Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Conseil / Astuce
Ce contenu est un extrait du livre électronique 'Architecture des microservices .NET pour les applications .NET conteneurisées', disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement, lisible hors ligne.

Cette section se concentre sur le développement d’une application d’entreprise côté serveur hypothétique.
Spécifications d’application
L’application hypothétique gère les requêtes en exécutant la logique métier, en accédant aux bases de données, puis en retournant des réponses HTML, JSON ou XML. Nous allons dire que l’application doit prendre en charge différents clients, y compris les navigateurs de bureau exécutant des applications monopage (SPA), les applications web traditionnelles, les applications web mobiles et les applications mobiles natives. L'application peut également exposer une API pour que les tiers puissent l'utiliser. Il doit également être en mesure d’intégrer ses microservices ou applications externes de manière asynchrone, afin que cette approche contribue à la résilience des microservices en cas de défaillances partielles.
L’application se compose de ces types de composants :
Composants de présentation. Ces composants sont responsables de la gestion de l’interface utilisateur et de l’utilisation des services distants.
Logique de domaine ou métier. Ce composant est la logique de domaine de l’application.
Logique d’accès à la base de données. Ce composant se compose de composants d’accès aux données responsables de l’accès aux bases de données (SQL ou NoSQL).
Logique d’intégration d’application. Ce composant inclut un canal de messagerie, basé sur les répartiteurs de messages.
L’application nécessite une scalabilité élevée, tout en autorisant ses sous-systèmes verticaux à effectuer un scale-out de manière autonome, car certains sous-systèmes nécessitent plus d’extensibilité que d’autres.
L’application doit être déployée dans plusieurs environnements d’infrastructure (plusieurs clouds publics et locaux) et idéalement être multiplateforme, capable de passer de Linux à Windows (ou vice versa) facilement.
Contexte de l’équipe de développement
Nous partons également du principe suivant sur le processus de développement de l’application :
Vous avez plusieurs équipes de développement qui se concentrent sur différents domaines d’activité de l’application.
Les nouveaux membres de l’équipe doivent devenir productifs rapidement et l’application doit être facile à comprendre et à modifier.
L’application aura une évolution à long terme et des règles métier en constante évolution.
Vous avez besoin d’une bonne facilité de maintenance à long terme, ce qui signifie une agilité lors de l’implémentation de nouvelles modifications à l’avenir tout en étant en mesure de mettre à jour plusieurs sous-systèmes avec un impact minimal sur les autres sous-systèmes.
Vous souhaitez pratiquer l’intégration continue et le déploiement continu de l’application.
Vous souhaitez tirer parti des technologies émergentes (frameworks, langages de programmation, etc.) tout en changeant l’application. Vous ne souhaitez pas effectuer de migrations complètes de l’application lorsque vous passez à de nouvelles technologies, car cela entraînerait des coûts élevés et affecterait la prévisibilité et la stabilité de l’application.
Choix d’une architecture
Qu’est-ce que l’architecture de déploiement d’application doit-elle être ? Les spécifications de l’application, ainsi que le contexte de développement, suggèrent fortement d’concevoir l’application en la décomposant en sous-systèmes autonomes sous la forme de microservices et de conteneurs de collaboration, où un microservice est un conteneur.
Dans cette approche, chaque service (conteneur) implémente un ensemble de fonctions cohérentes et étroitement associées. Par exemple, une application peut se composer de services tels que le service catalogue, le service de commande, le service panier, le service de profil utilisateur, etc.
Les microservices communiquent à l’aide de protocoles tels que HTTP (REST), mais également de manière asynchrone (par exemple, à l’aide d’AMQP) dans la mesure du possible, en particulier lors de la propagation des mises à jour avec des événements d’intégration.
Les microservices sont développés et déployés en tant que conteneurs indépendamment les uns des autres. Cette approche signifie qu’une équipe de développement peut développer et déployer un certain microservice sans avoir d’impact sur d’autres sous-systèmes.
