Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Découvrez comment créer une application de détection d’anomalies pour les données de vente de produits. Ce tutoriel crée une application console .NET à l’aide de C# dans Visual Studio.
Dans ce tutoriel, vous allez apprendre à :
- Chargement des données
- Créer une transformation pour la détection des anomalies de pic
- Détecter les anomalies de pic avec la transformation
- Créer une transformation pour la détection des anomalies de point de modification
- Détecter les anomalies de point de changement avec la transformation
Vous trouverez le code source de ce didacticiel dans le référentiel dotnet/samples .
Prerequisites
Visual Studio 2022 ou version ultérieure avec la charge de travail développement .NET Desktop installée.
Note
Le format de données dans product-sales.csv est basé sur le jeu de données « Shampoo Sales Over a Three Year Period », initialement sourcé de DataMarket et fourni par la Time Series Data Library (TSDL), créé par Rob Hyndman.
Jeu de données « Shampoo Sales Over a Three Year » sous la licence Open License par défaut dataMarket.
Création d’une application console
Créez une application console C# appelée « ProductSalesAnomalyDetection ». Cliquez sur le bouton Suivant .
Choisissez .NET 8 comme framework à utiliser. Cliquez sur le bouton Créer.
Créez un répertoire nommé Data dans votre projet pour enregistrer vos fichiers de jeu de données.
Installez le package NuGet Microsoft.ML :
Note
Cet exemple utilise la dernière version stable des packages NuGet mentionnés, sauf indication contraire.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur votre projet, puis sélectionnez Gérer les packages NuGet. Choisissez « nuget.org » comme source du package, sélectionnez l’onglet Parcourir, recherchez Microsoft.ML et sélectionnez Installer. Sélectionnez le bouton OK dans la boîte de dialogue Aperçu des modifications , puis sélectionnez le bouton J’acceptedans la boîte de dialogue Acceptation de licence si vous acceptez les termes du contrat de licence pour les packages répertoriés. Répétez ces étapes pour Microsoft.ML.TimeSeries.
Ajoutez les directives suivantes
usingen haut de votre fichier Program.cs :using Microsoft.ML; using ProductSalesAnomalyDetection;
Téléchargez vos données
Téléchargez le jeu de données et enregistrez-le dans le dossier Données que vous avez créé précédemment :
Cliquez avec le bouton droit sur product-sales.csv , puis sélectionnez « Enregistrer le lien (ou cible) En tant que ... »
Veillez à enregistrer le fichier *.csv dans le dossier Données , ou après l’avoir enregistré ailleurs, déplacez le fichier *.csv vers le dossier Données .
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le fichier *.csv, puis sélectionnez Propriétés. Sous Avancé, modifiez la valeur de Copie dans le répertoire de sortie pour copier si elle est plus récente.
Le tableau suivant est un aperçu des données de votre fichier *.csv :
| Mois | ProductSales |
|---|---|
| 1-Jan | 271 |
| 2-Jan | 150.9 |
| ..... | ..... |
| 1-Février | 199.3 |
| ..... | ..... |
Créer des classes et définir des chemins d’accès
Ensuite, définissez vos structures de données de classe d’entrée et de prédiction.
Ajoutez une nouvelle classe à votre projet :
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet, puis sélectionnez Ajouter > un nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez le champ Nom par ProductSalesData.cs. Ensuite, sélectionnez Ajouter.
Le fichier ProductSalesData.cs s’ouvre dans l’éditeur de code.
Ajoutez la directive suivante
usingen haut de ProductSalesData.cs :using Microsoft.ML.Data;Supprimez la définition de classe existante et ajoutez le code suivant, qui a deux classes
ProductSalesDataetProductSalesPrediction, au fichier ProductSalesData.cs :public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesDataspécifie une classe de données d’entrée. L’attribut LoadColumn spécifie les colonnes (par index de colonne) dans le jeu de données à charger.ProductSalesPredictionspécifie la classe de données de prédiction. Pour la détection d’anomalies, la prédiction se compose d’une alerte pour indiquer s’il existe une anomalie, un score brut et une valeur p. Plus la valeur p est proche de 0, plus une anomalie s’est produite.Créez deux champs globaux pour contenir le chemin du fichier de jeu de données récemment téléchargé et le chemin d’accès du fichier de modèle enregistré :
-
_dataPatha le chemin d’accès au jeu de données utilisé pour entraîner le modèle. -
_docsizea le nombre d’enregistrements dans le fichier de jeu de données. Vous allez utiliser_docSizepour calculerpvalueHistoryLength.
-
Ajoutez le code suivant à la ligne située en dessous des
usingdirectives pour spécifier ces chemins d’accès :string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
Initialiser les variables
Remplacez la
Console.WriteLine("Hello World!")ligne par le code suivant pour déclarer et initialiser lamlContextvariable :MLContext mlContext = new MLContext();La classe MLContext est un point de départ pour toutes les opérations ML.NET, et l’initialisation
mlContextcrée un environnement ML.NET qui peut être partagé entre les objets de flux de travail de création de modèle. Il est similaire, conceptuellement, àDBContextentity Framework.
Chargement des données
Les données de ML.NET sont représentées sous forme d’interface IDataView.
IDataView est un moyen flexible et efficace de décrire les données tabulaires (numériques et textuelles). Les données peuvent être chargées à partir d’un fichier texte ou d’autres sources (par exemple, une base de données SQL ou des fichiers journaux) dans un IDataView objet.
Ajoutez le code suivant après avoir créé la
mlContextvariable :IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');LoadFromTextFile() définit le schéma de données et lit dans le fichier. Il prend les variables de chemin d’accès aux données et retourne un
IDataView.
Détection des anomalies de série chronologique
La détection d’anomalies signale des événements ou comportements inattendus ou inhabituels. Il donne des indices où rechercher des problèmes et vous aide à répondre à la question « Est-ce bizarre ? ».

La détection des anomalies est le processus de détection des valeurs aberrantes dans les données de série temporelle ; des points dans une série temporelle d'entrée donnée où le comportement n’est pas ce qui était attendu, ou « étrange ».
La détection d’anomalies peut être utile de nombreuses façons. Par exemple:
Si vous avez une voiture, vous voudrez peut-être savoir : Est-ce que cette jauge d’huile est normale, ou est-ce que j’ai une fuite ? Si vous surveillez la consommation d’énergie, vous souhaitez savoir : Y a-t-il une panne ?
Il existe deux types d’anomalies de série chronologique qui peuvent être détectées :
Les pics indiquent des rafales temporaires de comportement anormal dans le système.
Les points de modification indiquent le début des modifications persistantes au fil du temps dans le système.
Dans ML.NET, les algorithmes de détection des pics IID ou de détection de point de modification IID sont adaptés aux jeux de données indépendants et distribués de la même façon. Ils supposent que vos données d’entrée sont une séquence de points de données qui sont échantillonné indépendamment d’une distribution stationnaire.
Contrairement aux modèles des autres didacticiels, les transformations du détecteur d’anomalies de série chronologique fonctionnent directement sur les données d’entrée. La IEstimator.Fit() méthode n’a pas besoin de données d’apprentissage pour produire la transformation. Toutefois, il a besoin du schéma de données, qui est fourni par une vue de données générée à partir d’une liste vide de ProductSalesData.
Vous allez analyser les mêmes données de ventes de produits pour détecter les pics et les points de modification. Le processus de génération et de modèle d’entraînement est le même pour la détection des pics et la détection des points de modification ; la principale différence est l’algorithme de détection spécifique utilisé.
Détection de pics
L’objectif de la détection des pics est d’identifier les rafales soudaines et temporaires qui diffèrent considérablement de la majorité des valeurs de données de série chronologique. Il est important de détecter rapidement ces éléments, événements ou observations rares suspects afin de les minimiser. L’approche suivante peut être utilisée pour détecter diverses anomalies telles que les pannes, les cyber-attaques ou le contenu web viral. L’image suivante est un exemple de pics dans un jeu de données de série chronologique :
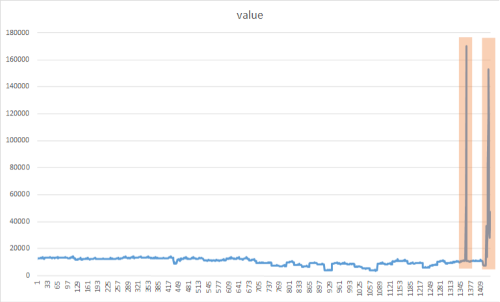
Ajouter la méthode CreateEmptyDataView()
Ajoutez la méthode suivante à Program.cs:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
Le CreateEmptyDataView() produit un objet de vue de données vide avec le schéma approprié à utiliser comme entrée de la IEstimator.Fit() méthode.
Créer la méthode DetectSpike()
La méthode DetectSpike() :
- Crée la transformation à partir de l’estimateur.
- Détecte les pics en fonction des données de ventes historiques.
- Affiche les résultats.
Créez la
DetectSpike()méthode en bas du fichier Program.cs à l’aide du code suivant :DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }Utilisez iidSpikeEstimator afin d'entraîner le modèle pour la détection de pics. Ajoutez-la à la
DetectSpike()méthode avec le code suivant :var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);Créez la transformation de détection de pics en ajoutant les éléments suivants comme ligne de code suivante dans la
DetectSpike()méthode :Conseil / Astuce
Les
confidenceparamètres etpvalueHistoryLengthles paramètres affectent la façon dont les pics sont détectés.confidencedétermine la sensibilité de votre modèle aux pics. Plus la confiance est faible, plus l’algorithme est susceptible de détecter des pics « plus petits ». LepvalueHistoryLengthparamètre définit le nombre de points de données dans une fenêtre glissante. La valeur de ce paramètre est généralement un pourcentage de l’ensemble du jeu de données. Plus le modèle est baspvalueHistoryLength, plus le modèle oublie les pics importants précédents.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));Ajoutez la ligne de code suivante pour transformer les
productSalesdonnées comme ligne suivante dans laDetectSpike()méthode :IDataView transformedData = iidSpikeTransform.Transform(productSales);Le code précédent utilise la méthode Transform() pour effectuer des prédictions pour plusieurs lignes d’entrée d’un jeu de données.
Convertissez-vous
transformedDataen un affichage fortement typéIEnumerablepour faciliter l’affichage à l’aide de la méthode CreateEnumerable() avec le code suivant :var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Créez une ligne d’en-tête d’affichage à l’aide du code suivant Console.WriteLine() :
Console.WriteLine("Alert\tScore\tP-Value");Vous afficherez les informations suivantes dans vos résultats de détection de pics :
-
Alertindique une alerte de pic pour un point de données donné. -
Scoreest laProductSalesvaleur d’un point de données donné dans le jeu de données. -
P-ValueLe « P » signifie probabilité. Plus la valeur p est proche de 0, plus le point de données est probablement une anomalie.
-
Utilisez le code suivant pour itérer à travers les
predictionsIEnumerableet afficher les résultats :foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");Ajoutez l’appel à la
DetectSpike()méthode sous l’appel à laLoadFromTextFile()méthode :DetectSpike(mlContext, _docsize, dataView);
Résultats de la détection de pics
Vos résultats doivent être similaires à ce qui suit. Pendant le traitement, les messages sont affichés. Vous pouvez voir des avertissements ou traiter des messages. Certains des messages ont été supprimés des résultats suivants pour plus de clarté.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
Détection des points de modification
Change points sont des modifications persistantes dans une distribution de flux d’événements de série chronologique des valeurs, telles que les modifications de niveau et les tendances. Ces modifications persistantes durent beaucoup plus longtemps que spikes et peuvent indiquer des événements catastrophiques.
