Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous utilisez des notebooks avec le runtime Spark pour transformer et préparer les données brutes au sein de votre lakehouse.
Prérequis
Avant de commencer, vous devez suivre les didacticiels précédents de cette série :
- Créer un lakehouse
- Ingérer des données dans un entrepôt de données
- Vérifiez que les schémas lakehouse sont activés dans votre lakehouse .
Préparer les données
Dans les étapes précédentes du didacticiel, vous avez ingéré des données brutes de la source vers la section Fichiers de la lakehouse. Vous pouvez maintenant transformer ces données et les préparer pour la création de tables Delta.
Téléchargez les notebooks à partir du dossier Code source du didacticiel Lakehouse.
Dans votre navigateur, accédez à votre espace de travail Fabric dans le portail Fabric.
Sélectionnez Importer>un bloc-notes>à partir de cet ordinateur.
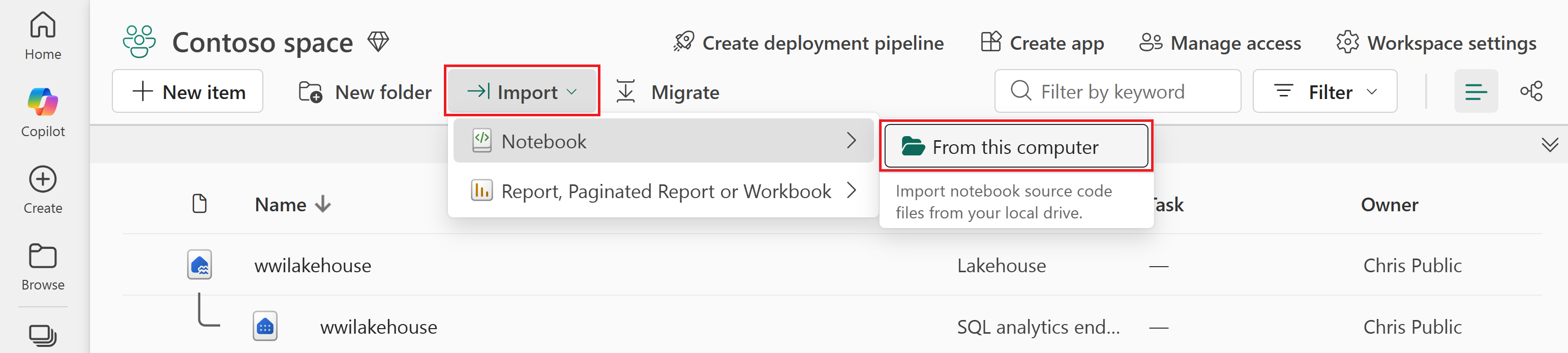
Sélectionnez Charger dans le volet Importer l’état qui s’ouvre sur le côté droit de l’écran.
Sélectionnez uniquement le bloc-notes qui correspond à votre langage de codage préféré.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Sélectionnez Ouvrir. Une notification indiquant l’état de l’importation s’affiche dans le coin supérieur droit de la fenêtre du navigateur.
Une fois l’importation réussie, accédez à l’affichage éléments de l’espace de travail pour vérifier le bloc-notes importé.
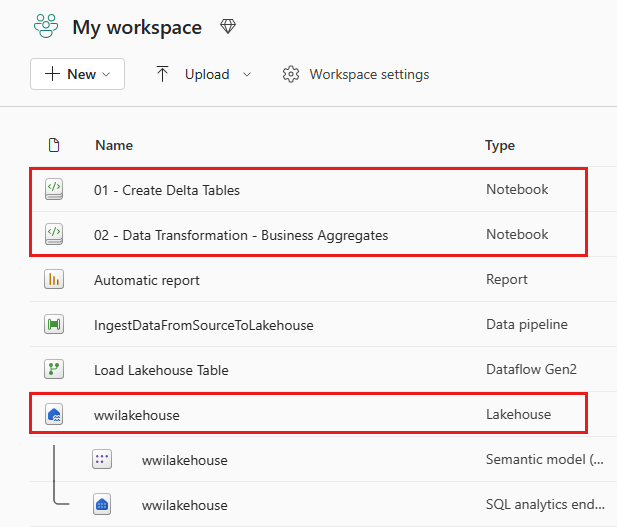
Sélectionnez le lac de wwilakehouse pour l’ouvrir, afin que le bloc-notes que vous ouvrez ensuite soit lié à celui-ci.
Dans le menu de navigation supérieur, sélectionnez Ouvrir le bloc-notes>existant.
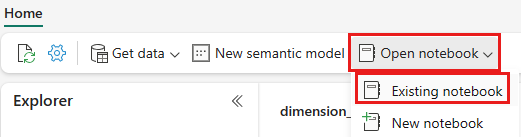
Sélectionnez votre notebook importé pour PySpark ou Spark SQL, puis sélectionnez Ouvrir. Le bloc-notes est déjà lié à votre lakehouse ouvert, comme indiqué dans l’Explorateur lakehouse.



Vous êtes maintenant prêt à exécuter les cellules du notebook qui créent et transforment vos tables Delta.
Dans les sections suivantes, exécutez les cellules du bloc-notes de manière séquentielle. Pour exécuter une cellule, sélectionnez l’icône Exécuter qui apparaît à gauche de la cellule au pointage. Vous pouvez également sélectionner Exécuter tout dans le ruban supérieur (Accueil) pour exécuter toutes les cellules en séquence.
Important
Ce didacticiel nécessite que les schémas lakehouse soient activés. Si les schémas ne sont pas activés, le code de ce didacticiel ne fonctionnera pas comme prévu.
Dans le bloc-notes importé, vous voyez les sections Path 1 et Path 2 . Pour ce tutoriel, utilisez path 1 (schémas lakehouse activés) et ignorez path 2 (schémas lakehouse non activés).
Créer des tables delta
Dans cette section, vous exécutez les cellules du notebook pour créer des tables Delta à partir des données brutes.
Les tableaux suivent un schéma en étoile, qui est un modèle courant pour organiser les données analytiques :
- Une table de faits (
fact_sale) contient les événements mesurables de l’entreprise , dans ce cas, les transactions de ventes individuelles avec des quantités, des prix et des bénéfices. -
Les tables de dimension (
dimension_city, ,dimension_customer,dimension_datedimension_employee,dimension_stock_item) contiennent les attributs descriptifs qui donnent un contexte aux faits, tels que l’endroit où une vente s’est produite, qui l’a fait et quand.
Dans cette page de tutoriel, sélectionnez l’onglet correspondant au bloc-notes que vous avez importé et continuez à utiliser ce même onglet pour toutes les étapes. Les onglets se trouvent dans cet article, et non dans le bloc-notes.
Cellule 1 - Configuration de session Spark. Cette cellule active deux fonctionnalités Fabric qui optimisent l’écriture et la lecture des données dans les cellules suivantes. V-order optimise la disposition du fichier Parquet pour une lecture plus rapide et une meilleure compression. Optimiser l’écriture réduit le nombre de fichiers écrits et augmente la taille de fichier individuelle.
Exécutez cette cellule et attendez qu’elle se termine avant de passer à l’étape suivante.
Cellule 2 - Fait - Vente. Cette cellule lit les données parquet brutes à partir de
Files/wwi-raw-data/full/fact_sale_1y_full, ajoute des colonnes pour les parties de la date (Année, Trimestre et Mois) et écritfact_saleen tant que table Delta partitionnée par Année et Trimestre.Exécutez cette cellule et attendez qu’elle se termine avant de passer à l’étape suivante.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Cellule 3 - Dimensions. Cette cellule lit les jeux de données Parquet à cinq dimensions et les écrit sous forme de tables Delta (
dimension_city,dimension_customer,dimension_date,dimension_employee, etdimension_stock_item) dansTables/dbo/....Exécutez cette cellule et attendez qu’elle se termine avant de passer à l’étape suivante.
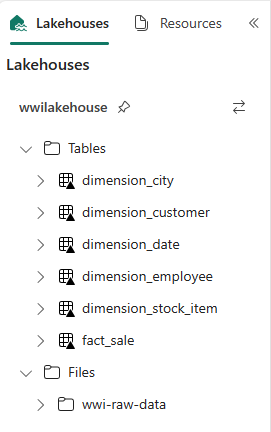
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Pour valider les tables créées, faites un clic droit sur le lakehouse wwilakehouse dans l’explorateur, puis sélectionnez Actualiser. Les tables s’affichent.

Transformer des données pour les agrégats métier
Dans cette section, vous continuez dans le même notebook et exécutez les cellules suivantes pour créer des tables d’agrégation à partir des tables Delta que vous avez créées dans la section précédente.
Vérifiez que le bloc-notes est toujours lié à wwilakehouse.
Cellule 4 - Charger des tables sources pour la transformation (PySpark uniquement). Si vous utilisez le notebook PySpark, exécutez cette cellule pour charger des tables Delta dans des DataFrames pour les étapes d’agrégation qui suivent.
Exécutez cette cellule et attendez qu’elle se termine avant de passer à l’étape suivante.
Cellule 5 - Créer
aggregate_sale_by_date_city. Cette cellule joint les données de ventes, de date et de ville, puis crée la table d’agrégation au niveau de la ville.Exécutez cette cellule et attendez qu’elle se termine avant de passer à l’étape suivante.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Cellule 6 - Créer
aggregate_sale_by_date_employee. Cette cellule joint les données des ventes, des dates et des employés, puis crée la table d’agrégation au niveau de l’employé.Exécutez cette cellule et attendez qu’elle se termine avant de passer à l’étape suivante.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Pour valider les tables créées, faites un clic droit sur le lakehouse wwilakehouse dans l’explorateur, puis sélectionnez Actualiser. Les tables d’agrégation s’affichent.

Ce tutoriel écrit des données sous forme de fichiers Delta Lake. Fabric découvre et inscrit automatiquement ces tables dans le metastore. Vous n’avez donc pas besoin d’exécuter des instructions distinctes CREATE TABLE .