Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment fonctionnent les pipelines d’intégration et de déploiement Git pour les fonctions de données utilisateur dans Microsoft Fabric. Avec l’intégration de Git, vous pouvez synchroniser votre espace de travail Fabric avec une branche de référentiel, ce qui vous permet de contrôler les versions de vos fonctions de données utilisateur, de collaborer à l’aide de branches et de demandes de tirage(pull) et d’utiliser votre code dans vos outils Git préférés, tels qu’Azure DevOps.
Apprenez-en plus sur le processus d’intégration de Git à votre espace de travail Microsoft Fabric dans Concepts de base de l’intégration Git.
Configurer une connexion
Avec les paramètres de votre espace de travail, vous pouvez facilement configurer une connexion à votre dépôt pour commiter et synchroniser les modifications. Pour configurer la connexion, consultez Démarrer avec l’intégration de Git. Une fois connecté, vos éléments, y compris les fonctions de données utilisateur, apparaissent dans le volet de Contrôle de la source.

Une fois que vous avez validé avec succès les éléments de fonctions de données utilisateur dans le référentiel Git, vous voyez les dossiers de fonctions de données utilisateur dans le référentiel. Vous pouvez désormais exécuter des opérations futures, comme créer une requête d'extraction.
Représentation des fonctions de données utilisateur dans Git
L’image suivante montre un exemple de structure de fichiers de chaque élément de fonctions de données utilisateur dans le référentiel.

La structure du dossier comprend les éléments suivants :
.platform : Le fichier
.platformcontient les attributs suivants :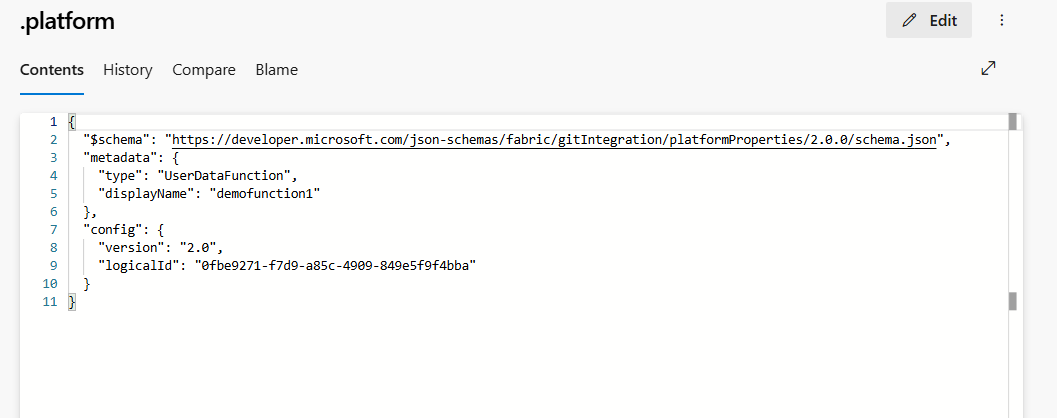
- version : Numéro de version des fichiers système. Ce numéro est utilisé pour activer la rétrocompatibilité. Le numéro de version de l'élément peut être différent.
- logicalId : Un identifiant inter-espaces de travail généré automatiquement représentant un élément et sa représentation de contrôle de source.
-
type :
UserDataFunctionest le type permettant de définir un élément de fonctions de données utilisateur. - displayName : Représente le nom de l'élément. Lorsque l'élément de fonctions de données utilisateur est renommé, ce displayName est mis à jour.
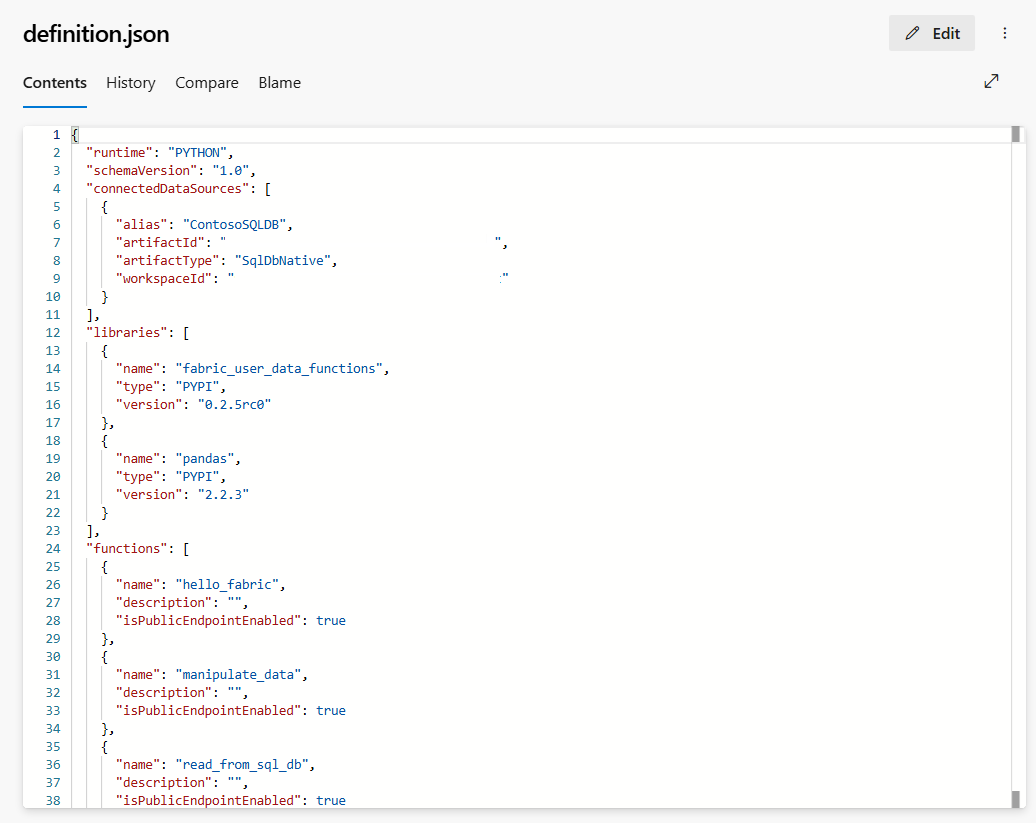
definitions.json : Ce fichier partage toutes les définitions d'éléments de fonctions de données utilisateur telles que les connexions, les bibliothèques, etc. en tant que représentation des propriétés d'éléments de fonctions de données utilisateur.
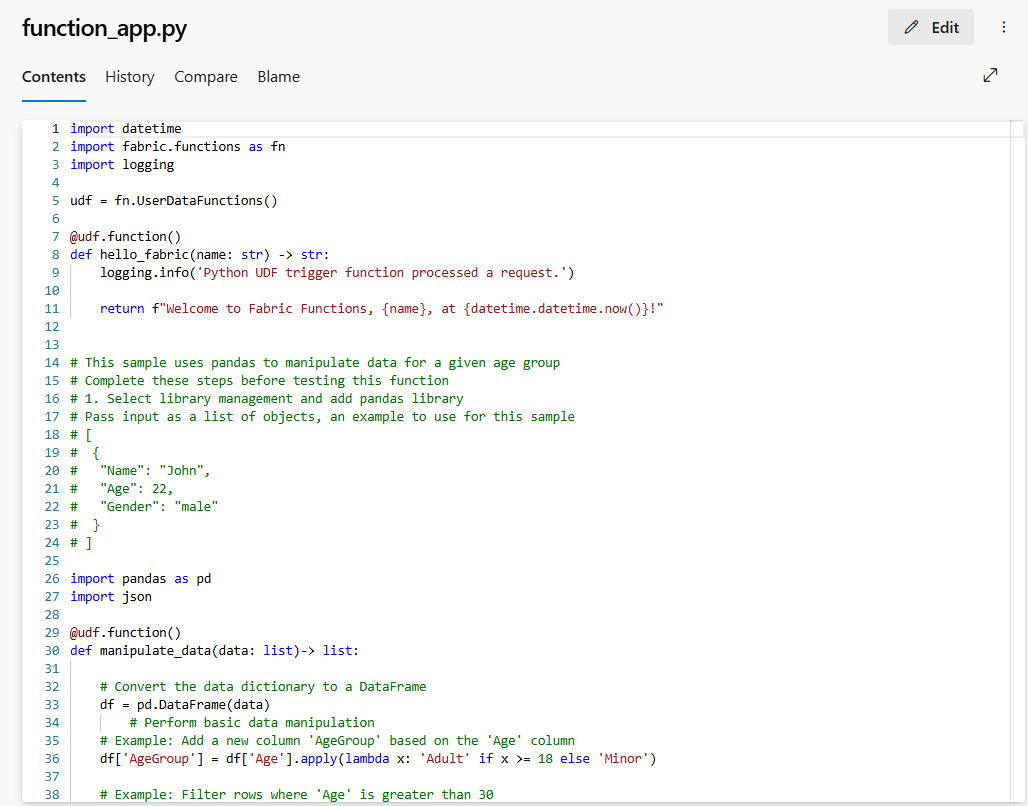
function-app.py : Ce fichier est votre code de fonctions. Toutes les modifications de code que vous apportez à l’élément de fonctions de données utilisateur sont synchronisées dans le référentiel avec ce fichier. Vous pouvez effectuer diverses opérations Git pour gérer le cycle de développement du code.
ressources : Le dossier contient un fichier functions.json avec toutes les métadonnées telles que les connexions, les bibliothèques et les fonctions de cet élément. NE PAS METTRE À JOUR CE FICHIER manuellement.
functions.jsonpermet à Fabric de créer ou de recréer l'élément de fonctions de données utilisateur dans un espace de travail.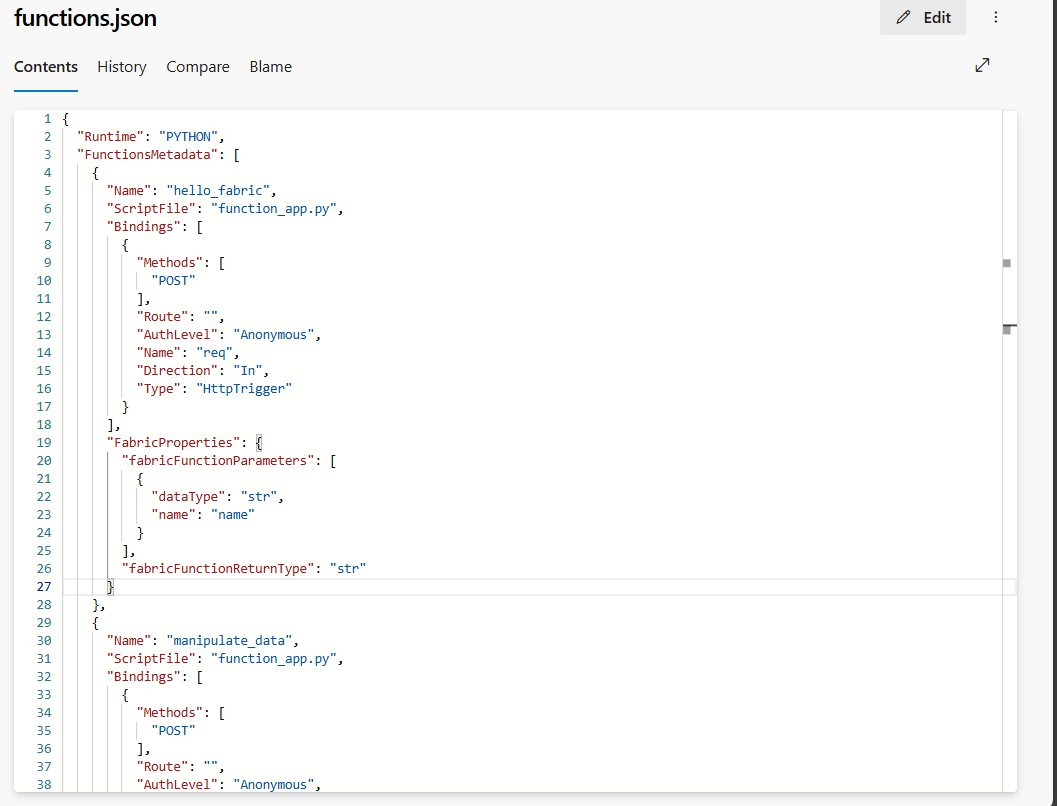




Pour plus d’informations sur l’intégration git, y compris des détails sur la structure des dossiers et les fichiers système, consultez le format de code source de l’intégration Git.
Fonctions de données utilisateur dans les pipelines de déploiement
Vous pouvez utiliser des pipelines de déploiement pour déployer vos fonctions de données utilisateur dans différents environnements, tels que le développement, le test et la production. Les pipelines de déploiement vous aident à simplifier votre processus de développement, à garantir la qualité et la cohérence, et à réduire les erreurs manuelles avec des opérations légères et à faible code.
Remarque
Toutes les connexions et bibliothèques sont ajoutées aux nouveaux éléments de fonctions de données utilisateur créés dans d'autres environnements.
Pour déployer vos fonctions de données utilisateur à l’aide d’un pipeline de déploiement :
Créez un pipeline de déploiement ou ouvrez un pipeline de déploiement existant. Consultez Prise en main des pipelines de déploiement pour plus d’informations.
Affectez des espaces de travail à différentes phases en fonction de vos objectifs de déploiement.
Sélectionnez, affichez et comparez des éléments, y compris des éléments de fonctions de données utilisateur entre différentes étapes.
Sélectionnez Déployer pour déployer votre élément de fonctions de données utilisateur dans votre environnement de test. Vous pouvez ajouter une note pour fournir des détails sur les modifications apportées à ce déploiement. De même, vous pouvez appliquer des modifications aux étapes de développement, de test et de production.
Surveillez l’état du déploiement dans l’Historique de déploiement.