Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait du livre électronique, architecte d’applications web modernes avec ASP.NET Core et Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

« Si vous pensez qu’une bonne architecture est coûteuse, essayez une mauvaise architecture. » - Brian Foote et Joseph Yoder
La plupart des applications .NET traditionnelles sont déployées en tant qu’unités uniques correspondant à un exécutable ou à une application web unique s’exécutant dans un seul domaine d’application IIS. Cette approche est le modèle de déploiement le plus simple et sert très bien de nombreuses applications publiques internes et plus petites. Toutefois, même compte tenu de cette unité de déploiement unique, la plupart des applications métier non triviales bénéficient d’une séparation logique en plusieurs couches.
Qu’est-ce qu’une application monolithique ?
Une application monolithique est une application entièrement autonome, en termes de comportement. Il peut interagir avec d’autres services ou magasins de données au cours de ses opérations, mais le cœur de son comportement s’exécute dans son propre processus et l’ensemble de l’application est généralement déployé en tant qu’unité unique. Si une telle application doit être mise à l’échelle horizontalement, l’ensemble de l’application est généralement dupliqué sur plusieurs serveurs ou machines virtuelles.
Applications tout-en-un
Le plus petit nombre possible de projets pour une architecture d’application est un. Dans cette architecture, la logique entière de l’application est contenue dans un projet unique, compilée sur un seul assembly et déployée en tant qu’unité unique.
Un nouveau projet ASP.NET Core, créé dans Visual Studio ou à partir de la ligne de commande, commence comme un monolithe simple « tout-en-un ». Il contient tout le comportement de l’application, notamment la présentation, l’entreprise et la logique d’accès aux données. La figure 5-1 montre la structure de fichiers d’une application à projet unique.

Figure 5-1. Une application ASP.NET Core de projet unique.
Dans un scénario de projet unique, la séparation des préoccupations est obtenue par le biais de l’utilisation de dossiers. Le modèle par défaut inclut des dossiers distincts pour les responsabilités de modèle MVC des modèles, des vues et des contrôleurs, ainsi que des dossiers supplémentaires pour les données et services. Dans cette disposition, les détails de présentation doivent être limités autant que possible au dossier Vues, et les détails de l’implémentation de l’accès aux données doivent être limités aux classes conservées dans le dossier Données. La logique métier doit résider dans des services et des classes dans le dossier Models.
Bien que simple, la solution monolithique à projet unique présente quelques inconvénients. À mesure que la taille et la complexité du projet augmentent, le nombre de fichiers et de dossiers continuera également de croître. Les problèmes d’interface utilisateur (modèles, vues, contrôleurs) résident dans plusieurs dossiers, qui ne sont pas regroupés par ordre alphabétique. Ce problème ne s’aggrave que lorsque des constructions supplémentaires au niveau de l’interface utilisateur, telles que Filtres ou ModelBinders, sont ajoutées dans leurs propres dossiers. La logique métier est dispersée entre les dossiers Modèles et Services, et il n’existe aucune indication claire des classes dans lesquelles les dossiers doivent dépendre des autres. Ce manque d’organisation au niveau du projet conduit fréquemment au code spaghetti.
Pour résoudre ces problèmes, les applications évoluent souvent en solutions multi-projets, où chaque projet est considéré comme résidant dans une couche particulière de l’application.
Qu’est-ce que les couches ?
À mesure que les applications augmentent en complexité, une façon de gérer cette complexité consiste à décomposer l’application en fonction de ses responsabilités ou préoccupations. Cette approche suit le principe de séparation des préoccupations et peut aider à maintenir une base de code croissante organisée afin que les développeurs puissent facilement trouver où certaines fonctionnalités sont implémentées. L’architecture en couches offre un certain nombre d’avantages au-delà de l’organisation de code, cependant.
En organisant du code en couches, les fonctionnalités courantes de bas niveau peuvent être réutilisées dans l’application. Cette réutilisation est bénéfique, car cela signifie que moins de code doit être écrit et qu’il peut permettre à l’application de normaliser sur une seule implémentation, en suivant le principe de ne pas répéter (DRY).
Avec une architecture en couches, les applications peuvent appliquer des restrictions sur les couches qui peuvent communiquer avec d’autres couches. Cette architecture permet d’obtenir l’encapsulation. Lorsqu’une couche est modifiée ou remplacée, seules les couches qui fonctionnent avec elles doivent être affectées. En limitant les couches qui dépendent des autres couches, l’impact des modifications peut être atténué afin qu’une seule modification n’ait pas d’impact sur l’ensemble de l’application.
Les couches (et l’encapsulation) facilitent considérablement le remplacement des fonctionnalités au sein de l’application. Par exemple, une application peut utiliser initialement sa propre base de données SQL Server pour la persistance, mais elle peut choisir ultérieurement d’utiliser une stratégie de persistance basée sur le cloud ou une autre derrière une API web. Si l’application a correctement encapsulé son implémentation de persistance dans une couche logique, cette couche spécifique à SQL Server peut être remplacée par une nouvelle implémentation de la même interface publique.
