Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'applique à :✅ Fabric Data Engineering et Data Science
Découvrez comment envoyer des travaux de traitement par lots Spark à l’aide de l’API Livy pour Fabric Data Engineering. Actuellement, l'API Livy ne prend pas en charge le Principal de Service Azure (SPN).
Prérequis
Fabric Premium ou Capacité d'essai avec un Lakehouse.
Un client distant tel que Visual Studio Code avec Jupyter Notebooks, PySpark et le Microsoft Authentication Library (MSAL) pour Python.
Un jeton d’application Microsoft Entra est requis pour accéder à l’API Rest Fabric. Registrer une application avec le Microsoft identity platform.
Certaines données dans votre lakehouse, cet exemple utilise le fichier Parquet NYC Taxi & Limousine Commission green_tripdata_2022_08 chargé dans le lakehouse.
L’API Livy définit un point de terminaison unifié pour les opérations. Remplacez les espaces réservés {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} et {Fabric_LakehouseID} par vos valeurs appropriées lorsque vous suivez les exemples de cet article.
Configurer Visual Studio Code pour votre ensemble d’API Livy
Sélectionnez Lakehouse Settings dans votre Fabric Lakehouse.

Accédez à la section Point de terminaison Livy.
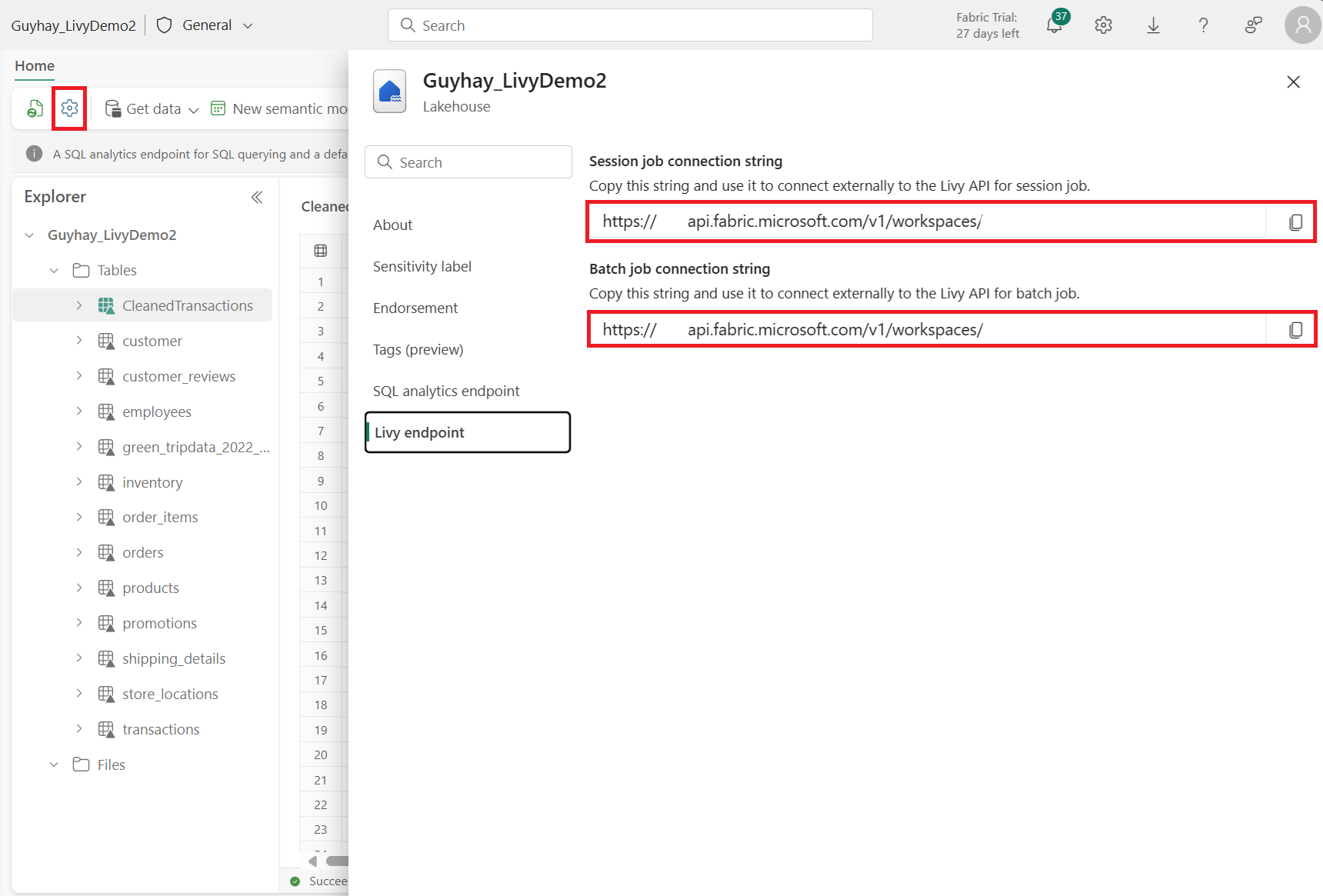
Copiez la chaîne de connexion Batch (la deuxième zone rouge dans l'image) dans votre code.
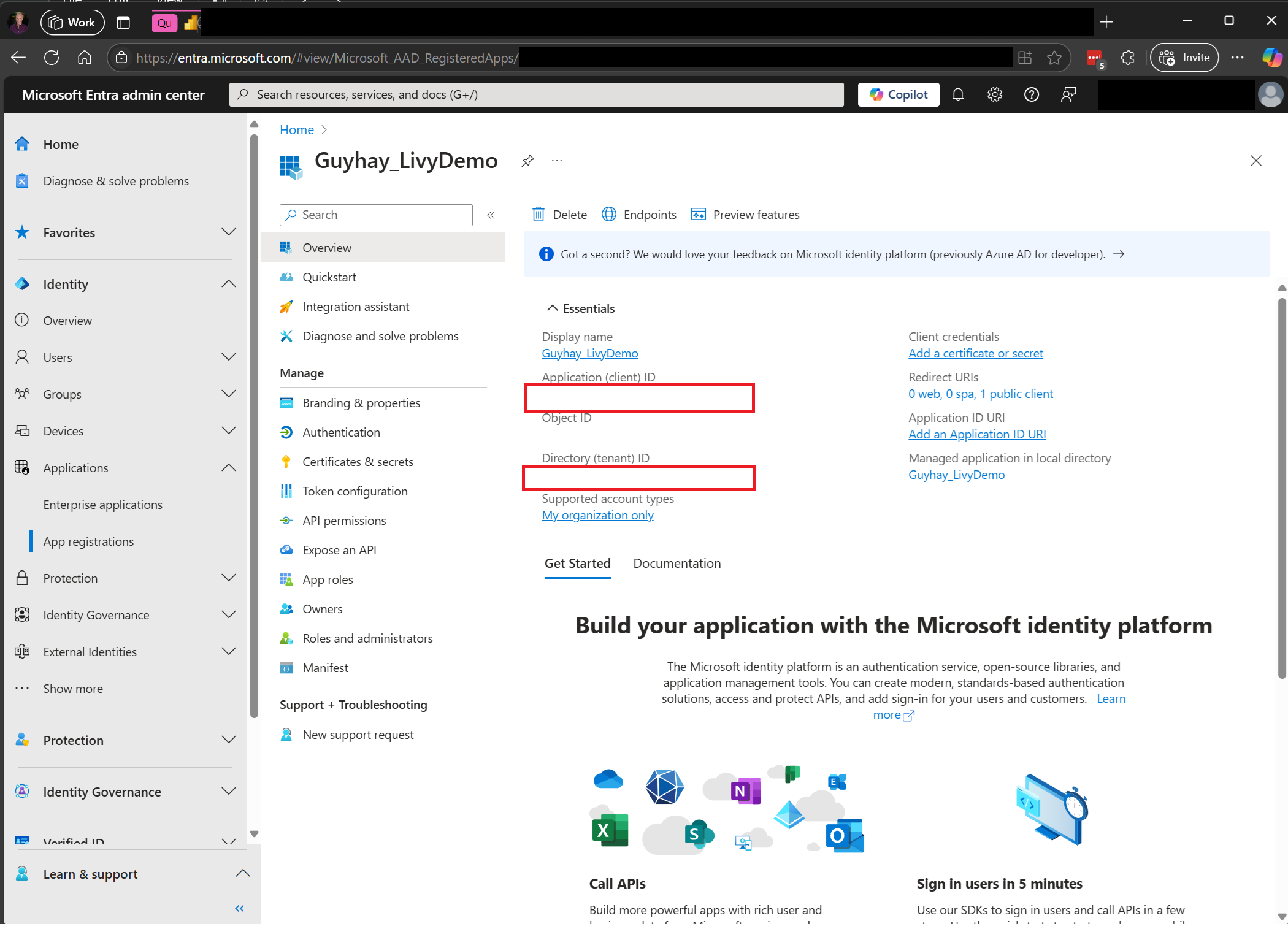
Accédez à Microsoft Entra admin center et copiez l’ID d’application (client) et l’ID d’annuaire (locataire) dans votre code.



Créez un code Spark Batch et chargez-le dans votre Lakehouse
Créer un bloc-notes
.ipynbdans Visual Studio Code et insérer le code suivantimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("batch_demo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") tableName = spark_context.getConf().get("spark.targetTable") if tableName is not None: print("tableName: " + str(tableName)) else: print("tableName is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM green_tripdata_2022 where total_amount > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("lpep_pickup_datetime").substr(1, 4)) deltaTablePath = f"Tables/{tableName}CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Enregistrez le fichier Python