Chaque microservice a sa propre base de données, ce qui lui permet d’être entièrement découplé d’autres microservices. Si nécessaire, la cohérence entre les bases de données provenant de différents microservices est obtenue à l’aide d’événements d’intégration au niveau de l’application (par le biais d’un bus d’événements logique), comme géré dans la séparation des responsabilités de commande et de requête (CQRS). C'est pourquoi, les contraintes commerciales doivent intégrer le principe de cohérence éventuelle entre les multiples microservices et les bases de données associées.
eShopOnContainers : application de référence pour .NET et microservices déployés à l’aide de conteneurs
Pour que vous puissiez vous concentrer sur l’architecture et les technologies au lieu de réfléchir à un domaine d’entreprise hypothétique que vous ne savez peut-être pas, nous avons sélectionné un domaine d’entreprise bien connu, à savoir une application de commerce électronique simplifiée (e-shop) qui présente un catalogue de produits, prend des commandes des clients, vérifie l’inventaire et effectue d’autres fonctions métier. Ce code source d’application basé sur un conteneur est disponible dans le dépôt GitHub eShopOnContainers .
L’application se compose de plusieurs sous-systèmes, y compris plusieurs serveurs frontaux de magasin (une application web et une application mobile native), ainsi que les microservices et conteneurs principaux pour toutes les opérations côté serveur requises avec plusieurs passerelles API comme points d’entrée consolidés vers les microservices internes. La figure 6-1 montre l’architecture de l’application de référence.
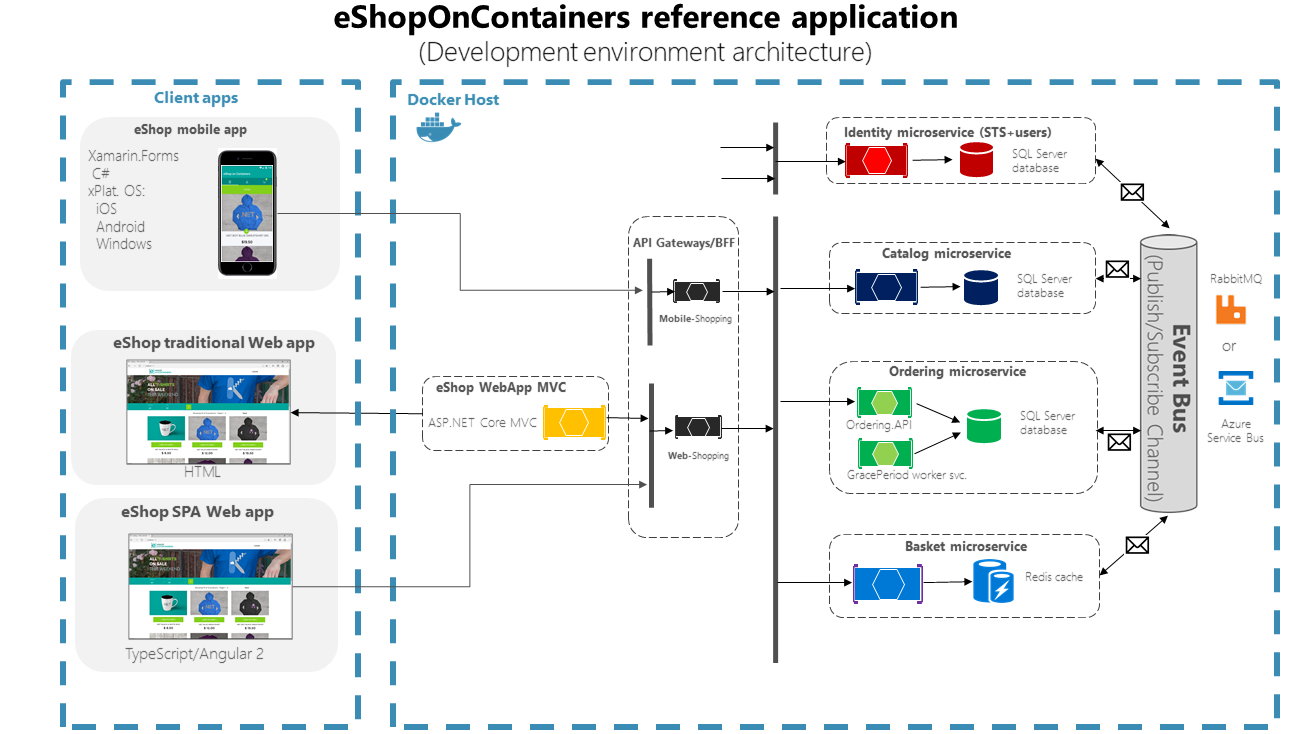
Figure 6-1. L’architecture d’application de référence eShopOnContainers pour l’environnement de développement
Le diagramme ci-dessus montre que les clients Mobile et SPA communiquent avec des points de terminaison de passerelle API uniques, qui communiquent ensuite aux microservices. Les clients web traditionnels communiquent avec le microservice MVC, qui communique avec les microservices via la passerelle d’API.
