Utilisez un notebook pour charger des données dans votre lakehouse
Dans ce tutoriel, découvrez comment lire/écrire des données dans votre lakehouse Fabric avec un notebook. Fabric prend en charge l’API Spark et l’API Pandas pour atteindre cet objectif.
Charger des données avec une API Apache Spark
Dans la cellule de code du bloc-notes, utilisez l'exemple de code suivant pour lire les données de la source et les charger dans Fichiers, Tables ou les deux sections de votre Lakehouse.
Pour spécifier l’emplacement à partir duquel lire, vous pouvez utiliser le chemin d’accès relatif si les données proviennent du lakehouse par défaut de votre notebook actuel. Ou, si les données proviennent d’un autre lakehouse, vous pouvez utiliser le chemin d’accès absolu de l’Azure Blob File System (ABFS). Copiez ce chemin d’accès depuis le menu contextuel des données.
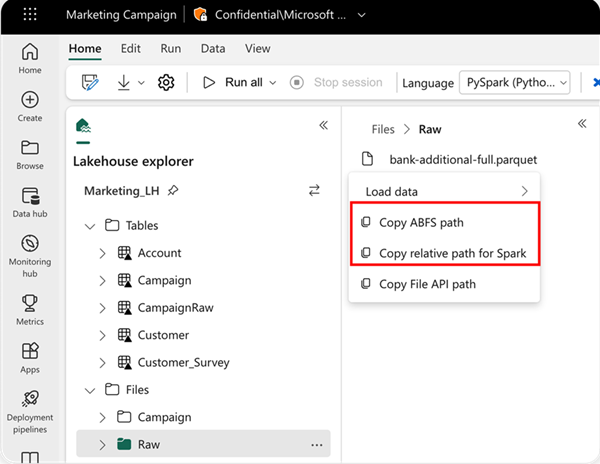
Copier le chemin d’accès ABFS : cette option renvoie le chemin d’accès absolu du fichier.
Copier le chemin d’accès relatif pour Spark : cette option renvoie le chemin d’accès relatif du fichier dans le lakehouse par défaut.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Charger des données avec une API Pandas
Pour prendre en charge l’API Pandas, le lakehouse par défaut sera automatiquement monté sur le notebook. Le point de montage est '/lakehouse/default/'. Vous pouvez utiliser ce point de montage pour lire/écrire des données depuis/vers le Lakehouse par défaut. L’option « Copier le chemin d’accès de l’API de fichier » du menu contextuel renverra le chemin d’accès de l’API de fichier à partir de ce point de montage. Le chemin renvoyé par l'option Copier le chemin ABFS fonctionne également pour l'API Pandas.
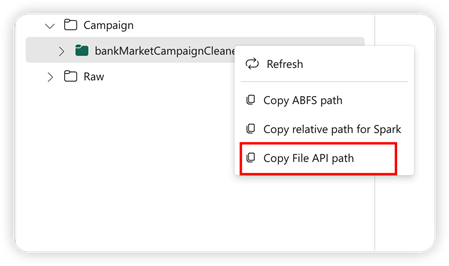
Copier le chemin d’accès de l’API de fichier : cette option renvoie le chemin d’accès sous le point de montage du lakehouse par défaut.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Conseil
Pour l'API Spark, veuillez utiliser l'option Copier le chemin ABFS ou Copier le chemin relatif pour Spark pour obtenir le chemin du fichier. Pour l'API Pandas, veuillez utiliser l'option Copier le chemin ABFS ou Copier le chemin de l'API de fichier pour obtenir le chemin du fichier.
Le moyen le plus rapide de faire fonctionner le code avec l'API Spark ou l'API Pandas est d'utiliser l'option Charger les données et de sélectionner l'API que vous souhaitez utiliser. Le code sera automatiquement généré dans une nouvelle cellule de code du notebook.

Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour