Facturation et rapports d’utilisation pour Apache Spark dans Microsoft Fabric
S’applique à : ![]() l’engineering et la science des données dans Microsoft Fabric
l’engineering et la science des données dans Microsoft Fabric
Cet article décrit les rapports et l’utilisation du calcul pour Apache Spark qui alimente les charges de travail Synapse d’engineering données et de science des données dans Microsoft Fabric. L’utilisation du calcul comprend des opérations de lakehouse comme l’aperçu des tables, le chargement dans delta, les exécutions de notebooks à partir de l’interface, les exécutions planifiées, les exécutions déclenchées par les étapes de notebook dans les pipelines et les exécutions de définition de tâche Apache Spark.
Comme d’autres expériences dans Microsoft Fabric, l’engineering données utilise également la capacité associée à un espace de travail pour exécuter ces travaux, et vos frais de capacité globaux s’affichent dans le portail Azure sous votre abonnement Microsoft Cost Management. Pour en savoir plus sur la facturation Fabric, consultez Comprendre votre facture Azure sur une capacité Fabric.
Capacité Fabric
En tant qu’utilisateur, vous pouvez acheter une capacité Fabric à partir d’Azure en spécifiant l’utilisation d’un abonnement Azure. La taille de la capacité détermine la puissance de calcul disponible. Pour Apache Spark pour Fabric, chaque CU achetée se traduit par 2 vCores Apache Spark. Par exemple, si vous achetez une capacité Fabric F128, vous obtenez 256 SparkVCores. Une capacité Fabric est partagée entre tous les espaces de travail qu’elle contient, et dans lesquels le calcul Apache Spark total autorisé est partagé entre tous les travaux envoyés par tous les espaces de travail associés à une capacité. Pour comprendre les différentes références SKU, l’allocation et la limitation des cœurs sur Spark, consultez Limites de simultanéité et mise en file d’attente dans Apache Spark pour Microsoft Fabric.
Configuration de calcul Spark et capacité achetée
Le calcul Apache Spark pour Fabric offre deux options pour la configuration du calcul.
Pools de démarrage : ces pools par défaut sont un moyen simple et rapide d’utiliser Spark sur la plateforme Microsoft Fabric en quelques secondes. Vous pouvez utiliser des sessions Spark immédiatement, au lieu d’attendre que Spark configure les nœuds pour vous, ce qui vous permet d’en faire plus avec les données et d’obtenir des informations plus rapidement. En ce qui concerne la facturation et la consommation de capacité, vous êtes facturé quand vous commencez à exécuter votre notebook ou la définition de tâche Spark ou l’opération de lakehouse. Vous n'êtes pas facturé pour la durée d'inactivité des clusters dans le pool.
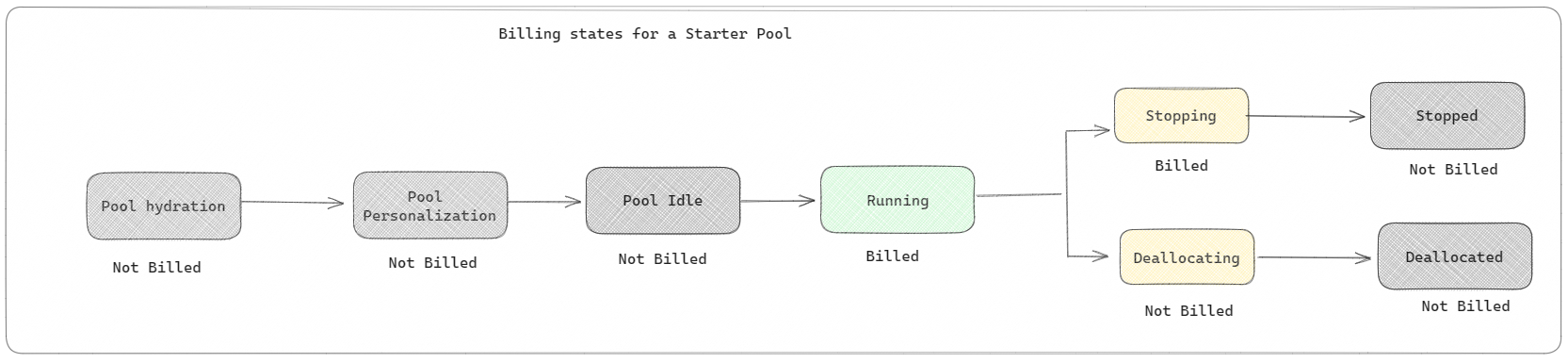