Environnement d’hébergement. Dans la figure 6-1, plusieurs conteneurs sont déployés dans un seul hôte Docker. Cela serait le cas lors du déploiement sur un seul hôte Docker avec la commande docker-compose up. Toutefois, si vous utilisez un orchestrateur ou un cluster de conteneurs, chaque conteneur peut s’exécuter dans un autre hôte (nœud) et n’importe quel nœud peut exécuter n’importe quel nombre de conteneurs, comme nous l’avons expliqué précédemment dans la section d’architecture.
Architecture de communication. L’application eShopOnContainers utilise deux types de communication, en fonction du type de l’action fonctionnelle (requêtes par rapport aux mises à jour et transactions) :
Communication de client à microservice Http via des passerelles d’API. Cette approche est utilisée pour les requêtes et lors de l’acceptation des commandes de mise à jour ou transactionnelles à partir des applications clientes. L’approche à l’aide de passerelles d’API est expliquée en détail dans les sections ultérieures.
Communication asynchrone basée sur des événements. Cette communication se produit via un bus d’événements pour propager les mises à jour entre les microservices ou pour s’intégrer à des applications externes. Le bus d’événements peut être implémenté avec n’importe quelle technologie d’infrastructure de répartiteur de messagerie comme RabbitMQ ou à l’aide de bus de service de niveau supérieur (abstraction-level) comme Azure Service Bus, NServiceBus, MassTransit ou Brighter.
L’application est déployée en tant qu’ensemble de microservices sous la forme de conteneurs. Les applications clientes peuvent communiquer avec ces microservices s’exécutant en tant que conteneurs via les URL publiques publiées par les passerelles d’API.
Souveraineté des données par microservice
Dans l’exemple d’application, chaque microservice possède sa propre base de données ou source de données, bien que toutes les bases de données SQL Server soient déployées en tant que conteneur unique. Cette décision de conception a été prise uniquement pour faciliter l’obtention du code à partir de GitHub, le cloner et l’ouvrir dans Visual Studio ou Visual Studio Code. Vous pouvez également compiler facilement les images Docker personnalisées à l’aide de l’interface CLI .NET et de l’interface CLI Docker, puis de les déployer et de les exécuter dans un environnement de développement Docker. De toute façon, l’utilisation de conteneurs pour les sources de données permet aux développeurs de créer et de déployer en quelques minutes sans avoir à provisionner une base de données externe ou toute autre source de données avec des dépendances matérielles sur l’infrastructure (cloud ou local).
Dans un environnement de production réel, pour la haute disponibilité et pour l’extensibilité, les bases de données doivent être basées sur des serveurs de base de données dans le cloud ou en local, mais pas dans des conteneurs.
Par conséquent, les unités de déploiement pour les microservices (et même pour les bases de données de cette application) sont des conteneurs Docker, et l’application de référence est une application multiconteneur qui adopte des principes de microservices.
Ressources supplémentaires
- Code source de l’application de référence eShopOnContainers Code source de l’application de référence
https://aka.ms/eShopOnContainers/
Avantages d’une solution basée sur un microservice
Une solution basée sur des microservices comme celle-ci présente de nombreux avantages :
Chaque microservice est relativement petit , facile à gérer et à évoluer. Spécifiquement:
Il est facile pour un développeur de comprendre et de commencer rapidement avec une bonne productivité.
