Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel présente un exemple de bout en bout d’un flux de travail Synapse Data Science dans Microsoft Fabric. Le scénario crée un modèle pour les recommandations de livres en ligne.
Ce tutoriel décrit les étapes suivantes :
- Charger les données dans un lakehouse
- Effectuer une analyse exploratoire sur les données
- Entraîner un modèle et l’enregistrer avec MLflow
- Charger le modèle et effectuer des prédictions
De nombreux types d’algorithmes de recommandation sont disponibles. Ce tutoriel utilise l’algorithme de factorisation de la matrice Alternating Least Squares (ALS). ALS est un algorithme de filtrage collaboratif basé sur un modèle.

ALS tente d’estimer la matrice de notation R comme le produit de deux matrices de rang inférieur, U et V. Ici, R = U * Vt. En règle générale, ces approximations sont appelées matrices facteur.
L’algorithme ALS est itératif. Chaque itération contient l’une des matrices de facteurs constantes, tandis qu’elle résout l’autre à l’aide de la méthode des moindres carrés. Il fixe ensuite la matrice de facteurs nouvellement résolue comme constante tout en résolvant l'autre matrice de facteurs.

Conditions préalables
Obtenez un abonnement Microsoft Fabric. Vous pouvez également vous inscrire à un essai gratuit Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Basculez vers Fabric à l’aide du sélecteur d’expérience situé en bas à gauche de votre page d’accueil.

- Si nécessaire, créez une Microsoft Fabric lakehouse comme décrit dans Create a lakehouse in Microsoft Fabric.
Suivez avec un bloc-notes
Choisissez l’une de ces options à suivre dans un bloc-notes :
- Ouvrez et exécutez le notebook intégré.
- Chargez votre bloc-notes à partir de GitHub.
Ouvrir le notebook intégré
Le carnet de recommandations de livres échantillon accompagne ce didacticiel.
Pour ouvrir l’exemple de notebook pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données.
Assurez-vous d’attacher un lakehouse au notebook avant de commencer à exécuter du code.
Importer le bloc-notes à partir de GitHub
Le bloc-notes AIsample - Book Recommendation.ipynb accompagne ce didacticiel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code à partir de cette page, vous pouvez créer un bloc-notes.
Assurez-vous d'attacher un lakehouse au notebook avant de commencer à exécuter du code.
Étape 1 : Charger les données
Le jeu de données de recommandation de livre dans ce scénario se compose de trois jeux de données distincts :
Books.csv: un numéro de livre standard international (ISBN) identifie chaque livre, avec des dates non valides déjà supprimées. Le jeu de données inclut également le titre, l’auteur et publisher. Pour un livre avec plusieurs auteurs, le fichier Books.csv répertorie uniquement le premier auteur. Les URL pointent vers les ressources du site web Amazon pour les images de couverture, en trois tailles.
ISBN Titre-livre Auteur-livre Année-de-publication Éditeur Image-URL-S Image-URL-M Image-URL-l 0195153448 Mythologie classique Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: les évaluations pour chaque livre sont explicites (fournies par les utilisateurs, sur une échelle de 1 à 10) ou implicites (observées sans entrée utilisateur et indiquées par 0).
User-ID ISBN Classement-livre 276725 034545104X 0 276726 0155061224 5 Users.csv: les ID utilisateur sont anonymisés et mappés à des entiers. Les données démographiques ( par exemple, l’emplacement et l’âge) sont fournies, le cas échéant. Si ces données ne sont pas disponibles, ces valeurs sont
null.User-ID Emplacement Âge 1 « nyc new york usa » 2 « stockton california usa » 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Définissez ces paramètres pour pouvoir utiliser ce notebook avec différents jeux de données :
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Télécharger et stocker les données dans un lakehouse
Ce code télécharge le jeu de données, puis le stocke dans le lakehouse.
Important
Assurez-vous d’ajouter un lakehouse au notebook avant de l’exécuter. Sinon, vous obtenez une erreur.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Configurer le suivi des expériences MLflow
Utilisez ce code pour configurer le suivi des expériences MLflow. Cet exemple désactive la journalisation automatique. Pour plus d’informations, consultez l’article Autologging dans Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Lire des données à partir du lakehouse
Après avoir placé les données correctes dans le lac de données, lisez séparément les trois jeux de données dans des DataFrames Spark distincts du notebook. Les chemins d’accès aux fichiers de ce code utilisent les paramètres définis précédemment.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Étape 2 : Effectuer une analyse exploratoire des données
Afficher des données brutes
Explorez les DataFrames à l’aide de la display commande. À l’aide de cette commande, vous pouvez afficher des statistiques dataFrame de haut niveau et comprendre comment les différentes colonnes de jeu de données se rapportent les unes aux autres. Avant d’explorer les jeux de données, utilisez ce code pour importer les bibliothèques requises :
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Utilisez ce code pour examiner le DataFrame qui contient les données du livre :
display(df_items, summary=True)
Ajoutez une colonne _item_id pour une utilisation ultérieure. La valeur _item_id doit être un entier pour les modèles de recommandation. Ce code utilise StringIndexer pour transformer ITEM_ID_COL en index :
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Affichez le DataFrame et vérifiez si la valeur _item_id augmente monotoniquement et successivement, comme prévu :
display(df_items.sort(F.col("_item_id").desc()))
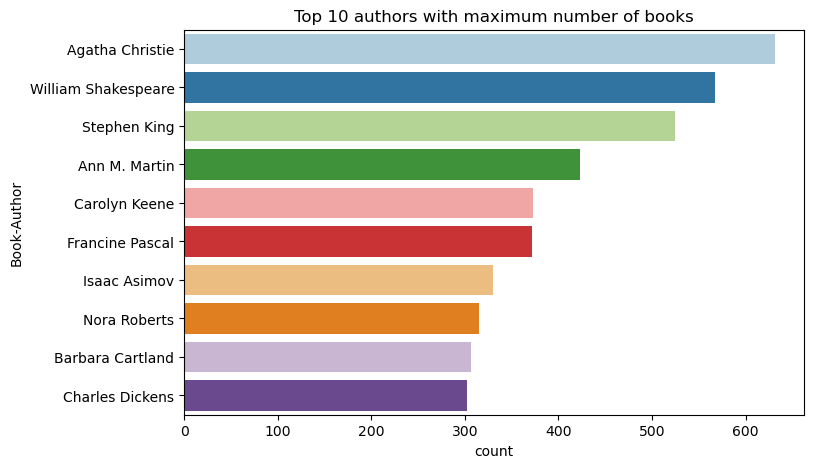
Utilisez ce code pour tracer les 10 premiers auteurs, par nombre de livres écrits, dans l’ordre décroissant. Agatha Christie est l’auteur principal avec plus de 600 livres, suivi de William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Ensuite, affichez le DataFrame qui contient les données utilisateur :
display(df_users, summary=True)
Si une ligne a une valeur User-ID manquante, supprimez cette ligne. Les valeurs manquantes dans un jeu de données personnalisé ne provoquent pas de problèmes.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Ajoutez une colonne _user_id pour une utilisation ultérieure. Pour les modèles de recommandation, la valeur _user_id doit être un entier. L’exemple de code suivant utilise StringIndexer pour transformer USER_ID_COL en index.
Le jeu de données de livre possède déjà une colonne entière User-ID. Toutefois, l’ajout d’une colonne _user_id pour la compatibilité avec différents jeux de données rend cet exemple plus robuste. Utilisez ce code pour ajouter la colonne _user_id :
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Utilisez ce code pour afficher les données d’évaluation :
display(df_ratings, summary=True)
Obtenez les évaluations distinctes et enregistrez-les pour une utilisation ultérieure dans une liste nommée ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
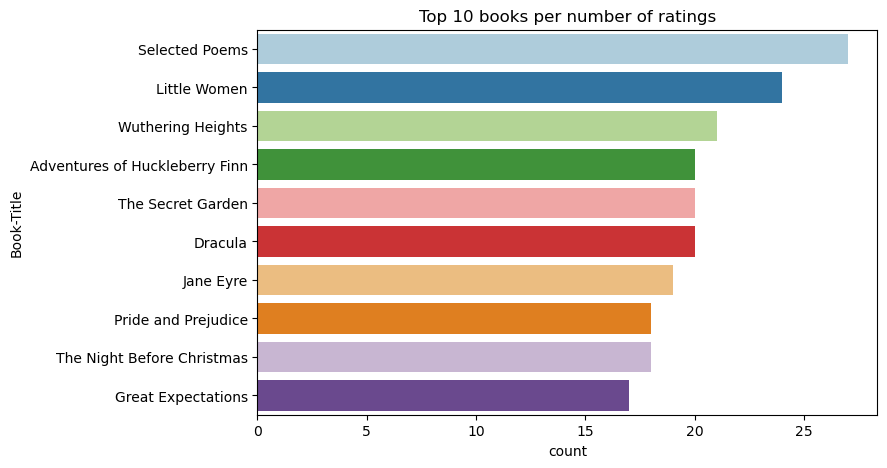
Utilisez ce code pour afficher les 10 premiers livres avec les évaluations les plus élevées :
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Selon les évaluations, Poèmes sélectionnés est le livre le plus populaire. Adventures of Huckleberry Finn, The Secret Gardenet Dracula ont la même cote.
Fusionner des données
Fusionnez les trois DataFrames dans un DataFrame pour une analyse plus complète :
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Utilisez ce code pour afficher le nombre d’utilisateurs, de livres et d’interactions distincts :
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Calculer et tracer les éléments les plus populaires
Utilisez ce code pour calculer et afficher les 10 livres les plus populaires :
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Conseil
Utilisez la valeur <topn> pour les sections populaires ou les suggestions des articles les plus achetés.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Préparer des jeux de données d’entraînement et de test
La matrice ALS nécessite une préparation des données avant l’entraînement. Utilisez cet exemple de code pour préparer les données. Le code effectue ces actions :
- Convertissez la colonne d’évaluation en type correct.
- Échantillonner les données d'entraînement avec des évaluations utilisateur.
- Fractionnez les données en jeux de données d’entraînement et de test.
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
L’éparsité fait référence aux données de commentaires éparses, qui ne peuvent pas identifier les similitudes dans les intérêts des utilisateurs. Pour mieux comprendre les données et le problème actuel, utilisez ce code pour calculer la sparsité du jeu de données :
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Étape 3 : Développer et entraîner le modèle
Entraîner un modèle ALS pour donner aux utilisateurs des recommandations personnalisées.
Définir le modèle
Spark ML fournit une API pratique pour créer le modèle ALS. Toutefois, le modèle ne gère pas de manière fiable les problèmes tels que l’éparsité des données et le démarrage à froid (en faisant des recommandations lorsque les utilisateurs ou les éléments sont nouveaux). Pour améliorer les performances du modèle, combinez la validation croisée et le réglage automatique des hyperparamètres.
Utilisez ce code pour importer les bibliothèques requises pour l’entraînement et l’évaluation du modèle :
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Ajuster les hyperparamètres de modèle
L’exemple de code suivant construit une grille de paramètres pour faciliter la recherche sur les hyperparamètres. Le code crée également un évaluateur de régression qui utilise l’erreur de carré racine moyenne (RMSE) comme métrique d’évaluation :
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
L’exemple de code suivant lance différentes méthodes de paramétrage de modèle en fonction des paramètres préconfigurés. Pour plus d’informations sur le réglage des modèles, consultez Paramétrage ML : sélection de modèle et réglage des hyperparamètres sur le site web Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Évaluer le modèle
Évaluez les modèles par rapport aux données de test. Un modèle bien formé comporte des métriques élevées sur le jeu de données.
Un modèle surajusté peut nécessiter davantage de données d’apprentissage ou une réduction de certaines fonctionnalités redondantes. Vous devrez peut-être modifier l’architecture du modèle ou affiner ses paramètres.
Remarque
Une valeur de métrique R-squared négative indique que le modèle entraîné s’exécute moins bien qu’une ligne droite horizontale. Cette recherche suggère que le modèle entraîné n’explique pas les données.
Utilisez ce code pour définir une fonction d’évaluation :
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Suivre l’expérience à l’aide de MLflow
Utilisez MLflow pour suivre toutes les expériences et consigner les paramètres, les métriques et les modèles. Pour démarrer la formation et l’évaluation du modèle, utilisez ce code :
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Sélectionnez l’expérience nommée aisample-recommendation dans votre espace de travail pour afficher les informations consignées de l’exécution de l’entraînement. Si vous modifiez le nom de l’expérience, sélectionnez l’expérience portant le nouveau nom. Les informations enregistrées ressemblent à cette image :

Étape 4 : Charger le modèle final pour le scoring et effectuer des prédictions
Une fois que vous avez terminé d’entraîner le modèle et sélectionné le meilleur modèle, chargez le modèle pour l'évaluation, parfois également appelée inférence. Ce code charge le modèle et utilise des prédictions pour recommander les 10 premiers livres pour chaque utilisateur :
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
La sortie ressemble à ce tableau :
| _item_id | _id_utilisateur | rating | Titre-livre |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher : Vies de ... |
| 786 | 7 | 6.2255826 | Le D de l'Homme au Piano |
| 45330 | 7 | 4.980466 | État d’esprit |
| 38960 | 7 | 4.980466 | Tout ce qu’il voulait |
| 125415 | 7 | 4.505084 | Harry Potter et ... |
| 44939 | 7 | 4.3579073 | Taltos : Vies de ... |
| 175247 | 7 | 4.3579073 | The Bonesetter’s ... |
| 170183 | 7 | 4.228735 | Vivre le Simple... |
| 88503 | 7 | 4.221206 | Île du Blu... |
| 32894 | 7 | 3.9031885 | Solstice d’hiver |
Enregistrer les prédictions dans le lakehouse
Utilisez ce code pour enregistrer les suggestions dans le lakehouse :
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)
Contenu connexe
- Entraîner et évaluer un modèle de classification de texte
- modèle d'apprentissage automatique dans Microsoft Fabric
- Entraîner des modèles d'apprentissage automatique
- Expériences d'apprentissage automatique dans Microsoft Fabric