Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez apprendre à effectuer une analyse exploratoire des données (EDA) pour examiner et examiner les données tout en récapitulé ses principales caractéristiques à l’aide des techniques de visualisation des données.
Vous utiliserez seaborn, une bibliothèque de visualisation de données Python qui fournit une interface de haut niveau pour créer des visuels sur des dataframes et des tableaux. Pour plus d’informations sur seaborn, consultez Seaborn : Statistical Data Visualisation.
Vous utiliserez également data Wrangler, un outil basé sur un notebook qui vous offre une expérience immersive pour effectuer une analyse exploratoire des données et le nettoyage.
Les principales étapes de ce didacticiel sont les suivantes :
- Lire les données stockées à partir d’une table delta dans le lakehouse.
- Convertissez un DataFrame Spark en DataFrame Pandas, pris en charge par les bibliothèques de visualisation Python.
- Utilisez Data Wrangler pour effectuer le nettoyage et la transformation initiaux des données.
- Effectuez une analyse exploratoire des données à l’aide de
seaborn.
Conditions préalables
Obtenez un abonnement Microsoft Fabric . Vous pouvez également vous inscrire à une version d’évaluation gratuite de Microsoft Fabric .
Connectez-vous à Microsoft Fabric.
Basculez vers Fabric à l’aide du sélecteur d’expérience situé en bas à gauche de votre page d’accueil.

Il s’agit de la partie 2 sur 5 de la série de tutoriels. Pour suivre ce didacticiel, commencez par effectuer les travaux suivants :
Suivre dans le notebook
2-explore-cleanse-data.ipynb est le notebook qui accompagne ce tutoriel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code à partir de cette page, vous pouvez créer un bloc-notes.
Assurez-vous d’attacher un lakehouse au notebook avant de commencer à exécuter du code.
Important
Attachez le même lakehouse que celui que vous avez utilisé dans la partie 1.
Lire des données brutes à partir du lakehouse
Lisez les données brutes de la section Fichiers du lakehouse. Vous avez chargé ces données dans le bloc-notes précédent. Assurez-vous que vous avez attaché le même lakehouse que celui utilisé dans la partie 1 à ce notebook avant d’exécuter ce code.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Créer un DataFrame pandas à partir du jeu de données
Convertissez le DataFrame spark en DataFrame pandas pour faciliter le traitement et la visualisation.
df = df.toPandas()
Afficher des données brutes
Explorez les données brutes avec display, effectuez des statistiques de base et affichez des vues de graphique. Notez que vous devez d’abord importer les bibliothèques requises telles que Numpy, Pnadas, Seabornet Matplotlib pour l’analyse et la visualisation des données.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
Utiliser Data Wrangler pour effectuer le nettoyage initial des données
Pour explorer et transformer tout DataFrame Pandas de votre notebook, lancez Data Wrangler directement à partir de ce dernier.
Note
Data Wrangler ne peut pas être ouvert pendant que le noyau du notebook est occupé. L’exécution de la cellule doit être terminée avant le lancement de Data Wrangler.
- Sous l’onglet Données du ruban du notebook, sélectionnez Lancer Data Wrangler. Vous verrez la liste des DataFrames pandas activés disponibles pour modification.
- Sélectionnez le DataFrame que vous souhaitez ouvrir dans Data Wrangler. Étant donné que ce notebook ne contient qu’un seul DataFrame,
df, sélectionnezdf.
Data Wrangler lance et génère une vue d’ensemble descriptive de vos données. La table au milieu affiche chaque colonne de données. Le panneau Résumé en regard du tableau affiche des informations sur le DataFrame. Lorsque vous sélectionnez une colonne dans le tableau, le résumé est mis à jour avec des informations sur la colonne sélectionnée. Dans certains cas, les données affichées et résumées sont une vue tronquée de votre DataFrame. Lorsque cela se produit, vous verrez l’image d’avertissement dans le volet résumé. Pointez sur cet avertissement pour afficher le texte expliquant la situation.

Chaque opération que vous effectuez peut être appliquée en quelques clics, en mettant à jour l’affichage des données en temps réel et en générant du code que vous pouvez enregistrer dans votre bloc-notes en tant que fonction réutilisable.
Le reste de cette section vous guide tout au long des étapes de nettoyage des données avec Data Wrangler.
Supprimer les lignes dupliquées
Dans le volet gauche, vous trouverez une liste d’opérations (telles que Rechercher et remplacer, Format, Formules, Numérique) que vous pouvez effectuer sur le jeu de données.