En plus du potentiel de permutation d’implémentations en réponse aux modifications futures des exigences, les couches d’application peuvent également faciliter l’échange d’implémentations à des fins de test. Au lieu d’écrire des tests qui fonctionnent sur la couche de données réelle ou la couche d’interface utilisateur de l’application, ces couches peuvent être remplacées au moment du test par des implémentations factices qui fournissent des réponses connues aux requêtes. Cette approche rend généralement les tests beaucoup plus faciles à écrire et beaucoup plus rapidement à exécuter par rapport à l’exécution de tests sur l’infrastructure réelle de l’application.
La couche logique est une technique courante pour améliorer l’organisation du code dans les applications logicielles d’entreprise, et il existe plusieurs façons d’organiser le code en couches.
Remarque
Les couches représentent la séparation logique au sein de l’application. Si la logique d’application est distribuée physiquement à des serveurs ou processus distincts, ces cibles de déploiement physique distinctes sont appelées niveaux. Il est possible, et très courant, d’avoir une application N-Layer déployée sur un seul niveau.
Applications d’architecture « N-Layer » traditionnelles
L’organisation la plus courante de la logique d’application en couches est illustrée dans la figure 5-2.

Figure 5-2. Couches d’application classiques.
Ces couches sont fréquemment abrégées en tant qu’interface utilisateur, BLL (couche logique métier) et DAL (couche d’accès aux données). À l’aide de cette architecture, les utilisateurs effectuent des requêtes via la couche d’interface utilisateur, qui interagit uniquement avec la BLL. La BLL, à son tour, peut appeler le DAL pour les demandes d’accès aux données. La couche d’interface utilisateur ne doit pas effectuer de demandes directement au DAL, ni interagir directement avec la couche de persistance de données par d’autres moyens. De même, la couche BLL doit uniquement interagir avec persistance en passant par la couche DAL. De cette façon, chaque couche a sa propre responsabilité connue.
L’un des inconvénients de cette approche de superposition traditionnelle est que les dépendances au moment de la compilation s’exécutent du haut au bas. Autrement dit, la couche UI dépend de la BLL, qui dépend de la DAL. Cela signifie que la BLL, qui contient généralement la logique la plus importante dans l’application, dépend des détails d’implémentation de l’accès aux données (et souvent de l’existence d’une base de données). Le test de la logique métier dans une telle architecture est souvent difficile, nécessitant une base de données de test. Le principe d’inversion de dépendance peut être utilisé pour résoudre ce problème, comme vous le verrez dans la section suivante.
La figure 5-3 montre un exemple de solution, cassant l’application en trois projets par responsabilité (ou couche).

Figure 5-3. Application monolithique simple avec trois projets.
Bien que cette application utilise plusieurs projets à des fins organisationnelles, elle est toujours déployée en tant qu’unité unique et ses clients interagissent avec elle en tant qu’application web unique. Cela permet un processus de déploiement très simple. La figure 5-4 montre comment une telle application peut être hébergée à l’aide d’Azure.

Figure 5-4. Déploiement simple d’Azure Web App
À mesure que les besoins de l’application augmentent, des solutions de déploiement plus complexes et robustes peuvent être requises. La figure 5-5 montre un exemple de plan de déploiement plus complexe qui prend en charge des fonctionnalités supplémentaires.
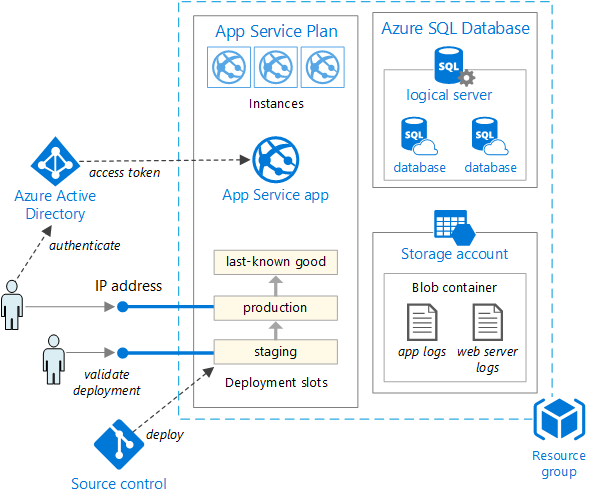
Figure 5-5. Déploiement d’une application web sur azure App Service
En interne, l’organisation de ce projet en plusieurs projets en fonction de la responsabilité améliore la facilité de maintenance de l’application.
