Supervision de l’intégrité de connexion de l’application pour la résilience
Afin d’augmenter la résilience d’une infrastructure, configurez la surveillance de l’intégrité de connexion aux applications pour vos applications critiques. Vous pouvez recevoir une alerte lorsqu’un incident impactant se produit. Cet article vous guide tout au long de la configuration du classeur d’intégrité de connexion aux applications pour surveiller les interruptions des connexions de vos utilisateurs.
Vous pouvez configurer des alertes en fonction du classeur d’intégrité de connexion aux applications. Ce classeur permet aux administrateurs de surveiller les demandes d’authentification pour des applications de ses tenants (locataires). Il fournit les fonctionnalités clés suivantes :
- Configurez le classeur pour superviser toutes les applications ou celles contenant des données en quasi-temps réel.
- Configurez des alertes pour détecter des changements de modèle d’authentification afin de pouvoir examiner et répondre.
- Comparez des tendances sur une période donnée. Le paramètre par défaut du classeur a la valeur semaine par semaine.
Notes
Affichez tous les classeurs disponibles et les conditions préalables à leur utilisation dans Utilisation des classeurs Azure Monitor pour les rapports.
Lors d’un événement impactant, deux choses peuvent se produire :
- Le nombre de connexions d’une application peut chuter de manière abrupte, car les utilisateurs ne peuvent pas se connecter.
- Le nombre d’échecs de connexion pourrait augmenter.
Prérequis
- Un locataire Microsoft Entra.
- Un utilisateur a au moins le rôle Administrateur de sécurité.
- Un espace de travail Log Analytics dans votre abonnement Azure pour l’envoi de journaux d’activité aux journaux d’activité Azure Monitor. Découvrez comment créer un espace de travail Log Analytics.
- Journaux Microsoft Entra intégrés aux journaux Azure Monitor. Découvrez comment Intégrer des journaux de connexion Microsoft Entra au flux Azure Monitor.
Configurer le classeur d’intégrité de connexion aux applications
Pour accéder aux workbooks dans le portail Azure, sélectionnez Microsoft Entra ID, puis Workbooks.
Des classeurs s’affichent sous Utilisation, Accès conditionnel et Résoudre des problèmes. Le classeur d’intégrité de connexion aux applications s’affiche dans la section Intégrité. Après avoir utilisé un classeur, celui-ci peut apparaître dans la section Classeurs récemment modifiés.
Vous pouvez utiliser le classeur d’intégrité de connexion aux applications pour visualiser ce qui se passe au niveau de vos connexions. Comme illustré dans la capture d’écran suivante, le classeur présente deux graphiques.
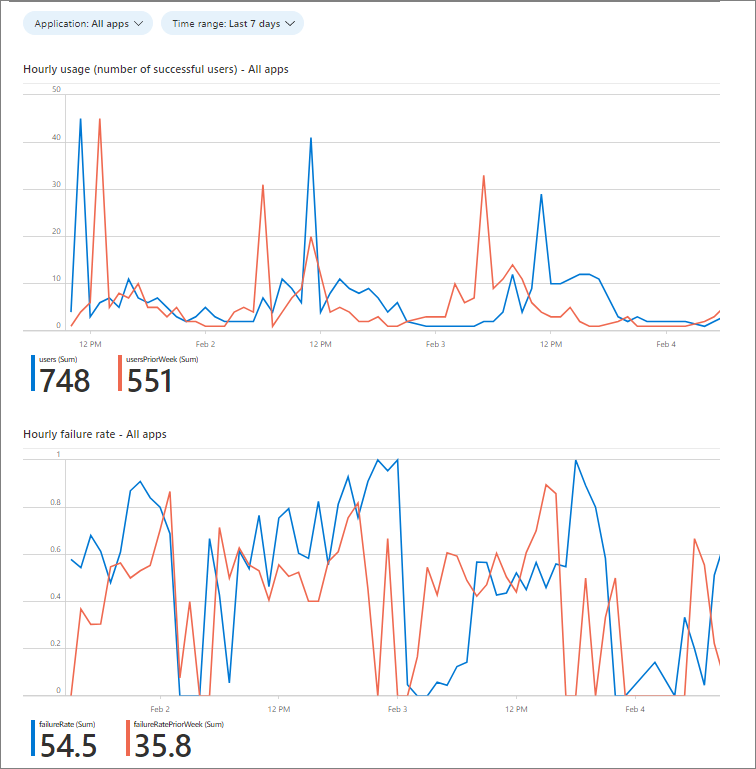
Dans la capture d’écran précédente, il existe deux graphiques :
- Utilisation horaire (nombre d’utilisateurs ayant réussi). En comparant le nombre actuel d’utilisateurs satisfaits à une période d’utilisation typique, vous pouvez repérer une baisse de l’utilisation qui pourrait nécessiter une investigation. Une baisse du taux d’utilisation réussie peut vous aider à identifier des problèmes de niveau de performance et d’utilisation que le taux d’échec ne peut pas détecter. Par exemple, si des utilisateurs ne peuvent pas accéder à votre application pour s’y connecter, il y a une diminution de l’utilisation, sans aucun échec. Consultez l’exemple de requête pour ces données dans la section suivante de cet article.