Les conteneurs démarrent rapidement, ce qui rend les développeurs plus productifs.
Un IDE tel que Visual Studio peut charger rapidement des projets plus petits, ce qui rend les développeurs productifs.
Chaque microservice peut être conçu, développé et déployé indépendamment d’autres microservices, ce qui offre une agilité, car il est plus facile de déployer de nouvelles versions de microservices fréquemment.
Il est possible d’effectuer un scale-out des zones individuelles de l’application. par exemple, le service catalogue ou le service panier d’achat peuvent nécessiter une montée en charge, mais pas le processus de commande. Une infrastructure de microservices sera beaucoup plus efficace en ce qui concerne les ressources utilisées lors du scale-out qu’une architecture monolithique.
Vous pouvez diviser le travail de développement entre plusieurs équipes. Chaque service peut être détenu par une seule équipe de développement. Chaque équipe peut gérer, développer, déployer et mettre à l’échelle son service indépendamment du reste des équipes.
Les problèmes sont plus isolés. S’il existe un problème dans un service, seul ce service est initialement affecté (sauf lorsque la conception incorrecte est utilisée, avec des dépendances directes entre les microservices) et d’autres services peuvent continuer à gérer les requêtes. En revanche, un composant défectueux dans une architecture de déploiement monolithique peut réduire l’ensemble du système, en particulier lorsqu’il implique des ressources, telles qu’une fuite de mémoire. En outre, lorsqu’un problème dans un microservice est résolu, vous pouvez déployer uniquement le microservice concerné sans avoir d’impact sur le reste de l’application.
Vous pouvez utiliser les dernières technologies. Étant donné que vous pouvez commencer à développer des services indépendamment et les exécuter côte à côte (grâce aux conteneurs et .NET), vous pouvez commencer à utiliser les dernières technologies et infrastructures au lieu d’être bloqués sur une pile ou une infrastructure plus ancienne pour l’ensemble de l’application.
Inconvénients d’une solution basée sur des microservices
Une solution basée sur des microservices comme celle-ci présente également certains inconvénients :
Application distribuée. La distribution de l’application ajoute de la complexité pour les développeurs lorsqu’ils conçoivent et créent les services. Par exemple, les développeurs doivent implémenter une communication interservices à l’aide de protocoles tels que HTTP ou AMQP, ce qui complique le test et la gestion des exceptions. Il ajoute également la latence au système.
Complexité du déploiement. Une application qui a des dizaines de types de microservices et a besoin d’une scalabilité élevée (elle doit pouvoir créer de nombreuses instances par service et équilibrer ces services entre de nombreux hôtes) signifie un degré élevé de complexité de déploiement pour les opérations et la gestion informatiques. Si vous n’utilisez pas d’infrastructure orientée microservice (comme un orchestrateur et un planificateur), cette complexité supplémentaire peut nécessiter beaucoup plus d’efforts de développement que l’application métier elle-même.
Transactions atomiques. Les transactions atomiques entre plusieurs microservices ne sont généralement pas possibles. Les exigences commerciales doivent intégrer la cohérence à terme entre plusieurs microservices. Pour plus d’informations, consultez les défis liés au traitement des messages idempotents.
Augmentation des besoins en ressources globales (mémoire totale, lecteurs et ressources réseau pour tous les serveurs ou hôtes). Dans de nombreux cas, lorsque vous remplacez une application monolithique par une approche de microservices, la quantité de ressources globales initiales nécessaires par la nouvelle application basée sur un microservice sera supérieure aux besoins d’infrastructure de l’application monolithique d’origine. Cette approche est due au fait que le degré de granularité et les services distribués plus élevés nécessitent des ressources plus globales. Toutefois, étant donné le faible coût des ressources en général et l’avantage d’être en mesure d’effectuer un scale-out de certaines zones de l’application par rapport aux coûts à long terme lors de l’évolution des applications monolithiques, l’utilisation accrue des ressources est généralement un bon compromis pour les applications volumineuses et à long terme.
Problèmes liés à la communication directe entre le client et le microservice. Lorsque l’application est volumineuse, avec des dizaines de microservices, il existe des défis et des limitations si l’application nécessite des communications directes client-à-microservice. Un problème est une incompatibilité potentielle entre les besoins du client et les API exposées par chacun des microservices. Dans certains cas, l’application cliente peut avoir besoin d’effectuer de nombreuses requêtes distinctes pour composer l’interface utilisateur, ce qui peut être inefficace sur Internet et serait irréalisable sur un réseau mobile. Par conséquent, les demandes de l’application cliente vers le système back-end doivent être réduites.
Un autre problème lié aux communications directes client-à-microservice est que certains microservices peuvent utiliser des protocoles qui ne sont pas compatibles avec le web. Un service peut utiliser un protocole binaire, tandis qu’un autre service peut utiliser la messagerie AMQP. Ces protocoles-là ne sont pas compatibles avec les pare-feu et sont mieux utilisés dans un réseau interne. En règle générale, une application doit utiliser des protocoles tels que HTTP et WebSockets pour la communication en dehors du pare-feu.
Un autre inconvénient de cette approche directe du client à service est qu’il est difficile de refactoriser les contrats pour ces microservices. Au fil du temps, les développeurs peuvent vouloir modifier la façon dont le système est partitionné en services. Par exemple, ils peuvent fusionner deux services ou fractionner un service en deux ou plusieurs services. Toutefois, si les clients communiquent directement avec les services, l’exécution de ce type de refactorisation peut interrompre la compatibilité avec les applications clientes.
Comme mentionné dans la section architecture, lors de la conception et de la création d’une application complexe basée sur des microservices, vous pouvez envisager l’utilisation de plusieurs passerelles d’API affinées au lieu de l’approche de communication directe de client à microservice.
Partitionnement des microservices : Enfin, quelle que soit l’approche que vous prenez pour votre architecture de microservice, un autre défi consiste à décider comment partitionner une application de bout en bout en plusieurs microservices. Comme indiqué dans la section architecture du guide, il existe plusieurs techniques et approches que vous pouvez adopter. En fait, vous devez identifier les zones de l’application qui sont découplées des autres domaines et qui ont un faible nombre de dépendances matérielles. Dans de nombreux cas, cette approche est alignée sur le partitionnement des services par cas d’usage. Par exemple, dans notre application e-shop, nous avons un service de commande qui est responsable de toute la logique métier liée au processus de commande. Nous avons également le service catalogue et le service panier qui implémentent d’autres fonctionnalités. Idéalement, chaque service ne doit avoir qu’un petit ensemble de responsabilités. Cette approche est similaire au principe de responsabilité unique (SRP) appliqué aux classes, qui indique qu’une classe ne doit avoir qu’une seule raison de changer. Mais dans ce cas, il s’agit de microservices, de sorte que l’étendue sera supérieure à une seule classe. La plupart du temps, un microservice doit être autonome, de bout en bout, y compris la responsabilité de ses propres sources de données.
Architecture externe ou interne et modèles de conception
L’architecture externe est l’architecture de microservice composée par plusieurs services, en suivant les principes décrits dans la section architecture de ce guide. Toutefois, selon la nature de chaque microservice, et indépendamment de l’architecture de microservice de haut niveau que vous choisissez, il est courant et parfois conseillé d’avoir différentes architectures internes, chacune basée sur des modèles différents, pour différents microservices. Les microservices peuvent même utiliser différentes technologies et langages de programmation. La figure 6-2 illustre cette diversité.
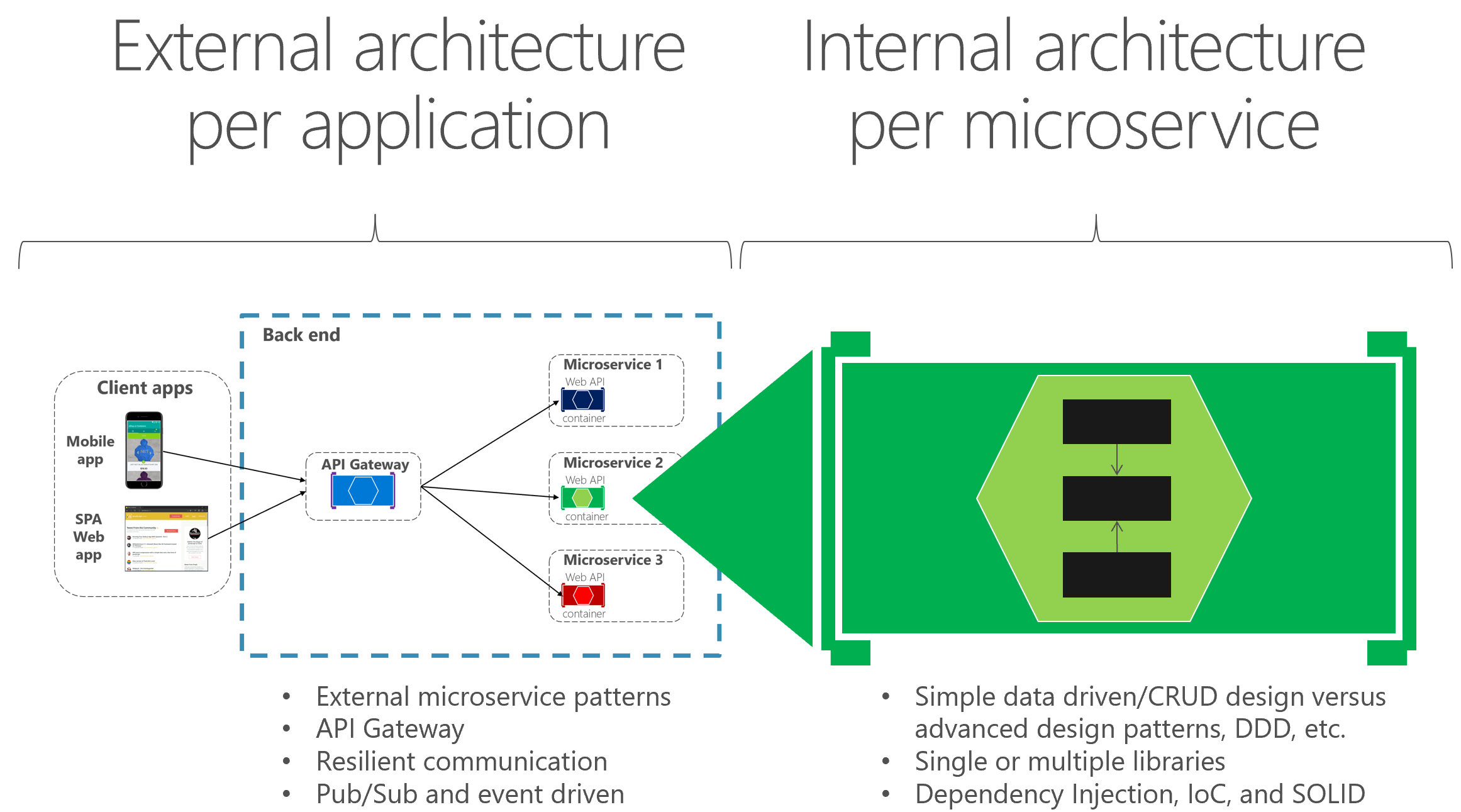
Figure 6-2. Architecture et conception externes versus internes
Par exemple, dans notre exemple eShopOnContainers , le catalogue, le panier et les microservices de profil utilisateur sont simples (essentiellement, sous-systèmes CRUD). Par conséquent, leur architecture et leur conception internes sont simples. Toutefois, vous pouvez avoir d’autres microservices, tels que le microservice de commande, qui est plus complexe et représente des règles métier en constante évolution avec un degré élevé de complexité du domaine. Dans les cas suivants, vous pouvez implémenter des modèles plus avancés au sein d’un microservice particulier, comme ceux définis avec des approches de conception pilotée par le domaine (DDD), comme nous le faisons dans le microservice de commande eShopOnContainers . (Nous allons examiner ces modèles DDD dans la section plus loin qui expliquent l’implémentation du microservice de commande eShopOnContainers .)
