Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L'extension Fabric Data Engineering pour Visual Studio (VS) Code prend entièrement en charge les opérations de définition des tâches Spark, à savoir la création, la lecture, la mise à jour et la suppression (CRUD), dans Fabric. Après avoir créé une définition de travail Spark, vous pouvez charger d’autres bibliothèques référencées, envoyer une demande d’exécution de la définition de travail Spark et vérifier l’historique des exécutions.
Créer une définition de travail Spark
Pour créer une définition de travail Spark :
Dans l’explorer de VS Code, sélectionnez l’option Créer une définition de travail Spark.

Entrez les champs obligatoires initiaux : nom, lakehouse référencé et lakehouse par défaut.
Les processus de requête et le nom de votre définition de tâche Spark nouvellement créée apparaissent sous le nœud racine de définition de tâche Spark dans VS Code Explorer. Sous le nœud Nom de la définition de tâche Spark, vous voyez trois sous-nœuds :
- Fichiers : liste du fichier de définition principal et d’autres bibliothèques référencées. Vous pouvez charger de nouveaux fichiers à partir de cette liste.
-
Lakehouse : liste de tous les lakehouses référencés par cette définition de travail Spark. Le lakehouse par défaut est marqué dans la liste et vous pouvez y accéder via le chemin d’accès relatif
Files/…, Tables/…. - Exécution : liste de l’historique des exécutions de cette définition de travail Spark et des états de travail de chaque exécution.
Charger un fichier de définition principal dans une bibliothèque référencée
Pour charger ou remplacer le fichier de définition principal, sélectionnez l’option Ajouter un fichier principal.
Pour télécharger le fichier de bibliothèque auquel le fichier de définition principal fait référence, sélectionnez l'option Ajouter un fichier Lib.
Après avoir téléchargé un fichier, vous pouvez le remplacer en cliquant sur l'option Mettre à jour le fichier et en téléchargeant un nouveau fichier, ou vous pouvez supprimer le fichier via l'option Supprimer.
Envoyer une demande d’exécution
Pour envoyer une demande d’exécution de la définition de travail Spark à partir de VS Code :
À partir des options à droite du nom de la définition de travail Spark que vous souhaitez exécuter, sélectionnez l’option Exécuter le travail Spark .

Une fois la demande envoyée, une nouvelle application Apache Spark s’affiche dans le nœud Exécutions de la liste Explorer. Vous pouvez annuler le travail en cours d’exécution en sélectionnant l’option Annuler le travail Spark .
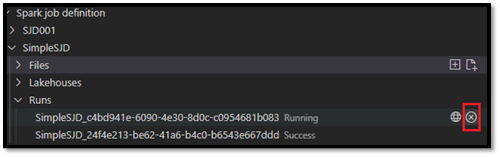
Ouvrir une définition de travail Spark dans le portail Fabric
Vous pouvez ouvrir la page de création de définition de travail Spark dans le portail Fabric en sélectionnant l’option Ouvrir dans le navigateur .
Vous pouvez également sélectionner Ouvrir dans le navigateur en regard d’une exécution terminée pour afficher la page d’analyse des détails de cette exécution.

Déboguer le code source de définition de travail Spark (Python)
Si la définition de travail Spark est créée avec PySpark (Python), vous pouvez télécharger le script .py du fichier de définition principal et du fichier référencé, puis déboguer le script source dans VS Code.
Pour télécharger le code source, sélectionnez l’option Déboguer la définition de travail Spark à droite de la définition du travail Spark.