Par exemple, si vous soumettez une tâche de bloc-notes à un pool de démarrage, vous êtes facturé uniquement pour la période pendant laquelle la session de bloc-notes est active. Le temps facturé n'inclut pas le temps d'inactivité ni le temps nécessaire à la personnalisation de la session avec le contexte Spark. Pour en savoir plus sur la configuration des pools de démarrage en fonction de la référence SKU de la capacité Fabric achetée, consultez Configuration des pools de démarrage en fonction de la capacité Fabric
Pools Spark : il s’agit de pools personnalisés, où vous pouvez personnaliser la taille des ressources dont vous avez besoin pour vos tâches d’analyse de données. Vous pouvez donner un nom à votre pool Spark et choisir le nombre et la taille des nœuds (les machines qui effectuent le travail). Vous pouvez également indiquer à Spark comment ajuster le nombre de nœuds en fonction de la quantité de travail dont vous disposez. La création d’un pool Spark est gratuite. vous payez uniquement lorsque vous exécutez une tâche Spark sur le pool, puis Spark configure les nœuds pour vous.
- La taille et le nombre de nœuds que vous pouvez avoir dans votre pool Spark personnalisé dépendent de votre capacité Microsoft Fabric. Vous pouvez utiliser ces vCores Spark pour créer des nœuds de différentes tailles pour votre pool Spark personnalisé, tant que le nombre total de vCores Spark ne dépasse pas 128.
- Les pools Spark sont facturés comme des pools de démarrage ; vous ne payez pas pour les pools Spark personnalisés que vous avez créés, sauf si vous disposez d'une session Spark active créée pour exécuter un notebook ou une définition de tâche Spark. Vous n'êtes facturé que pour la durée de vos exécutions de tâches. Vous n'êtes pas facturé pour des étapes telles que la création et la désallocation du cluster une fois le travail terminé.
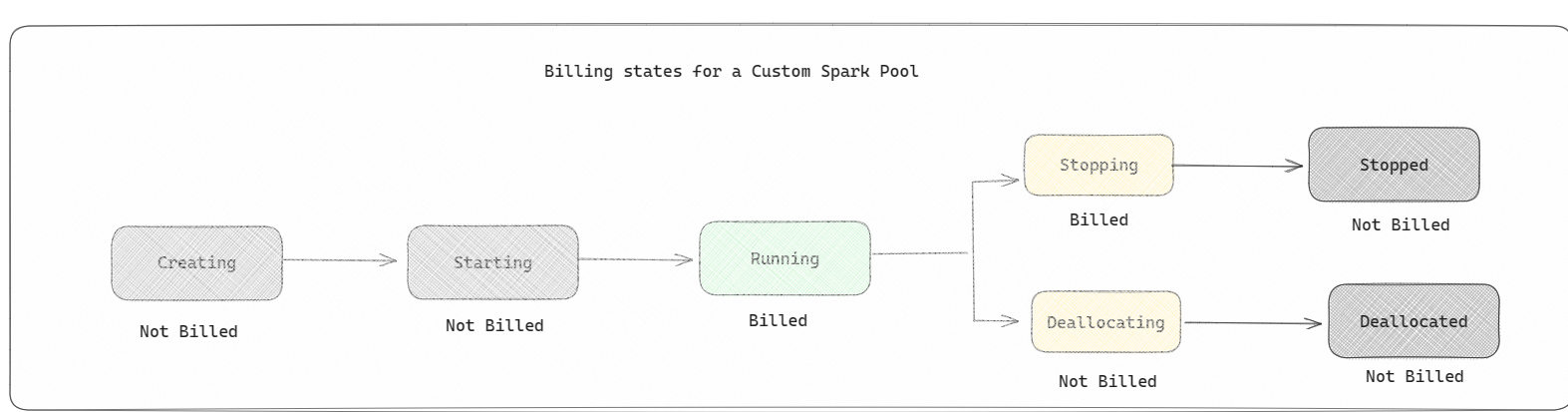
Par exemple, si vous soumettez une tâche de bloc-notes à un pool Spark personnalisé, vous n'êtes facturé que pour la période pendant laquelle la session est active. La facturation de cette session de notebook s'arrête une fois la session Spark arrêtée ou expirée. Vous n'êtes pas facturé pour le temps nécessaire à l'acquisition des instances de cluster à partir du cloud ni pour le temps nécessaire à l'initialisation du contexte Spark. Pour en savoir plus sur la configuration des pools Spark en fonction de la référence SKU de la capacité Fabric achetée, consultez Configuration des pools en fonction de la capacité Fabric


Remarque
La période d’expiration de session par défaut pour les pools de démarrage et les pools Spark que vous créez est définie sur 20 minutes. Si vous n'utilisez pas votre pool Spark pendant 2 minutes après l'expiration de votre session, votre pool Spark sera libéré. Pour arrêter la session et la facturation après avoir terminé l’exécution de votre notebook avant la période d’expiration de la session, vous pouvez cliquer sur le bouton Arrêter la session dans le menu Accueil des notebooks ou accéder à la page hub de surveillance et arrêter la session à cet endroit.
Rapports d’utilisation du calcul Spark
L’application Métriques de capacité Microsoft Fabric offre une visibilité de l’utilisation de la capacité pour toutes les charges de travail Fabric à un seul endroit. Ils sont utilisés par les administrateurs de capacité pour monitorer les performances des charges de travail et leur utilisation, par rapport à la capacité achetée.
Une fois que vous avez installé l’application, sélectionnez le type d’élément Notebook,Lakehouse,Définition de tâche Spark dans la liste déroulante Sélectionner un type d’élément :. Le graphique Ruban multimétrique peut maintenant être ajusté sur la période souhaitée pour comprendre l’utilisation de tous ces éléments sélectionnés.
Toutes les opérations associées à Spark sont classées en tant qu’opérations en arrière-plan. La consommation de capacité à partir de Spark s’affiche sous un notebook, une définition de travail Spark ou un lakehouse, et est agrégée par nom d’opération et par élément. Par exemple : si vous exécutez un travail de notebook, vous pouvez voir l’exécution du notebook, les unités de capacité utilisées par le notebook (nombre total de vCores Spark/2 car 1 CU donne 2 vCores Spark), la durée du travail dans le rapport.
 Pour en savoir plus sur les rapports d’utilisation de la capacité Spark, consultez Surveiller la consommation de capacité Apache Spark
Pour en savoir plus sur les rapports d’utilisation de la capacité Spark, consultez Surveiller la consommation de capacité Apache Spark
Exemple de facturation
Prenez en compte le scénario suivant :
Prenons une capacité C1 qui héberge un espace de travail Fabric W1, et cet espace de travail contient le lakehouse LH1 et le notebook NB1.
- Toute opération Spark effectuée par le notebook(NB1) ou le lakehouse(LH1) est signalée par rapport à la capacité C1.
Étendons cet exemple à un scénario où une autre capacité C2 héberge un espace de travail Fabric W2 et supposons que cet espace de travail contient une définition de tâche Spark (SJD1) et un lakehouse (LH2).
- Si la définition de tâche Spark (SDJ2) de l’espace de travail (W2) lit les données du lakehouse (LH1), l’utilisation est signalée par rapport à la capacité C2 associée à l’espace de travail (W2) hébergeant l’élément.
- Si le notebook (NB1) effectue une opération de lecture à partir de Lakehouse(LH2), la consommation de capacité est signalée par rapport à la capacité C1 qui alimente l’espace de travail W1 qui héberge l’élément de notebook.
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour