des conteneurs est effectuée avec un programme logiciel spécial appelé orchestrateur de conteneurs. Fonctionnant à grande échelle avec de nombreux conteneurs fonctionnant indépendamment, l'orchestration est indispensable.
La figure 1-7 montre les tâches de gestion que les orchestrateurs de conteneurs automatisent.
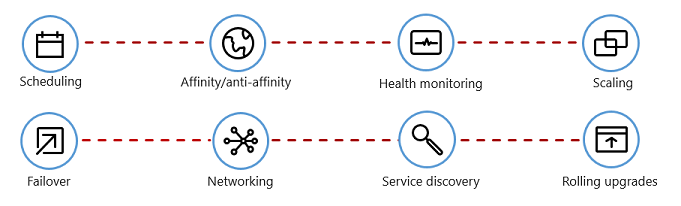
Figure 1-7. Que font les orchestrateurs de conteneurs
Le tableau suivant décrit les tâches d’orchestration courantes.
| Tâches | Explication |
|---|---|
| Planification | Provisionnez automatiquement des instances de conteneur. |
| Affinité/anti-affinité | Provisionnez des conteneurs à proximité ou loin de l’autre, ce qui contribue à la disponibilité et aux performances. |
| Surveillance de la santé | Détectez et corrigez automatiquement les défaillances. |
| Basculement | Reprovisionner automatiquement une instance ayant échoué sur un ordinateur sain. |
| Croissance | Ajoutez ou supprimez automatiquement une instance de conteneur pour répondre à la demande. |
| Réseautage | Gestion d’une superposition réseau pour la communication de conteneur. |
| Découverte de services | Permettre aux conteneurs de se localiser les uns les autres. |
| Mises à niveau progressives | Coordonnez les mises à niveau incrémentielles avec un déploiement sans temps d’arrêt. Restaurez automatiquement les modifications problématiques. |
Notez comment les orchestrateurs de conteneurs adoptent les principes de disposabilité et de concurrence de l'applicationTwelve-Factor.
Factor #9 spécifie que « Les instances de service doivent être jetables, ce qui favorise les start-ups rapides pour augmenter les opportunités d’extensibilité et les arrêts appropriés pour laisser le système dans un état correct ». Les conteneurs Docker ainsi qu’un orchestrateur répondent intrinsèquement à cette exigence. »
Factor #8 spécifie que « Les services effectuent un scale-out sur un grand nombre de petits processus identiques (copies) au lieu de monter en puissance une seule grande instance sur l’ordinateur le plus puissant disponible ».
Bien que plusieurs orchestrateurs de conteneurs existent, Kubernetes est devenu la norme de facto pour le monde natif du cloud. Il s’agit d’une plateforme portable, extensible et open source pour la gestion des charges de travail conteneurisées.
Vous pouvez héberger votre propre instance de Kubernetes, mais vous êtes alors responsable de l’approvisionnement et de la gestion de ses ressources, ce qui peut être complexe. Le cloud Azure propose Kubernetes en tant que service managé. Azure Kubernetes Service (AKS) et Azure Red Hat OpenShift (ARO) vous permettent de tirer pleinement parti des fonctionnalités et de la puissance de Kubernetes en tant que service managé, sans avoir à l’installer et à la gérer.
L’orchestration de conteneurs est décrite en détail dans Mise à l’échelle des applications natives Cloud.
Services de stockage
Les systèmes natifs cloud dépendent de nombreuses ressources auxiliaires différentes, telles que les magasins de données, les répartiteurs de messages, la surveillance et les services d’identité. Ces services sont appelés services de stockage.
La figure 1-8 montre de nombreux services de stockage courants que les systèmes natifs cloud consomment.
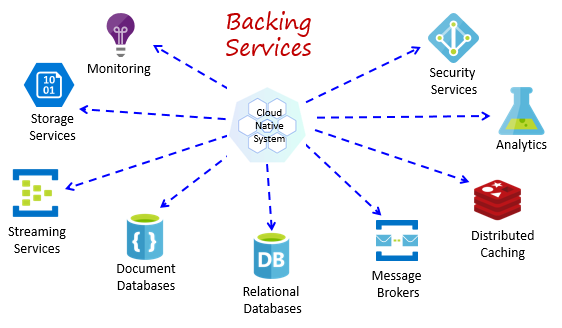
Figure 1-8. Services de stockage courants
Vous pouvez héberger vos propres services de stockage, mais vous êtes alors responsable des licences, de l’approvisionnement et de la gestion de ces ressources.