Cette unité peut être agrandie ou étendue pour tirer parti de l'évolutivité à la demande basée sur le cloud. Le scale-up signifie l’ajout d’un processeur, d’une mémoire, d’un espace disque ou d’autres ressources au ou aux serveurs hébergeant votre application. Le scale-out signifie l’ajout d’instances supplémentaires de ces serveurs, qu’il s’agisse de serveurs physiques, de machines virtuelles ou de conteneurs. Lorsque votre application est hébergée sur plusieurs instances, un équilibreur de charge est utilisé pour affecter des requêtes à des instances d’application individuelles.
L’approche la plus simple de la mise à l’échelle d’une application web dans Azure consiste à configurer la mise à l’échelle manuellement dans le plan App Service de l’application. La figure 5-6 montre l’écran de tableau de bord Azure approprié pour configurer le nombre d’instances qui servent une application.

Figure 5-6. Mise à l’échelle du plan App Service dans Azure.
Architecture propre
Les applications qui suivent le principe d’inversion des dépendances ainsi que les principes de conception de Domain-Driven (DDD) ont tendance à arriver à une architecture similaire. Cette architecture est passée par de nombreux noms au fil des ans. Au début, on l’a nommée architecture hexagonale, puis architecture ports-adaptateurs. Plus récemment, on l’a cité comme architecture en oignon ou architecture propre. Ce dernier nom, Clean Architecture, est utilisé comme nom pour cette architecture dans ce livre électronique.
L’application de référence eShopOnWeb utilise l’approche Clean Architecture pour organiser son code dans des projets. Vous pouvez trouver un modèle de solution que vous pouvez utiliser comme point de départ pour vos propres solutions ASP.NET Core dans le référentiel GitHub ardalis/cleanarchitecture ou en installant le modèle à partir de NuGet.
L’architecture propre place la logique métier et le modèle d’application au centre de l’application. Au lieu d’avoir une logique métier dépendante de l’accès aux données ou d’autres problèmes d’infrastructure, cette dépendance est inversée : les détails de l’infrastructure et de l’implémentation dépendent de l’Application Core. Cette fonctionnalité est obtenue en définissant des abstractions ou des interfaces, dans Application Core, qui sont ensuite implémentées par des types définis dans la couche Infrastructure. Une façon courante de visualiser cette architecture consiste à utiliser une série de cercles concentriques, semblables à un oignon. La figure 5-7 montre un exemple de ce style de représentation architecturale.

Figure 5-7. Architecture propre ; représentation des couches en oignon
Dans ce diagramme, les dépendances circulent vers le cercle le plus profond. Application Core prend son nom à partir de sa position au cœur de ce diagramme. Et vous pouvez voir sur le diagramme que Application Core n’a aucune dépendance sur d’autres couches d’application. Les entités et interfaces de l’application sont au centre même. Juste en dehors, mais toujours dans Application Core, sont des services de domaine, qui implémentent généralement des interfaces définies dans le cercle interne. En dehors du cœur de l'application, l'interface utilisateur et les couches de l'infrastructure dépendent du cœur de l'application, mais pas nécessairement entre elles.
La figure 5-8 montre un diagramme de couche horizontale plus traditionnel qui reflète mieux la dépendance entre l’interface utilisateur et d’autres couches.

Figure 5-8. Architecture propre ; vue en couches horizontales
Notez que les flèches solides représentent les dépendances au moment de la compilation, tandis que la flèche en pointillés représente une dépendance runtime uniquement. Avec l’architecture propre, la couche d’interface utilisateur fonctionne avec les interfaces définies dans Application Core au moment de la compilation, et idéalement ne doit pas connaître les types d’implémentation définis dans la couche Infrastructure. Toutefois, au moment de l’exécution, ces types d’implémentation sont requis pour que l’application s’exécute. Ils doivent donc être présents et câblés aux interfaces Application Core via l’injection de dépendances.
La figure 5-9 montre une vue plus détaillée de l’architecture d’une application ASP.NET Core lorsqu'elle est construite en suivant ces recommandations.
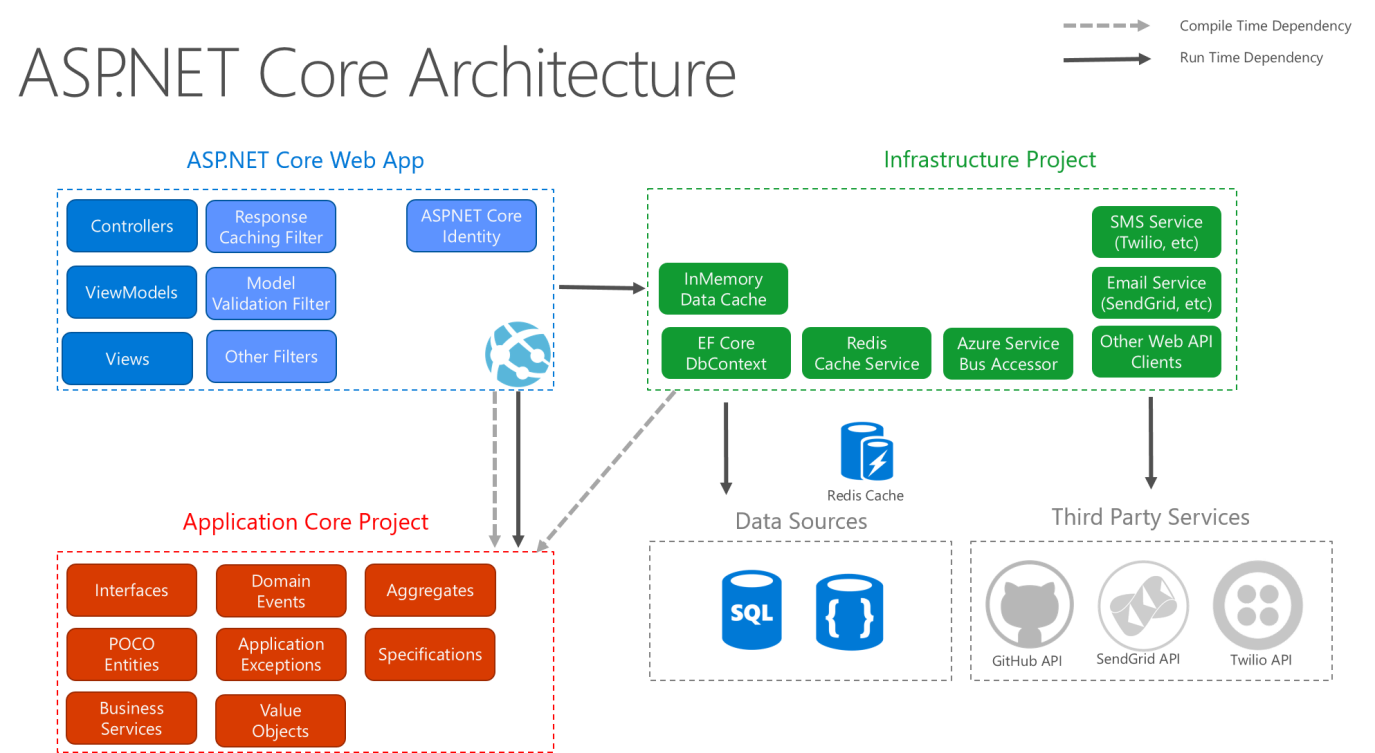
Figure 5-9. Diagramme d'architecture de ASP.NET Core suivant l'architecture Clean.
Étant donné que Application Core ne dépend pas de l’infrastructure, il est très facile d’écrire des tests unitaires automatisés pour cette couche. Les figures 5-10 et 5-11 montrent comment les tests s’intègrent dans cette architecture.

Figure 5-10. Test unitaire de l'Application Core de manière isolée.

Figure 5-11. Tests d’intégration des implémentations d'infrastructure avec des dépendances externes.
Étant donné que la couche d’interface utilisateur n’a aucune dépendance directe sur les types définis dans le projet d’infrastructure, il est également très facile d’échanger des implémentations, soit de faciliter les tests, soit en réponse à la modification des exigences de l’application. L'utilisation intégrée et la prise en charge de l'injection de dépendances par ASP.NET Core font de cette architecture le moyen le plus approprié pour structurer des applications monolithiques complexes.
Pour les applications monolithiques, les projets Application Core, Infrastructure et IU sont tous exécutés en tant qu’application unique. L’architecture de l’application runtime peut ressembler à la figure 5-12.
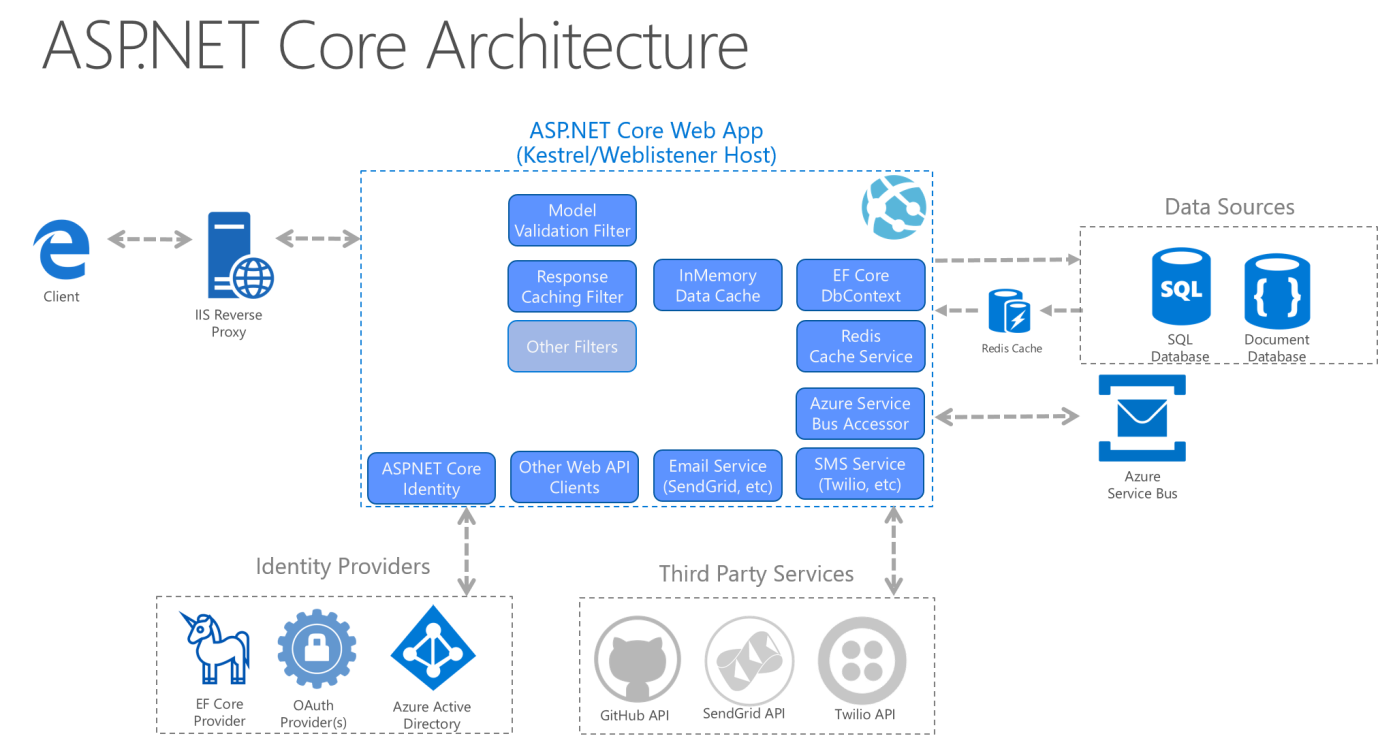
Figure 5-12. Exemple d'architecture d'exécution d'une application ASP.NET Core.
Organisation du code dans l’architecture propre
Dans une solution Clean Architecture, chaque projet a des responsabilités claires. Par conséquent, certains types appartiennent à chaque projet et vous trouverez fréquemment des dossiers correspondant à ces types dans le projet approprié.
Noyau de l'application
Application Core contient le modèle métier, qui inclut des entités, des services et des interfaces. Ces interfaces incluent des abstractions pour les opérations qui seront effectuées à l’aide de l’infrastructure, telles que l’accès aux données, l’accès au système de fichiers, les appels réseau, etc. Parfois, les services ou interfaces définis au niveau de cette couche doivent fonctionner avec des types non-entité qui n’ont aucune dépendance sur l’interface utilisateur ou l’infrastructure. Ces objets peuvent être définis comme des objets de transfert de données simples (DTO).
Types de base de l'application
- Entités (classes de modèle métier persistantes)
- Agrégats (groupes d’entités)
- Interfaces
- Services de domaine
- Spécifications
- Exceptions personnalisées et clauses de garde
- Événements de domaine et leurs gestionnaires
Infrastructure
Le projet d’infrastructure inclut généralement des implémentations d’accès aux données. Dans une application web standard ASP.NET Core, ces implémentations incluent Entity Framework (EF) DbContext, tous les objets EF Core Migration qui ont été définis et les classes d’implémentation d’accès aux données. La façon la plus courante d’extraire le code d’implémentation de l’accès aux données consiste à utiliser le modèle de conception du référentiel.
Outre les implémentations d’accès aux données, le projet d’infrastructure doit contenir des implémentations de services qui doivent interagir avec les problèmes d’infrastructure. Ces services doivent implémenter des interfaces définies dans Application Core, et l’infrastructure doit donc avoir une référence au projet Application Core.
Types d’infrastructure
- Types EF Core (
DbContext,Migration) - Types d’implémentation d’accès aux données (référentiels)
- Services spécifiques à l’infrastructure (par exemple,
FileLoggerouSmtpNotifier)
Couche d’interface utilisateur
La couche d’interface utilisateur d’une application ASP.NET Core MVC est le point d’entrée de l’application. Ce projet doit référencer le projet Application Core et ses types doivent interagir avec l’infrastructure strictement par le biais d’interfaces définies dans Application Core. Aucune instanciation directe ni appel statique aux types de la couche Infrastructure ne doit être autorisé dans la couche d’interface utilisateur.