Développez Rechercher et remplacer, puis sélectionnez Supprimer les lignes dupliquées.
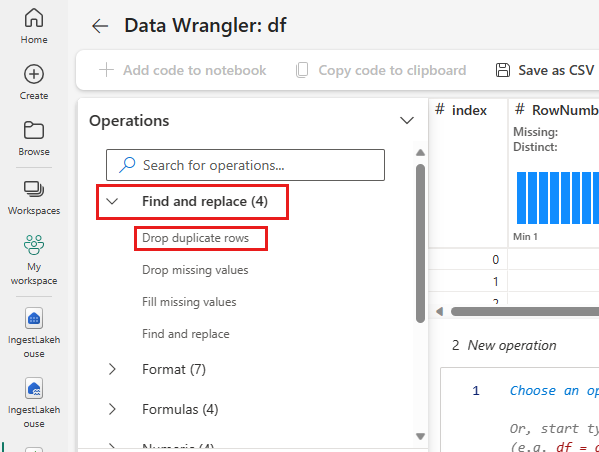
Un panneau s’affiche pour vous permettre de sélectionner la liste des colonnes que vous souhaitez comparer pour définir une ligne en double. Sélectionnez RowNumber et CustomerId.
Dans le panneau central, vous trouverez un aperçu des résultats de cette opération. Sous l'aperçu se trouve le code pour effectuer l'opération. Dans cette instance, les données semblent inchangées. Mais étant donné que vous examinez une vue tronquée, il est judicieux de néanmoins appliquer l’opération.
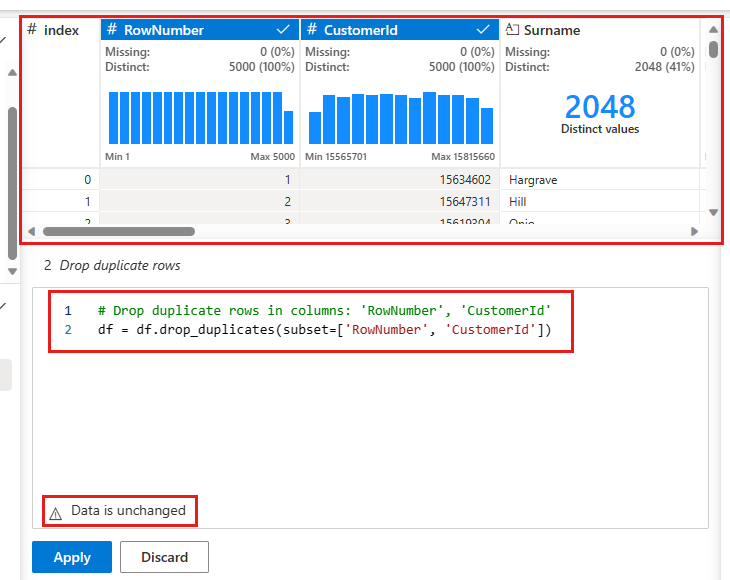
Sélectionnez Appliquer (à côté ou en bas) pour passer à l’étape suivante.

Supprimer des lignes avec des données manquantes
Utilisez Data Wrangler pour supprimer des lignes avec des données manquantes sur toutes les colonnes.
Sélectionnez Supprimer les valeurs manquantes dans Rechercher et remplacer.
Choisissez Tout sélectionner dans les Colonnes cibles.
Sélectionnez Appliquer pour passer à l’étape suivante.

Supprimer des colonnes
Utilisez Data Wrangler pour supprimer des colonnes dont vous n’avez pas besoin.
Développez le schéma , puis sélectionnez Supprimer les colonnes.
Sélectionnez Numéro de ligne, Identifiant client, Nom de famille. Ces colonnes apparaissent en rouge dans l’aperçu pour indiquer qu’elles sont modifiées par le code (dans ce cas, supprimées.)
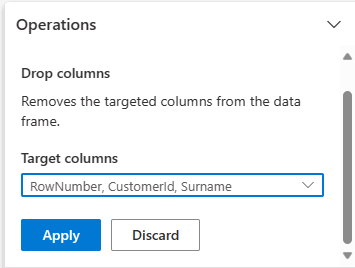
Sélectionnez Appliquer pour passer à l’étape suivante.

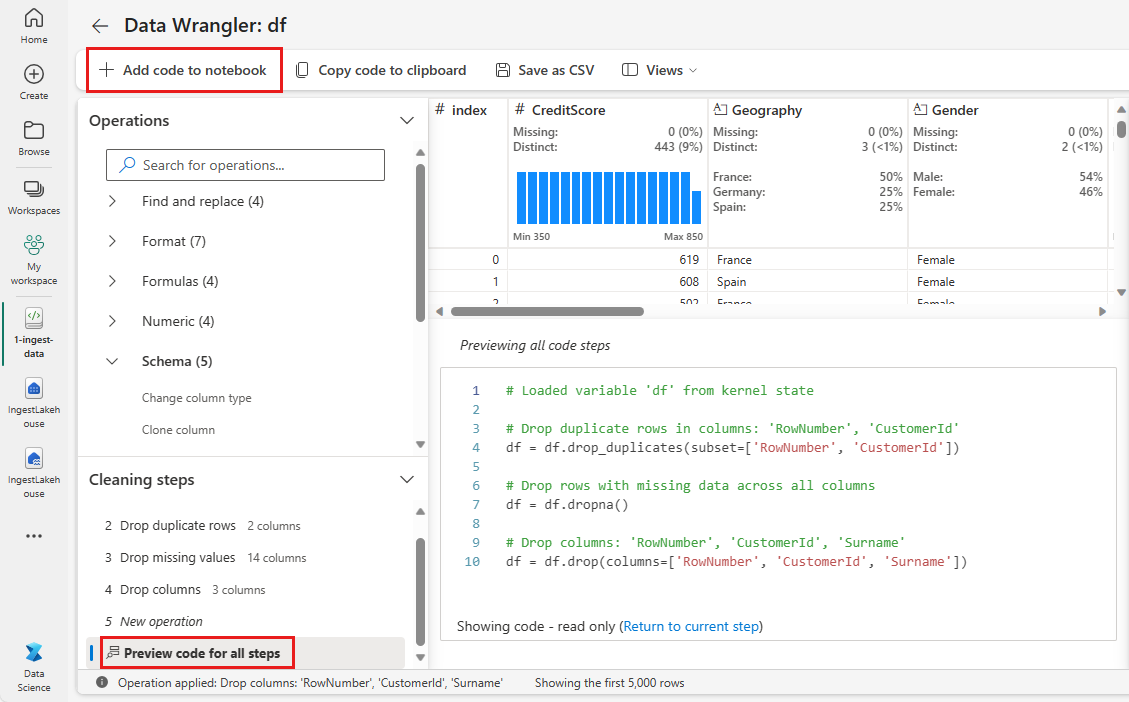
Ajouter du code au bloc-notes
Chaque fois que vous sélectionnez Appliquer, une nouvelle étape est créée dans le panneau Étapes de nettoyage en bas à gauche. En bas du panneau, sélectionnez code d’aperçu pour toutes les étapes pour afficher une combinaison de toutes les étapes distinctes.
Sélectionnez Ajouter du code au notebook en haut à gauche pour fermer Data Wrangler et ajouter automatiquement le code. L'action "Ajouter du code au carnet" encapsule le code dans une fonction, puis appelle la fonction.
Conseil
Le code généré par Data Wrangler ne sera pas appliqué tant que vous n’exécutez pas manuellement la nouvelle cellule.
Si vous n’avez pas utilisé Data Wrangler, vous pouvez utiliser cette cellule de code suivante.
Ce code est similaire au code produit par Data Wrangler, mais ajoute l’argument inplace=True à chacune des étapes générées. En définissant inplace=True, pandas remplace le DataFrame d’origine au lieu de produire un nouveau DataFrame en tant que sortie.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Explorer les données
Affichez des résumés et des visualisations des données nettoyées.
Déterminer les attributs catégoriels, numériques et cibles
Utilisez ce code pour déterminer les attributs catégoriels, numériques et cibles.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
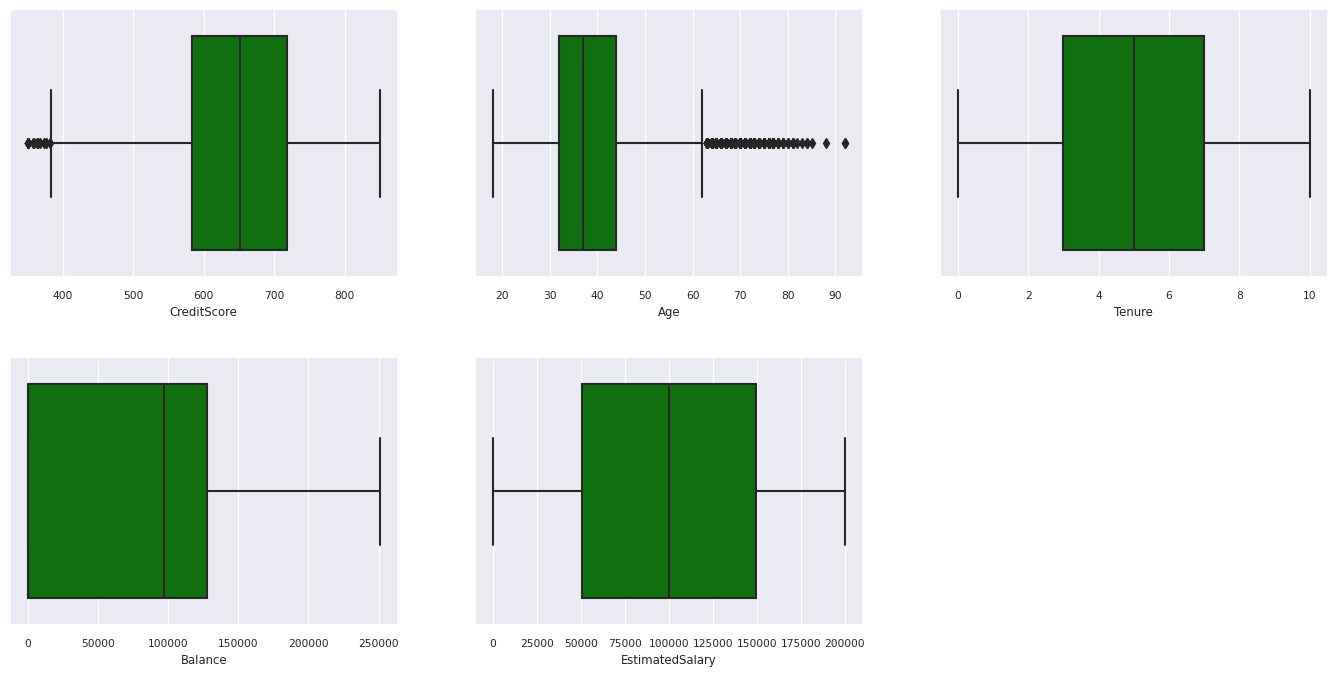
Résumé à cinq nombres
Afficher le résumé à cinq nombres (score minimal, premier quartile, médiane, troisième quartile, score maximal) pour les attributs numériques, à l’aide de tracés de zone.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Distribution des clients sortants et non-sortants
Affichez la distribution des clients sortants et non sortants selon les attributs catégoriels.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

Distribution d’attributs numériques
Afficher la distribution de fréquence d’attributs numériques à l’aide de l’histogramme.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Effectuer l’ingénierie des fonctionnalités
Effectuez l’ingénierie des fonctionnalités pour générer de nouveaux attributs en fonction des attributs actuels :
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Utiliser Data Wrangler pour effectuer un encodage à chaud
Data Wrangler peut également être utilisé pour effectuer un encodage un parmi n. Pour ce faire, rouvrez Data Wrangler. Cette fois, sélectionnez les données df_clean.
- Développez Formules, puis sélectionnez Encodage un parmi n.
- Un volet s’affiche pour vous permettre de sélectionner la liste des colonnes sur lesquelles vous souhaitez effectuer l’encodage un parmi n. Sélectionnez Géographie et Genre.
Vous pouvez copier le code généré, fermer Data Wrangler pour revenir au bloc-notes, puis coller dans une nouvelle cellule. Vous pouvez également sélectionner Ajouter du code au notebook en haut à gauche pour fermer Data Wrangler et ajouter automatiquement le code.
Si vous n’avez pas utilisé Data Wrangler, vous pouvez utiliser plutôt cette cellule de code suivante :
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Résumé des observations de l’analyse exploratoire des données
- La plupart des clients proviennent de la France par rapport à l’Espagne et à l’Allemagne, tandis que l’Espagne a le taux d’évolution le plus bas comparé à la France et à l’Allemagne.
- La plupart des clients ont des cartes de crédit.
- Il existe des clients dont le score d’âge et de crédit est supérieur à 60 et inférieur à 400, respectivement, mais ils ne peuvent pas être considérés comme des valeurs hors norme.
- Très peu de clients ont plus de deux des produits de la banque.
- Les clients qui ne sont pas actifs ont un taux d’attrition plus élevé.
- Les années d'ancienneté et le genre ne semblent pas avoir d'impact sur la décision du client de fermer le compte bancaire.
Créer une table delta pour les données nettoyées
Vous allez utiliser ces données dans le bloc-notes suivant de cette série.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Étape suivante
Entraîner et inscrire des modèles Machine Learning avec ces données :