Une fois le téléchargement terminé, le dossier du code source s'ouvre automatiquement.
Sélectionnez l’option Approuver les auteurs lorsque vous y êtes invité. (Cette option n'apparaît que la première fois que vous ouvrez le dossier. Si vous ne sélectionnez pas cette option, vous ne pouvez pas déboguer ou exécuter le script source. Pour plus d'informations, consultez Sécurité de Visual Studio espace de travail Code Trust.)
Si vous avez déjà téléchargé le code source, vous êtes invité à confirmer que vous souhaitez remplacer la version locale par le nouveau téléchargement.
Remarque
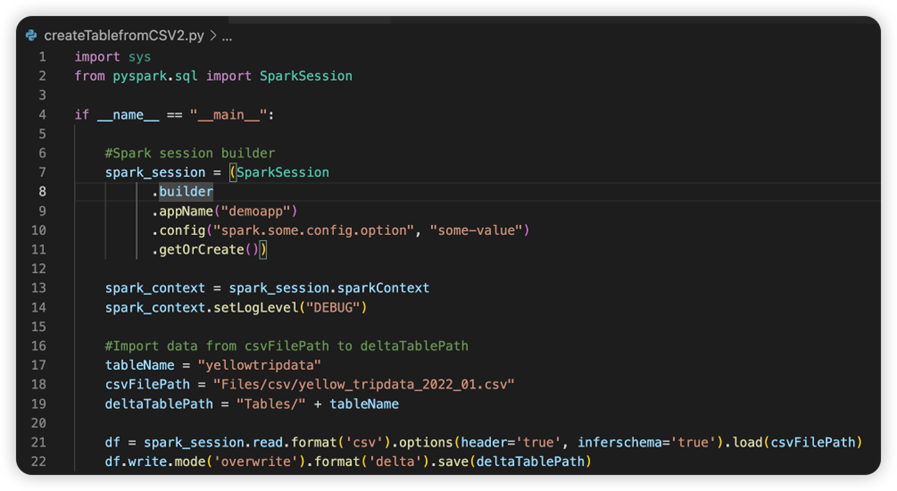
Dans le dossier racine du script source, le système crée un sous-dossier nommé conf. Dans ce dossier, un fichier nommé light-config.json contient certaines métadonnées système nécessaires pour l’exécution à distance. N’apportez AUCUNE modification à celle-ci.
Le fichier nommé sparkconf.py contient un extrait de code que vous devez ajouter pour configurer l’objet SparkConf . Pour activer le débogage à distance, assurez-vous que l’objet SparkConf est correctement configuré. L’image suivante montre la version d’origine du code source.
L’image suivante montre le code source mis à jour après avoir copié et collé l’extrait de code.
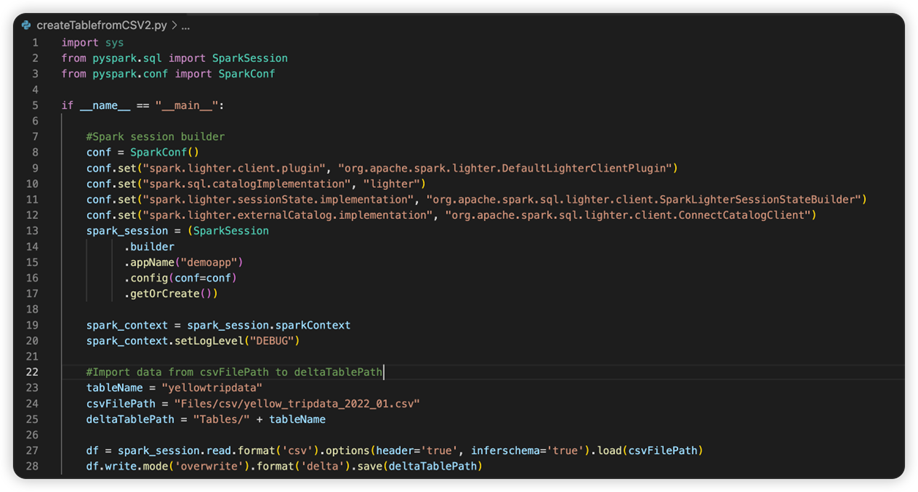
Après avoir mis à jour le code source avec la configuration nécessaire, vous devez choisir l’interpréteur Python approprié. Veillez à sélectionner celui installé dans l’environnement conda synapse-spark-kernel .
Modifier les propriétés de la définition de tâche Spark
Vous pouvez modifier les propriétés détaillées des définitions de travaux Spark, telles que les arguments de ligne de commande.
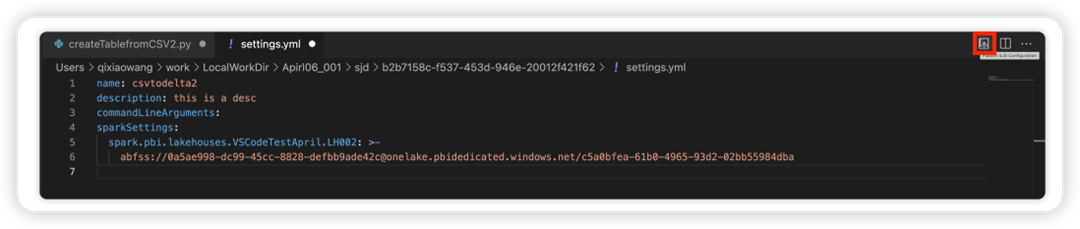
Sélectionnez l’option Mettre à jour la configuration SJD pour ouvrir un fichier settings.yml . Les propriétés existantes remplissent le contenu de ce fichier.
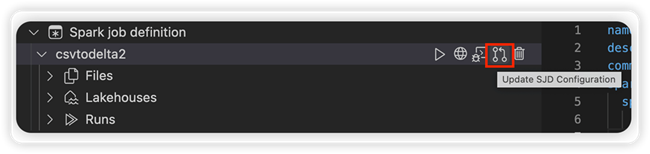
Mettez à jour et enregistrez le fichier .yml.
Sélectionnez l’option Publier la propriété SJD en haut à droite pour synchroniser la modification dans l’espace de travail à distance.