Types de couches d’interface utilisateur
- Contrôleurs
- Filtres personnalisés
- Intergiciel personnalisé
- Points de vue
- ViewModels
- Jeune entreprise
Le Startup fichier de classe ou de Program.cs est chargé de configurer l’application et de connecter des types d’implémentation aux interfaces. L’endroit où cette logique est effectuée est appelée racine de composition de l’application, et c’est ce qui permet à l’injection de dépendances de fonctionner correctement au moment de l’exécution.
Remarque
Pour configurer l’injection de dépendances au démarrage de l’application, le projet de la couche d'interface utilisateur peut avoir besoin de faire référence au projet Infrastructure. Cette dépendance peut être éliminée plus facilement à l’aide d’un conteneur d’injection de dépendances personnalisé ayant une prise en charge intégrée du chargement des types à partir des assemblys. Dans le cadre de cet exemple, l’approche la plus simple consiste à permettre au projet d’interface utilisateur de référencer le projet d’infrastructure (mais les développeurs doivent limiter les références réelles aux types du projet d’infrastructure à la racine de composition de l’application).
Applications et conteneurs monolithiques
Vous pouvez créer une application ou un service web basé sur un déploiement monolithique et le déployer en tant que conteneur. Dans l’application, il peut ne pas s’agir d’un monolithique, mais organisé en plusieurs bibliothèques, composants ou couches. En externe, il s’agit d’un conteneur unique avec un seul processus, une application web unique ou un seul service.
Pour gérer ce modèle, vous déployez un conteneur unique pour représenter l’application. Pour effectuer une mise à l’échelle, vous ajoutez simplement des copies supplémentaires avec un équilibreur de charge en frontal. La simplicité provient de la gestion d’un déploiement unique dans un seul conteneur ou machine virtuelle.

Vous pouvez inclure plusieurs composants/bibliothèques ou couches internes dans chaque conteneur, comme illustré dans la figure 5-13. Toutefois, en suivant le principe de conteneur « un conteneur fait une chose et le fait dans un processus », le modèle monolithique peut être un conflit.
L’inconvénient de cette approche se produit si/lorsque l’application augmente, ce qui exige qu’elle soit mise à l’échelle. Si toute l'application évolue, ce n'est pas vraiment un problème. Toutefois, dans la plupart des cas, quelques parties de l’application sont les points d’étranglement nécessitant une mise à l’échelle, tandis que d’autres composants sont utilisés moins.
À l’aide de l’exemple de commerce électronique classique, ce que vous devez probablement mettre à l’échelle est le composant d’informations sur le produit. Beaucoup plus de clients parcourent les produits que de les acheter. Plus de clients utilisent leur panier que le pipeline de paiement. Moins de clients ajoutent des commentaires ou affichent leur historique d’achat. Et vous n’avez probablement qu’une poignée d’employés, dans une seule région, qui doivent gérer le contenu et les campagnes marketing. En mettant à l’échelle la conception monolithique, tout le code est déployé plusieurs fois.
En plus du problème de « mise à l’échelle de tout », les modifications apportées à un composant unique nécessitent une retestation complète de l’ensemble de l’application et un redéploiement complet de toutes les instances.
L’approche monolithique est courante et de nombreuses organisations se développent avec cette approche architecturale. Beaucoup ont suffisamment de résultats, tandis que d’autres atteignent des limites. De nombreux développeurs ont conçu leurs applications selon ce modèle, car les outils et l'infrastructure rendaient trop difficile de créer des architectures orientées services (SOA), et ils ne voyaient pas le besoin tant que l'application n'a pas grandi. Si vous constatez que vous atteignez les limites de l'approche monolithique, diviser l'application pour mieux tirer parti des conteneurs et des microservices peut être l'étape logique suivante.

Le déploiement d’applications monolithiques dans Microsoft Azure peut être réalisé à l’aide de machines virtuelles dédiées pour chaque instance. À l’aide d’ensembles de machines virtuelles Azure, vous pouvez facilement mettre à l’échelle les machines virtuelles. Azure App Services peut exécuter des applications monolithiques et mettre facilement à l’échelle des instances sans avoir à gérer les machines virtuelles. Azure App Services peut également exécuter des instances uniques de conteneurs Docker, ce qui simplifie le déploiement. À l’aide de Docker, vous pouvez déployer une seule machine virtuelle en tant qu’hôte Docker et exécuter plusieurs instances. À l’aide de l’équilibreur Azure, comme illustré dans la figure 5-14, vous pouvez gérer la mise à l’échelle.
Le déploiement sur les différents hôtes peut être géré avec des techniques de déploiement traditionnelles. Les hôtes Docker peuvent être gérés avec des commandes telles que docker run exécutées manuellement, ou par le biais d’automatisations telles que des pipelines de livraison continue (CD).