Change points ne sont généralement pas visibles à l’œil nu, mais peuvent être détectés dans vos données à l’aide d’approches telles que dans la méthode suivante. L’image suivante est un exemple de détection de point de modification :
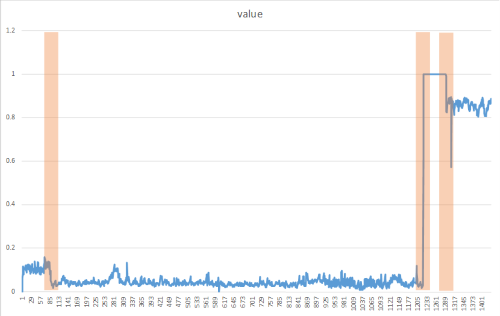
Créer la méthode DetectChangepoint()
La DetectChangepoint() méthode exécute les tâches suivantes :
- Crée la transformation à partir de l’estimateur.
- Détecte les points de modification en fonction des données de ventes historiques.
- Affiche les résultats.
Créez la
DetectChangepoint()méthode, juste après laDetectSpike()déclaration de méthode, à l’aide du code suivant :void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }Créez le iidChangePointEstimator dans la
DetectChangepoint()méthode avec le code suivant :var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);Comme vous l’avez fait précédemment, créez la transformation à partir de l’estimateur en ajoutant la ligne de code suivante dans la
DetectChangePoint()méthode :Conseil / Astuce
La détection des points de modification se produit avec un léger retard, car le modèle doit s’assurer que l’écart actuel est un changement persistant et pas seulement quelques pics aléatoires avant de créer une alerte. La quantité de ce délai est égale au
changeHistoryLengthparamètre. En augmentant la valeur de ce paramètre, les alertes de détection des modifications sur des modifications plus persistantes, mais le compromis serait plus long.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));Utilisez la
Transform()méthode pour transformer les données en ajoutant le code suivant àDetectChangePoint():IDataView transformedData = iidChangePointTransform.Transform(productSales);Comme vous l’avez fait précédemment, convertissez-le
transformedDataen un fortement typéIEnumerablepour faciliter l’affichage à l’aide de laCreateEnumerable()méthode avec le code suivant :var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Créez un en-tête d’affichage avec le code suivant comme ligne suivante dans la
DetectChangePoint()méthode :Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");Vous allez afficher les informations suivantes dans les résultats de la détection des points de modification :
-
Alertindique une alerte de point de modification pour un point de données donné. -
Scoreest laProductSalesvaleur d’un point de données donné dans le jeu de données. -
P-ValueLe « P » signifie probabilité. Plus la valeur P est proche de 0, plus le point de données est probablement une anomalie. -
Martingale valueest utilisé pour identifier la façon dont un point de données est « bizarre », en fonction de la séquence de valeurs P.
-
Itérez à travers
predictionsIEnumerableet affichez les résultats avec le code suivant :foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");Ajoutez l’appel suivant à la
DetectChangepoint()méthode après l’appel à laDetectSpike()méthode :DetectChangepoint(mlContext, _docsize, dataView);
Résultats de la détection des points de modification
Vos résultats doivent être similaires à ce qui suit. Pendant le traitement, les messages sont affichés. Vous pouvez voir des avertissements ou traiter des messages. Certains messages ont été supprimés des résultats suivants pour plus de clarté.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
Félicitations! Vous avez maintenant créé des modèles d'apprentissage automatique pour détecter les pics et les anomalies de points de changement dans les données de vente.
Vous trouverez le code source de ce didacticiel dans le référentiel dotnet/samples .
Dans ce didacticiel, vous avez appris à :
- Chargement des données
- Entraîner le modèle pour la détection des anomalies de pic
- Détecter les anomalies de pic avec le modèle entraîné
- Entraîner le modèle pour la détection des anomalies de point de modification
- Détecter les anomalies de point de changement avec mode entraîné
Étapes suivantes
Consultez le référentiel GitHub d’exemples Machine Learning pour explorer un exemple de détection des anomalies de données saisonnières.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.