Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans cet article, vous allez découvrir comment effectuer une analyse exploratoire des données à l’aide d’Azure Open Datasets et d’Apache Spark. Cet article analyse le jeu de données de taxis de New York City. Les données sont disponibles dans Azure Open Datasets. Ce sous-ensemble du jeu de données contient des données sur les courses de taxis jaunes, qui incluent des informations sur chaque course, les heures et lieux de départ et d’arrivée, le prix et d’autres attributs intéressants.
Dans cet article, vous découvrirez comment :
- Télécharger et préparer les données
- Analyser des données
- Visualiser les données
Prérequis
Obtenir un abonnement Microsoft Fabric. Ou, inscrivez-vous pour un essai gratuit de Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Basculez vers Fabric à l’aide du sélecteur d’expérience situé en bas à gauche de votre page d’accueil.

Télécharger et préparer les données
Pour commencer, téléchargez le jeu de données New York City (NYC) Taxi et préparez les données.
Créez un bloc-notes à l’aide de PySpark. Pour obtenir des instructions, consultez Créer un notebook.
Notes
Grâce au noyau PySpark, il est inutile de créer des contextes explicitement. Le contexte Spark est créé automatiquement pour vous lorsque vous exécutez la première cellule de code.
Dans cet article, vous utilisez différentes bibliothèques pour visualiser le jeu de données. Pour effectuer cette analyse, importez les bibliothèques suivantes :
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdComme les données brutes sont au format Parquet, vous pouvez utiliser le contexte Spark pour extraire le fichier en mémoire directement en tant que DataFrame. Utilisez l’API Open Datasets pour récupérer les données et créer un DataFrame Spark. Pour déduire les types de données et le schéma, utilisez les propriétés de schéma lors de la lecture du DataFrame Spark.
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Une fois les données lues, effectuez un premier filtrage pour nettoyer le jeu de données. Vous pouvez supprimer les colonnes inutiles et ajouter des colonnes supplémentaires qui extraient des informations importantes. Vous pouvez également filtrer les anomalies dans le jeu de données.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analyser des données
En tant qu’analyste de données, vous disposez d’un large éventail d’outils pour vous aider à extraire des informations à partir de ces données. Dans cette partie de l’article, vous allez découvrir quelques outils utiles disponibles dans les notebooks Microsoft Fabric. Dans cette analyse, vous souhaitez comprendre les facteurs qui donnent lieu à des pourboires plus élevés pour la période sélectionnée.
Magic SQL Apache Spark
Tout d'abord, effectuez une analyse exploratoire des données à l’aide d’Apache Spark SQL et de commandes magiques avec le notebook Microsoft Fabric. Une fois que vous avez la requête, visualisez les résultats à l’aide de la capacité chart options intégrée.
Dans le notebook, créez une cellule et copiez le code suivant. À l’aide de cette requête, vous pouvez comprendre la façon dont les montants moyens des pourboires changent au cours de la période sélectionnée. Cette requête vous aide également à identifier d’autres insights utiles, notamment le montant minimal/maximal d’un pourboire par jour et le montant moyen des courses.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCUne fois l’exécution de la requête terminée, vous pouvez visualiser les résultats en basculant vers la vue graphique. Dans cet exemple, nous allons créer un graphique en courbes en spécifiant le champ
day_of_monthcomme clé etavgTipAmountcomme valeur. Une fois que vous avez effectué les sélections, sélectionnez Appliquer pour actualiser votre graphique.
Visualiser les données
Outre les options intégrées de création de graphiques du notebook, vous pouvez utiliser des bibliothèques open source populaires pour créer vos propres visualisations. Dans les exemples suivants, utilisez Seaborn et Matplotlib, qui sont des bibliothèques Python couramment utilisées pour la visualisation des données.
Pour faciliter le développement et le rendre moins onéreux, réduisez l’échantillon de jeu de données. Utilisez la capacité intégrée d’échantillonnage Apache Spark. En outre, Seaborn et Matplotlib nécessitent un DataFrame Pandas ou un tableau NumPy. Pour obtenir un DataFrame Pandas, utilisez la commande
toPandas()pour convertir notre DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Vous pouvez comprendre la distribution des pourboires dans le jeu de données. Utilisez Matplotlib pour créer un histogramme montrant la répartition de la quantité et du nombre de pourboires. Sur la base de la distribution, vous pouvez voir que les pourboires sont biaisés autour de montants inférieurs ou égaux à 10 $.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()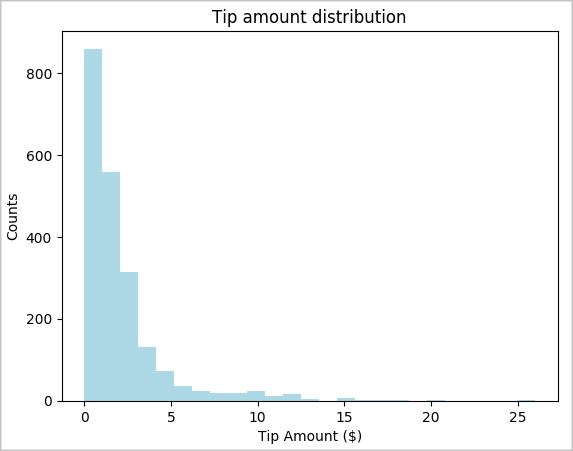
Ensuite, essayez de comprendre la relation entre les pourboires pour un trajet donné et le jour de la semaine. Utilisez Seaborn pour créer un diagramme à surfaces résumant les tendances pour chaque jour de la semaine.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()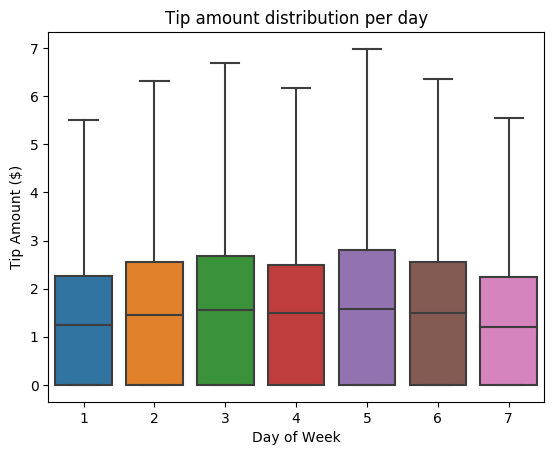
Une autre hypothèse est qu’il existe une relation positive entre le nombre de passagers et le montant total du pourboire des taxis. Pour vérifier cette relation, exécutez le code suivant pour générer un diagramme à surfaces illustrant la répartition des pourboires pour chaque nombre de passagers.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()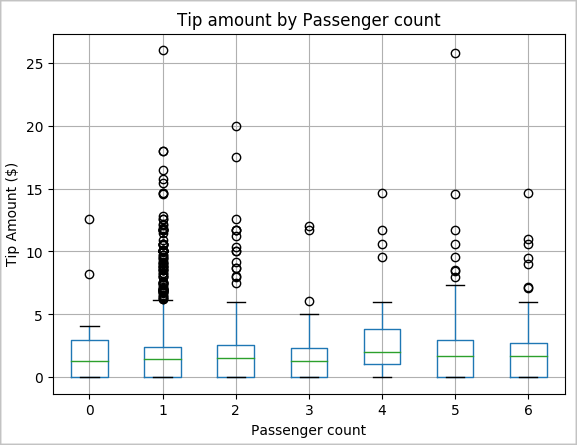
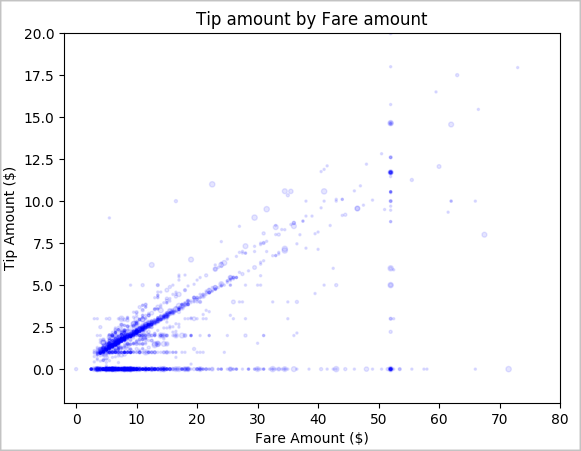
Pour finir, explorez la relation entre le montant de la course et le montant du pourboire. Sur la base des résultats, vous pouvez constater qu’il y a plusieurs observations où les gens ne donnent pas de pourboire. Cependant, il existe une relation positive entre le prix global de la course et le montant du pourboire.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()