- Taux d’échec horaire. Un pic dans le taux d’échec peut indiquer un problème avec vos mécanismes d’authentification. Les mesures de taux d’échec s’affichent uniquement lorsque des utilisateurs ont la possibilité de s’authentifier. Lorsque des utilisateurs ne peuvent pas accéder à la tentative, il n’y a pas d’échec.
Configurer la requête et les alertes
Vous créez des règles d'alerte dans Azure Monitor et pouvez exécuter automatiquement des requêtes enregistrées ou des recherches personnalisées dans les journaux à intervalles réguliers. Vous pouvez configurer une alerte qui avertit un groupe spécifique lorsque le taux d’utilisation ou d’échec dépasse un seuil défini.
Utilisez les instructions suivantes pour créer des alertes par e-mail en fonction des requêtes reflétées dans les graphiques. Les exemples de scripts envoient une notification par e-mail quand :
- L’utilisation réussie baisse de 90 % par rapport à la même heure deux jours auparavant, comme illustré dans l’exemple de graphique d’utilisation horaire précédent.
- Le taux d’échec augmente de 90 % par rapport à la même heure il y a deux jours, comme illustré dans l’exemple de graphique de taux d’échec horaire précédent.
Pour configurer la requête sous-jacente et définir des alertes, effectuez les étapes suivantes en utilisant l’exemple de requête comme base pour votre configuration. La description de la structure de requête s’affiche à la fin de cette section. Découvrez comment créer, afficher et gérer des alertes de journal en utilisant Azure Monitor dans Gérer les alertes de journal.
Dans le classeur, sélectionnez Modifier tel qu’illustré dans la capture d’écran suivante. Sélectionnez l’icône de requête dans le coin supérieur droit du graphique.
Affichez le journal des requêtes tel qu’illustré dans la capture d’écran suivante.
Copiez l’un des exemples de scripts suivants pour une nouvelle requête Kusto.
Collez la requête dans la fenêtre. Sélectionnez Exécuter. Recherchez le message Terminé et les résultats de la requête, comme illustré dans la capture d’écran suivante.
Mettez en surbrillance la requête. Sélectionnez + Nouvelle règle d’alerte.
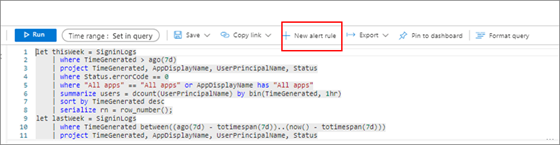
Configurez des conditions d’alerte. Comme illustré dans l’exemple de capture d’écran suivant, dans la section Condition, sous Mesure, sélectionnez Lignes de table pour Mesure. Sélectionnez Compte pour Type d’agrégation. Sélectionnez 2 jours pour Granularité d’agrégation.
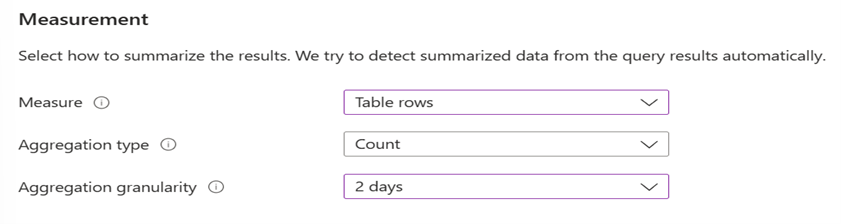
- Lignes de table. Vous pouvez utiliser le nombre de lignes retournées pour les utiliser avec des événements, tels que des exceptions d’application, Syslog et des journaux des événements Windows.
