Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les expériences d’ingénierie des données et de science des données Microsoft Fabric fonctionnent sur une plateforme de calcul Spark entièrement managée. Par défaut, tous les travaux Spark d’un espace de travail partagent les mêmes paramètres de pool et de ressources, mais différentes charges de travail ont souvent des exigences différentes. Une transformation de données légère n’a pas besoin de la même mémoire de pilote qu’un travail machine learning à grande échelle.
Les environnements fabric vous permettent d’adapter la configuration de calcul Spark par charge de travail, afin que chaque notebook ou définition de travail Spark puisse s’exécuter avec la version, le pool et le dimensionnement du pilote/exécuteur appropriés sans modifier les valeurs par défaut à l’échelle de l’espace de travail.
Configurer les paramètres de calcul au niveau de l’espace de travail
Les administrateurs d’espace de travail contrôlent si les éléments d’environnement peuvent remplacer la configuration de calcul par défaut de l’espace de travail. La personnalisation au niveau de l’élément désactivée garantit une utilisation cohérente des ressources dans l’espace de travail. L’activation offre aux membres et aux contributeurs la possibilité d'ajuster le calcul pour les charges de travail individuelles.
Dans votre navigateur, accédez à votre espace de travail Fabric dans le portail Fabric.
Sélectionnez Paramètres de l’espace de travail.
Sélectionnez Ingénierie/Science des données, puis sélectionnez Paramètres Spark.
Sélectionnez l’onglet Pool .
Activez le commutateur configurations de calcul pour les éléments sur Activé.
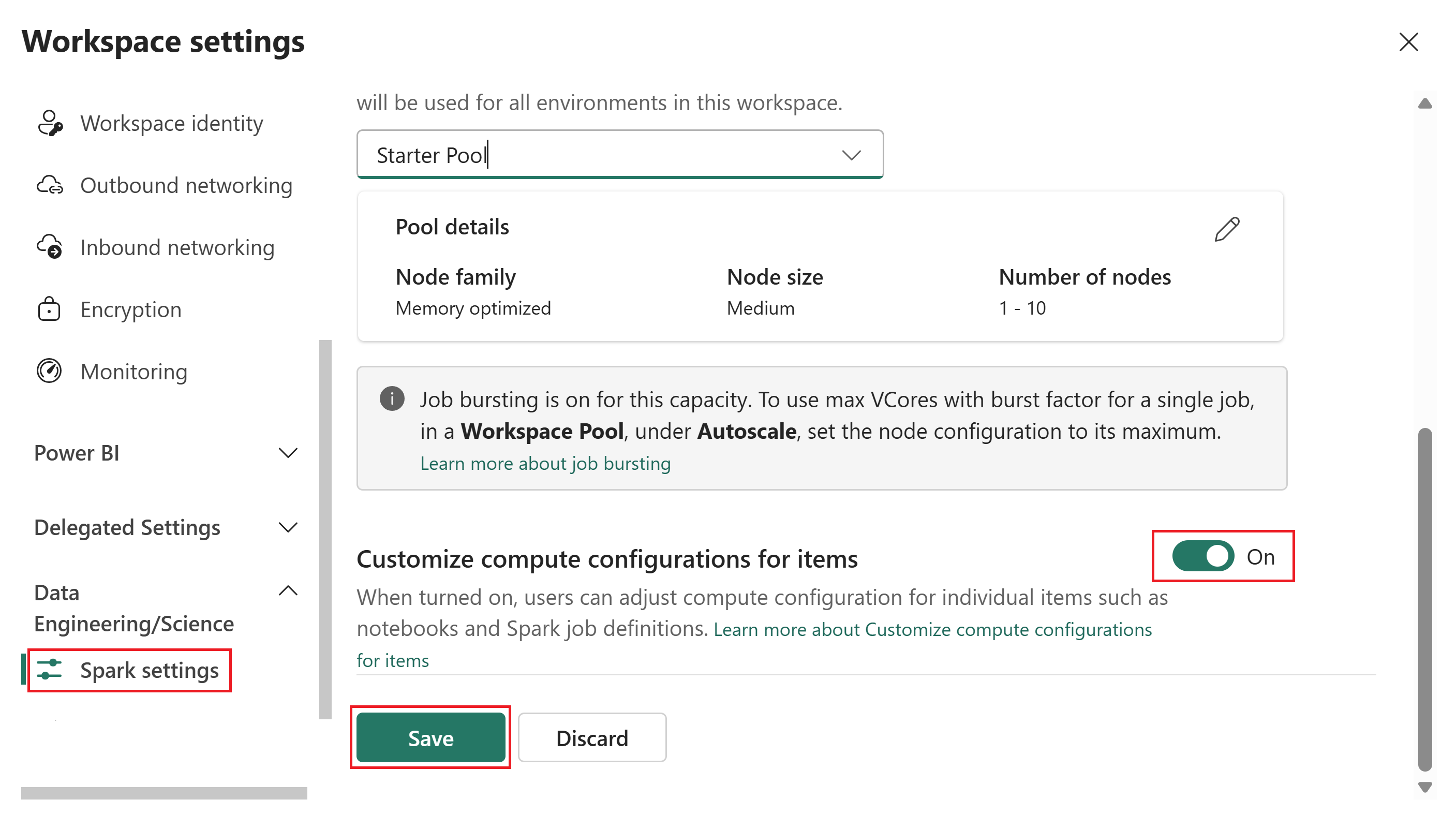
Lorsque cet interrupteur est activé, les membres et les contributeurs peuvent modifier les configurations de calcul computationnel au niveau de la session dans un environnement Fabric. Lorsqu’il est désactivé, la section Calcul dans les éléments d’environnement est désactivée et tous les travaux Spark utilisent le pool par défaut de l’espace de travail.
Cliquez sur Enregistrer.

Configurer le calcul dans un environnement
Une fois qu’un administrateur d’espace de travail active la personnalisation au niveau de l’élément, vous pouvez configurer les paramètres de calcul à l’intérieur d’un élément d’environnement. Cela inclut le choix d’un runtime Spark, la sélection d’un pool et le réglage des ressources du pilote et de l’exécuteur.
Sélectionner un runtime Spark
Ouvrez votre élément d’environnement.
Sous l’onglet Accueil , sélectionnez la liste déroulante Runtime et choisissez une version du runtime.


Chaque runtime Spark a ses propres paramètres par défaut et packages préinstallés.
Important
- Les modifications du runtime ne prennent pas effet tant que vous n’avez pas enregistré et publié l’environnement.
- Si les bibliothèques existantes ou les paramètres de calcul ne sont pas compatibles avec le runtime sélectionné, la publication échoue. Supprimez ou mettez à jour les paramètres incompatibles, puis publiez à nouveau.
- Pour obtenir des instructions de publication pas à pas, consultez Enregistrer et publier des modifications.
Sélectionner un pool et ajuster les propriétés de calcul
Ouvrez l’environnement et accédez à la section Calcul .
Sous Pool d’environnement, sélectionnez le pool de démarrage ou un pool personnalisé créé par votre administrateur d’espace de travail.
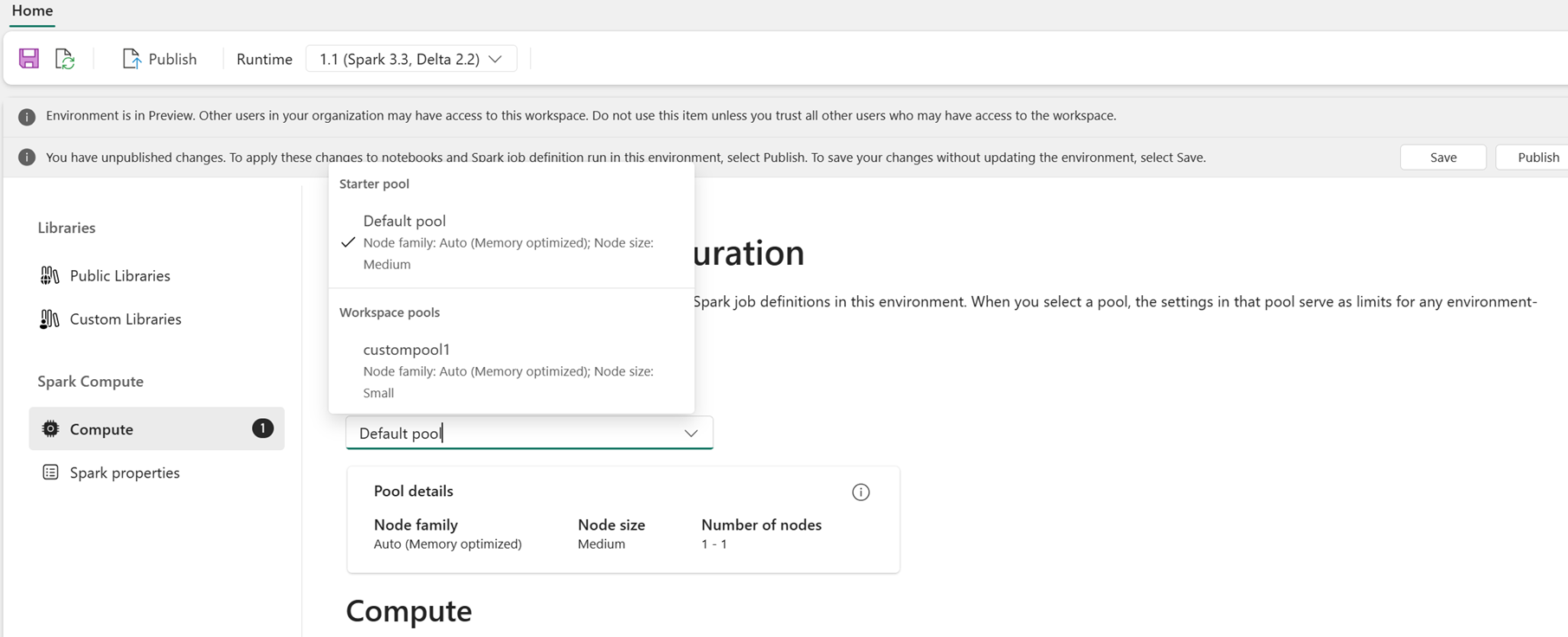
Utilisez les listes déroulantes de la page Calcul pour configurer les propriétés Spark au niveau de la session pour le pool sélectionné. Les valeurs disponibles dépendent de la taille du nœud du pool.
