Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait du livre électronique, architecte d’applications web modernes avec ASP.NET Core et Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

« Si les bâtisseurs bâtissaient des bâtiments comme les programmeurs écrivent des programmes, le premier pivert passant par là détruirait la civilisation. »
- Gerald Weinberg
Vous devez élaborer et concevoir des solutions logicielles en pensant à la maintenabilité. Les principes décrits dans cette section peuvent vous aider à prendre des décisions architecturales qui entraînent des applications propres et gérables. En règle générale, ces principes vous guideront vers la création d’applications à partir de composants discrets qui ne sont pas étroitement couplés à d’autres parties de votre application, mais plutôt de communiquer par le biais d’interfaces explicites ou de systèmes de messagerie.
Principes de conception courants
Séparation des responsabilités
Un principe de référence lors du développement est la séparation des préoccupations. Ce principe affirme que les logiciels doivent être séparés en fonction des types de travail qu’il effectue. Par exemple, envisagez une application qui inclut une logique permettant d’identifier les éléments remarquables à afficher à l’utilisateur et qui met en forme ces éléments de manière particulière pour les rendre plus visibles. Le comportement responsable de choisir quels éléments mettre en forme devrait être séparé du comportement responsable de la mise en forme des éléments, car ces comportements représentent des préoccupations distinctes qui sont seulement liés de manière accidentelle.
Architecturalement, les applications peuvent être créées logiquement pour suivre ce principe en séparant le comportement métier principal de l’infrastructure et de la logique d’interface utilisateur. Dans l’idéal, les règles et la logique métier doivent résider dans un projet distinct, qui ne doit pas dépendre d’autres projets dans l’application. Cette séparation permet de s’assurer que le modèle métier est facile à tester et peut évoluer sans être étroitement couplé aux détails de l’implémentation de bas niveau (cela permet également de s’assurer que les problèmes d’infrastructure dépendent des abstractions définies dans la couche métier). La séparation des préoccupations est un élément clé de l’utilisation des couches dans les architectures d’application.
Encapsulation
Différentes parties d’une application doivent utiliser l’encapsulation pour les isoler des autres parties de l’application. Les composants et couches d’application doivent être en mesure d’ajuster leur implémentation interne sans interrompre leurs collaborateurs tant que les contrats externes ne sont pas violés. L’utilisation appropriée de l’encapsulation permet d’obtenir un couplage et une modularité lâches dans les conceptions d’applications, car les objets et les packages peuvent être remplacés par d’autres implémentations tant que la même interface est conservée.
Dans les classes, l’encapsulation est obtenue en limitant l’accès externe à l’état interne de la classe. Si un acteur extérieur souhaite manipuler l’état de l’objet, il doit le faire via une fonction bien définie (ou un jeu de propriétés), plutôt que d’avoir un accès direct à l’état privé de l’objet. De même, les composants d’application et les applications eux-mêmes doivent exposer des interfaces bien définies pour que leurs collaborateurs utilisent, plutôt que d’autoriser leur état à être modifié directement. Cette approche libère la conception interne de l’application pour évoluer au fil du temps sans se soucier que cela interrompra les collaborateurs, tant que les contrats publics sont maintenus.
L’état global mutable est antithétique pour l’encapsulation. Une valeur extraite d’un état global mutable dans une fonction ne peut pas être basée sur la même valeur dans une autre fonction (ou encore plus dans la même fonction). Comprendre les préoccupations liées à l’état global mutable est l’une des raisons pour lesquelles les langages de programmation comme C# prennent en charge différentes règles d’étendue, qui sont utilisées partout entre des instructions et des méthodes vers des classes. Il est important de noter que les architectures pilotées par les données qui s’appuient sur une base de données centrale pour l’intégration au sein et entre les applications sont, elles-mêmes, le choix de dépendre de l’état global mutable représenté par la base de données. Une considération clé dans la conception pilotée par le domaine et l’architecture propre consiste à encapsuler l’accès aux données et à garantir que l’état de l’application n’est pas rendu non valide par un accès direct à son format de persistance.
Inversion de dépendance
La direction de la dépendance au sein de l’application doit être dans la direction de l’abstraction, et non dans les détails de l’implémentation. La plupart des applications sont écrites de telle sorte que les dépendances de compilation aillent dans le sens de l’exécution du runtime, ce qui génère un graphique de dépendance directe. Autrement dit, si la classe A appelle une méthode de la classe B et que la classe B appelle une méthode de la classe C, alors lors de la compilation, la classe A dépendra de la classe B, et la classe B dépendra de la classe C, comme illustré dans la figure 4-1.