Les fournisseurs de cloud offrent un large éventail de services de stockage gérés. Au lieu de posséder le service, il vous suffit de l’utiliser. Le fournisseur de cloud exploite la ressource à grande échelle et assume la responsabilité des performances, de la sécurité et de la maintenance. La surveillance, la redondance et la disponibilité sont intégrées au service. Les fournisseurs garantissent les performances au niveau du service et prennent entièrement en charge leurs services managés : ouvrez un ticket et corrigez votre problème.
Les systèmes natifs cloud favorisent les services de stockage managés des fournisseurs de cloud. Les économies de temps et de travail peuvent être significatives. Le risque opérationnel lié à l'hébergement de vos propres services et à la survenue de problèmes peut rapidement devenir coûteux.
Une bonne pratique consiste à traiter un service de stockage en tant que ressource jointe, lié dynamiquement à un microservice avec des informations de configuration (URL et informations d’identification) stockées dans une configuration externe. Cette aide est expliquée dans l’applicationTwelve-Factor, décrite plus haut dans le chapitre.
Factor #4 spécifie que les services de stockage « doivent être exposés via une URL adressable. Cela dissocie la ressource de l’application, ce qui lui permet d’être interchangeable.
Factor #3 spécifie que « Les informations de configuration sont déplacées hors du microservice et externalisées par le biais d’un outil de gestion de la configuration en dehors du code ».
Avec ce modèle, un service de stockage peut être attaché et détaché sans modification du code. Vous pouvez promouvoir un microservice de l’AQ vers un environnement intermédiaire. Vous mettez à jour la configuration du microservice pour pointer vers les services de stockage en préproduction et injecter les paramètres dans votre conteneur via une variable d’environnement.
Les fournisseurs de cloud fournissent des API qui vous permettent de communiquer avec leurs services de stockage propriétaires. Ces bibliothèques encapsulent le raccordement et la complexité propriétaires. Toutefois, la communication directe avec ces API couplera étroitement votre code à ce service de stockage spécifique. Il s’agit d’une pratique largement acceptée pour isoler les détails de l’implémentation de l’API fournisseur. Introduisez une couche d’intermédiation ou une API intermédiaire, exposant des opérations génériques à votre code de service et encapsulez le code du fournisseur à l’intérieur de celui-ci. Ce couplage libre vous permet d’échanger un service de stockage pour un autre ou de déplacer votre code vers un autre environnement cloud sans avoir à apporter de modifications au code du service de ligne principale. Dapr, abordé précédemment, suit ce modèle avec son ensemble de blocs de construction prédéfinis.
Lors d’une dernière réflexion, les services de stockage favorisent également le principe Sans état de l’application à douze facteurs, décrit plus haut dans le chapitre.
Factor #6 spécifie que « Chaque microservice doit s’exécuter dans son propre processus, isolé des autres services en cours d’exécution. Externalisez l’état requis à un service de stockage tel qu’un cache distribué ou un magasin de données. »
Les services de stockage sont abordés dans les modèles de données natifs cloud et les modèles de communication natifs cloud.
Automatisation
Comme vous l’avez vu, les systèmes natifs cloud embrassent les microservices, les conteneurs et la conception moderne du système pour atteindre la vitesse et l’agilité. Mais ce n’est qu’une partie de l’histoire. Comment provisionner les environnements cloud sur lesquels ces systèmes s’exécutent ? Comment déployez-vous rapidement des fonctionnalités et des mises à jour d’application ? Comment arrondissez-vous l’image complète ?
Introduction à la pratique largement acceptée de l’infrastructure en tant que code, ou IaC.
Avec IaC, vous automatisez l’approvisionnement de plateforme et le déploiement d’applications. Vous appliquez essentiellement des pratiques d’ingénierie logicielle telles que le test et le contrôle de version à vos pratiques DevOps. Votre infrastructure et vos déploiements sont automatisés, cohérents et reproductibles.
Automatisation de l’infrastructure
Les outils tels qu’Azure Resource Manager, Azure Bicep, Terraform à partir de HashiCorp et Azure CLI vous permettent de scripter de manière déclarative l’infrastructure cloud dont vous avez besoin. Les noms de ressources, les emplacements, les capacités et les secrets sont paramétrés et dynamiques. Le version du script est gérée et ce dernier est archivé dans le contrôle de code source en tant qu’artefact de votre projet. Vous appelez le script pour approvisionner une infrastructure cohérente et reproductible dans les environnements système, tels que l’assurance qualité, la préproduction et la production.
Plus en détail, l’IaC est idempotent, ce qui signifie que vous pouvez exécuter le même script encore et encore, sans effets secondaires. Si l’équipe doit apporter une modification, elle modifie et réexécute le script. Seules les ressources mises à jour sont affectées.
Dans l’article What is Infrastructure as Code, l'auteur Sam Guckenheimer décrit comment « Les équipes qui implémentent IaC peuvent fournir des environnements stables rapidement et à grande échelle. Ils évitent la configuration manuelle des environnements et appliquent la cohérence en représentant l’état souhaité de leurs environnements via du code. Les déploiements d’infrastructure avec IaC sont reproductibles et empêchent les problèmes d’exécution causés par la dérive de configuration ou les dépendances manquantes. Les équipes DevOps peuvent collaborer avec un ensemble unifié de pratiques et d’outils pour fournir des applications et leur infrastructure de prise en charge rapidement, fiable et à grande échelle.
Automatisation des déploiements
L’applicationTwelve-Factor, décrite précédemment, appelle des étapes distinctes lors de la transformation du code terminé en une application en cours d’exécution.
Factor #5 spécifie que « Chaque version doit appliquer une séparation stricte entre les phases de génération, de mise en production et d’exécution. Chacune doit être marquée avec un ID unique et prendre en charge la possibilité de restaurer ».
Les systèmes CI/CD modernes aident à respecter ce principe. Ils fournissent des étapes de génération et de livraison distinctes qui permettent de garantir un code cohérent et de qualité facilement disponible pour les utilisateurs.
La figure 1-9 montre la séparation à travers le processus de déploiement.
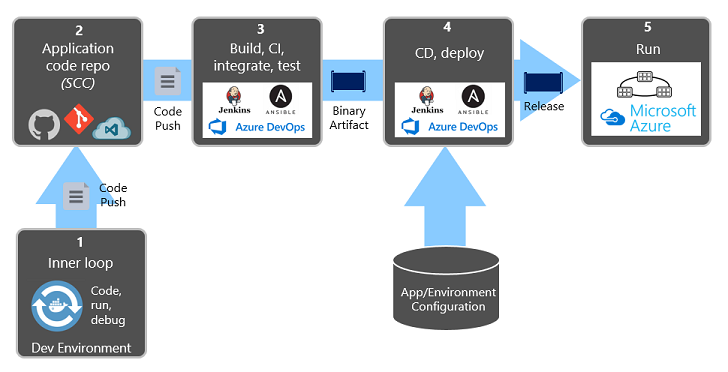
Figure 1-9. Étapes de déploiement dans un pipeline CI/CD
Dans la figure précédente, portez une attention particulière à la séparation des tâches :
- Le développeur construit une fonctionnalité dans son environnement de développement, itérant à travers ce qu’on appelle la « boucle interne » du code, de l’exécution et du débogage.
- Une fois terminé, ce code est envoyé dans un référentiel de code, tel que GitHub, Azure DevOps ou BitBucket.
- Le push déclenche une phase de génération qui transforme le code en artefact binaire. Le travail est implémenté avec un pipeline d’intégration continue (CI). Il génère, teste et empaquette automatiquement l’application.
- La phase de mise en production récupère l’artefact binaire, applique les informations de configuration de l’application externe et de l’environnement et produit une version immuable. La version est déployée dans un environnement spécifié. Le travail est effectué à l'aide d'un pipeline de livraison continue (CD). Chaque version doit être identifiable. Vous pouvez dire : « Ce déploiement exécute la version 2.1.1 de l’application . »
- Enfin, la fonctionnalité publiée est exécutée dans l’environnement d’exécution cible. Les versions sont immuables, ce qui signifie que toute modification doit créer une nouvelle version.
En appliquant ces pratiques, les organisations ont radicalement évolué dans leur façon d'expédier des logiciels. Beaucoup sont passés des versions trimestrielles aux mises à jour à la demande. L’objectif est de détecter les problèmes au début du cycle de développement lorsqu’ils sont moins coûteux à résoudre. Plus la durée entre les intégrations est longue, les problèmes les plus coûteux deviennent à résoudre. Avec une cohérence dans le processus d’intégration, les équipes peuvent valider les modifications de code plus fréquemment, ce qui entraîne une meilleure collaboration et une meilleure qualité logicielle.
L’infrastructure en tant qu’automatisation du code et du déploiement, ainsi que GitHub et Azure DevOps, sont abordées en détail dans DevOps.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.