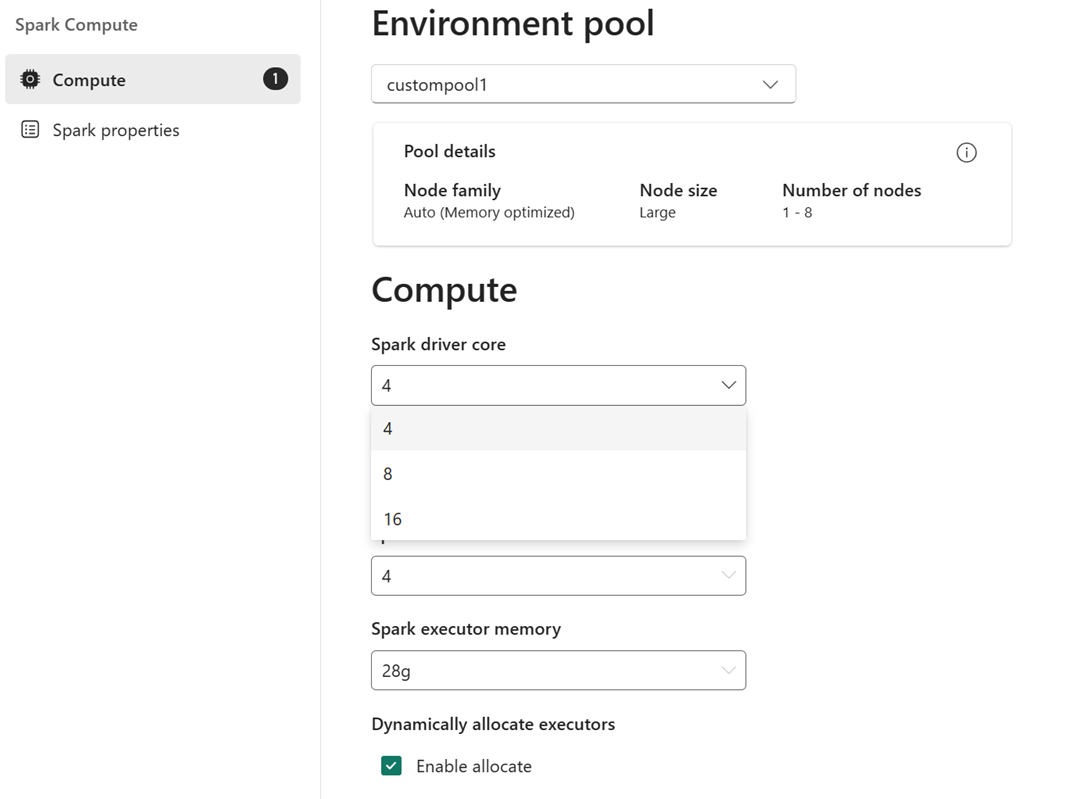
Les propriétés sont les suivantes :
- Cœurs de pilote Spark : nombre de cœurs alloués au pilote Spark.
- Mémoire du pilote Spark : quantité de mémoire allouée au pilote Spark.
- Cœurs d’exécuteur Spark : nombre de cœurs alloués à chaque exécuteur.
- Mémoire de l’exécuteur Spark : quantité de mémoire allouée à chaque exécuteur.


Pour plus d’informations sur les tailles de pool disponibles et les limites de ressources, consultez calcul Spark dans Fabric.
Note
Les propriétés Spark définies via spark.conf.set paramètrent les niveaux d'application et ne sont pas liées aux paramètres de calcul de l’environnement décrits ici.