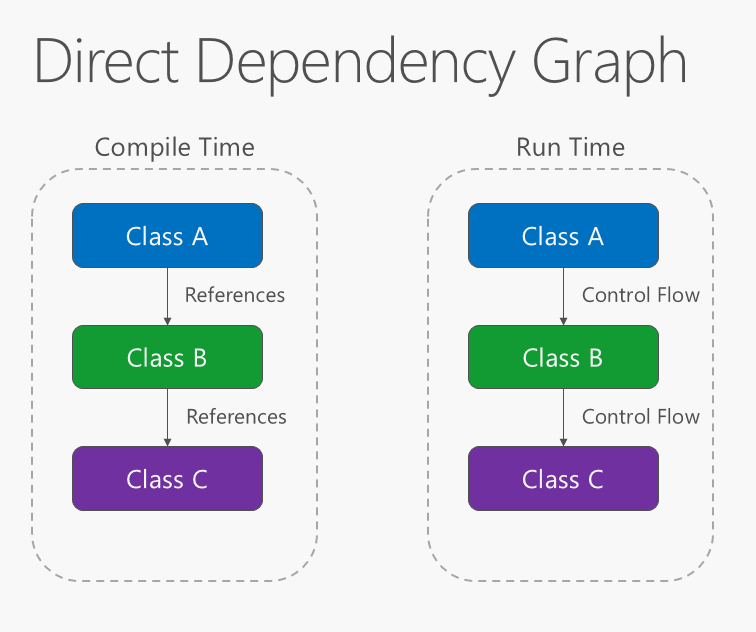
Figure 4-1. Graphique des dépendances directes.
L’application du principe d’inversion de dépendance permet à A d’appeler des méthodes sur une abstraction que B implémente, ce qui permet à A d’appeler B au moment de l’exécution, mais pour B de dépendre d’une interface contrôlée par A au moment de la compilation (par conséquent, invertissant la dépendance au moment de la compilation classique). Au moment de l’exécution, le flux d’exécution du programme reste inchangé, mais l’introduction des interfaces signifie que différentes implémentations de ces interfaces peuvent facilement être branchées.
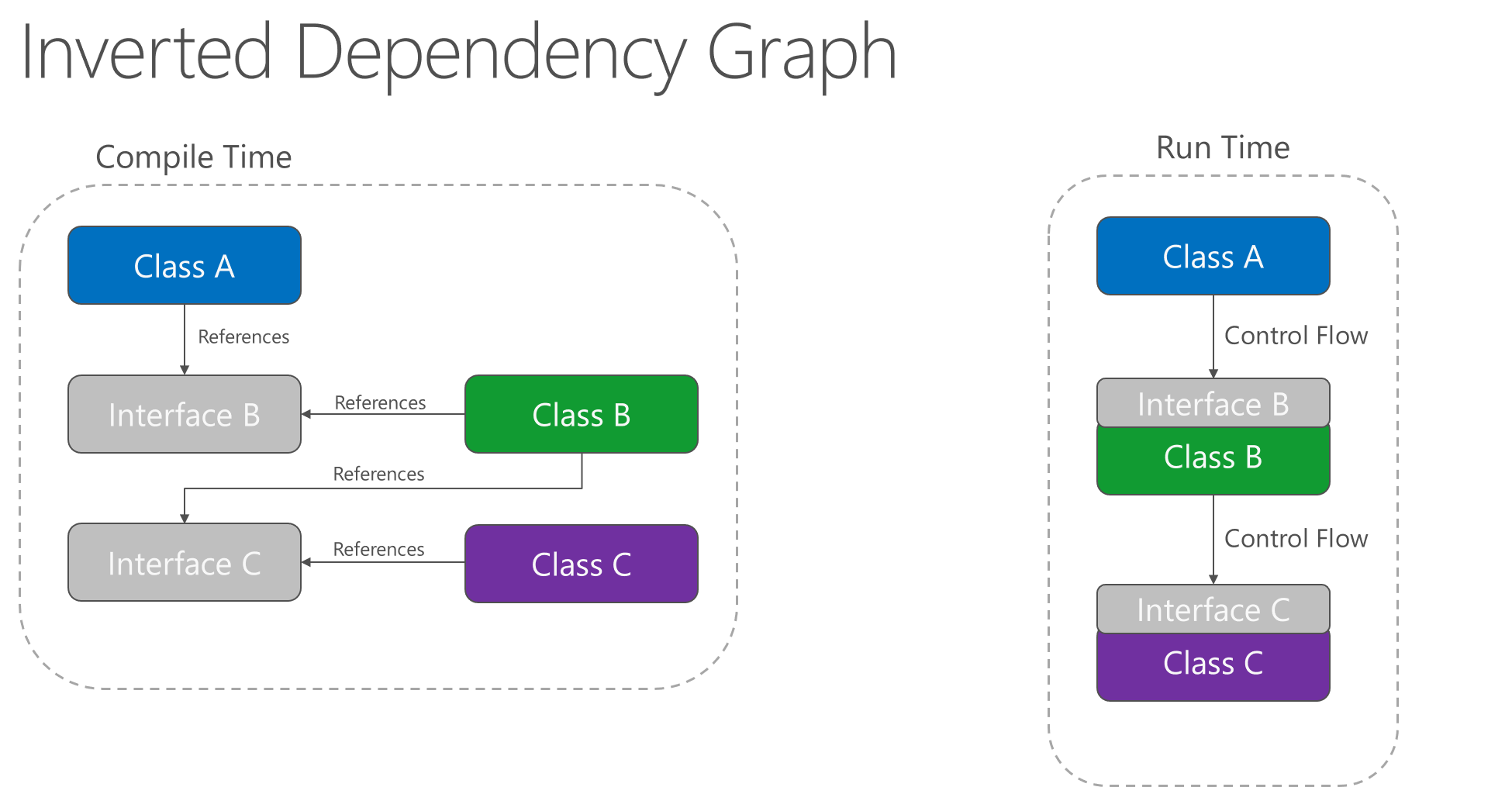
Figure 4-2. Graphique des dépendances inversées.
L’inversion de dépendance est un élément clé de la création d’applications faiblement couplées, car les détails de l’implémentation peuvent être écrits pour dépendre et implémenter des abstractions de niveau supérieur, plutôt que d’une autre façon. Les applications résultantes sont plus testables, modulaires et maintenables en conséquence. La pratique de l’injection de dépendances est rendue possible en suivant le principe d’inversion de dépendance.
Dépendances explicites
Les méthodes et classes doivent exiger explicitement les objets de collaboration dont ils ont besoin pour fonctionner correctement. Il s’appelle le principe des dépendances explicites. Les constructeurs de classes permettent aux classes d’identifier les éléments dont ils ont besoin afin d’être dans un état valide et de fonctionner correctement. Si vous définissez des classes qui peuvent être construites et appelées, mais qui ne fonctionneront correctement que si certains composants globaux ou d'infrastructure sont en place, ces classes sont malhonnêtes envers leurs clients. Le contrat de constructeur indique au client qu’il a uniquement besoin des éléments spécifiés (éventuellement rien si la classe utilise simplement un constructeur sans paramètre), mais au moment de l’exécution, il s’avère que l’objet a vraiment besoin d’autre chose.
En suivant le principe des dépendances explicites, vos classes et méthodes sont honnêtes avec leurs clients sur ce dont ils ont besoin pour fonctionner. En suivant le principe, votre code est plus auto-documenté et vos contrats de codage plus conviviaux, car les utilisateurs devront faire confiance à ce que tant qu’ils fournissent ce qui est requis sous la forme de paramètres de méthode ou de constructeur, les objets qu’ils souhaitent utiliser se comportent correctement au moment de l’exécution.
Responsabilité unique
Le principe de responsabilité unique s’applique à la conception orientée objet, mais peut également être considéré comme un principe architectural similaire à la séparation des préoccupations. Il indique que les objets ne doivent avoir qu’une seule responsabilité et qu’ils ne doivent avoir qu’une seule raison de changer. Plus précisément, la seule situation dans laquelle l’objet doit changer est si la manière dont elle effectue sa responsabilité doit être mise à jour. Le fait de suivre ce principe permet de produire des systèmes plus faiblement couplés et modulaires, car de nombreux types de nouveaux comportements peuvent être implémentés en tant que nouvelles classes, plutôt qu’en ajoutant une responsabilité supplémentaire aux classes existantes. L’ajout de nouvelles classes est toujours plus sûr que la modification des classes existantes, car aucun code ne dépend encore des nouvelles classes.
Dans une application monolithique, nous pouvons appliquer le principe de responsabilité unique à un niveau élevé aux couches de l’application. La responsabilité de présentation doit rester dans le projet d’interface utilisateur, tandis que la responsabilité de l’accès aux données doit être conservée dans un projet d’infrastructure. La logique métier doit être conservée dans le projet principal de l’application, où elle peut être facilement testée et peut évoluer indépendamment des autres responsabilités.
Lorsque ce principe est appliqué à l’architecture d’application et qu’il est dirigé vers son point de terminaison logique, vous obtenez des microservices. Un microservice donné doit avoir une responsabilité unique. Si vous devez étendre le comportement d’un système, il est généralement préférable de le faire en ajoutant des microservices supplémentaires, plutôt qu’en ajoutant la responsabilité à un système existant.
En savoir plus sur l’architecture des microservices
Ne vous répétez pas (DRY)
L’application doit éviter de spécifier le comportement lié à un concept particulier dans plusieurs endroits, car cette pratique est une source fréquente d’erreurs. À un moment donné, une modification des exigences nécessite la modification de ce comportement. Il est probable qu’au moins une instance du comportement ne soit pas mise à jour et que le système se comporte de manière incohérente.
Au lieu de dupliquer la logique, encapsulez-la dans une construction de programmation. Faites de cette construction l’autorité unique sur ce comportement et faites en sorte que toute autre partie de l’application nécessitant ce comportement utilise la nouvelle construction.
Remarque
Évitez d'associer des comportements qui se répètent uniquement par hasard. Par exemple, simplement parce que deux constantes différentes ont la même valeur, cela ne signifie pas que vous ne devez avoir qu’une seule constante, si conceptuellement elles font référence à des choses différentes. La duplication est toujours préférable au couplage à l’abstraction incorrecte.
Ignorance de la persistance
L’ignorance de persistance (PI) fait référence aux types qui doivent être conservés, mais dont le code n’est pas affecté par le choix de la technologie de persistance. Ces types dans .NET sont parfois appelés objets CLR bruts(POC), car ils n’ont pas besoin d’hériter d’une classe de base particulière ou d’implémenter une interface particulière. L’ignorance de la persistance est pratique, car elle permet au même modèle métier d’être stocké de plusieurs façons, ce qui offre davantage de flexibilité à l’application. Les choix de persistance peuvent changer au fil du temps, d’une technologie de base de données à une autre ou d’autres formes de persistance peuvent être nécessaires en plus de ce que l’application a démarré (par exemple, à l’aide d’un cache Redis ou d’Azure Cosmos DB en plus d’une base de données relationnelle).
Voici quelques exemples de violations de ce principe :
Classe de base requise.
Implémentation d’interface requise.
Classes responsables de se sauvegarder elles-mêmes (par exemple, le modèle Active Record).
Constructeur sans paramètre requis.
Propriétés nécessitant un mot clé virtuel.
Attributs obligatoires spécifiques à la persistance.
L’exigence que les classes aient l’une des fonctionnalités ou comportements ci-dessus ajoute le couplage entre les types à conserver et le choix de la technologie de persistance, ce qui rend plus difficile l’adoption de nouvelles stratégies d’accès aux données à l’avenir.
Contextes limités
Les contextes délimités sont un modèle central dans Domain-Driven Conception. Ils permettent de résoudre la complexité des grandes applications ou organisations en les fractionnant en modules conceptuels distincts. Chaque module conceptuel représente ensuite un contexte séparé d’autres contextes (donc limités) et peut évoluer indépendamment. Chaque contexte limité doit idéalement être libre de choisir ses propres noms pour les concepts qu’il contient et doit avoir un accès exclusif à son propre magasin de persistance.
Au minimum, les applications web individuelles devraient être leur propre contexte délimité, avec leur propre stockage persistant pour leur modèle métier, plutôt que de partager une base de données avec d'autres applications. La communication entre les contextes délimités se produit par le biais d’interfaces programmatiques, plutôt que par le biais d’une base de données partagée, ce qui permet à la logique métier et aux événements de se produire en réponse aux modifications qui se produisent. Les contextes délimités correspondent étroitement aux microservices, qui sont également idéalement implémentés en tant que contextes délimités individuels.
Ressources supplémentaires
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.