localement. Cette charge utile de code Python contient deux instructions Spark qui fonctionnent sur les données d’un Lakehouse et doivent être chargées dans votre Lakehouse. Vous avez besoin du chemin ABFS (Azure Blob File System) du payload pour référencer dans votre job de lot API Livy dans Visual Studio Code et le nom de votre table Lakehouse dans l’instruction
SELECTSQL.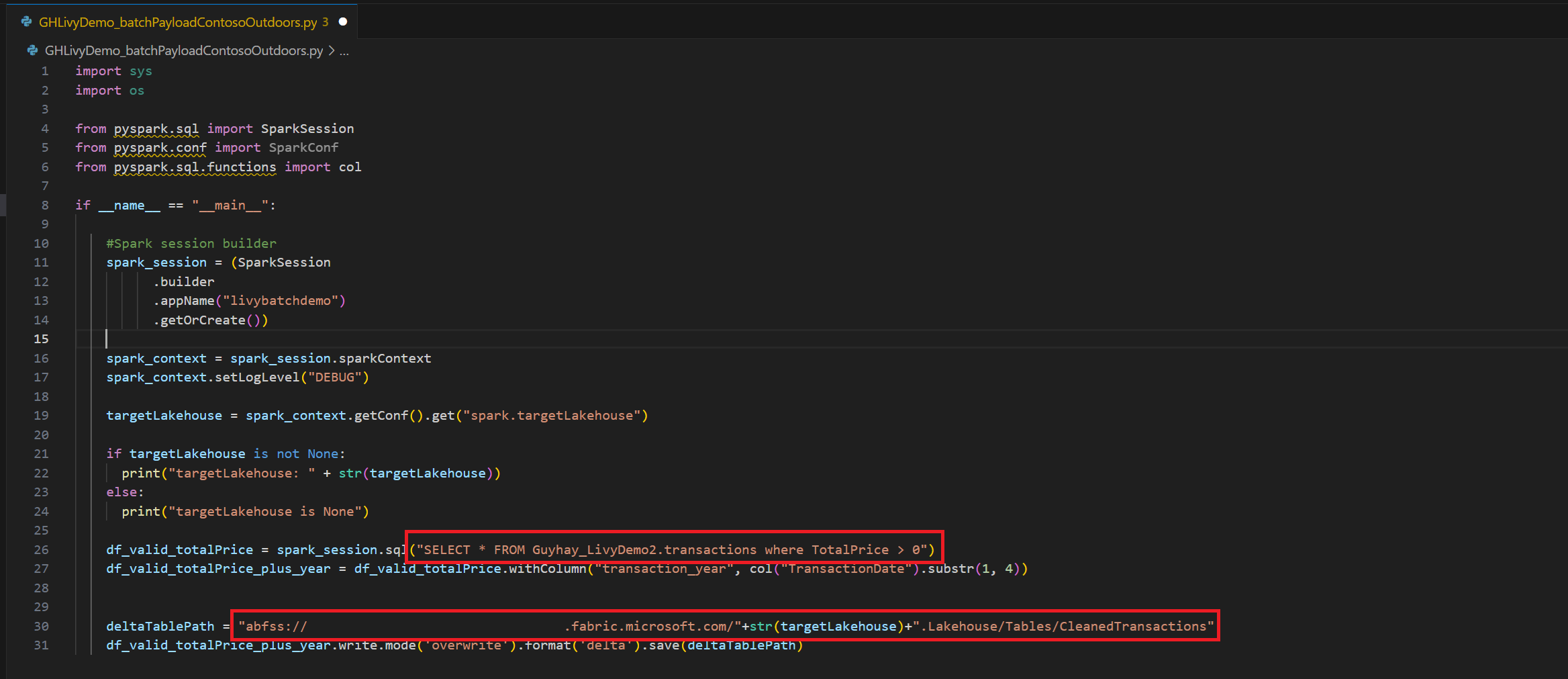
Chargez la charge utile Python dans la section fichiers de votre Lakehouse. Dans l’explorateur Lakehouse, sélectionnez Fichiers. > Sélectionnez Obtenir des données>Télécharger des fichiers. Sélectionnez des fichiers via le sélecteur de fichiers.
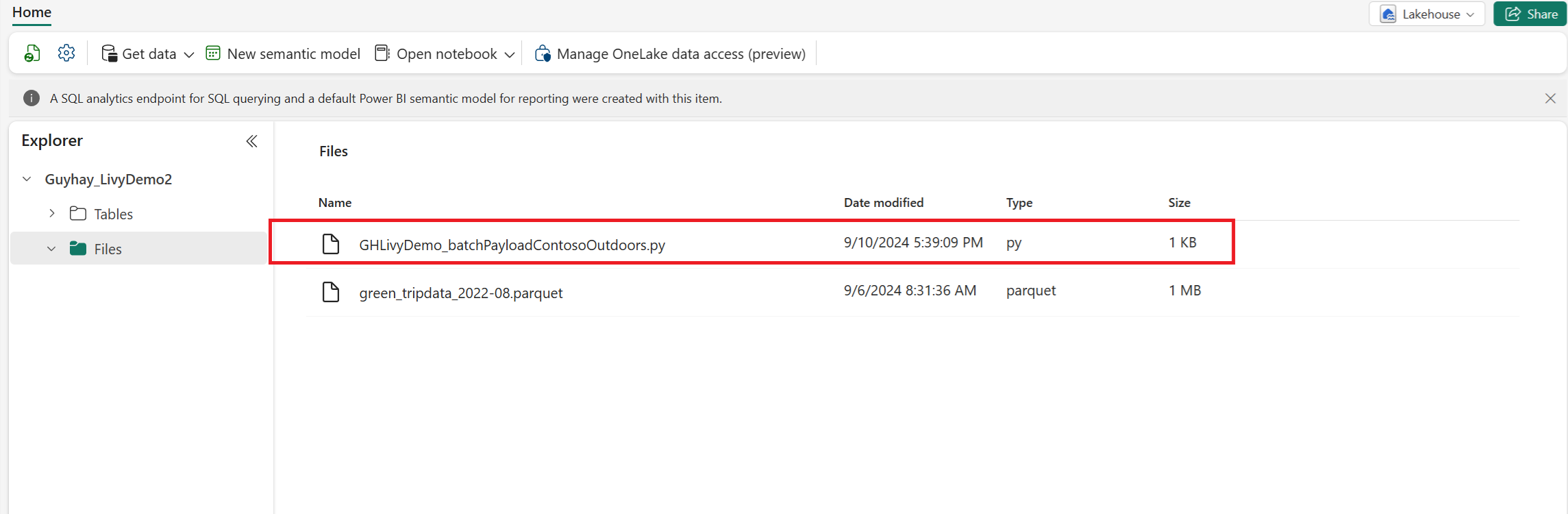
Une fois le fichier dans la section Fichiers de votre Lakehouse, sélectionnez les trois points (points de suspension) à droite de votre nom de fichier de charge utile, puis sélectionnez Propriétés.
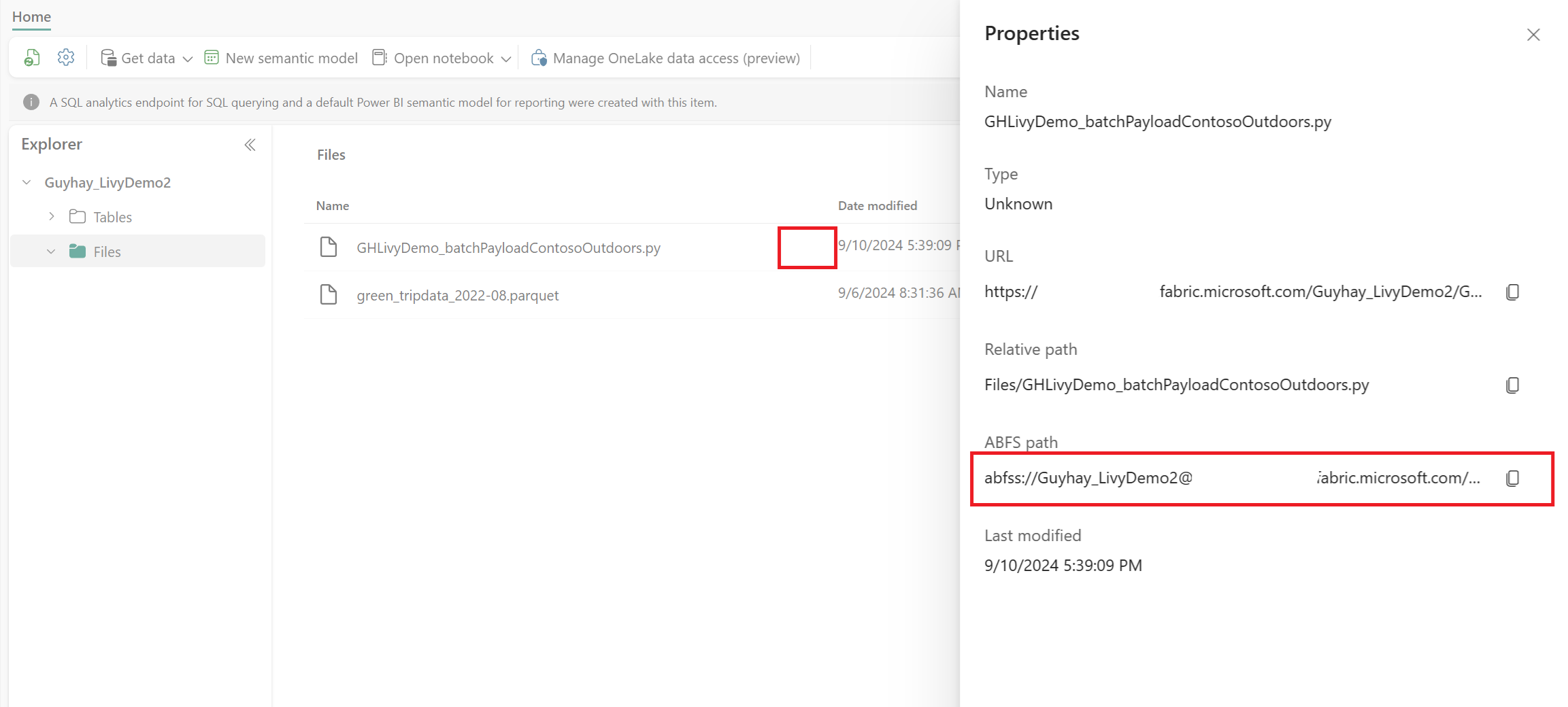
Copiez ce chemin ABFS dans votre cellule Notebook à l’étape 1.



Authentifier une session de commande Spark d’API Livy à l’aide d’un jeton utilisateur Microsoft Entra ou d’un jeton SPN Microsoft Entra
Authentifier une session de commande Spark d’API Livy à l’aide d’un jeton SPN Microsoft Entra
Créez un bloc-notes
.ipynbdans Visual Studio Code et insérez le code suivant.import sys from msal import ConfidentialClientApplication # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Service Principal Application ID # Certificate paths - Update these paths to your certificate files certificate_path = "PATH_TO_YOUR_CERTIFICATE.pem" # Public certificate file private_key_path = "PATH_TO_YOUR_PRIVATE_KEY.pem" # Private key file certificate_thumbprint = "YOUR_CERTIFICATE_THUMBPRINT" # Certificate thumbprint # OAuth settings audience = "https://analysis.windows.net/powerbi/api/.default" authority = f"https://login.windows.net/{tenant_id}" def get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint=None): """ Get an app-only access token for a Service Principal using OAuth 2.0 client credentials flow. This function uses certificate-based authentication which is more secure than client secrets. Args: client_id (str): The Service Principal's client ID audience (str): The audience for the token (resource scope) authority (str): The OAuth authority URL certificate_path (str): Path to the certificate file (.pem format) private_key_path (str): Path to the private key file (.pem format) certificate_thumbprint (str): Certificate thumbprint (optional but recommended) Returns: str: The access token for API authentication Raises: Exception: If token acquisition fails """ try: # Read the certificate from PEM file with open(certificate_path, "r", encoding="utf-8") as f: certificate_pem = f.read() # Read the private key from PEM file with open(private_key_path, "r", encoding="utf-8") as f: private_key_pem = f.read() # Create the confidential client application app = ConfidentialClientApplication( client_id=client_id, authority=authority, client_credential={ "private_key": private_key_pem, "thumbprint": certificate_thumbprint, "certificate": certificate_pem } ) # Acquire token using client credentials flow token_response = app.acquire_token_for_client(scopes=[audience]) if "access_token" in token_response: print("Successfully acquired access token") return token_response["access_token"] else: raise Exception(f"Failed to retrieve token: {token_response.get('error_description', 'Unknown error')}") except FileNotFoundError as e: print(f"Certificate file not found: {e}") sys.exit(1) except Exception as e: print(f"Error retrieving token: {e}", file=sys.stderr) sys.exit(1) # Get the access token token = get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint)Exécutez la cellule du bloc-notes, et vous devriez voir le jeton Microsoft Entra retourné.