Application monolithique déployée dans un conteneur
Il existe des avantages liés à l’utilisation de conteneurs pour gérer les déploiements d’applications monolithiques. La mise à l’échelle des instances de conteneurs est beaucoup plus rapide et plus facile que le déploiement de machines virtuelles supplémentaires. Même en cas d’utilisation de groupes de machines virtuelles identiques pour la mise à l’échelle des machines virtuelles, leur création prend du temps. Lorsqu’elle est déployée en tant qu’instances d’application, la configuration de l’application est gérée dans le cadre de la machine virtuelle.
Le déploiement des mises à jour en tant qu’images Docker est beaucoup plus rapide et efficace sur le réseau. Les images Docker démarrent généralement en quelques secondes, ce qui accélère les lancements. La destruction d’une instance Docker est aussi simple que l’émission d’une docker stop commande, généralement en moins d’une seconde.
Étant donné que les conteneurs sont intrinsèquement immuables par conception, vous n’avez jamais besoin de vous soucier des machines virtuelles endommagées, tandis que les scripts de mise à jour peuvent oublier de tenir compte de certaines configurations ou fichiers spécifiques laissés sur le disque.
Vous pouvez utiliser des conteneurs Docker pour un déploiement monolithique d’applications web plus simples. Cette approche améliore l’intégration continue et les pipelines de déploiement continu et permet d’obtenir un succès de déploiement en production. Plus de "Ça marche sur ma machine, pourquoi ça ne marche pas en production ?"
Une architecture basée sur des microservices présente de nombreux avantages, mais ces avantages proviennent d’une complexité accrue. Dans certains cas, les coûts l’emportent sur les avantages. Par conséquent, une application de déploiement monolithique s’exécutant dans un seul conteneur ou dans quelques conteneurs est une meilleure option.
Une application monolithique peut ne pas être facilement décomposable en microservices bien séparés. Les microservices doivent fonctionner indépendamment les uns des autres pour fournir une application plus résiliente. Si vous ne pouvez pas fournir de tranches de fonctionnalités indépendantes de l’application, la séparation n’ajoute que de la complexité.
Une application n’a peut-être pas encore besoin de mettre à l’échelle les fonctionnalités indépendamment. De nombreuses applications, lorsqu’elles doivent être mises à l’échelle au-delà d’une seule instance, peuvent le faire via le processus relativement simple de clonage de cette instance entière. Le travail supplémentaire pour séparer l’application en services discrets offre un avantage minimal lorsque la mise à l’échelle des instances complètes de l’application est simple et rentable.
Au début du développement d’une application, vous n’avez peut-être pas une idée claire où sont les limites fonctionnelles naturelles. Au fur et à mesure que vous développez un produit minimum viable, la séparation naturelle n’a peut-être pas encore émergée. Certaines de ces conditions peuvent être temporaires. Vous pouvez commencer par créer une application monolithique, puis séparer ultérieurement certaines fonctionnalités à développer et déployer en tant que microservices. D’autres conditions peuvent être essentielles à l’espace de problème de l’application, ce qui signifie que l’application ne peut jamais être divisée en plusieurs microservices.
La séparation d’une application en plusieurs processus discrets introduit également une surcharge. Il est plus complexe de séparer les fonctionnalités en différents processus. Les protocoles de communication deviennent plus complexes. Au lieu des appels de méthode, vous devez utiliser des communications asynchrones entre les services. Lorsque vous passez à une architecture de microservices, vous devez ajouter un grand nombre des blocs de construction implémentés dans la version de microservices de l’application eShopOnContainers : gestion des bus d’événements, résilience des messages et nouvelles tentatives, cohérence éventuelle, etc.
L’application de référence eShopOnWeb beaucoup plus simple prend en charge l’utilisation du conteneur monolithique à conteneur unique. L’application comprend une application web qui inclut des vues MVC traditionnelles, des API web et des pages Razor. Si vous le souhaitez, vous pouvez exécuter le composant d’administration blazor de l’application, qui nécessite également un projet d’API distinct.
L’application peut être lancée à partir de la racine de la solution à l'aide des commandes docker-compose build et docker-compose up. Cette commande configure un conteneur pour l’instance web, à l’aide de la Dockerfile racine du projet web et exécute le conteneur sur un port spécifié. Vous pouvez télécharger la source de cette application à partir de GitHub et l’exécuter localement. Même cette application monolithique bénéficie d’être déployée dans un environnement de conteneur.
Pour un seul, le déploiement conteneurisé signifie que chaque instance de l’application s’exécute dans le même environnement. Cette approche inclut l’environnement de développement où les tests et le développement précoces ont lieu. L’équipe de développement peut exécuter l’application dans un environnement conteneurisé qui correspond à l’environnement de production.
De plus, les applications conteneurisées peuvent faire l’objet d’un scale-out à moindre coût. L’utilisation d’un environnement de conteneur permet un partage de ressources supérieur à celui des environnements de machine virtuelle traditionnels.
Enfin, le conteneurisation de l’application force une séparation entre la logique métier et le serveur de stockage. À mesure que l’application est mise à l’échelle, les plusieurs conteneurs s’appuient tous sur un seul support de stockage physique. Ce support de stockage est généralement un serveur à haute disponibilité exécutant une base de données SQL Server.
Prise en charge de Docker
Le eShopOnWeb projet s’exécute sur .NET. Par conséquent, il peut s’exécuter dans des conteneurs Basés sur Linux ou Windows. Notez que pour le déploiement Docker, vous souhaitez utiliser le même type d’hôte pour SQL Server. Les conteneurs Linux permettent une empreinte plus petite et sont préférés.
Vous pouvez utiliser Visual Studio 2017 ou version ultérieure pour ajouter la prise en charge de Docker à une application existante en cliquant avec le bouton droit sur un projet dans l’Explorateur de solutions et en choisissant Ajouter> unsupport Docker. Cette étape ajoute les fichiers requis et modifie le projet pour les utiliser. L’exemple actuel eShopOnWeb contient déjà ces fichiers.
Le fichier au niveau docker-compose.yml de la solution contient des informations sur les images à générer et les conteneurs à lancer. Le fichier vous permet d’utiliser la docker-compose commande pour lancer plusieurs applications en même temps. Dans ce cas, il lance uniquement le projet Web. Vous pouvez également l’utiliser pour configurer des dépendances, comme un conteneur de base de données distinct.
version: '3'
services:
eshopwebmvc:
image: eshopwebmvc
build:
context: .
dockerfile: src/Web/Dockerfile
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "5106:5106"
networks:
default:
external:
name: nat
Le fichier docker-compose.yml référence Dockerfile dans le projet Web. Il Dockerfile est utilisé pour spécifier le conteneur de base qui sera utilisé et la façon dont l’application sera configurée sur celle-ci. Voici le Web de Dockerfile :
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.sln .
COPY . .
WORKDIR /app/src/Web
RUN dotnet restore
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS runtime
WORKDIR /app
COPY --from=build /app/src/Web/out ./
ENTRYPOINT ["dotnet", "Web.dll"]
Résolution des problèmes docker
Une fois que vous avez exécuté l’application conteneurisée, elle continue à s’exécuter jusqu’à ce que vous l’arrêtiez. Vous pouvez afficher les conteneurs en cours d’exécution avec la docker ps commande. Vous pouvez arrêter un conteneur en cours d’exécution à l’aide de la docker stop commande et spécifier l’ID de conteneur.
Notez que l’exécution de conteneurs Docker peut être liée à des ports que vous pouvez autrement essayer d’utiliser dans votre environnement de développement. Si vous essayez d’exécuter ou de déboguer une application à l’aide du même port qu’un conteneur Docker en cours d’exécution, vous obtenez une erreur indiquant que le serveur ne peut pas se lier à ce port. Une fois de plus, l’arrêt du conteneur doit résoudre le problème.
Si vous souhaitez ajouter la prise en charge de Docker à votre application à l’aide de Visual Studio, assurez-vous que Docker Desktop est en cours d’exécution lorsque vous le faites. L’Assistant ne s’exécute pas correctement si Docker Desktop n’est pas en cours d’exécution lorsque vous démarrez l’Assistant. En outre, l’assistant examine votre choix de conteneur actuel pour ajouter la prise en charge appropriée de Docker. Si vous souhaitez ajouter le support des conteneurs Windows, vous devez exécuter l’Assistant pendant que Docker Desktop s’exécute avec les conteneurs Windows configurés. Si vous souhaitez ajouter la prise en charge des conteneurs Linux, exécutez l'assistant pendant que Docker fonctionne avec des conteneurs Linux configurés.
Autres styles architecturaux d’application web
- Web-Queue-Worker : les principaux composants de cette architecture sont un serveur frontal web qui traite les demandes clientes et un worker qui effectue des tâches gourmandes en ressources, des workflows de longue durée ou des travaux par lots. Le front-end web communique avec le worker via une file de messages.
- N-tier : une architecture de couche N divise une application en couches logiques et en niveaux physiques.
- Microservice : une architecture de microservices se compose d’une collection de petits services autonomes. Chaque service est autonome et doit implémenter une fonctionnalité unique dans un contexte borné.
Références – Architectures web courantes
-
Architecture propre
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html -
L'architecture Onion
https://jeffreypalermo.com/blog/the-onion-architecture-part-1/ -
Modèle de référentiel
https://deviq.com/repository-pattern/ -
Modèle de solution d’architecture propre
https://github.com/ardalis/cleanarchitecture -
Livre électronique d’architecture de microservices
https://aka.ms/MicroservicesEbook -
DDD ( conceptionDomain-Driven)
https://learn.microsoft.com/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.