Démarrage rapide : Déplacer et transformer des données avec des dataflows et des pipelines de données
Dans ce tutoriel, vous allez découvrir comment l’expérience de flux de données et de pipeline de données peut créer une solution Data Factory puissante et complète.
Conditions préalables
Pour commencer, vous devez disposer des conditions préalables suivantes :
- Un compte de locataire avec un abonnement actif. Créez un compte gratuit .
- Vérifiez que vous disposez d’un espace de travail Microsoft Fabric activé : Créez un espace de travail qui n'est pas l'espace de travail par défaut Mon espace de travail.
- Une base de données Azure SQL avec des données de table.
- Compte Stockage Blob.
Dataflows comparés aux pipelines
Dataflows Gen2 vous permet d'utiliser une interface sans code et plus de 300 transformations basées sur l'IA pour nettoyer, préparer et transformer facilement les données avec plus de flexibilité que n'importe quel autre outil. Les pipelines de données permettent d’obtenir des fonctionnalités d’orchestration de données prêtes à l’emploi pour composer des flux de travail de données flexibles répondant aux besoins de votre entreprise. Dans un pipeline, vous pouvez créer des regroupements logiques d’activités qui effectuent une tâche, ce qui peut inclure l’appel d’un dataflow pour nettoyer et préparer vos données. Bien que certaines fonctionnalités se chevauchent entre les deux, le choix d'utiliser l'un ou l'autre dans une situation spécifique dépend de la nécessité de bénéficier de la pleine richesse des pipelines ou de pouvoir se contenter des capacités plus simples mais plus limitées des flux de données. Pour plus d’informations, consultez le guide de décision sur le tissu
Transformer des données avec des dataflows
Suivez ces étapes pour configurer votre dataflow.
Étape 1 : Créer un dataflow
Choisissez votre espace de travail activé par Fabric, puis sélectionnez Nouveau. Sélectionnez ensuite Dataflow Gen2.
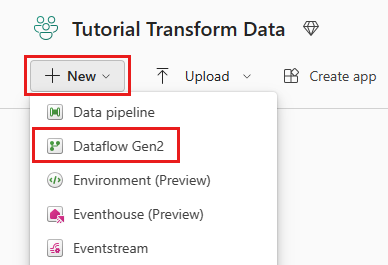
La fenêtre de l’éditeur de flux de données s’affiche. Sélectionnez la carte Importer à partir de SQL Server.
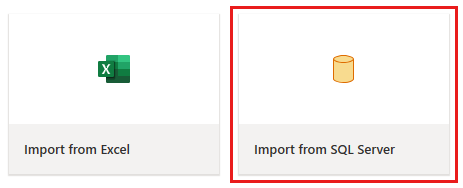


Étape 2 : Obtenir des données
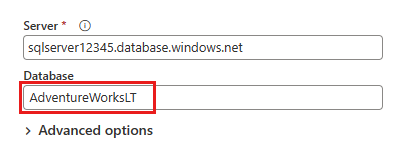
Dans la boîte de dialogue Se connecter à la source de données présentée ensuite, entrez les détails pour vous connecter à votre base de données Azure SQL, puis sélectionnez Suivant. Pour cet exemple, vous utilisez l’exemple de base de données AdventureWorksLT configuré lorsque vous configurez la base de données Azure SQL dans les conditions préalables.
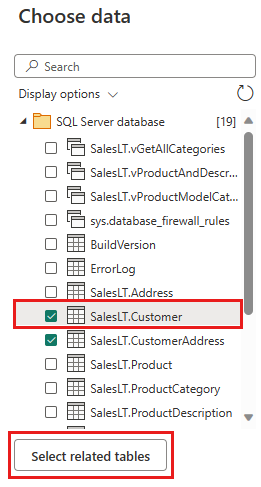
Sélectionnez les données que vous souhaitez transformer, puis sélectionnez Créer. Pour ce démarrage rapide, sélectionnez SalesLT.Customer dans les exemples de données AdventureWorksLT fournis pour Azure SQL base de données, puis le bouton Sélectionner des tables associées pour inclure automatiquement deux autres tables associées.


Étape 3 : Transformer vos données
S’il n’est pas sélectionné, sélectionnez le bouton Vue Diagramme dans la barre d’état en bas de la page, ou sélectionnez Vue Diagramme sous le menu Affichage en haut de l’éditeur Power Query. L’une ou l’autre de ces options peut activer la vue de diagramme.
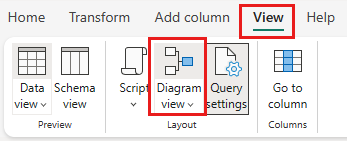
Cliquez avec le bouton droit sur votre requête SalesLT Customer, ou sélectionnez les points de suspension verticaux à droite de la requête, puis sélectionnez Fusionner les requêtes.
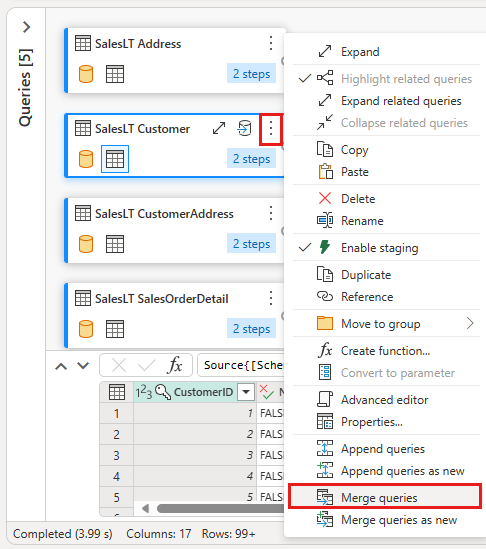
Configurez la fusion en sélectionnant la table SalesLTOrderHeader comme table appropriée pour la fusion, la colonne CustomerID de chaque table comme colonne de jointure et externe gauche comme type de jointure. Sélectionnez ensuite OK pour ajouter la requête de fusion.
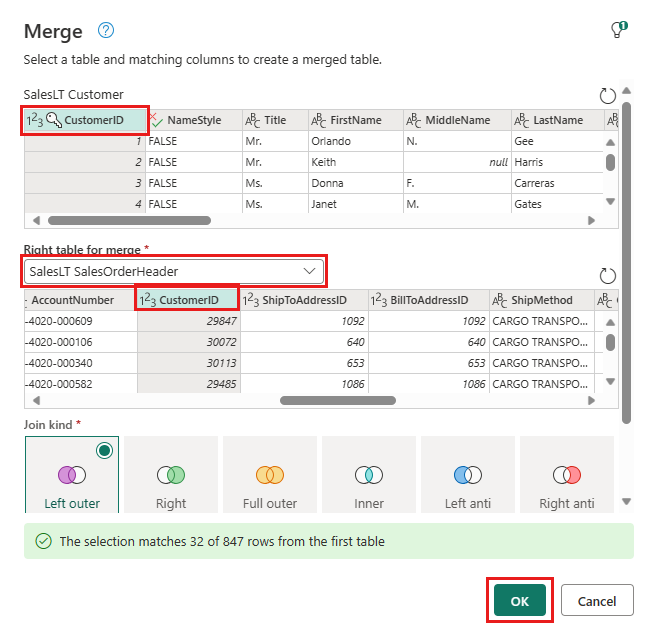
Sélectionnez le bouton Ajouter une destination de données, qui ressemble à un symbole de base de données avec une flèche au-dessus de celle-ci, à partir de la nouvelle requête de fusion que vous avez créée. Sélectionnez ensuite base de données Azure SQL comme type de destination.
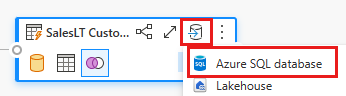
Fournissez les détails de votre connexion de base de données Azure SQL où la requête de fusion doit être publiée. Dans cet exemple, vous pouvez également utiliser la base de données AdventureWorksLT que nous avons utilisée comme source de données pour la destination.
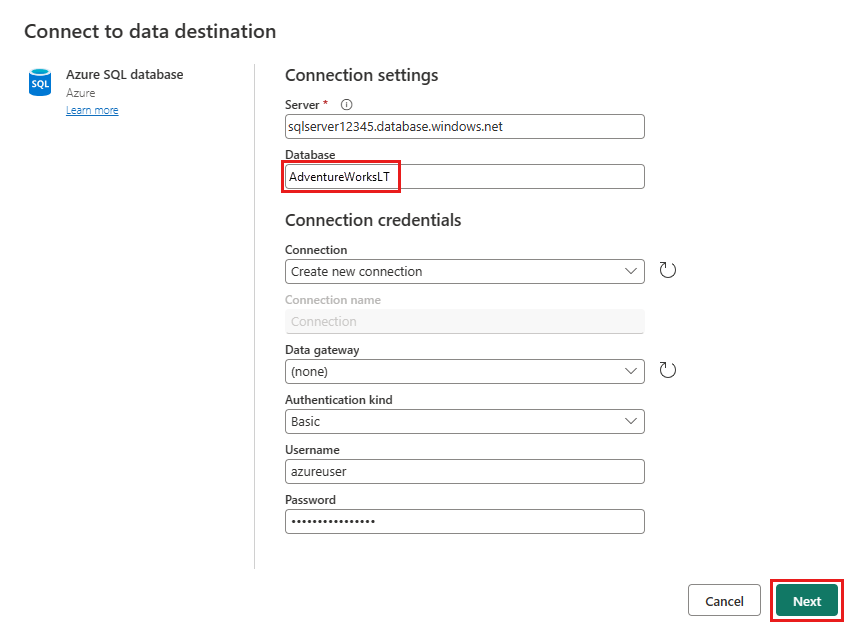
Choisissez une base de données pour stocker les données, puis fournissez un nom de table, puis sélectionnez suivant .
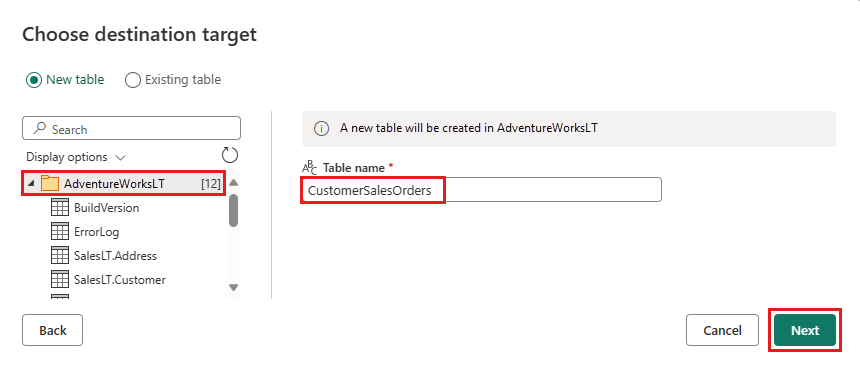
Vous pouvez conserver les paramètres par défaut dans la boîte de dialogue Choisir les paramètres de destination, puis sélectionner Enregistrer les paramètres sans apporter de modifications ici.
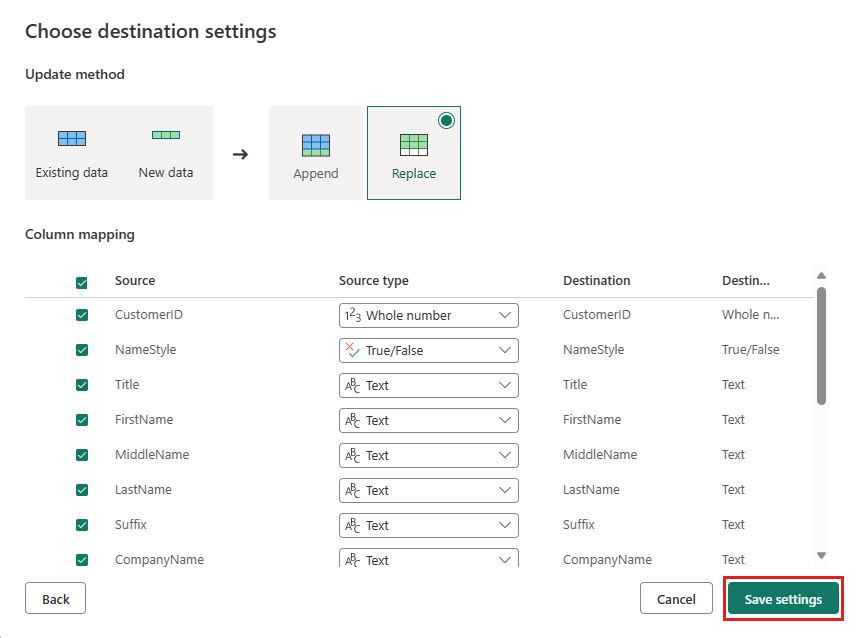
Sélectionnez Publier de nouveau sur la page de l’éditeur de flux de données pour publier le flux de données.



Déplacer des données avec des pipelines de données
Maintenant que vous avez créé un Dataflow Gen2, vous pouvez l’utiliser dans un pipeline. Dans cet exemple, vous copiez les données générées à partir du flux de données dans le format texte dans un compte stockage Blob Azure.
Étape 1 : Créer un pipeline de données
Dans votre espace de travail, sélectionnez Nouveau, puis Pipeline de données.
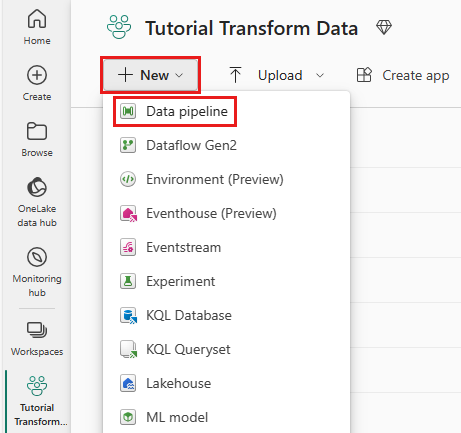
Nommez votre pipeline, puis sélectionnez Créer.
Étape 2 : Configurer votre dataflow
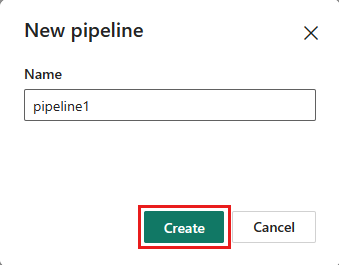
Ajoutez une nouvelle activité de flux de données à votre pipeline de données en sélectionnant dataflow sous l’onglet Activités .

Sélectionnez le flux de données sur le canevas du pipeline, puis l’onglet Paramètres de . Choisissez le flux de données que vous avez créé précédemment dans la liste déroulante.
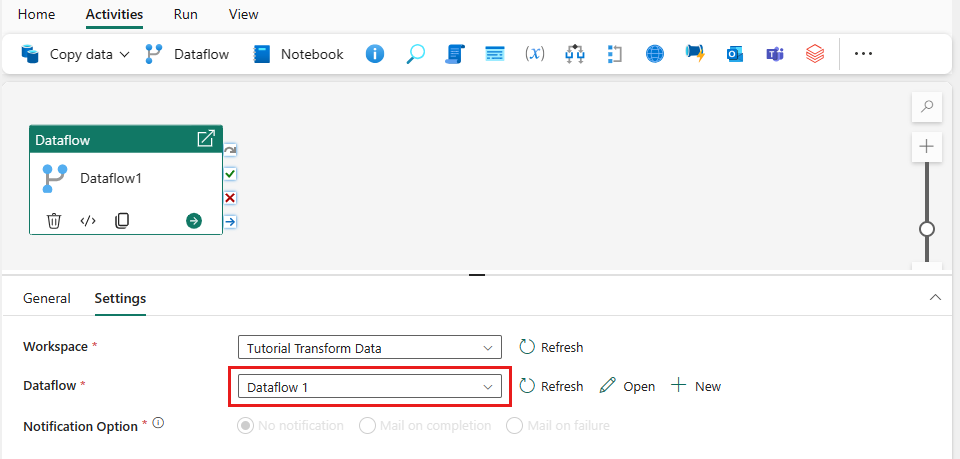
Sélectionnez Enregistrer, puis Exécuter pour exécuter le flux de données pour remplir initialement sa table de requêtes fusionnée que vous avez conçue à l’étape précédente.

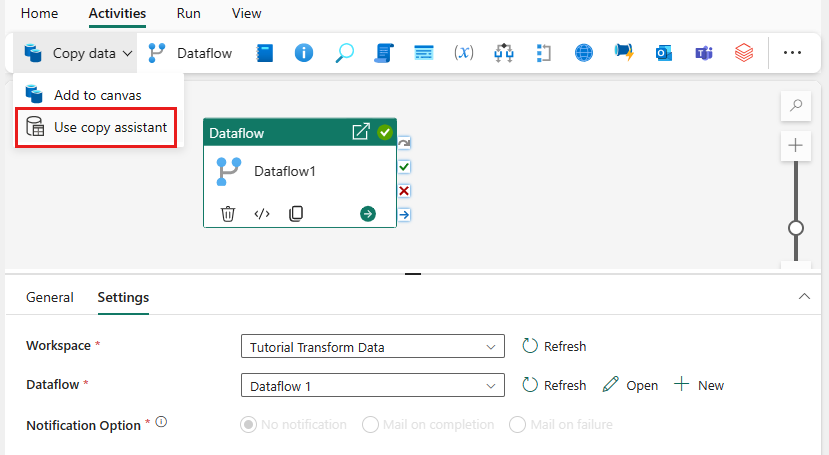
Étape 3 : Utiliser l’Assistant Copie pour ajouter une activité de copie
Sélectionnez Copier les données sur le canevas et ouvrez l’outil Assistant de copie pour commencer. Vous pouvez également sélectionner Utiliser l’assistant de copie dans la liste déroulante Copier les données sous l’onglet Activités du ruban.
Choisissez votre source de données en sélectionnant un type de source de données. Dans ce tutoriel, vous utilisez Azure SQL Database utilisé précédemment lorsque vous avez créé le flux de données pour générer une nouvelle requête de fusion. Faites défiler vers le bas les exemples d’offres de données et sélectionnez l’onglet Azure, puis Azure SQL Database. Sélectionnez suivant pour continuer.
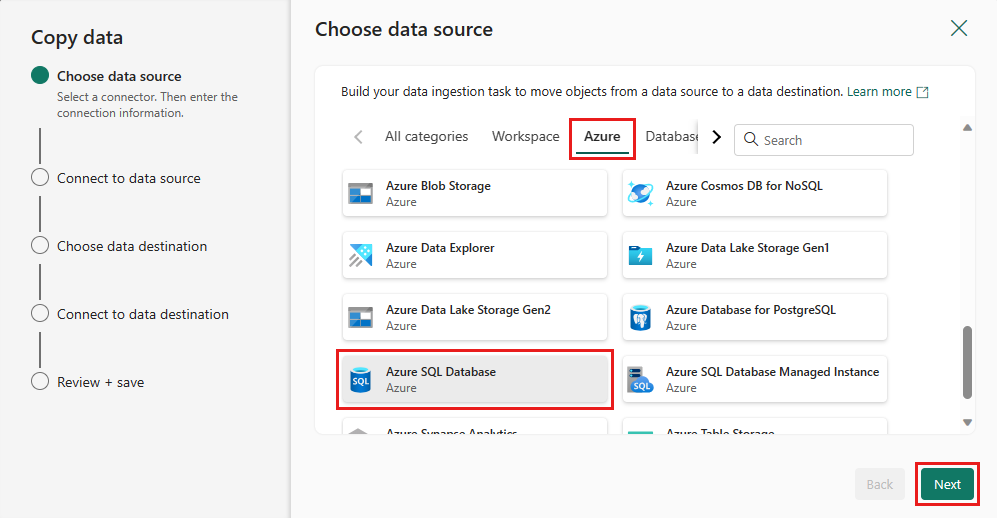
Créez une connexion à votre source de données en sélectionnant Créer une connexion. Renseignez les informations de connexion requises dans le panneau et entrez AdventureWorksLT pour la base de données, où nous avons généré la requête de fusion dans le flux de données. Sélectionnez ensuite suivant.
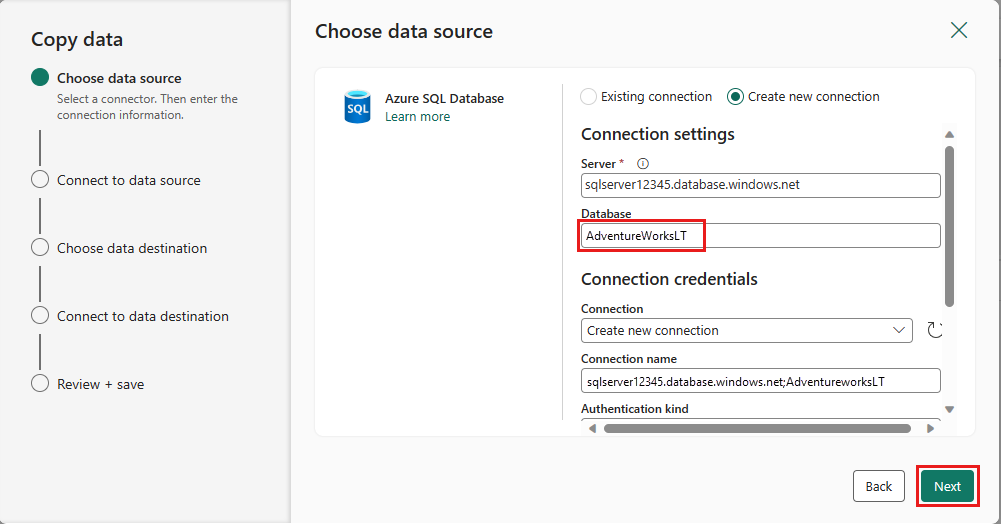
Sélectionnez la table que vous avez générée à l’étape de flux de données précédemment, puis sélectionnez suivant.
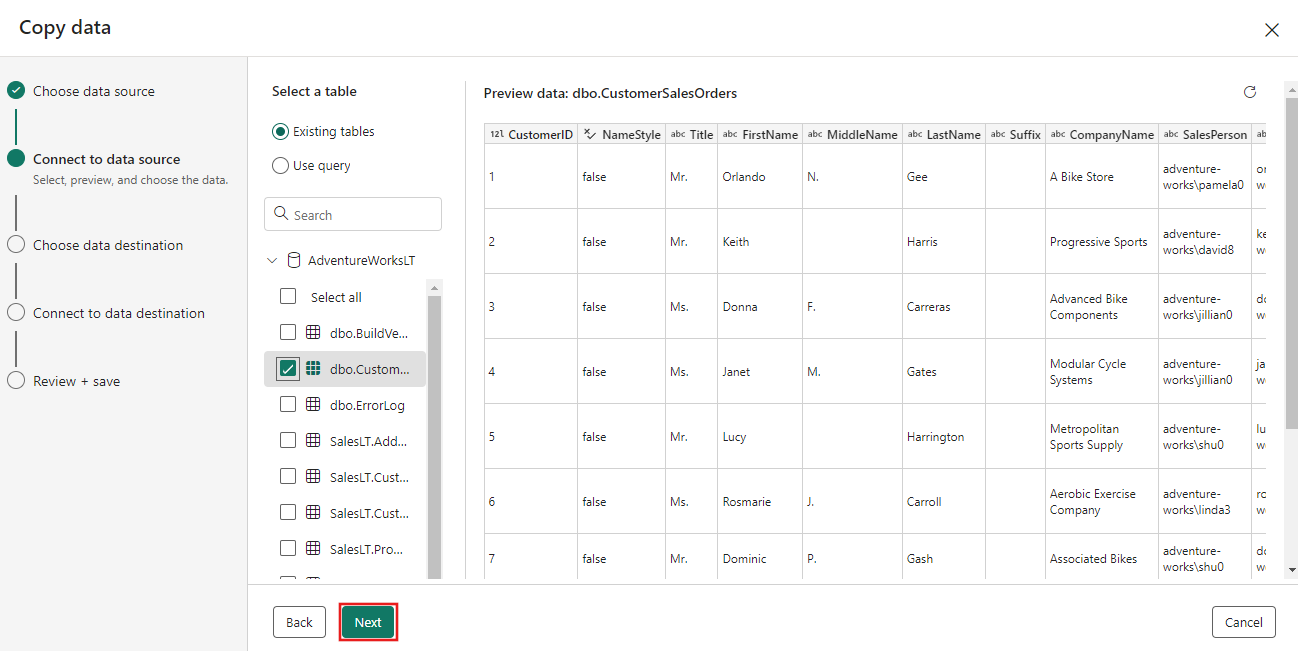
Pour votre destination, choisissez Azure Blob Storage, puis sélectionnez Suivant.
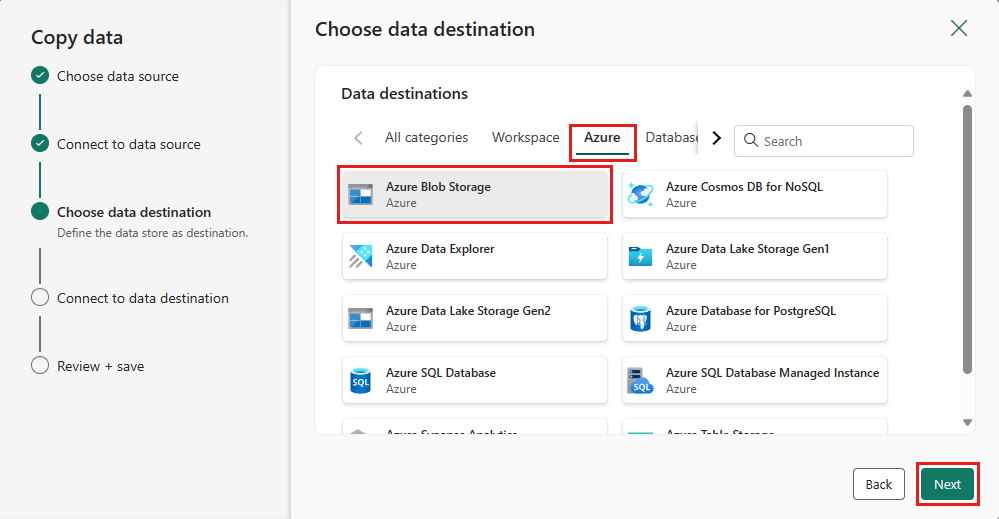
Créez une connexion à votre destination en sélectionnant Créer une connexion. Fournissez les détails de votre connexion, puis sélectionnez suivant .
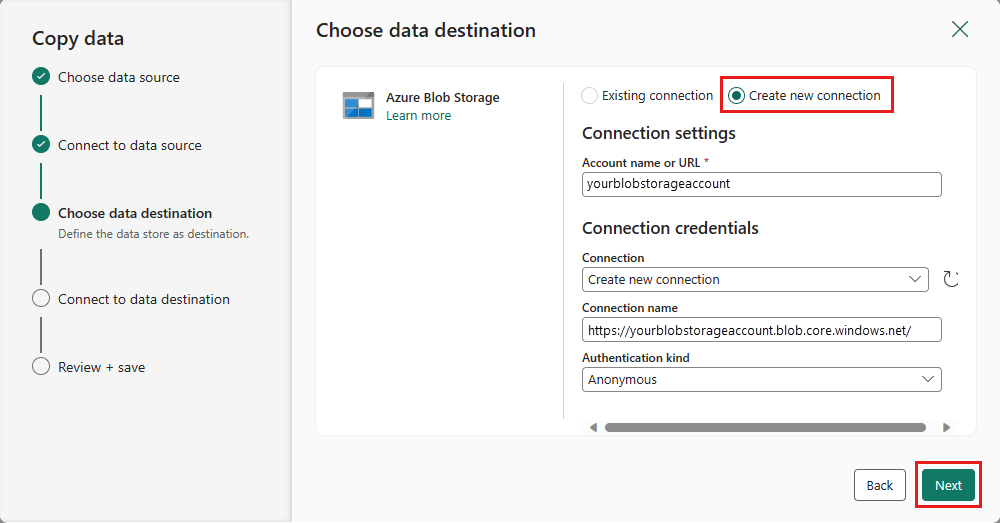
Sélectionnez le chemin d’accès de votre dossier et fournissez un nom de fichier , puis sélectionnez suivant.

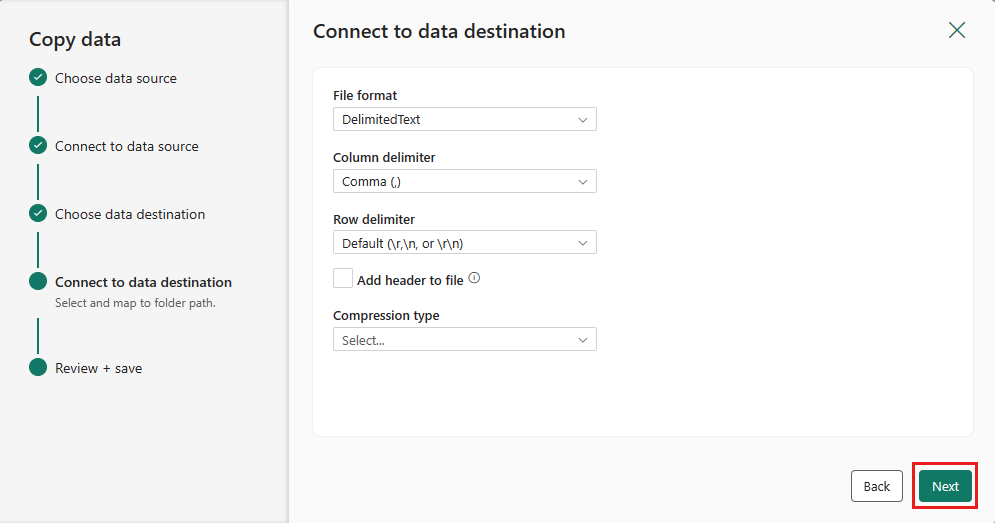
Sélectionnez suivant pour accepter à nouveau le format de fichier par défaut, le délimiteur de colonne, le délimiteur de ligne et le type de compression, y compris éventuellement un en-tête.
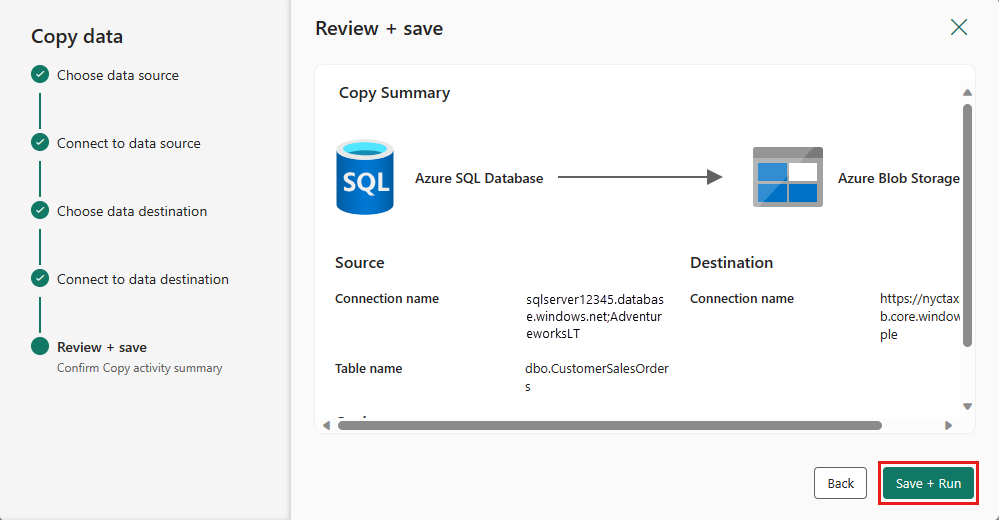
Finalisez vos paramètres. Ensuite, passez en revue et sélectionnez Enregistrer + Exécuter pour terminer le processus.
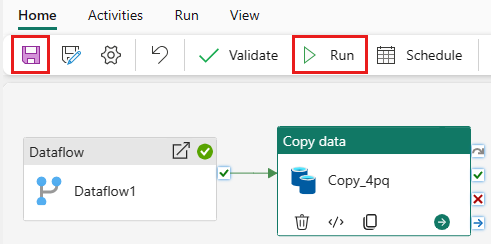
Étape 5 : Concevoir votre pipeline de données et enregistrer pour exécuter et charger des données
Pour exécuter l’activité de copie après l’activité de flux de données, faites glisser l’activité Réussite de l’activité de flux de données vers l’activité de copie. L’activité Copier s’exécute uniquement une fois que l’activité flux de données réussit.

Sélectionnez Enregistrer pour enregistrer votre pipeline de données. Sélectionnez ensuite Exécuter pour exécuter votre pipeline de données et charger vos données.
Planifier l’exécution du pipeline
Une fois que vous avez terminé le développement et le test de votre pipeline, vous pouvez planifier son exécution automatiquement.
Sous l’onglet Accueil de la fenêtre de l’éditeur de pipeline, sélectionnez Planification.
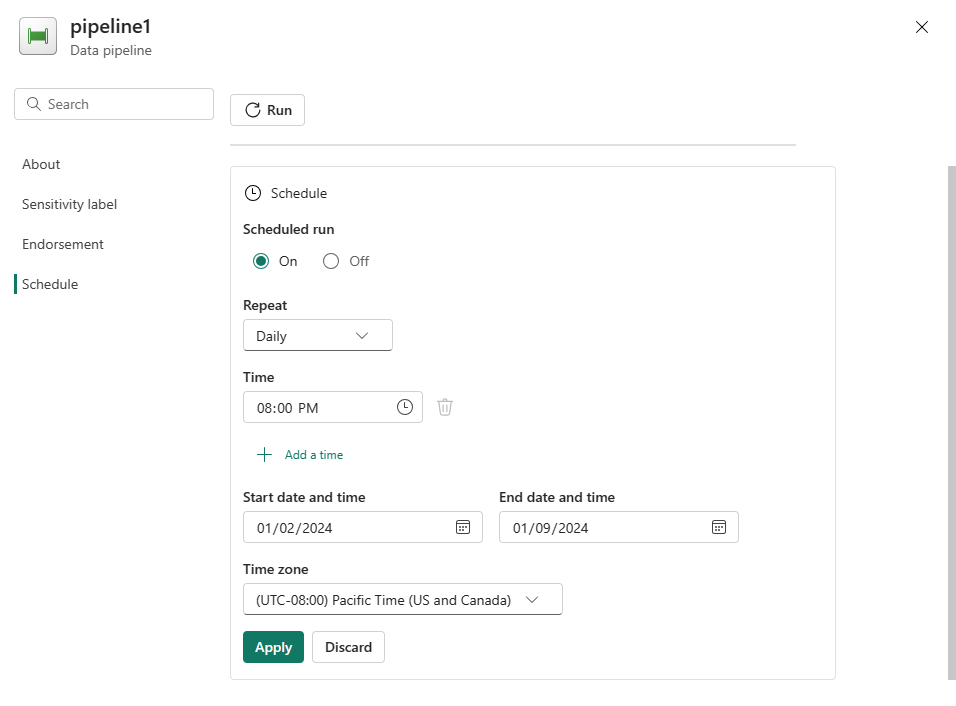
Configurez la planification en fonction des besoins. L’exemple ci-dessous planifie l’exécution quotidienne du pipeline à 18h00 jusqu’à la fin de l’année.
Contenu connexe
Cet exemple vous montre comment créer et configurer un Dataflow Gen2 pour créer une requête de fusion et le stocker dans une base de données Azure SQL, puis copier des données de la base de données dans un fichier texte dans stockage Blob Azure. Vous avez appris à :
- Créez un dataflow.
- Transformez des données avec le dataflow.
- Créez un pipeline de données à l’aide du flux de données.
- Ordonner l’exécution des étapes dans le pipeline.
- Copiez des données avec l’Assistant Copie.
- Exécutez et planifiez votre pipeline de données.
Ensuite, avancez pour en savoir plus sur la supervision des exécutions de votre pipeline.