Une autre raison pour une technologie différente par microservice peut être la nature de chaque microservice. Par exemple, il peut être préférable d’utiliser un langage de programmation fonctionnel comme F#, ou même un langage comme R si vous ciblez des domaines IA et Machine Learning, au lieu d’un langage de programmation plus orienté objet comme C#.
La ligne de fond est que chaque microservice peut avoir une architecture interne différente basée sur différents modèles de conception. Tous les microservices ne doivent pas être implémentés à l’aide de modèles DDD avancés, car cela serait sur-ingénierie. De même, les microservices complexes avec une logique métier en constante évolution ne doivent pas être implémentés en tant que composants CRUD, ou vous pouvez vous retrouver avec du code de faible qualité.
Le nouveau monde : plusieurs modèles architecturaux et microservices polyglottes
Il existe de nombreux modèles architecturaux utilisés par les architectes logiciels et les développeurs. Voici quelques-uns (mélange de styles d’architecture et de modèles d’architecture) :
CRUD simple, un seul niveau, une seule couche
Conception pilotée par le domaine (DDD) en couches (N-Layered)
Architecture propre (telle qu’utilisée avec eShopOnWeb)
Séparation des responsabilités des commandes et des requêtes (CQRS).
architectureEvent-Driven (EDA).
Vous pouvez également créer des microservices avec de nombreuses technologies et langages, tels que ASP.NET API web Core, NancyFx, ASP.NET Core SignalR (disponible avec .NET Core 2 ou version ultérieure), F#, Node.js, Python, Java, C++, GoLang, etc.
Le point important est qu’aucun modèle d’architecture ou style particulier, ni aucune technologie particulière, ne convient à toutes les situations. La figure 6-3 montre certaines approches et technologies (bien qu’elles ne soient pas dans un ordre particulier) qui pourraient être utilisées dans différents microservices.
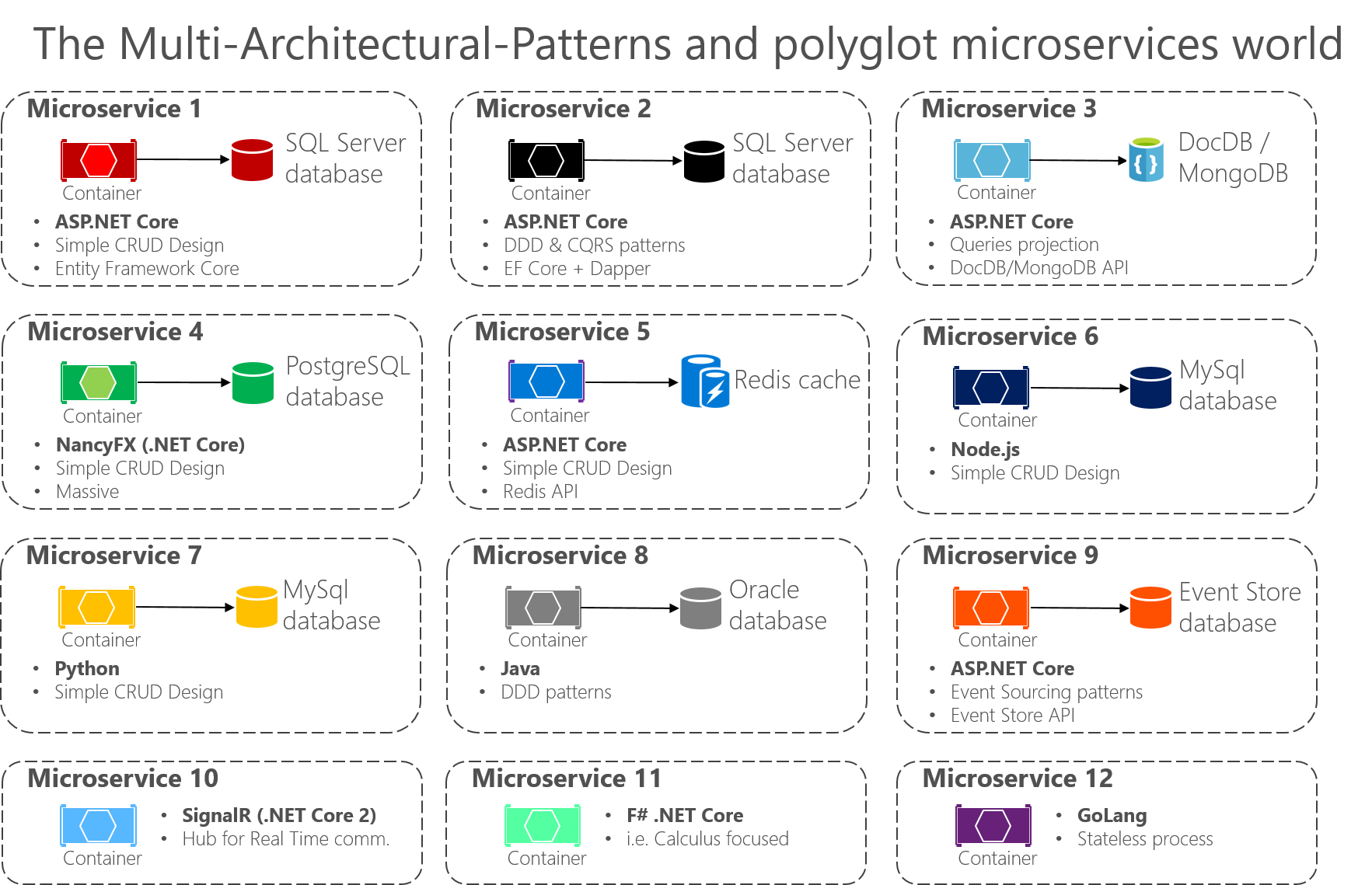
Figure 6-3. Les modèles multi-architecturaux et le monde des microservices polyglottes
Les modèles multi-architecturaux et les microservices polyglottes signifient que vous pouvez combiner et faire correspondre les langages et les technologies aux besoins de chaque microservice et les avoir toujours en train de communiquer entre eux. Comme le montre la figure 6-3, dans les applications composées de nombreux microservices (contextes délimités dans la terminologie de conception pilotée par le domaine, ou simplement « sous-systèmes » en tant que microservices autonomes), vous pouvez implémenter chaque microservice de manière différente. Chacun peut avoir un modèle d’architecture différent et utiliser différents langages et bases de données en fonction de la nature, des exigences métier et des priorités de l’application. Dans certains cas, les microservices peuvent être similaires. Mais ce n’est généralement pas le cas, car la limite de contexte et les exigences de chaque sous-système sont généralement différentes.
Par exemple, pour une application de maintenance CRUD simple, il peut ne pas être judicieux de concevoir et d’implémenter des modèles DDD. Toutefois, pour votre domaine principal ou votre activité principale, vous devrez peut-être appliquer des modèles plus avancés pour aborder la complexité de l’entreprise avec des règles métier en constante évolution.
En particulier lorsque vous traitez de grandes applications composées par plusieurs sous-systèmes, vous ne devez pas appliquer une architecture de niveau supérieur unique basée sur un modèle d’architecture unique. Par exemple, CQRS ne doit pas être appliqué en tant qu’architecture de niveau supérieur pour une application entière, mais peut être utile pour un ensemble spécifique de services.
Il n'existe pas de solution miracle ou de modèle d’architecture unique pour chaque cas donné. Vous ne pouvez pas avoir « un modèle d’architecture pour les règler tous ». Selon les priorités de chaque microservice, vous devez choisir une approche différente pour chacune d’elles, comme expliqué dans les sections suivantes.
Collaborez avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner des problèmes et des demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.