Authentifier une session Spark d’API Livy à l’aide d’un jeton utilisateur Microsoft Entra
Créez un bloc-notes
.ipynbdans Visual Studio Code et insérez le code suivant.from msal import PublicClientApplication import requests import time # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Application ID (can be the same as above or different) # Required scopes for Livy API access scopes = [ "https://api.fabric.microsoft.com/Lakehouse.Execute.All", # Required — execute operations in lakehouses "https://api.fabric.microsoft.com/Lakehouse.Read.All", # Required — read lakehouse metadata "https://api.fabric.microsoft.com/Code.AccessFabric.All", # Required — general Fabric API access from Spark Runtime "https://api.fabric.microsoft.com/Code.AccessStorage.All", # Required — access OneLake and Azure storage from Spark Runtime ] # Optional scopes — add these only if your Spark jobs need access to the corresponding services: # "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All" # Optional — access Azure Key Vault from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All" # Optional — access Azure Data Lake Storage Gen1 from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All" # Optional — access Azure Data Explorer from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessSQL.All" # Optional — access Azure SQL audience tokens from Spark Runtime def get_access_token(tenant_id, client_id, scopes): """ Get an access token using interactive authentication. This method will open a browser window for user authentication. Args: tenant_id (str): The Azure Active Directory tenant ID client_id (str): The application client ID scopes (list): List of required permission scopes Returns: str: The access token, or None if authentication fails """ app = PublicClientApplication( client_id, authority=f"https://login.microsoftonline.com/{tenant_id}" ) print("Opening browser for interactive authentication...") token_response = app.acquire_token_interactive(scopes=scopes) if "access_token" in token_response: print("Successfully authenticated") return token_response["access_token"] else: print(f"Authentication failed: {token_response.get('error_description', 'Unknown error')}") return None # Uncomment the lines below to use interactive authentication token = get_access_token(tenant_id, client_id, scopes) print("Access token acquired via interactive login")Exécutez la cellule de notebook. Une fenêtre contextuelle devrait apparaître dans votre navigateur pour vous permettre de choisir l’identité avec laquelle vous connecter.
Après avoir choisi l’identité à utiliser pour vous connecter, vous devez approuver les autorisations de l’API d’inscription d’application Microsoft Entra.
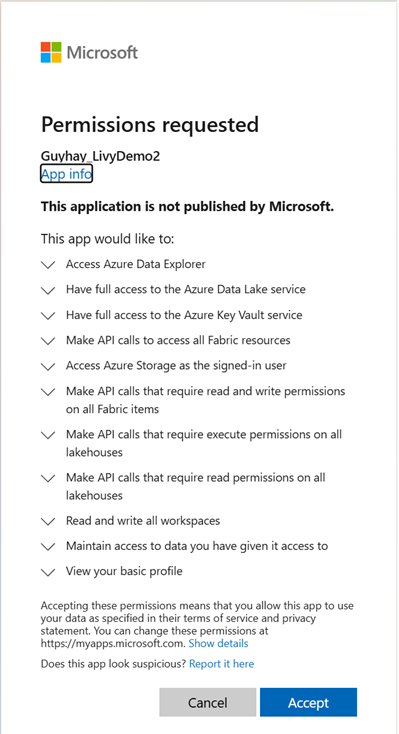
Fermez la fenêtre du navigateur après avoir procédé à l’authentification.

Dans Visual Studio Code, vous devez voir le jeton Microsoft Entra retourné.
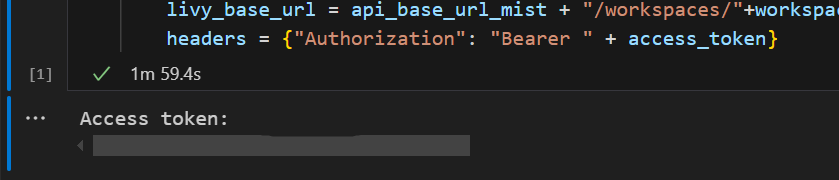




Comprendre les portées Code.* pour l'API Livy
Lorsque vos travaux Spark s’exécutent via l’API Livy, les Code.* étendues contrôlent les services externes auxquels le runtime Spark peut accéder pour le compte de l’utilisateur authentifié. Deux sont nécessaires ; le reste est facultatif en fonction de votre charge de travail.
Périmètres requis de code.*
| Étendue | Description |
|---|---|
Code.AccessFabric.All |
Permet d’obtenir des jetons d’accès à Microsoft Fabric. Obligatoire pour toutes les opérations d’API Livy. |
Code.AccessStorage.All |
Permet d’obtenir des jetons d’accès à OneLake et au stockage Azure. Requis pour la lecture et l’écriture de données dans les lakehouses (environnement de stockage de données). |
Étendues de code facultatives.*
Ajoutez ces étendues uniquement si vos travaux Spark doivent accéder aux services de Azure correspondants au moment de l’exécution.
| Étendue | Description | Quand utiliser |
|---|---|---|
Code.AccessAzureKeyvault.All |
Permet d’obtenir des jetons d’accès à Azure Key Vault. | Votre code Spark récupère des secrets, des clés ou des certificats à partir de Azure Key Vault. |
Code.AccessAzureDataLake.All |
Permet d’obtenir des jetons d’accès à Azure Data Lake Storage Gen1. | Votre code Spark lit ou écrit dans les comptes Azure Data Lake Storage Gen1. |
Code.AccessAzureDataExplorer.All |
Permet d’obtenir des jetons d’accès à Azure Data Explorer (Kusto). | Votre code Spark interroge ou ingère des données depuis/vers des clusters Azure Data Explorer. |
Code.AccessSQL.All |
Permet d’obtenir des jetons d’accès à Azure SQL. | Votre code Spark doit se connecter aux bases de données Azure SQL. |
Note
Les étendues Lakehouse.Execute.All et Lakehouse.Read.All sont également requises, mais ne font pas partie de la famille Code.*. Ils accordent l’autorisation d’exécuter des opérations dans et de lire des métadonnées à partir de Fabric lakehouses respectivement.
Soumettez un lot Livy et surveillez le travail de traitement par lots.
Ajoutez une autre cellule de notebook et insérez ce code.
# submit payload to existing batch session import requests import time import json api_base_url = "https://api.fabric.microsoft.com/v1" # Base URL for Fabric APIs # Fabric Resource IDs - Replace with your workspace and lakehouse IDs workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" # Construct the Livy Batch API URL # URL pattern: {base_url}/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyApi/versions/{api_version}/batches livy_base_url = f"{api_base_url}/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyApi/versions/2023-12-01/batches" # Set up authentication headers headers = {"Authorization": f"Bearer {token}"} print(f"Livy Batch API URL: {livy_base_url}") new_table_name = "TABLE_NAME" # Name for the new table # Configure the batch job print("Configuring batch job parameters...") # Batch job configuration - Modify these values for your use case payload_data = { # Job name - will appear in the Fabric UI "name": f"livy_batch_demo_{new_table_name}", # Path to your Python file in the lakehouse "file": "<ABFSS_PATH_TO_YOUR_PYTHON_FILE>", # Replace with your Python file path # Optional: Spark configuration parameters "conf": { "spark.targetTable": new_table_name, # Custom configuration for your application }, } print("Batch Job Configuration:") print(json.dumps(payload_data, indent=2)) try: # Submit the batch job print("\nSubmitting batch job...") post_batch = requests.post(livy_base_url, headers=headers, json=payload_data) if post_batch.status_code == 202: batch_info = post_batch.json() print("Livy batch job submitted successfully!") print(f"Batch Job Info: {json.dumps(batch_info, indent=2)}") # Extract batch ID for monitoring batch_id = batch_info['id'] livy_batch_get_url = f"{livy_base_url}/{batch_id}" print(f"\nBatch Job ID: {batch_id}") print(f"Monitoring URL: {livy_batch_get_url}") else: print(f"Failed to submit batch job. Status code: {post_batch.status_code}") print(f"Response: {post_batch.text}") except requests.exceptions.RequestException as e: print(f"Network error occurred: {e}") except json.JSONDecodeError as e: print(f"JSON decode error: {e}") print(f"Response text: {post_batch.text}") except Exception as e: print(f"Unexpected error: {e}")Exécutez la cellule de notebook, vous devriez voir plusieurs lignes imprimées lorsqu'une tâche par lots Livy est créée et exécutée.

Pour voir les modifications, revenez à votre Lakehouse.

Intégration avec des environnements Fabric
Par défaut, cette session d’API Livy s’exécute sur le pool de démarrage par défaut de l’espace de travail. Vous pouvez également utiliser Fabric environnements Create, configurer et utiliser un environnement dans Microsoft Fabric pour personnaliser le pool Spark utilisé par la session API Livy pour ces travaux Spark. Pour utiliser votre environnement Fabric, mettez à jour la cellule de notebook précédente avec cette modification d'une seule ligne.
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # remove this line to use starter pools instead of an environment, replace "EnvironmentID" with your environment ID
}
}
Afficher vos travaux dans le hub de supervision
Vous pouvez accéder au hub de supervision pour afficher diverses activités Apache Spark en sélectionnant Superviser dans les liens de navigation de gauche.
Lorsque le travail par lots est terminé, vous pouvez voir l'état de la session en accédant à Surveillance.
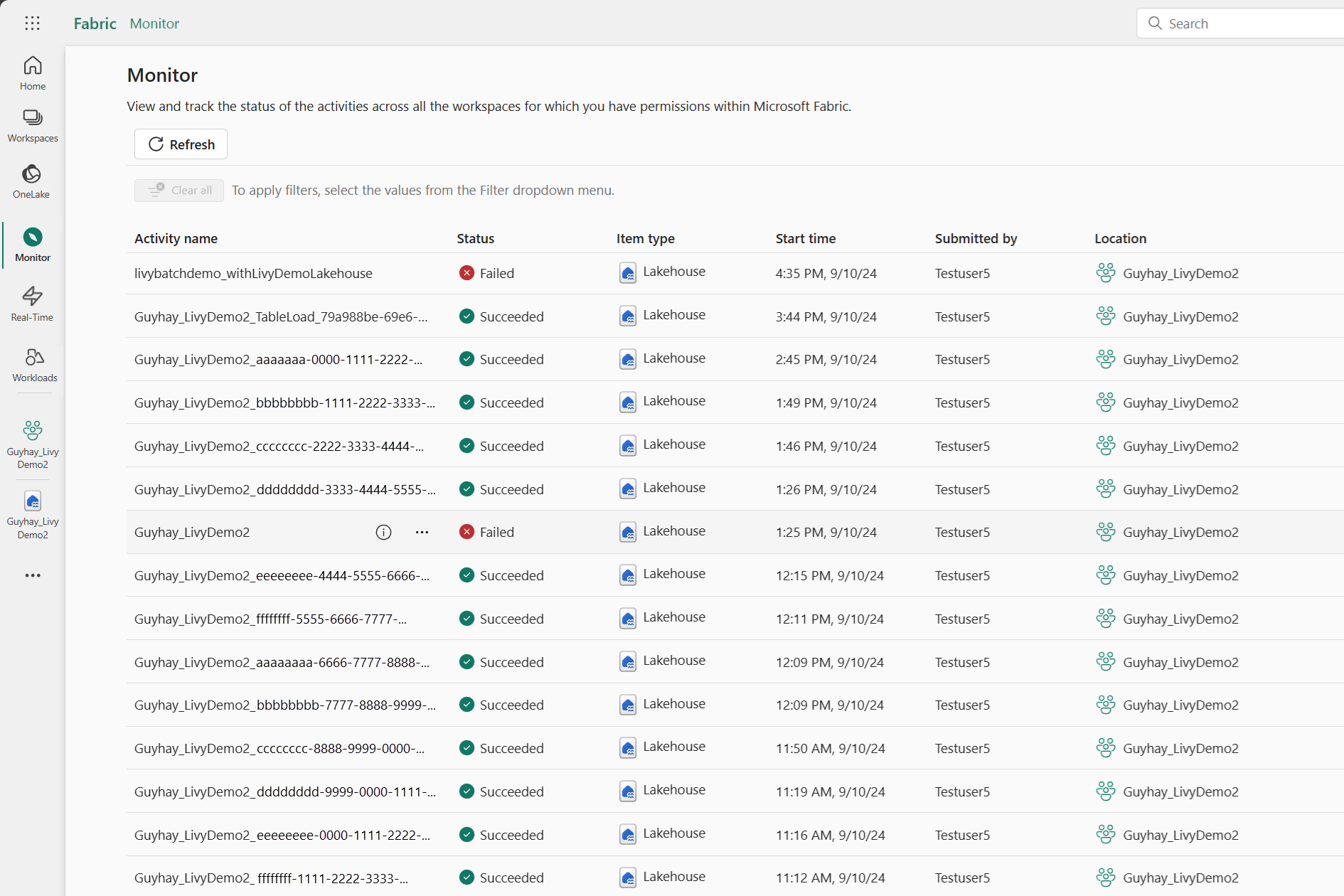
Sélectionnez et ouvrez le nom de l’activité la plus récente.
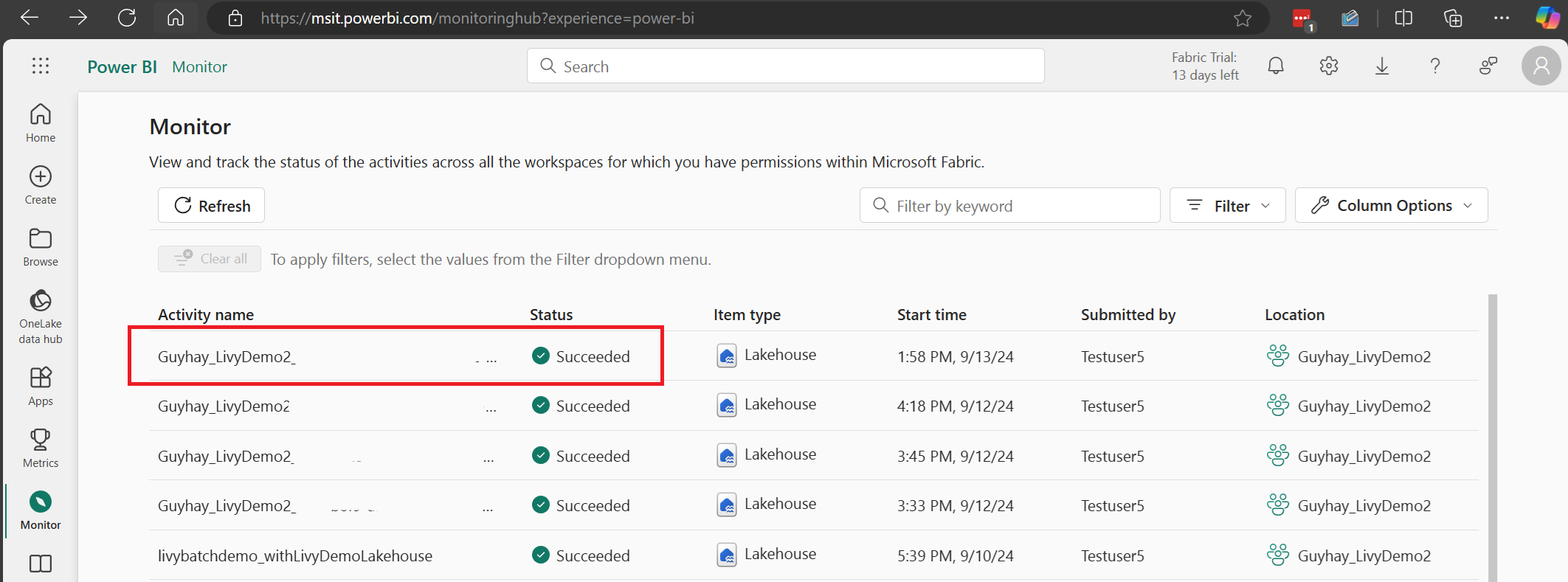
Dans ce cas de session d’API Livy, vous pouvez voir votre envoi de lot précédent, les détails d’exécution, les versions Spark et la configuration. Notez l’état Arrêté en haut à droite.
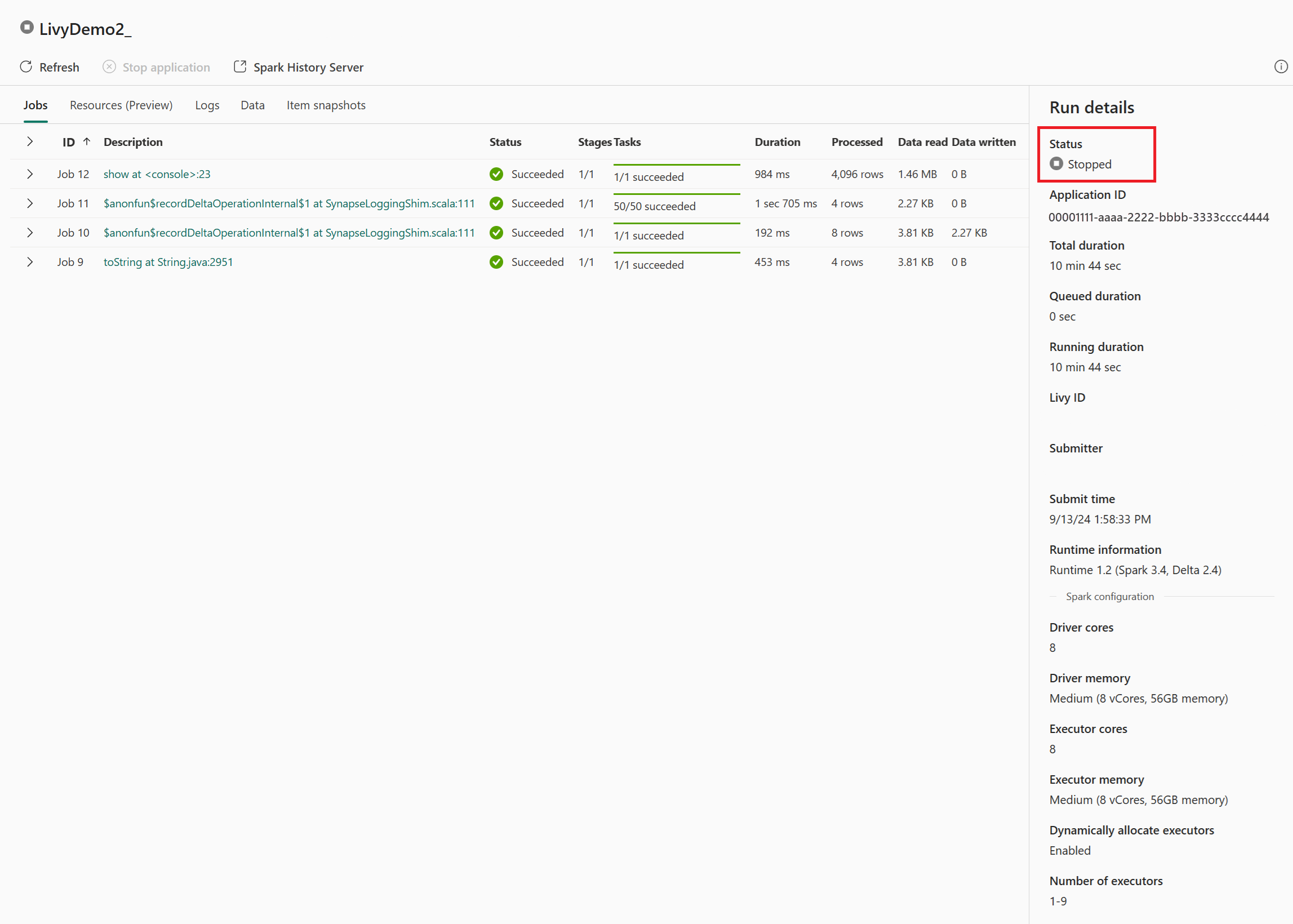



Pour récapituler l’ensemble du processus, vous avez besoin d’un client distant tel que Visual Studio Code, d’un jeton d’application Microsoft Entra, de l’URL du point de terminaison de l’API Livy, de l’authentification à votre Lakehouse, d’une charge utile Spark dans votre Lakehouse et enfin d’une session d’API Livy par lots.