- Type d’agrégation. Points de données appliqués avec le type Count (nombre).
- Granularité d’agrégation. Cette valeur définit la période qui fonctionne avec Fréquence d’évaluation.
Dans Logique d’alerte, configurez les paramètres comme illustré dans l’exemple de capture d’écran.
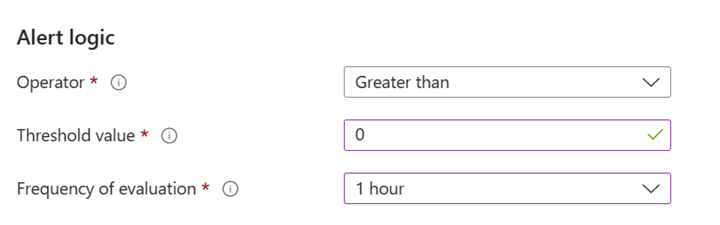
- Valeur de seuil : 0. Cette valeur génère une alerte sur tous les résultats.
- Fréquence d’évaluation : 1 heure. Cette valeur définit la période d’évaluation sur une fois par heure pour l’heure précédente.
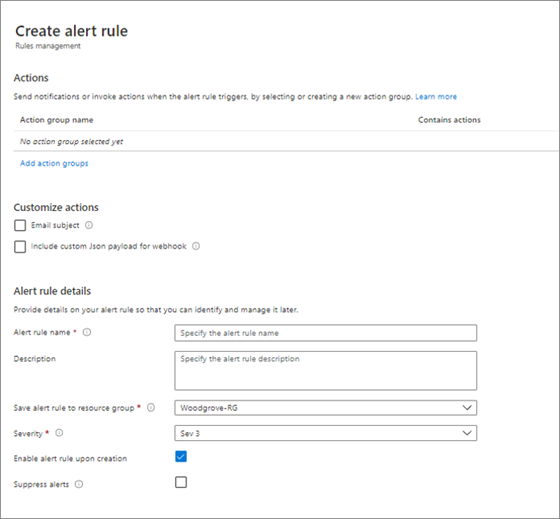
Dans la section Actions, configurez les paramètres comme illustré dans l’exemple de capture d’écran.
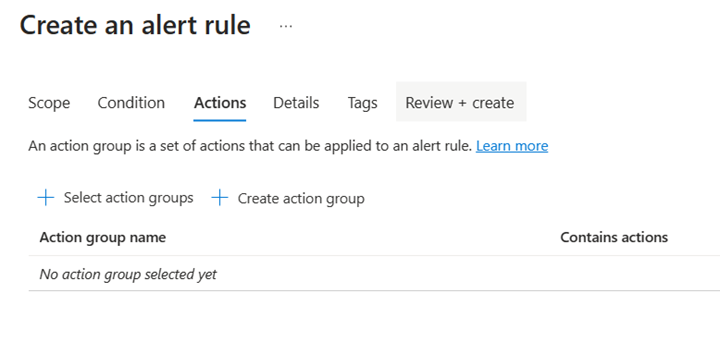
- Sélectionnez Sélectionner un groupe d’actions, puis ajoutez le groupe pour lequel vous souhaitez recevoir des notifications d’alerte.
- Sous Personnaliser les actions, sélectionnez Alertes par e-mail.
- Ajoutez une ligne d’objet.
Dans la section Détails, configurez les paramètres comme illustré dans l’exemple de capture d’écran.
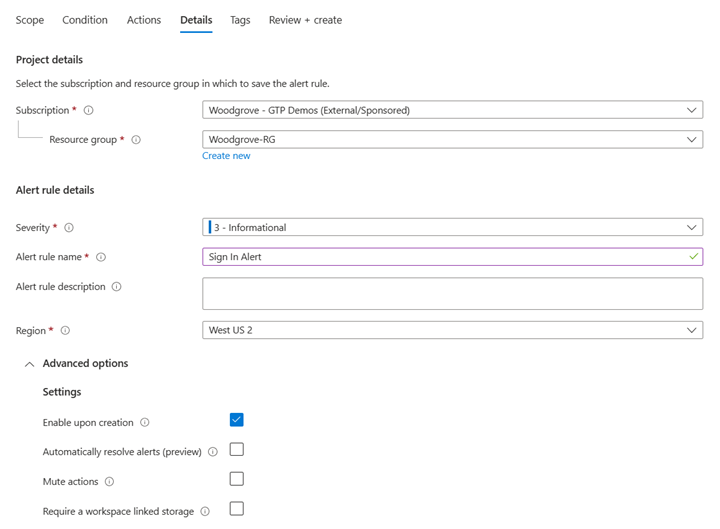
- Ajoutez un nom d’Abonnement et une description.
- Sélectionnez le Groupe de ressources auquel vous souhaitez ajouter l’alerte.
- Sélectionnez la Gravité par défaut.
- Sélectionnez Activer lors de la création si vous souhaitez la mettre immédiatement en ligne. Autrement, sélectionnez Désactiver les actions.
Dans la section Vérifier + créer, configurez les paramètres comme illustré dans l’exemple de capture d’écran.
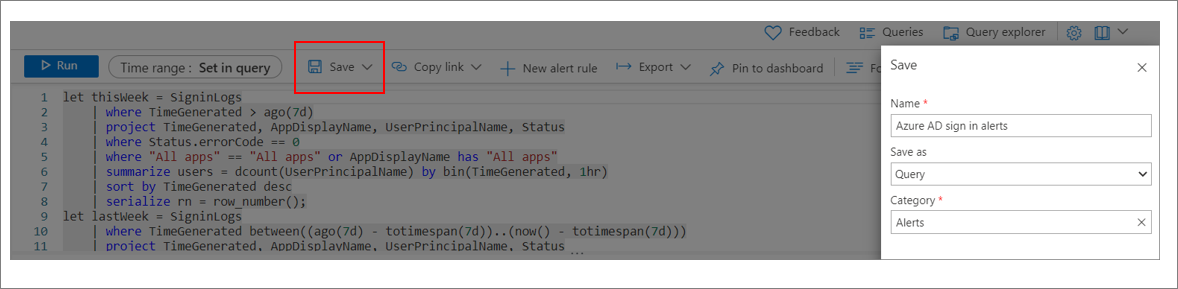
Sélectionnez Enregistrer. Entrez un nom pour la requête. Pour l’option Enregistrer sous, sélectionnez Requête. Pour l’option Catégorie, sélectionnez Alerte. Sélectionnez à nouveau Enregistrer.
Affiner vos requêtes et alertes
Pour modifier vos requêtes et alertes afin de bénéficier d’une efficacité maximale :
- Effectuez toujours un test les alertes.
- Modifiez la sensibilité et la fréquence des alertes afin de recevoir des notifications importantes. En cas de réception élevée, les administrateurs risquent de ne pas prêter attention aux alertes et ainsi de manquer d’importantes informations.
- Dans les clients de messagerie de l’administrateur, ajoutez l’adresse e-mail d’où proviennent les alertes à la liste des expéditeurs autorisés. Cette approche empêche les notifications manquées dues à un filtre de courrier indésirable sur leurs clients de messagerie.
- Par définition, les requêtes d’alerte dans Azure Monitor peuvent uniquement inclure les résultats des dernières 48 heures.
Exemples de scripts
Requête Kusto pour augmentation du taux d’échec
Dans la requête suivante, nous détectons une augmentation des taux d’échec. Si nécessaire, vous pouvez ajuster le ratio en bas de l’écran. Il représente le pourcentage de variation du trafic au cours de la dernière heure par rapport au trafic d’hier à la même heure. Un résultat de 0,5 indique une différence de 50 % dans le trafic.
let today = SigninLogs
| where TimeGenerated > ago(1h) // Query failure rate in the last hour
| project TimeGenerated, UserPrincipalName, AppDisplayName, status = case(Status.errorCode == "0", "success", "failure")
// Optionally filter by a specific application
//| where AppDisplayName == **APP NAME**
| summarize success = countif(status == "success"), failure = countif(status == "failure") by bin(TimeGenerated, 1h) // hourly failure rate
| project TimeGenerated, failureRate = (failure * 1.0) / ((failure + success) * 1.0)
| sort by TimeGenerated desc
| serialize rowNumber = row_number();
let yesterday = SigninLogs
| where TimeGenerated between((ago(1h) – totimespan(1d))..(now() – totimespan(1d))) // Query failure rate at the same time yesterday
| project TimeGenerated, UserPrincipalName, AppDisplayName, status = case(Status.errorCode == "0", "success", "failure")
// Optionally filter by a specific application
//| where AppDisplayName == **APP NAME**
| summarize success = countif(status == "success"), failure = countif(status == "failure") by bin(TimeGenerated, 1h) // hourly failure rate at same time yesterday
| project TimeGenerated, failureRateYesterday = (failure * 1.0) / ((failure + success) * 1.0)
| sort by TimeGenerated desc
| serialize rowNumber = row_number();
today
| join (yesterday) on rowNumber // join data from same time today and yesterday
| project TimeGenerated, failureRate, failureRateYesterday
// Set threshold to be the percent difference in failure rate in the last hour as compared to the same time yesterday
// Day variable is the number of days since the previous Sunday. Optionally ignore results on Sat, Sun, and Mon because large variability in traffic is expected.
| extend day = dayofweek(now())
| where day != time(6.00:00:00) // exclude Sat
| where day != time(0.00:00:00) // exclude Sun
| where day != time(1.00:00:00) // exclude Mon
| where abs(failureRate – failureRateYesterday) > 0.5
Requête Kusto pour baisse de l’utilisation
Dans la requête suivante, nous comparons le trafic de la dernière heure au trafic d’hier à la même heure. Nous excluons le samedi, le dimanche et le lundi, car nous nous attendons à une grande variabilité du trafic de la journée précédente à la même heure.
Si nécessaire, vous pouvez ajuster le ratio en bas de l’écran. Il représente le pourcentage de variation du trafic au cours de la dernière heure par rapport au trafic d’hier à la même heure. Un résultat de 0,5 indique une différence de 50 % dans le trafic. Ajustez ces valeurs en fonction du modèle opérationnel de votre entreprise.
Let today = SigninLogs // Query traffic in the last hour
| where TimeGenerated > ago(1h)
| project TimeGenerated, AppDisplayName, UserPrincipalName
// Optionally filter by AppDisplayName to scope query to a single application
//| where AppDisplayName contains "Office 365 Exchange Online"
| summarize users = dcount(UserPrincipalName) by bin(TimeGenerated, 1hr) // Count distinct users in the last hour
| sort by TimeGenerated desc
| serialize rn = row_number();
let yesterday = SigninLogs // Query traffic at the same hour yesterday
| where TimeGenerated between((ago(1h) – totimespan(1d))..(now() – totimespan(1d))) // Count distinct users in the same hour yesterday
| project TimeGenerated, AppDisplayName, UserPrincipalName
// Optionally filter by AppDisplayName to scope query to a single application
//| where AppDisplayName contains "Office 365 Exchange Online"
| summarize usersYesterday = dcount(UserPrincipalName) by bin(TimeGenerated, 1hr)
| sort by TimeGenerated desc
| serialize rn = row_number();
today
| join // Join data from today and yesterday together
(
yesterday
)
on rn
// Calculate the difference in number of users in the last hour compared to the same time yesterday
| project TimeGenerated, users, usersYesterday, difference = abs(users – usersYesterday), max = max_of(users, usersYesterday)
| extend ratio = (difference * 1.0) / max // Ratio is the percent difference in traffic in the last hour as compared to the same time yesterday
// Day variable is the number of days since the previous Sunday. Optionally ignore results on Sat, Sun, and Mon because large variability in traffic is expected.
| extend day = dayofweek(now())
| where day != time(6.00:00:00) // exclude Sat
| where day != time(0.00:00:00) // exclude Sun
| where day != time(1.00:00:00) // exclude Mon
| where ratio > 0.7 // Threshold percent difference in sign-in traffic as compared to same hour yesterday
Créer des processus pour gérer les alertes
Une fois les requêtes et alertes configurées, créez des processus d’entreprise pour gérer les alertes.
- Qui surveille le classeur et quand ?
- Quand des alertes se produisent, qui les examine ?
- Quels sont les besoins en communication ? Qui crée les communications et qui les reçoit ?
- En cas de panne, quels sont les processus d’entreprise qui s’appliquent ?
Étapes suivantes
En savoir plus sur les classeurs
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour